 README
¶
README
¶
kafka dev env:
clone: git clone git@github.com:wurstmeister/kafka-docker.git
start kafka: docker-compose -f docker-compose-single-broker.yml up -d
close kafka: docker-compose down -v
gomsg
The project is not yet complete.
项目还未完成,文档也没好好整理,代码量很少,有兴趣的可以稍微看看。
分布式推送服务:
- 基于gRPC,轻量级
- 无限横向扩展
- 单用户多平台使用
- 离线消息存储
- 在此基础上开发的简易聊天系统 gochat
Install/Preview video, Click to watch
不想看安装过程可以直接看 1:02 和 2:00
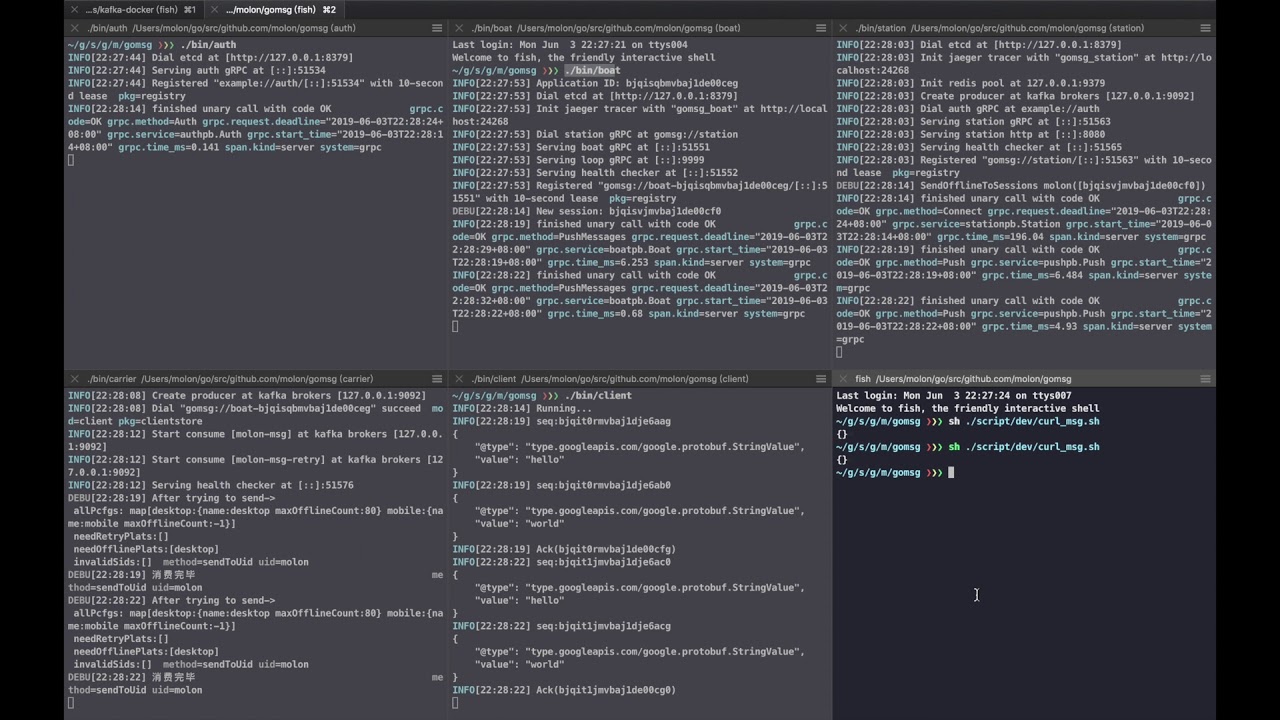
Don't care the words below (以下很乱,还不一定对,暂时的笔记罢了,不用怎么关心)
服务简介
- boat负责保持客户端连接,且和station同步连接状态
- station负责同步客户端连接状态持久化到redis,且负责向MQ投递推送任务或者一般任务(踢出/下发离线消息)
- carrier负责消费MQ的推送任务,在线则下发,不在线则离线存储,且根据情况决定是否向MQ投递通知任务
- carrier负责消费MQ的一般任务,kickout啊,下发离线消息等等。
- horn负责消费MQ的通知任务,根据情况决定是调用iOS APNS啊,还是其他的第三方通知服务
station 分发任务
- 消息到达MQ在此姑且认作此消息一定会被消费
- 分发消息的RPC调用在保证消息到达MQ之后返回成功
推送任务
- 以uid+platforms粒度来走
- 粒度并没有粗到msg维度是因为很难控制每个uid的接收状态,且违背了以MQ做削峰流控的目的
- 粒度并没有细到uid+platform甚至uid+session是因为太细会太占用mq的资源
- 此粒度下如果发生部分失败,可以使用 投递新的缩减版消息 出去,并且ack之前的消息来进行部分重试。
- carrier消费此任务时若发现用户不在线,触发离线消息存储逻辑,且根据情况向MQ投递通知任务,通知任务的消费端是horn。
- carrier发现redis反馈用户在线,但实际不在线,也要负责修正数据
- carrier发现用户一直不作ack,也要负责直接kickout操作等等
一般任务(踢出/下发离线消息等)
- 一般是以uid+session粒度来走
- carrier消费此任务时候要负责存储的同步
carrier其他细节
- 保证消息到达是针对
某个uid+某个platform来判定,如果对应项不在线,则依据对应platform的离线存储策略对消息进行存储。 - 如果
某个uid在同一个platform有多个session,都会投递,但只要session_id最大的那个到达也就足够了 - 整个系统场景下,
某个uid重复登录同一个platform后,其他会话是会异步收到kickout消息的 mq收到的消息中都会带有retry_count,如果消息消费失败,也会ack,并且要将retry_count+1后重新投递出去- 自己实现的
retry_count机制是因为我们要根据不同的retry_count做一些事情,例如丢弃消息或者离线认定 - 自己实现的
retry_count机制也可以很方便的只重试一个大消费任务中的部分消费任务。 - 例如在收到
to_uid消息后,如果发现其中N个platform的投递或者离线存储成功,M个没成功,则发布retry给mq的时候就可以只带着对应的M个。 - 这样的好处: 因为
to_uid消息大部分是会消费成功的,又不会像to_uid_platform那么的细粒度,能增加吞吐量,又能避免因部分platform消费失败而产生的整个to_uid消息的重试。 - 最后超过一定
retry_count实在消费失败的话,就丢进dlq死信队列,等待报警发现,人工来处理了。
redis结构设计(设计上暂不支持redis集群)
连接信息
"msg/u:uid1/ss": {
"sid1":"platform1-bid1",
