 README
¶
README
¶
logkit 
简介
logkit是七牛Pandora开发的一个通用的日志收集工具,可以将不同数据源的数据方便的发送到Pandora进行数据分析,除了基本的数据发送功能,logkit还有容错、并发、监控、删除等功能。
详细的文档可以参见logkit wiki
支持的数据源
- 文件(包括csv格式的文件,kafka-rest日志文件,nginx日志文件等,并支持以grok的方式解析日志)
- MySQL
- Microsoft SQL Server(MS SQL)
- Elasticsearch
- MongoDB
- Kafka
- Redis
工作方式
logkit本身支持多种数据源,并且可以同时发送多个数据源的数据到Pandora,每个数据源对应一个逻辑上的runner,一个runner负责一个数据源的数据推送,工作原理如下图所示

下载
请移步至Download页面
安装与使用
- 下载&解压logkit工具
Linux 版本
wget http://op26gaeek.bkt.clouddn.com/logkit.tar.gz && tar xvf logkit.tar.gz && cd _package_linux64/
MacOS 版本
wget http://op26gaeek.bkt.clouddn.com/logkit_mac.tar.gz && tar xvf logkit_mac.tar.gz && cd _package_mac/
Windows 版本
请下载 http://op26gaeek.bkt.clouddn.com/logkit_windows.zip 并解压缩,进入目录
- 修改runner的配置
打开 confs/default.conf
按照图示进行修改
- 启动logkit工具
./logkit -f logkit.conf
logkit.conf是logkit工具本身的配置文件,主要用于指定logkit运行时需要的资源和各个runner配置文件的具体路径。
max_procslogkit运行过程中最多用到多少个核debug_level日志输出级别,0为debug,数字越高级别越高confs_path是一个列表,列表中的每一项都是一个runner的配置文件夹,如果每一项中文件夹下配置发生增加、减少或者变更,logkit会相应的增加、减少或者变更runner,配置文件夹中的每个配置文件都代表了一个runner。
典型的配置如下:
{
"max_procs": 8,
"debug_level": 1,
"confs_path": ["confs"]
}
上面的配置指定了一个runner的配置文件夹,这个配置文件夹下面每个以.conf结尾的文件就代表了一个运行的runner,也就代表了一个logkit正在运行的推送数据的线程。
单个runner的配置详解
为了简化logkit的配置工作,Pandora提供一个logkit配置文件帮手来根据不同的runner类型来生成配置文件。
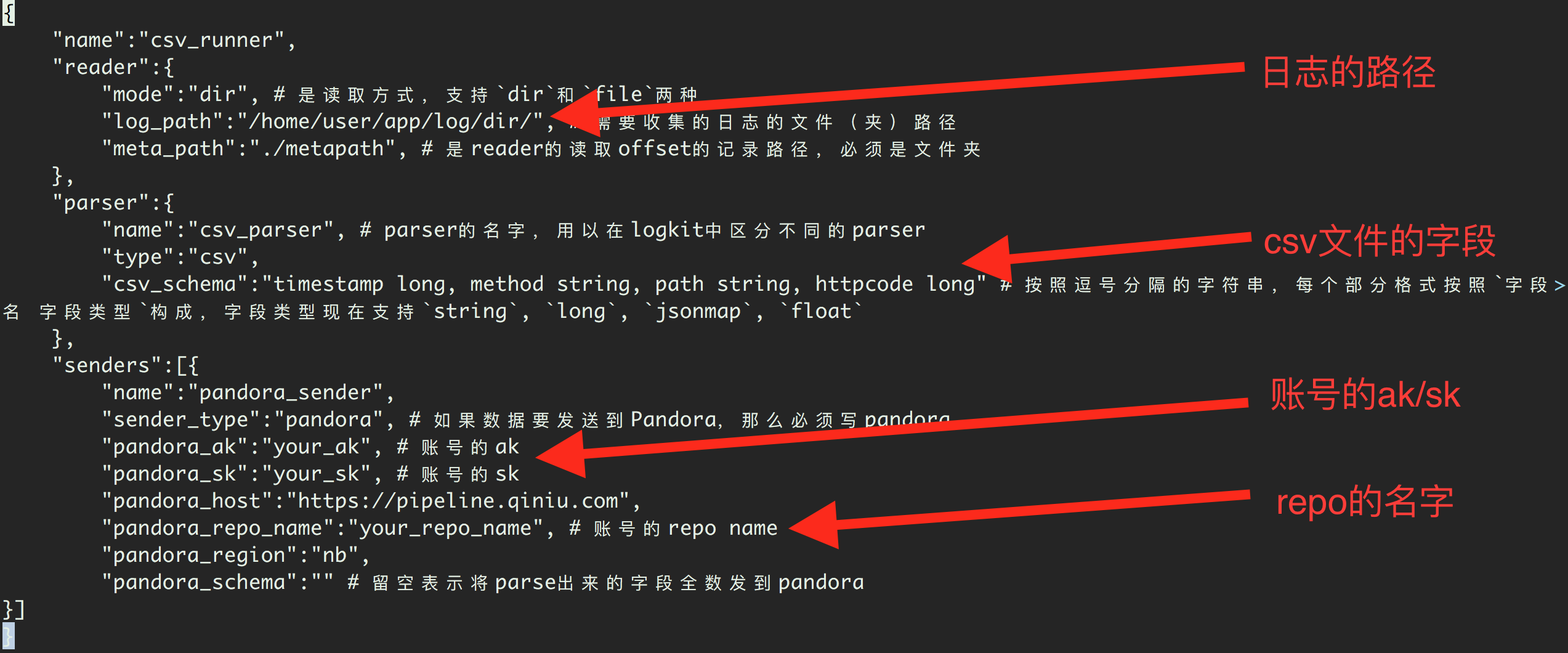
典型的 csv Runner配置如下。
{
"name":"csv_runner", # 用来标识runner的名字,用以在logkit中区分不同runner的日志
"reader":{
"mode":"dir", # 是读取方式,支持`dir`和`file`两种
"log_path":"/home/user/app/log/dir/", # 需要收集的日志的文件(夹)路径
"meta_path":"./metapath", # 是reader的读取offset的记录路径,必须是文件夹
},
"parser":{
"name":"csv_parser", # parser的名字,用以在logkit中区分不同的parser
"type":"csv",
