 README
¶
README
¶
Example: web-links
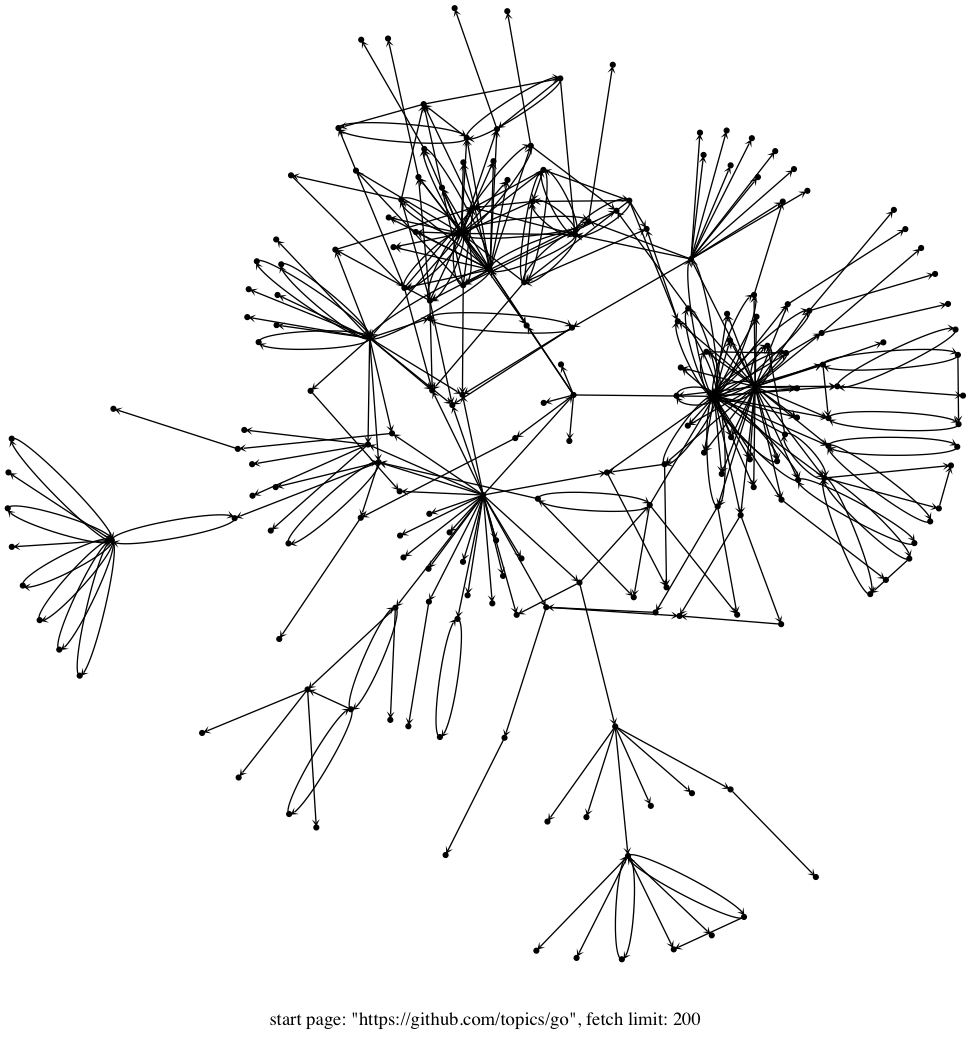
This example is a simple web crawler that finds all anchor tags in a web page and follows the links to get to other pages. After a predefined number of pages are fetched, it creates a graph of the pages using graphviz.
The crawler only fetches URLs that are of the form github.com/user/repo. Here is a graph generated by this program starting from https://github.com/topics/go limited to 200 URLs:
 Documentation
¶
Documentation
¶

There is no documentation for this package.
Click to show internal directories.
Click to hide internal directories.