 README
¶
README
¶
Travel time information system

![]()

This repository is part of bigger conceptual system that provides travel time estimations based on mobile devices identification.
Explanation:
In general public there is high saturation of Bluetooth devices. When BT device pass through paths around city special detectors grabs device MAC address with timestamp. There is great concern taken about privacy and MAC address is hashed before it is passed down through the system. Then system tries to figure out what is current travel time between points based given statistically meaningful amount of data.
NOTE: Given similar in nature ANPR data similar thing could be achieved even with greater accuracy.
Demo
This screencast presents basic functionality currently available: traffic simulator and events retriever.

Message bus
Repository provides server for collecting and querying events received from mobile devices detectors. Additionally there is client tool for simple traffic flow simulation.
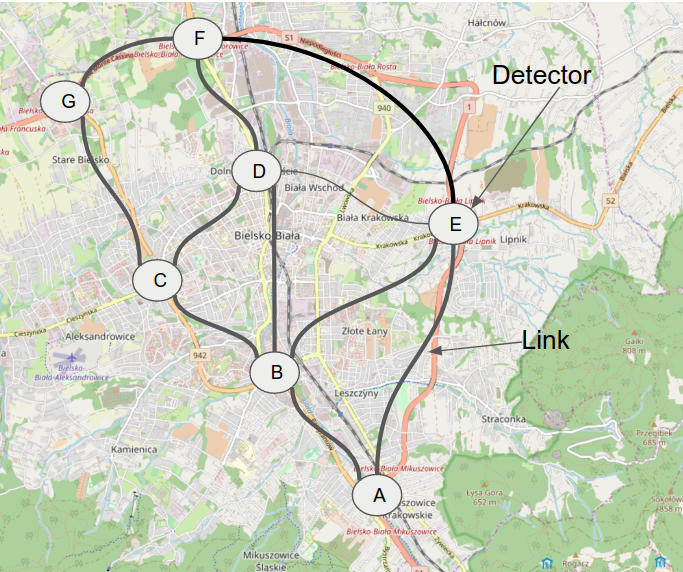
Bluetooth / WiFi / IMSI detectors aka. detector of mobile devices
Detectors are devices located around city, highways etc. capable for intercepting Bluetooth, WiFi, MAC addresses and IMSI ids from passing travelers.
NOTE
This service is purely conceptual however, I did work with similar system which was capable of intercepting Bluetooth MAC addresses. Adding IMSI catcher is purely theoretical since they are basically illegal without special permissions.
Technical details
This section provides some extra technical details.
Architecture
This service in majority follows flattened Clean Architecture as described by Uncle Bob. There is nice example written in Go.
Services
There are 3 services available:
- collector - responsible for collecting all detector data and any mutable operations,
- query - responsible for making query type requests,
- *healthcheck - grpc healthcheck used by kubernetes to check POD status. However not doing anything meaningful at this stage.
In principle there are components under cmd which provide easy way to compose services above into
servers. Real main function is encapsulated inside Runner interface which should be customized
according to desired server shape. Each service in turn provides easy way to attach itself
to run group
Server
There is one server cqserver (collector-query-server) provided which is composed of all above services. Since only ETCD backend implementation
are now available it's quite hard wired now. However existing architectrue allows easily to introduce repository
factory methods to achieve full backend independence.
Configuration
Example configuration could be found in root directory <service_name>.cofnig.yaml. For
more details please reference either calling a binary release with --help flag or going
directly into cmd/<service>/main.go and inspecting config structure.
Example for cqserver:
Usage of main:
--collector_port string grpc collector port (default ":9000")
--query_port string grpc query port (default ":8000")
--healthcheck_port string grpc health check port (default ":5000")
--etcd.prefix string etcd app prefix (default "tdc")
--etcd.endpoints string... etcd endpoints (default "http://127.0.0.1:2379")
--config_file string
-h, --help print this help menu
Service could be also configured via environment variables, please reference gonfig package.
Deployment
Deployment assumes existence of etcd cluster with endpoints ["http://etcd-0:2379", "http://etcd-1:2379", "http://etcd-2:2379"].
This could be achieved easily by deploying etcd-operator.
Deployment also assumes existence of cert-manager
to provide TLS certificates for domains. Expected issuer in this case is http-issuer.
Helm chart is stored under deployment directory with subdirectories which are named after corresponding server name.
Local setup
Please use docker-compose up then connect with client with defaults.
ETCD repository data model
Storing events from detectors would include detector ID as root path then bucketing based on unix timestamp with bucket size of 100 seconds:
${namespace}/detectors/<detector_id>/<unix_timestamp/100>/<ulid>.<device_id>