"csv_schema":"timestamp long, method string, path string, httpcode long" # 按照逗号分隔的字符串,每个部分格式按照`字段名 字段类型`构成,字段类型现在支持`string`, `long`, `jsonmap`, `float`
},
"senders":[{ # senders是
"name":"pandora_sender",
"sender_type":"pandora", # 如果数据要发送到Pandora,那么必须写pandora
"pandora_ak":"your_ak", # 账号的ak
"pandora_sk":"your_sk", # 账号的sk
"pandora_host":"https://pipeline.qiniu.com",
"pandora_repo_name":"your_repo_name", # 账号的repo name
"pandora_region":"nb"
}]
}
对于csv文件的上传,只需要修改上述配置文件的log_path,csv_schema,pandora_ak,pandora_sk,pandora_repo_name就完成了一个基本的上传csv文件的logkit配置。
从源码安装与启动
启动服务的命令中可以指定服务的启动配置
go get -u github.com/kardianos/govendor
govendor sync
go get ./...
go build -o logkit logkit.go
./logkit -f logkit.conf
使用logkit的docker镜像启动
docker pull wonderflow/logkit
docker run -d -p 3000:3000 -v /local/logkit/dataconf:/app/confs -v /local/log/path:/logs/path logkit
镜像中,logkit读取/app/confs下的配置文件,所以可以通过挂载目录的形式,将本地的logkit配置目录/local/logkit/dataconf挂载到镜像里面。
需要注意的是,镜像中的logkit收集 /logs目录下的日志,需要把本地的日志目录也挂载到镜像里面去才能启动,比如本地的日志目录为/local/log/path, 挂载到镜像中的/logs/path目录,那么/local/logkit/dataconf目录下的配置文件填写的日志路径必须是/logs/path。
Enjoy it!
 Documentation
¶
Documentation
¶

There is no documentation for this package.
 Directories
¶
Directories
¶
| Path | Synopsis |
|---|---|
|
rate limit and traffic control
|
rate limit and traffic control |
|
Package bufio implements buffered I/O. It wraps an FileReader or io.Writer object, creating another object (Reader or Writer) that also implements the interface but provides buffering and some help for textual I/O.
|
Package bufio implements buffered I/O. It wraps an FileReader or io.Writer object, creating another object (Reader or Writer) that also implements the interface but provides buffering and some help for textual I/O. |