 README
¶
README
¶

mapreduce
English | 简体中文
Why MapReduce is needed
In practical business scenarios we often need to get the corresponding properties from different rpc services to assemble complex objects.
For example, to query product details.
- product service - query product attributes
- inventory service - query inventory properties
- price service - query price attributes
- marketing service - query marketing properties
If it is a serial call, the response time will increase linearly with the number of rpc calls, so we will generally change serial to parallel to optimize response time.
Simple scenarios using WaitGroup can also meet the needs, but what if we need to check the data returned by the rpc call, data processing, data aggregation? The official go library does not have such a tool (CompleteFuture is provided in java), so we implemented an in-process data batching MapReduce concurrent tool based on the MapReduce architecture.
Design ideas
Let's try to put ourselves in the author's shoes and sort out the possible business scenarios for the concurrency tool:
- querying product details: supporting concurrent calls to multiple services to combine product attributes, and supporting call errors that can be ended immediately.
- automatic recommendation of user card coupons on product details page: support concurrently verifying card coupons, automatically rejecting them if they fail, and returning all of them.
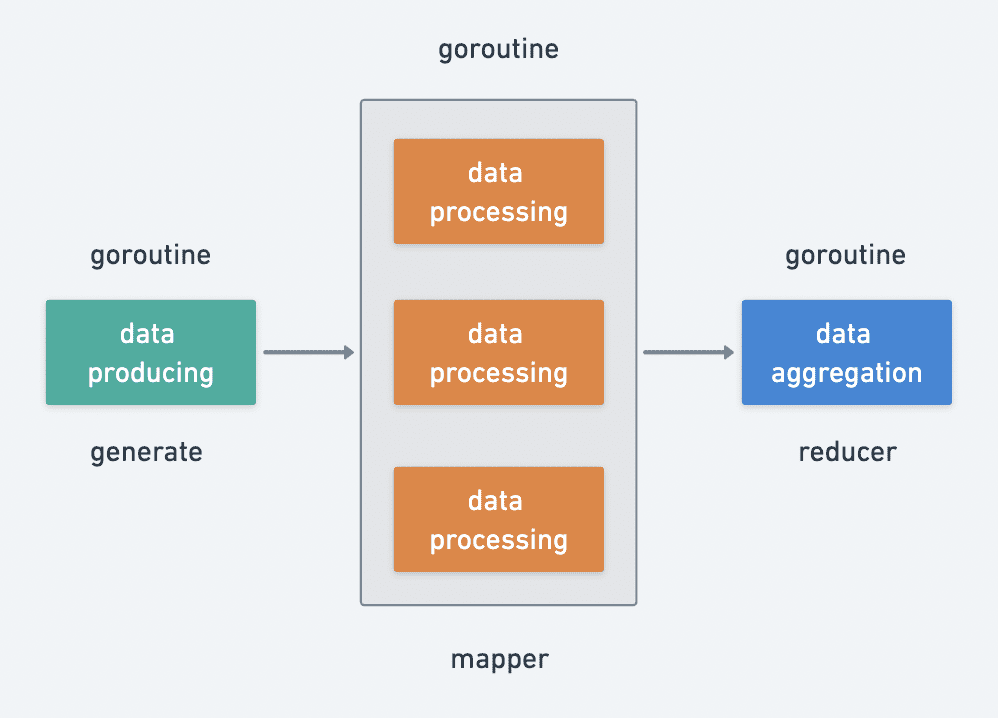
The above is actually processing the input data and finally outputting the cleaned data. There is a very classic asynchronous pattern for data processing: the producer-consumer pattern. So we can abstract the life cycle of data batch processing, which can be roughly divided into three phases.

- data production generate
- data processing mapper
- data aggregation reducer
Data producing is an indispensable stage, data processing and data aggregation are optional stages, data producing and processing support concurrent calls, data aggregation is basically a pure memory operation, so a single concurrent process can do it.
Since different stages of data processing are performed by different goroutines, it is natural to consider the use of channel to achieve communication between goroutines.
How can I terminate the process at any time?
It's simple, just receive from a channel or the given context in the goroutine.
