 README
¶
README
¶
Timings
| day | time |
|---|---|
| 24 | 0.6 |
| 1 | 0.7 |
| 10 | 0.7 |
| 16 | 0.7 |
| 2 | 0.7 |
| 6 | 0.7 |
| 7 | 0.7 |
| 13 | 0.9 |
| 3 | 0.9 |
| 4 | 1.0 |
| 9 | 1.0 |
| 12 | 1.1 |
| 17 | 1.1 |
| 8 | 1.2 |
| 11 | 2.3 |
| 22 | 3.4 |
| 14 | 3.8 |
| 5 | 4.4 |
| 21 | 11.8 |
| 18 | 14.1 |
| 20 | 23.8 |
| 25 | 30.8 |
| 15 | 41.8 |
| 19 | 49.1 |
| 23 | 51.5 |
| total | 248.8 |
end-to-end timing for part1&2 in ms - mbair M1/16GB - darwin 23.0.0 - go version go1.21.3 darwin/arm64 - hyperfine 1.17.0 - 2023-10-16
Installation and benchmark
- optionnally install gocyclo
- install hyperfine
git clonethis repository somewhere in your$GOPATHexportenvar$SESSIONwith your AoCsessionvalue (get it from the cookie stored in your browser)$ cd 2022$ make$ make runtime && cat runtime.md- explore the other
Makefilegoals
Day 1
For the first day of aoc2021, I've written and submitted the results in less than 5mn but it only got me in the top 3k ranks, wow!
We have to count, in a serie of numbers, how many time there's an increase between two successive numbers. I've got nothing to say about the problem: it's all about composing speed.
For part2, I chose to use three variables (say instead of an array) because the simpler, the better: between two readable and efficient syntaxes, I always try to write the simplest form. That said, here, three is the limit before the array form being better.
Speaking of this problem simplicity, it's nonetheless the perfect occasion to compose a well written program. I mean we have to use a naming and a style made to last: the construct for input.scan(){} is to be found as it is in the Go manual by Donovan & Kernighan (D&K). It's efficient because it states simply, clearly and shortly what the coding intention is.
A word about the variable old: here we have a previous and a current value to compare, we could use last/prev and cur. As I find same length names nice to manipulate when I edit a program, you'll often see me using old/cur/nxt and it usually helps to understand what's going on at first sight.
Finally, we can also feel the minimalism of the Go language: I have to define MaxInt. I try to do this in the idiomatic way even if it's not: I'm supposed to link to the math library only to import this constant. As it feels like a C style regression to me, I don't!
Day 2
In competitive programming, when confronted to simulation problems, we frequently can do something without having to perfectly parse the inputs. Here, input lines are made of a command followed by a single number argument: 1) as first letters of legit commands are all different, it suffices to read line[0] (f, u, d) to decode a command. 2) if we split any input line on its central space, the number will go to the right.
Day 3
I love Go utf8 support, greek γράμματα and old school low-level problems: I pleased myself writing this solution. This program only supports 12bits numbers. With a little effort it could support dynamic widths but, again, I aimed for simplicity: the constant width is easy to edit if inputs are ever to change.
I've written a single rate() function to solve part2. It executes its parameterized workflow according to a modal argument gas. As this choice is binary, gas is naturally a boolean. I use the constants O2 and CO2 in order to improve readability.
rate() computes (in a string representing a binary number) the most/least popular bits of inputs (also a bunch of strings), it returns the result of strconv.ParseInt() from the standard library. Instead of handling the possible error right after calling ParseInt(), I let it float up the calling stack until I need to address it: here it's just before sending the conversion down to a channel.
I tend to (gracefully) handle errors only when they can't go up in the calling stack: usually, they have a clear meaning by then. That said, unless I have to, I won't do any error handling during competitive programming sessions.
As the computations (part1, part2/[o2, co2]) are clearly independent, I use goroutines concurrency: it's almost free and the speedup worth it!
Finally, popcnt is a CPU instruction that counts how many bits are set to one in an integer. H.S. Warren Jr. made the concept famous in Hacker's Delight. The underlying concept is the Hamming weight and I use popcount or popcnt whenever I have to count a population of some sort.
Day 4
Here, the solution has to play loto: it must keep track of drawn numbers on the cardboards of its deck.