"sid2":"platform3-bid1",
}
- 没有不知
uid却要对某session直接进行操作的场景,所以只存如上结构即可,无需其他。 - 因为
session的状态是在boat里已经保存过了的,所以就不需要写入redis还做一次心跳机制了。 - 由于
boat里的session本来就是会随着生命周期调用connect和disconnect方法的,所以非异常情况下不会产生脏数据。 - 如果产生,也无非两种情况,皆可修正:
-
boat服务在etcd里已经不存在了,对应session被读取时修正即可。
-
boat服务还在,但是调用发消息方法时候其反馈说session是不存在的,修正即可。
弊端:
- 读取时候才有清除脏数据的可能,否则会永远存在。因为极端情况很少,本身数据量也不大。就不考虑了。
离线消息
// 存储消息,用两个字段,不用hash是为了一次就能批量获取消息内容
"msg/om:seq1/m": "xxx" // 消息内容
"msg/om:seq1/n": "100" // 消息引用计数,引用计数<=0时候要主动删除对应的这两条
// 某用户在某平台的离线消息 zset
// 分数皆为 timestamp ,即为 seq 的发出时间,相同 timestamp 内按 seq 字段排序
// 这样在获取时过滤过期和删除过期元素都很方便
"msg/u:uid1/p:platform1/oms": [
"seq1",
"seq2",
"seq3",
"seq4",
]
如何写入(需lua执行保证原子性)
- 根据消息发出时间计算出其过期时间
expireat = ts+expire ZADD msg/u:uid1/p:platform1/oms NX ts seq1-
- 如果返回0,说明已经记录过了
-
- 如果返回1,执行
INCR msg/om:seq1/n
- 如果返回1,执行
-
-
- 如果返回1,说明是刚刚创建的,所以要执行
EXPIREAT msg/om:seq1/n expireat和SET msg/om:seq1/m "xxxx" NX以及EXPIREAT msg/om:seq1/m expireat
- 如果返回1,说明是刚刚创建的,所以要执行
-
-
-
- 根据当前时间计算出未过期消息时间戳
expirets = now-expire
- 根据当前时间计算出未过期消息时间戳
-
-
-
- 直接执行
EXPIRE msg/u:uid1/p:platform1/oms expire,因为如果过了这个时间没有更新 EXPIRE 的话,肯定消息全特么都过期了,防止用户一直没操作而产生的过多的脏数据
- 直接执行
-
如何清理脏数据(需lua执行保证原子性)
- 一般在写入一批离线消息成功之后就要执行
- 执行一发
ZREMRANGEBYSCORE msg/u:uid1/p:platform1/oms -inf (expirets删除过期元素,减少下面的开支 - 而因为最大离线映射数做的清理,就需要修正引用计数了
- 查出来对应rank的数据列表
ZRANGE msg/u:uid1/p:platform1/oms 0 -max_offline_msg_count - 执行
ZREMRANGEBYRANK msg/u:uid1/p:platform1/oms 0 -max_offline_msg_count - 对列表中的数据挨个执行:
-
DECR msg/om:seq1/n
-
- 上一步若返回<=0,则执行
DEL msg/om:seq1/m msg/om:seq1/n)
- 上一步若返回<=0,则执行
如何读取(即为发送离线消息)
- 根据当前时间算出未过期消息时间戳
expirets = now-expire - 下面的往复执行,直到拿不到消息为止,拿不到时请执行一发
ZREMRANGEBYSCORE msg/u:uid1/p:platform1/oms -inf (expirets删除过期元素 -
ZRANGEBYSCORE msg/u:uid1/p:platform1/oms expirets +inf LIMIT 0 50获取头部50个未过期消息
-
- 执行
MGET msg/om:seq1/m msg/om:seq2/m拿到所有消息内容
- 执行
-
- 投递给客户端,若失败,则重试这次消费
-
- 若成功,则执行删除操作,下面三步需lua执行保证原子性,然后外部循环操作
-
-
