 README
¶
README
¶
OWID-API 🌎
This project is a Proof of Concept which implements a GraphQL API for exploring OurWorldInData (OWID) datasets.
OWID is a scientific online publication that focuses on large global problems such as poverty, disease, hunger, climate change, war, existential risks, and inequality. The goal of OWID is to make the knowledge on the big problems accessible and understandable. As they say on their homepage, Our World in Data’s mission is to publish the “research and data to make progress against the world’s largest problems”.
Demo
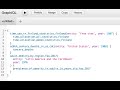
How does OWID-API work?
The data in OWID is stored as CSV files. Every dataset has schema information (see example here). Every dataset has 2 keys to access to the different variables. These 2 keys are entity and year. The first might be whatever dimension of the information like country, person names and so on.
OWID-API implements a GraphQL Schema which is generated from the metadata which and it fetches the information from the CSV files.
The Schema and Server need to be re-generated when there is a new update in the datasets. Currently, this is a manual process. There are 2 step to re-generate:
- Generate Schema
- Generate Server
You can get the current schema executing the following queries:
- Get Full Schema. See here
- Get All Dataset names. See here
- Get the plain text from repo. See here
- Navigate Schema from Playground Documentation Explorer
Generate Schema
There is one Go function to generate the schema. This process read all files datapackage.json from this repo and create a new file schema.graphql.
> make schema
Generate Server
Finally the following command will generate the server using gqlgen.
> make server
Usage
There are 2 ways to explore OWID datasets: Rest API or GraphiQL Playground.
Rest API:
POST https://owid-api.vercel.app/api/query
{
"query": "{\n\ttime_use_in_sweden_statistics_sweden(entity: \"Gainful employment\", year:1990){ time_allocation_weekday_women \n\t}}"
}
For now, no authentication required.
Playground:
Endpoint: https://owid-api.vercel.app/api/playground
For example: query 2 datasets, time_use_in_sweden_statistics_sweden AND time_use_in_finland_statistics_finland
{
time_use_in_sweden_statistics_sweden(entity: "Gainful employment", year: 1990) {
time_allocation_weekday_women
}
time_use_in_finland_statistics_finland(entity: "Free time", year: 1987) {
time_allocation_all_statistics_finland
time_allocation_women_statistics_finland
}
}
Response
Either Rest API or Playground query, the response is always a GraphQL representation. See here for more details.
Schema Design
Naming
When generating schema, naming dataset and variables is using the same normalizer which applies the same rules, like toLower or replace(...).
This is an initial approach and in next iterations it should be improved in order to handle shorter naming and more descriptive since for example:
total_value_of_exports_by_country_to_world_percgdp_owid_calculations_based_on_fouquin_and_hugot_cepii_2016_and_other_sources is clearly not really easy to remember or deal with.
Types
Another decision was the types of each variable. A first data inspection shows that all variables, except entity are numbers, and since some of them are decimals, the type for all variables is Float.
Resolvers
Resolvers are generated automatically as part of the Server Generation. Since there are lots of datasets, the output file (schema.resolvers.go) is huge. To implement each dataset resolver is hard to the decision was to use a custom template and common and very simple logic. In order to do it a custom_resolver.goptl template is copied where the plugin is located. Then the server can be generated. The result of this is schema.resolvers.go.
Arguments
This project assumes that every dataset has 2 arguments: Entity:String and Year:Int.
Example:
Query:
{
time_use_in_finland_statistics_finland(entity: "Free time", year: 1987) {
time_allocation_all_statistics_finland
time_allocation_women_statistics_finland
}
o20th_century_deaths_in_us_cdc(entity: "United States", year: 1908) {
cancers_deaths
}
adult_obesity_by_region_fao_2017(
entity: "Latin America and the Caribbean"
year: 1976
) {
prevalence_of_obesity_in_adults_18_years_old_fao_2017
}
}
Response
{
"data": {
"time_use_in_finland_statistics_finland": {
"time_allocation_all_statistics_finland": 348.24182,
"time_allocation_women_statistics_finland": 334.53537
},
"o20th_century_deaths_in_us_cdc": {
"cancers_deaths": 27617
},
"adult_obesity_by_region_fao_2017": {
"prevalence_of_obesity_in_adults_18_years_old_fao_2017": 7.1
}
}
}
Architecture
...TBD...
Roadmap
As mentioned at the beginning, this started as a Proof of Concept. So a roadmap definition is just a vague idea on what I would like to learn and build. So I would start naming the following list of features:
- Schema generation
- Server generation
- Playground and Rest API
- Full Schema for real
- Data fetcher for ALL datasets
- Data fetcher automation for new datasets
- Naming improvements (for datasets and variables)
- Datasets updates automation
- Local sources (folders, files, url) for testing purposes
- Split large files (e.g. resolvers)
- Authentication?
- More and better logging
- Testing, testing, testing
- Improve client ID in metrics (user agent + ip?)
- Metrics
- Serve real-time data from different sources
- ...to be continued...