 README
¶
README
¶
![]()
Easy, advanced inference platform for large language models on Kubernetes
![]()

llmaz (pronounced /lima:z/), aims to provide a Production-Ready inference platform for large language models on Kubernetes. It closely integrates with the state-of-the-art inference backends to bring the leading-edge researches to cloud.
🌱 llmaz is alpha now, so API may change before graduating to Beta.
Architecture
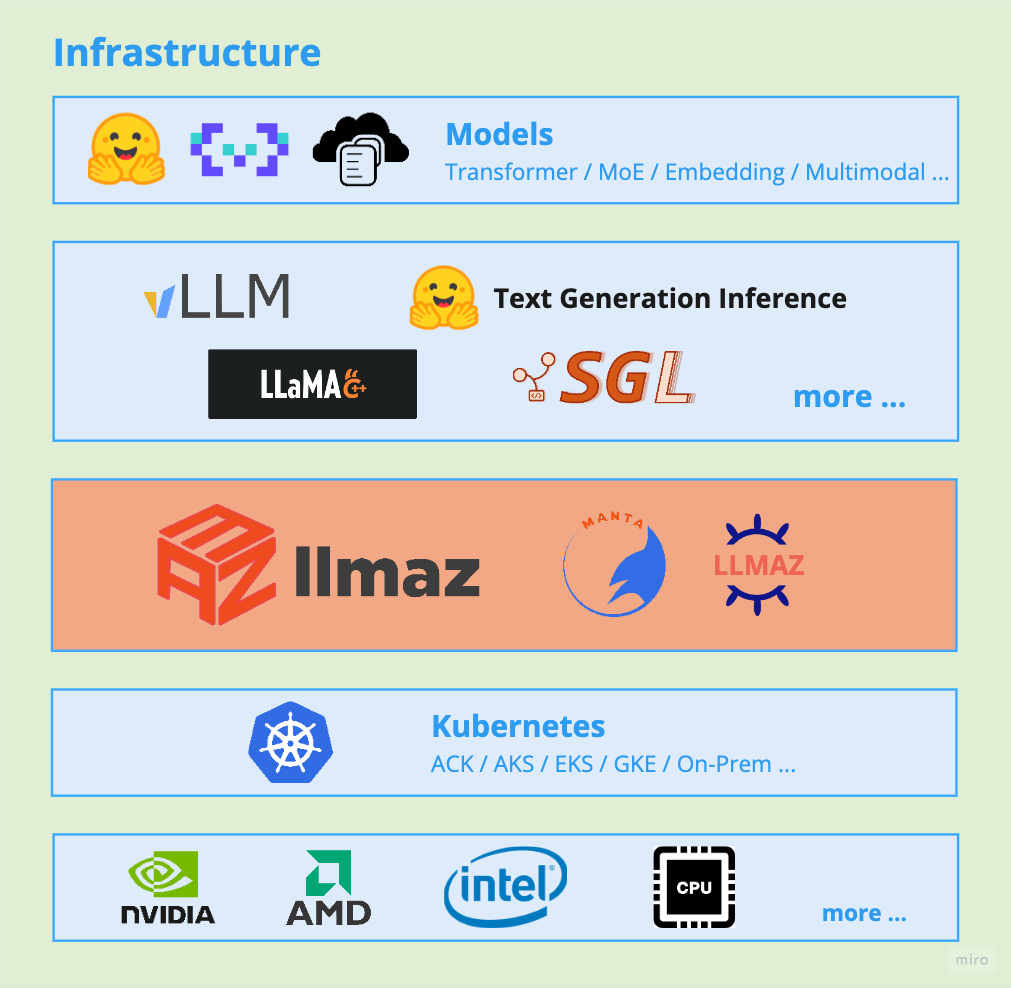
Features Overview
- Easy of Use: People can quick deploy a LLM service with minimal configurations.
- Broad Backends Support: llmaz supports a wide range of advanced inference backends for different scenarios, like vLLM, Text-Generation-Inference, SGLang, llama.cpp. Find the full list of supported backends here.
- Efficient Model Distribution (WIP): Out-of-the-box model cache system support with Manta, still under development right now with architecture reframing.
- Accelerator Fungibility: llmaz supports serving the same LLM with various accelerators to optimize cost and performance.