To model a cardboard, I use a structure that groups:
- 5 row adders
- 5 column adders
- 1
mapof numbers and their position on the board
ie. this board (3x3 instead of 5x5):
| 1 | 2 | 3 |
| 4 | 5 | 6 |
| 7 | 8 | 9 |
is represented like this:
| 12 | 15 | 18 | |
| 6 | . | . | . |
| 15 | . | . | . |
| 24 | . | . | . |
{
1: (1, 1), 2: (1, 2), 3: (1, 3),
4: (2, 1), 5: (2, 2), 6: (2, 3),
7: (3, 1), 8: (3, 2): 9: (3, 3),
}
When 3 is drawn, we have to:
- read
3row and column in themap:{1, 3} - delete
3from themap - update the sum of row
1:6-3 = 3 - update the sum of column
3:18-3 = 15
| 12 | 15 | 15 | |
| 3 | . | . | . |
| 15 | . | . | . |
| 24 | . | . | . |
{
1: (1, 1), 2: (1, 2), 3: (1, 3),
4: (2, 1), 5: (2, 2), 6: (2, 3),
7: (3, 1), 8: (3, 2): 9: (3, 3),
}
If any count falls to zero, the corresponding line or column is a win, it's bingo! If all the counts are zero (or if the map is empty), the board itself is a win.
For each bingo, summing the remaining numbers on the board amounts to either sum line or column adders.
The chosen data structure helps solve the problem by simply and efficiently supporting all required operations during a loto draw. As there is no duplicate number in inputs I don't even bother purging the map in the biff() function.
We don't need to use a stack to solve this problem: one could actually memorise the first and the last board to win.
I choose to use one because my program is more general this way: the stack stores the game history and it becomes easy to answer any question on the relative order of the winning boards. ie. at any time of a draw, the last winning board is on the top of the stack.
On the practical side, there's apparently a problem: In Go resizing a slice while iterating on it is undefined (it doesn't work): we can't delete winning boards form our deck, the moment they win... We can overcome this limitation if 1) we don't change the slice size while iterating on it and 2) we update the slice before or on the current pointer. Here between the lines 88~97, we see, for each drawn number that a winning board goes to the stack while others go back to the deck. Whenever we finish a pass on our deck, the slice can be resized to the remaining cards.
It works because instead of deleting winning boards, we put the others back in the deck. It's easy to see that i from the line 88 will always be lesser or equal than the implicit index of line 89. Finally, the relative order of the boards is preserved (it's usually a good property that comes for free here).
Day 5
If the lines had other slopes than ±π/4 we could have used bresenham!
Day 6
It's when I ran the problem by hand that I saw the daily populations rotating toward left with a peculiar addition between day 0 and 6. I find the accompanying python very yummy!
Day 7
Surely one of the nicest contributions on reddit this year!
For the record, when coding part1 I mistakenly chose the mean instead of the median. When, later, reading part2 I recognised the mean from before. Sometime, in competitive programming, we have to follow hunches so I wrote the solution full steam and without totally comprehending it. I had my second star by flooring the mean but wasn't sure about it (this was random computing after all). The next morning, when I read the paper it made my day!
Day 8
Sadly this day log has been lost
Day 9
I tackled part2 with Hoshen-Kopelman that I've used previously with success. The algorithm exploits the reordering properties of a standard Union-Find (here is sedgewick's lecture about it). It's able to overcome connected components contouring problems: when north-west flood filling a grid the result can show concavity and numerous irregularities (corner cases) that are difficult to acccount for. When using Hoshen-Kopelman one can achieve the perfect output in linear time, just like my solution for this day \o/.
Day 10
This problem is so classical that it even has a name: bracket matching. It is solved in every IDE usually with a stack.
Instead of pushing an opening symbol to the stack, pushing the corresponding closing one simplifies the matching that comes later (ligne 50).
Day 11
This is a direct application of dynamic programming combined with multiple buffering.
Day 12
This is a direct application of depth-first search on a graph. It surely will be given as an exercise of the baccalauréat of code, in the futur.
<EDIT> While exploring Go vs. Rust performances, I came to Tim Visée's work. For this problem, he has gone the extra mile of 1) putting the strings aside to have a full integer problem, 2) building an adjacency matrix and 3) use a stack-based iterative dfs. All in all, these optimizations also work for Go: the runtime of this problem vanished from 44.3ms to 1.7ms. That said, if you don't feel comfortable studying this (expert) version, pull the old one instead...
Day 13
Between the lines of the story, this problem hides two basic techniques: one from coding theory and the other from computer graphics. Some dots are given as vectors. After having transformed (decoded) them, we need to display the result on the screen (rasterise).