ZREM msg/u:uid1/p:platform1/oms seq1
-
-
-
- 上一步若返回1,则执行
DECR msg/om:seq1/n
- 上一步若返回1,则执行
-
-
-
- 上一步若返回<=0,则执行
DEL msg/om:seq1/m msg/om:seq1/n)
- 上一步若返回<=0,则执行
-
弊端
- 在有效期内,对于一直不拉取离线消息并且没有产生新离线消息的用户,其列表会存在一部分已经过期的消息映射。这个基本上也无法避免了。
TODO或者备忘
- redis的存储结构要设计成支持集群的
- horn服务的雏形 (喇叭服务,在存储离线的同时要根据platform的需要决定是否生产通知消息,此服务负责消费)
- boat net listener没设置limit,这个要以后做下压力测试才能知道怎么设置合适
- 连接的tls
- 需要测试boat能单机连接多少,若10W,那就需要去测试10W的用户瞬间全部对station执行disconnect,redis是否撑得住,应该需要更好的法子。
- 存在离线存储的任务比拉取离线任务晚执行的可能性,如果有特别强的要求,可以考虑单uid+platform下的分布式锁保证顺序同步,但是遇见处理失败重试的场景下也没辙。
- 倘若boat服务没挂,但是和etcd有临时的断开,在断开时间里,消息会丢失认作离线,解决法子就是发现断开,立即关闭自身,有必要么?或者是在etcd重连之后广播一条离线消息下发任务,此节点的用户都来一发。有必要么?
- carrier的消费能力有些依赖于等待客户端ack的时间,所以可能要将客户端ack这一步设计成异步的,让
接到任务下发客户端等待ACK和接到客户端ACK之后的工作并告知MQ确认这两者放到一个额外的协程池里去控制吞吐。
 Directories
¶
Directories
¶
| Path | Synopsis |
|---|---|
|
Binary client is an example client.
|
Binary client is an example client. |
|
cmd
|
|
|
example
|
|
|
internal
|
|
|
pb/boatpb
Package boatpb is a generated protocol buffer package.
|
Package boatpb is a generated protocol buffer package. |
|
pb/mqpb
Package mqpb is a generated protocol buffer package.
|
Package mqpb is a generated protocol buffer package. |
|
pb/stationpb
Package stationpb is a generated protocol buffer package.
|
Package stationpb is a generated protocol buffer package. |
|
pb
|
|
|
authpb
Package authpb is a generated protocol buffer package.
|
Package authpb is a generated protocol buffer package. |
|
errorpb
Package errorpb is a generated protocol buffer package.
|
Package errorpb is a generated protocol buffer package. |
|
msgpb
Package msgpb is a generated protocol buffer package.
|
Package msgpb is a generated protocol buffer package. |
|
pushpb
Package pushpb is a generated protocol buffer package.
|
Package pushpb is a generated protocol buffer package. |
Click to show internal directories.
Click to hide internal directories.