- SOTA Inference: llmaz supports the latest cutting-edge researches like Speculative Decoding or Splitwise(WIP) to run on Kubernetes.
- Various Model Providers: llmaz supports a wide range of model providers, such as HuggingFace, ModelScope, ObjectStores. llmaz will automatically handle the model loading, requiring no effort from users.
- Multi-hosts Support: llmaz supports both single-host and multi-hosts scenarios with LWS from day 0.
- Scaling Efficiency: llmaz supports horizontal scaling with HPA by default and will integrate with autoscaling components like Cluster-Autoscaler or Karpenter for smart scaling across different clouds.
Quick Start
Installation
Read the Installation for guidance.
Deploy
Here's a toy example for deploying facebook/opt-125m, all you need to do
is to apply a Model and a Playground.
If you're running on CPUs, you can refer to llama.cpp, or more examples here.
Note: if your model needs Huggingface token for weight downloads, please run
kubectl create secret generic modelhub-secret --from-literal=HF_TOKEN=<your token>ahead.
Model
apiVersion: llmaz.io/v1alpha1
kind: OpenModel
metadata:
name: opt-125m
spec:
familyName: opt
source:
modelHub:
modelID: facebook/opt-125m
inferenceConfig:
flavors:
- name: default # Configure GPU type
requests:
nvidia.com/gpu: 1
Inference Playground
apiVersion: inference.llmaz.io/v1alpha1
kind: Playground
metadata:
name: opt-125m
spec:
replicas: 1
modelClaim:
modelName: opt-125m
Verify
Expose the service
By default, llmaz will create a ClusterIP service named like <service>-lb for load balancing.
kubectl port-forward svc/opt-125m-lb 8080:8080
Get registered models
curl http://localhost:8080/v1/models
Request a query
curl http://localhost:8080/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "opt-125m",
"prompt": "San Francisco is a",
"max_tokens": 10,
"temperature": 0
}'
More than quick-start
If you want to learn more about this project, please refer to develop.md.
Roadmap
- Gateway support for traffic routing
- Metrics support
- Serverless support for cloud-agnostic users
- CLI tool support
- Model training, fine tuning in the long-term
Community
Join us for more discussions:
- Slack Channel: #llmaz
Contributions
All kinds of contributions are welcomed ! Please following CONTRIBUTING.md.
 Directories
¶
Directories
¶
| Path | Synopsis |
|---|---|
|
api
|
|
|
core/v1alpha1
Package v1alpha1 contains API Schema definitions for the v1alpha1 API group +kubebuilder:object:generate=true +groupName=llmaz.io
|
Package v1alpha1 contains API Schema definitions for the v1alpha1 API group +kubebuilder:object:generate=true +groupName=llmaz.io |
|
inference/v1alpha1
Package v1alpha1 contains API Schema definitions for the inference v1alpha1 API group +kubebuilder:object:generate=true +groupName=inference.llmaz.io
|
Package v1alpha1 contains API Schema definitions for the inference v1alpha1 API group +kubebuilder:object:generate=true +groupName=inference.llmaz.io |
|
client-go
|
|
|
clientset/versioned/fake
This package has the automatically generated fake clientset.
|
This package has the automatically generated fake clientset. |
|
clientset/versioned/scheme
This package contains the scheme of the automatically generated clientset.
|
This package contains the scheme of the automatically generated clientset. |
|
clientset/versioned/typed/core/v1alpha1
This package has the automatically generated typed clients.
|
This package has the automatically generated typed clients. |
|
clientset/versioned/typed/core/v1alpha1/fake
Package fake has the automatically generated clients.
|
Package fake has the automatically generated clients. |
|
clientset/versioned/typed/inference/v1alpha1
This package has the automatically generated typed clients.
|
This package has the automatically generated typed clients. |
|
clientset/versioned/typed/inference/v1alpha1/fake
Package fake has the automatically generated clients.
|
Package fake has the automatically generated clients. |
|
hack
|
|
|
test
|
|
|
util/format
Package format is an extension of Gomega's format package which improves printing of objects that can be serialized well as YAML, like the structs in the Kubernetes API.
|
Package format is an extension of Gomega's format package which improves printing of objects that can be serialized well as YAML, like the structs in the Kubernetes API. |