I've coded this display as a Raster Scan Display. It is based on an aabb spanning over a framebuffer. Namely, in order to obtain an image, I rasterise the dots into this buffer.
Thanks to one of my teammates, during a review, I discovered that the undefined character � of extended ASCII is the brightest of all: that's why it's the lighten-up pixel value.
When I'm using well known abstractions, I shorten the coding time: I ease writing, debuging and editing. I know beforehand what's need to be done and how, mainly because there's plenty of documentation. If I use an abstraction enough, I end up knowing it by heart.
I've found this problem really entertaining.
❯ cat input.txt| ./aoc13.2
� ��� ���� �� ��� �� ���� � �
� � � � � � � � � � �
� � � ��� � ��� � ��� ����
� ��� � � � � � � � �
� � � � � � � � � � � � �
���� � � � �� ��� �� ���� � �
Side Note
When solving this problem, one finds that for a moving dot $p_{n}(x,y)$ during the $nth$ symetry of axis $a$, one have:
$$x_{p_{n+1}} = 2*x_{a} - x_{p_{n}}$$
or
$$y_{p_{n+1}} = 2*y_{a} - y_{p_{n}}$$
We can show how with möbius homogeneous coordinates.
In this system, the following matrices represent a translation of vector $\vec{u}(x, y)$, a symetry around $x$ axis (horizontal folding) and one around $y$ axis (vertical folding):
$$\begin{pmatrix} 1 & 0 & x_{u}\\0 & 1 & y_{u}\\0 & 0 & 1\\ \end{pmatrix} \begin{pmatrix} 1 & 0 & 0\\0 & -1 & 0\\0 & 0 & 1\\ \end{pmatrix} \begin{pmatrix} -1 & 0 & 0\\0 & 1 & 0\\0 & 0 & 1\\ \end{pmatrix}$$
Folding the sheet in two around axis $x=a$ amounts to:
- translate some dots with $(-a, 0)$ (to have them in a self-centered system),
- obviously, move them symetrically around the $y$ axis and
- translate them back with $(a, 0)$ (to have them back in their original system)
That is:
$$Tr_{a}(x).S_{y}(x).Tr_{-a}(x)$$
It is read from right to left and we can't change the order of these transformations. To transform a point one writes:
$$\begin{pmatrix} 1 & 0 & x_{a}\\0 & 1 & 0\\0 & 0 & 1\\ \end{pmatrix} . \begin{pmatrix} -1 & 0 & 0\\0 & 1 & 0\\0 & 0 & 1\\ \end{pmatrix} . \begin{pmatrix} 1 & 0 & -x_{a}\\0 & 1 & 0\\0 & 0 & 1\\ \end{pmatrix} . \begin{pmatrix} x_{p}\\y_{p}\\0 \end{pmatrix}$$
Which brings the sought after formula:
$$x_{p_{n+1}} = 2*x_{a} - x_{p_{n}}$$
For problems in which all points are moving, this technique becomes really powerful: usually, it's easy to combine (say multiply) all the transformations into a single matrix before massively applying it (O(T+N)) instead of computing each transformation, in turn, for each point (O(T*N))…
Day 15
When using Dijkstra algorithm there's not much left to say: it builds a kind of data mycelium while decomposing (nibbling) the problem. To guide this search, we can use a priority queue. Here i'm using the one from the Go standard library.

Day 16
To solve this problem, I'm using the really nice bearmini's bitstream-go library combined with the standard Go math/big.
These libraries implement standard interfaces like Reader and Writer. Thanks to these interfaces, filters (functions) share the same prototypes as the low-level functions in front of which they're laid. This enables us to build data pipelines like the one on line 161.
In part2, I implement an accumulator machine that evaluates commands encoded in a BITS datagram.
Pedantic Note:
I believe the problem mistakenly states BITS packet instead of datagram.
Day 17
Sadly this day log has been lost
Day 18
The problem deal with a peculiar kind of binary trees which have a pair of operations defined on them: the snailfish numbers.
In these trees, leaves contain an integer and are linked between them and to the root by internal nodes. An internal node contains solely a pair of links. This data structure is known to operate a classification like in k-d trees or B-trees.
I pump spaces into the input line until I can get every bracket and number the first time I tokenise it. newPair() is a variadic function.
The explode() operation uses the flatten form of the tree to update neighboring leaves.
During reduce(), I use binary flags to synchronise the workflow (done ligne 174~184).