value: {"timestamp": "<unixNano>"} # storing precise time
Buckets are deterministic values derived from unix timestamp. Consecutive timestamp values would look like following:
1563568100 => 2019-07-19T20:28:20+00:00
1563568200 => 2019-07-19T20:30:00+00:00
1563568300 => 2019-07-19T20:31:40+00:00
This allows for easy time range queries.
Additionaly there is ulid concatenated with device ID to ensure no key conflicts, even if events overlap with millisecond accuracy and enables lexicographical sorting by time (eg. can retrieve latest events).
Thanks to unix timestamp usage we could avoid many problems regarding timezones, leap years, daylight saving time changes etc.
Since detectors are representing directed graph of traffic flows we can limit complexity of calculating all graph connections by explicitly declaring links between detectors by listing it's incoming traffic peers.
${namespace}/links/<dest_detector_id>/<src_detector_id#0>
${namespace}/links/<dest_detector_id>/<src_detector_id#1>
${namespace}/links/<dest_detector_id>/<src_detector_id#2>
value: {"max_seconds": "600"} # maximum travel time which is taken under consideration
Worker which would calculate travel times for given detector should acquire
<dest_detector_id> to reserve given batch of work since number of source detectors
should be well beyond 10 resulting in fair amount of work for single run.
Installation of etcdctl
For manual inspection of ETCD one could install this tool with:
go get github.com/coreos/etcd/etcdctl
cd <go-dir>/src/github.com/coreos/etcd/
git checkout -b v3.3.4
CFLAGS="-Wno-error" go install .
Use with following flag export ETCDCTL_API=3
12factor
- Codebase - all services are in one place constructing monorepo for group of related servers,
- Dependencies - vgo,
- Config - configuration is handled with gonfig which allows easily for environment variables override typical for kubernetes environment. Order: defaults, config, ENV, command line.
- Backing Service - there is
Repositoryinterface used as proxy for backing service, ETCD implementation is provided. This allows for backend swaps. - Build, Run, Release - semantic versions, goreleaser and docker builds,
- Stateless Processes - state is kept away from servers in
Repository - Port Binding - either using docker-compose or helm chart to deploy it provides discovery with service name,
- Concurrency - the way
cmdis constructed allows for separation ofcollectorandqueryservices into it's own servers. - Disposability - containers, present :),
- Dev-Prod Parity - helm chart allows to deploy to Prod and Test in consistent way, just change your
FQDN, - Logs - logs are thrown into
stdout, pattern which is widely accepted inkubernetesworld, well then DevOps need to configurefluentdor if we are on GCP just go toStackdriver. - Admin Processes - since setup is repository agnostic all credits regarding migrations should be credited on particular implementation side.
Is this service cloud native?
Yes, it relies entirely on containerization and it designed to be easy to split into smaller services which can be scaled individually.
Can I use eventstore ?
Yes, if Repository interface implementation for eventstore can be provided. In general backend assumes
persistent, time sorted, time range queryable storage. In some cases simple key value retrieval is required.
How to access service while it's deployed on kubernetes cluster?
When you get helm chart running in cluster eg. with cqserver it provides single endpoint with FQDN specified
in values.yaml. Since we run separate services on single pod this way, ingress need to know how to split
traffic to each port. There are http routes provided named after grpc services which allow this logic to execute.
For client you need to run something like following:
$ mbcli --collector_host example.com --query_host example.com <other_options>
TODO
- inject versions to binary releases with build time variables,
- helm chart may provide init containers to check if given backend is alive,
- implement other service methods of collector and query,
- design ETCD storage and workers for processing rolling window travel time information,
- e2e tests,