 README
¶
README
¶

What is DevLake?
DevLake brings your DevOps data into one practical, customized, extensible view. Ingest, analyze, and visualize data from an ever-growing list of developer tools, with our open source product.
DevLake is designed for developer teams looking to make better sense of their development process and to bring a more data-driven approach to their own practices. You can ask DevLake many questions regarding your development process. Just connect and query.
See demo
Username/password:test/test. The demo is based on the data from this repo, merico-dev/lake.
Get started with just a few clicks
| Run DevLake |
User Flow
What can be accomplished with DevLake?
- Collect DevOps data across the entire SDLC process and connect data silos
- A standard data model and out-of-the-box metrics for software engineering
- Flexible framework for data collection and ETL, support customized analysis
User setup
- If you only plan to run the product locally, this is the ONLY section you should need.
- If you want to run in a cloud environment, click
 to set up. This is the detailed guide.
to set up. This is the detailed guide. - Commands written
like thisare to be run in your terminal.
Prerequisites
Launch DevLake
- Download
docker-compose.ymlandenv.examplefrom latest release page into a folder. - Rename
env.exampleto.env. For Mac/Linux users, please runmv env.example .envin the terminal. - Run
docker-compose up -dto launch DevLake.
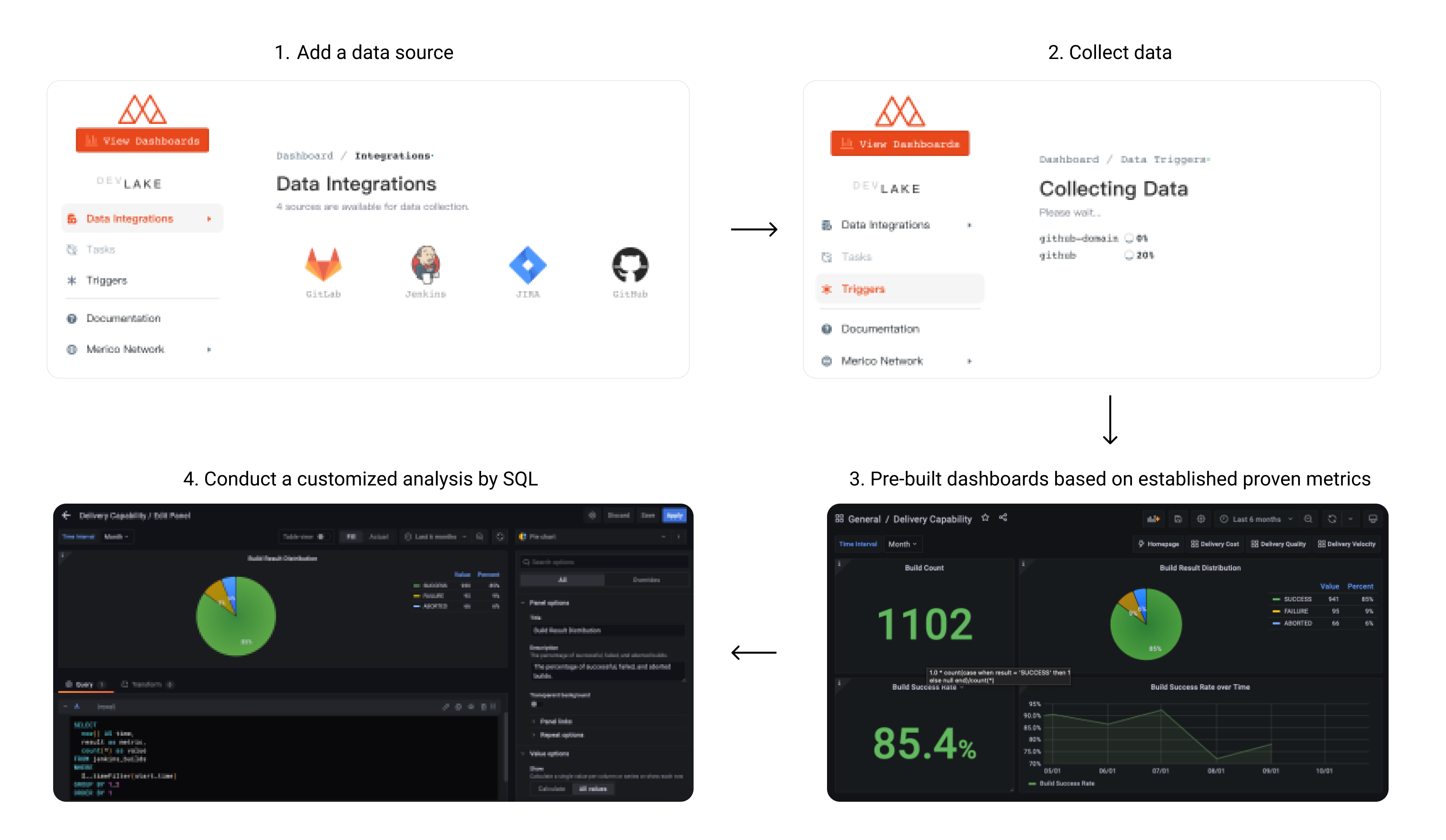
Configure data sources and collect data
-
Visit
config-uiathttp://localhost:4000in your browser to configure data sources. For users who'd like to collect GitHub data, we recommend reading our GitHub data collection guide which covers the following steps in detail.- Navigate to desired plugins on the Integrations page
- Please reference the following for more details on how to configure each one:
Jira
GitLab
Jenkins
GitHub - Submit the form to update the values by clicking on the Save Connection button on each form page
devlaketakes a while to fully boot up. ifconfig-uicomplaining about api being unreachable, please wait a few seconds and try refreshing the page.