A simple example
Calculate the sum of squares, simulating the concurrency.
package main
import (
"fmt"
"log"
"github.com/tal-tech/go-zero/core/mr"
)
func main() {
val, err := mr.MapReduce(func(source chan<- interface{}) {
// generator
for i := 0; i < 10; i++ {
source <- i
}
}, func(item interface{}, writer mr.Writer, cancel func(error)) {
// mapper
i := item.(int)
writer.Write(i * i)
}, func(pipe <-chan interface{}, writer mr.Writer, cancel func(error)) {
// reducer
var sum int
for i := range pipe {
sum += i.(int)
}
writer.Write(sum)
})
if err != nil {
log.Fatal(err)
}
fmt.Println("result:", val)
}
More examples: https://github.com/zeromicro/zero-examples/tree/main/mapreduce
Give a Star! ⭐
If you like or are using this project to learn or start your solution, please give it a star. Thanks!
 Documentation
¶
Documentation
¶
Index ¶
- Variables
- func Finish(fns ...func() error) error
- func FinishVoid(fns ...func())
- func Map(generate GenerateFunc, mapper MapFunc, opts ...Option) chan interface{}
- func MapReduce(generate GenerateFunc, mapper MapperFunc, reducer ReducerFunc, opts ...Option) (interface{}, error)
- func MapReduceVoid(generate GenerateFunc, mapper MapperFunc, reducer VoidReducerFunc, ...) error
- func MapReduceWithSource(source <-chan interface{}, mapper MapperFunc, reducer ReducerFunc, ...) (interface{}, error)
- func MapVoid(generate GenerateFunc, mapper VoidMapFunc, opts ...Option)
- type GenerateFunc
- type MapFunc
- type MapperFunc
- type Option
- type ReducerFunc
- type VoidMapFunc
- type VoidReducerFunc
- type Writer
Constants ¶
This section is empty.
Variables ¶
var ( // ErrCancelWithNil is an error that mapreduce was cancelled with nil. ErrCancelWithNil = errors.New("mapreduce cancelled with nil") // ErrReduceNoOutput is an error that reduce did not output a value. ErrReduceNoOutput = errors.New("reduce not writing value") )
Functions ¶
func Map ¶
func Map(generate GenerateFunc, mapper MapFunc, opts ...Option) chan interface{}
Map maps all elements generated from given generate func, and returns an output channel.
func MapReduce ¶
func MapReduce(generate GenerateFunc, mapper MapperFunc, reducer ReducerFunc, opts ...Option) (interface{}, error)
MapReduce maps all elements generated from given generate func, and reduces the output elements with given reducer.
func MapReduceVoid ¶
func MapReduceVoid(generate GenerateFunc, mapper MapperFunc, reducer VoidReducerFunc, opts ...Option) error
MapReduceVoid maps all elements generated from given generate, and reduce the output elements with given reducer.
func MapReduceWithSource ¶
func MapReduceWithSource(source <-chan interface{}, mapper MapperFunc, reducer ReducerFunc,
opts ...Option) (interface{}, error)
MapReduceWithSource maps all elements from source, and reduce the output elements with given reducer.
func MapVoid ¶
func MapVoid(generate GenerateFunc, mapper VoidMapFunc, opts ...Option)
MapVoid maps all elements from given generate but no output.
Types ¶
type GenerateFunc ¶
type GenerateFunc func(source chan<- interface{})
GenerateFunc is used to let callers send elements into source.
type MapFunc ¶
type MapFunc func(item interface{}, writer Writer)
MapFunc is used to do element processing and write the output to writer.
type MapperFunc ¶
MapperFunc is used to do element processing and write the output to writer, use cancel func to cancel the processing.
type Option ¶
type Option func(opts *mapReduceOptions)
Option defines the method to customize the mapreduce.
func WithContext ¶ added in v1.2.5
WithContext customizes a mapreduce processing accepts a given ctx.
func WithWorkers ¶
WithWorkers customizes a mapreduce processing with given workers.
type ReducerFunc ¶
ReducerFunc is used to reduce all the mapping output and write to writer, use cancel func to cancel the processing.
type VoidMapFunc ¶
type VoidMapFunc func(item interface{})
VoidMapFunc is used to do element processing, but no output.
type VoidReducerFunc ¶
type VoidReducerFunc func(pipe <-chan interface{}, cancel func(error))
VoidReducerFunc is used to reduce all the mapping output, but no output. Use cancel func to cancel the processing.