Finally, having profiled my first version, I found part2 to be waiting for to hint the kernel about its memory usage a lot. I took the step of making part2 concurrent with a producer which computes snailfish numbers and pass them to consumers that compute their magnitudes. In the main routine, I collect and filter the results. All of this made this program runtime go down from 651ms to 245ms!
<EDIT> Everything said before is true but too complicated. When rethinking this problem I found that maintaining two arrays: one for the integers and one for their depths made everything to fall in place gracefully except for the magnitude computation. Nonetheless, this was acceptable. I have spent almost 24 hours on this problem only and rewriting it entirely made my collection run in under a second on my mbair M1 \o/.
Day 19
The problem can be frightening at first sight.
I resort to a very mecanical solution. I have precomputed rotations and modelised them in two parts: the axis order and their signs. As usual when doing this kind of stuffs my brain started swelling to the point I used a matchbox and a pen in desperation of getting the precomputation right.
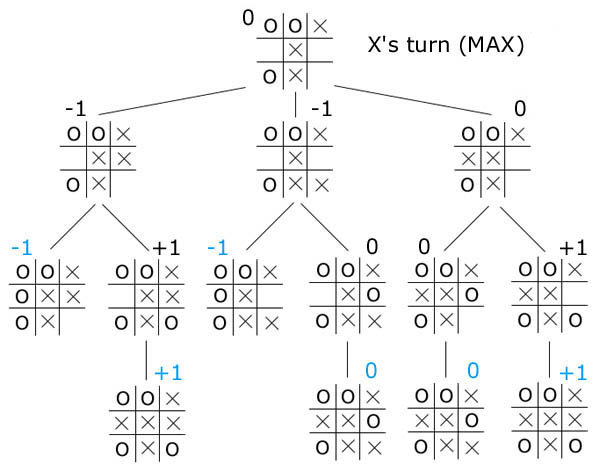
Day 21
The problem describes a two-player board game. In part2 the game is somehow augmented to 27 possible moves at each turn but is still tractable because the winning score is low (21).
The recursive algorithm that solves this game is the first I learned when studying game theory. It's about decision making and is named minimax. In this kind of game, we can exploit to our advantage the idea that a game is a first move from one player followed by a subgame in which the other player starts. And we repeat until victory.
Here minimax is performing well because on one hand, there's no secrecy (secret die roll or hidden position), the game information is complete and on the other, the victory of one player is the defeat of the other, this is a zero-sum game. As the moves come from a small combination of dice and that we can generate all of them, we can solve this game ie. pre-compute all the possible games.
A gamestate is a vector (c1, s1, c2, s2) with c1 and s1 the position and score of p1 player. A victory is a gamestate in which one the two scores s1 or s2 is over 21. There's no move beyond a victory, the game is over. A game is a set of gamestates linked by moves from a starting position to a victory.
Minimax solves the game by starting with (c1, 0, c2, 0) and playing one move for p1. If the move leads to victory, the game is over and p1 won. If not, the algorithm updates the current gamestate to (c'1, s'1, c2, s2) and plays all the possible subgames from (c2, s2, c'1, s'1) (ie. a subgame in which p2 has to move first). When done, we resume the top-level search from the next move of p1.
By doing this recursively, Minimax builds the complete game tree. We say that Minimax totally solves the game. There are very few interesting games that can be solved this way.
This algorithm is linked to the same name theorem that's founding the game theory. john von neumann was the first to write about it.
The last born and surely the most amazing realisation to date of this theory is α0. It performs super-humanly and has created new knowledge in the ancient game of go.
Day 22
I've spend many hours to chose a working data structure and to tune this solution. It's a minimal implementation of k-d trees. I guess the fatigue is to blame here. When reading the problem I knew I was supposed to BSP before intersecting aabb but I didn't want to comply at first because I knew the task was tedious. I first searched another way of flipping on and off some densed-packed data but I was already too tired to succeed. From this day on I had to make the choice not to drop out the competition every morning (spoiler alert, I didn't!).
<EDIT> Russ Cox did easily what I failed to do during the competition. I've added his solution because it's worth studying: here's a 10x at work!
Day 23
I made a first solution for this but afterward I saw the string representation online and found it so cute I've refactored everything to use it in my solution. Except for this representation, the solution is (again) an application of Dijkstra and the slowest of all my programs: it accounts for almost half the global runtime.
As I've lost the link to the original reddit contribution, if you are the first coder to have used this representation, please tell me: I'll credit you for your finding in a more proper way.