-
Create pipelines to trigger data collection in
config-ui -
Click View Dashboards button in the top left when done, or visit
localhost:3002(username:admin, password:admin).We use Grafana as a visualization tool to build charts for the data stored in our database. Using SQL queries, we can add panels to build, save, and edit customized dashboards.
All the details on provisioning and customizing a dashboard can be found in the Grafana Doc.
-
To synchronize data periodically, users can set up recurring pipelines with DevLake's pipeline blueprint for details.
Upgrade to a newer version
Support for database schema migration was introduced to DevLake in v0.10.0. From v0.10.0 onwards, users can upgrade their instance smoothly to a newer version. However, versions prior to v0.10.0 do not support upgrading to a newer version with a different database schema. We recommend users deploying a new instance if needed.
Developer Setup
Requirements
- Docker
- Golang v1.17+
- Make
- Mac (Already installed)
- Windows: Download
- Ubuntu:
sudo apt-get install build-essential
How to setup dev environment
-
Navigate to where you would like to install this project and clone the repository:
git clone https://github.com/merico-dev/lake.git cd lake -
Install dependencies for plugins:
-
Install Go packages
go get -
Copy the sample config file to new local file:
cp .env.example .env -
Update the following variables in the file
.env:DB_URL: Replacemysql:3306with127.0.0.1:3306
-
Start the MySQL and Grafana containers:
Make sure the Docker daemon is running before this step.
docker-compose up -d mysql grafana -
Run lake and config UI in dev mode in two seperate terminals:
# run lake make dev # run config UI make configure-dev -
Visit config UI at
localhost:4000to configure data sources.- Submit the form to update the values by clicking on the Save Connection button on each form page
-
Visit
localhost:4000/pipelines/createto RUN a Pipeline and trigger data collection.Pipelines Runs can be initiated by the new "Create Run" Interface. Simply enable the Data Source Providers you wish to run collection for, and specify the data you want to collect, for instance, Project ID for Gitlab and Repository Name for GitHub.
Once a valid pipeline configuration has been created, press Create Run to start/run the pipeline. After the pipeline starts, you will be automatically redirected to the Pipeline Activity screen to monitor collection activity.
Pipelines is accessible from the main menu of the config-ui for easy access.
- Manage All Pipelines:
http://localhost:4000/pipelines - Create Pipeline RUN:
http://localhost:4000/pipelines/create - Track Pipeline Activity:
http://localhost:4000/pipelines/activity/[RUN_ID]
For advanced use cases and complex pipelines, please use the Raw JSON API to manually initiate a run using cURL or graphical API tool such as Postman.
POSTthe following request to the DevLake API Endpoint.[ [ { "plugin": "github", "options": { "repo": "lake", "owner": "merico-dev" } } ] ]Please refer to this wiki How to trigger data collection.
- Manage All Pipelines:
-
Click View Dashboards button in the top left when done, or visit
localhost:3002(username:admin, password:admin).We use Grafana as a visualization tool to build charts for the data stored in our database. Using SQL queries, we can add panels to build, save, and edit customized dashboards.
All the details on provisioning and customizing a dashboard can be found in the Grafana Doc.
-
(Optional) To run the tests:
make test
Temporal Mode
Normally, DevLake would execute pipelines on local machine (we call it local mode), it is sufficient most of the time.However, when you have too many pipelines that need to be executed in parallel, it can be problematic, either limited by the horsepower or throughput of a single machine.
temporal mode was added to support distributed pipeline execution, you can fire up arbitrary workers on multiple machines to carry out those pipelines in parallel without hitting the single machine limitation.
But, be careful, many API services like JIRA/GITHUB have request rate limit mechanism, collect data in parallel against same API service with same identity would most likely hit the wall.
How it works
- DevLake Server and Workers connect to the same temporal server by setting up
TEMPORAL_URL - DevLake Server sends
pipelineto temporal server, and one of the Workers would pick it up and execute
IMPORTANT: This feature is in early stage of development, use with cautious
Temporal Demo
Requirements
How to setup
- Clone and fire up temporalio services
- Clone this repo, and fire up DevLake with command
docker-compose -f docker-compose-temporal.yml up -d
Project Roadmap
- Roadmap 2022: Detailed project roadmaps for 2022.
- DevLake already supported following data sources:
- Supported engineering metrics: provide rich perspectives to observe and analyze SDLC.
How to Contribute
This section lists all the documents to help you contribute to the repo.
- Architecture: Architecture of DevLake
- Data Model: Domain Layer Schema
- Add a Plugin: Guide to add a plugin
- Add metrics: Guide to add metrics in a plugin
- Contribution guidelines: Start from here if you want to make contribution
Community
License
This project is licensed under Apache License 2.0 - see the LICENSE file for details.
 Documentation
¶
Documentation
¶

There is no documentation for this package.