<EDIT> pem told me about a good heuristic function and made structural comments about the game space: he enabled me to refactor the move generation, to augment Dijkstra into A* and finally I had to fix/tweak the code to ease Go runtime memory handling. Namely, before optimizing anything I first profiled a flat version (without concurrency) of the program. After having lighten the program by fixing data structures (pointers/no pointer mainly), I studied the decisions made by my Go compiler with:
go build -gcflags '-m' aoc23.go
When using Go, strings are immutable and every transformation on a string induce an allocation. Moreover, strings tend to easily escape to the heap inducing even more operations there (allocs/gc). For part2, the solution explores 57k paths of 23B strings. This amounts to a modest 1MB but it's the tens of thousand strings we don't want to move around unwillingly. That is to say, strings may not be the best choice here but it was mine, for the sake of fun: I surely went heavy on this problem, my board abstraction is a fixed-size array of strings. The only good thing that comes here is copying the data: a walrus assignement of a board does the trick! I also made the choice to break a rule and pass some strings.Builder by value (I won't do this IRL).
pem's featured version is faster than mine (~90ms) and worth studying (same principle/clean code).
The solution presented here runs in around 100ms (GOGC=off) and the total runtime for this collection is 478ms.
\o/ Total runtime of my programs is under half a second \o/ Though, I believe some carefully crafted rust could run in the double-digits ms (and some crazy dark magic rust invocations may even run in the single-digit ms on selected hardware).
<EDIT>
I've reworked this program: not only the input is read dynamically but the new version is copy free
and thus runs faster than before.
The presented A* has a minimal form, it uses the input almost directly. I believe it's the fastest day23 Go version published today, it runs in ~47ms. Look at this awesome CPU profile:

Along with its satisfying Go benchmarks:
❯ make gobench
go test -bench=. -benchmem
goos: darwin
goarch: arm64
pkg: github.com/erik-adelbert/aoc/2021/23
BenchmarkMkBuros-8 1278229 890.9 ns/op 4768 B/op 21 allocs/op
BenchmarkBuroString-8 30614197 38.82 ns/op 0 B/op 0 allocs/op
BenchmarkBuroGet-8 1000000000 0.3130 ns/op 0 B/op 0 allocs/op
BenchmarkBuroSet-8 1000000000 0.3131 ns/op 0 B/op 0 allocs/op
BenchmarkBuroHome-8 1000000000 0.3133 ns/op 0 B/op 0 allocs/op
BenchmarkBuroPart1Hcost-8 16081874 74.16 ns/op 0 B/op 0 allocs/op
BenchmarkBuroPart2Hcost-8 13972828 85.48 ns/op 0 B/op 0 allocs/op
BenchmarkBuroPeek-8 382037193 3.140 ns/op 0 B/op 0 allocs/op
BenchmarkBuroPop-8 182283752 6.580 ns/op 0 B/op 0 allocs/op
BenchmarkBuroPush-8 1000000000 1.064 ns/op 0 B/op 0 allocs/op
BenchmarkBuroIsDead-8 42184574 28.19 ns/op 0 B/op 0 allocs/op
BenchmarkStateMoveInplaceOk-8 100000000 11.35 ns/op 0 B/op 0 allocs/op
BenchmarkStateMoveAllocOk-8 100000000 11.41 ns/op 0 B/op 0 allocs/op
BenchmarkStateMoveInplaceNotOk-8 169744543 7.065 ns/op 0 B/op 0 allocs/op
BenchmarkStateMoveAllocNotOk-8 169837947 7.099 ns/op 0 B/op 0 allocs/op
BenchmarkStateMoves-8 7202716 166.0 ns/op 8 B/op 1 allocs/op
BenchmarkStateSolvePart1-8 1738 640303 ns/op 7752457 B/op 2506 allocs/op
BenchmarkStateSolvePart2-8 24 46333365 ns/op 18715008 B/op 162511 allocs/op
BenchmarkStdHashmapRoundTrip-8 45152602 25.46 ns/op 0 B/op 0 allocs/op
BenchmarkFNV1HashmapRoundTrip-8 126051969 9.576 ns/op 0 B/op 0 allocs/op
PASS
ok github.com/erik-adelbert/aoc/2021/23 25.680s
The overall runtime is ~258ms
Day 24
I've cracked this problem by hand (txt files) thanks to the support of a teammate. It was my most difficult day and I almost quit again. The solution shown here is an adaptation of the clever python I've found on line after christmas.
I'm not able to solve this problem generally using a computer (surely not in less than 24 hours). I still thinks that it hasn't a clear general solution: it's about program comprehension and I don't know what it really is or even could be.
On the other hand, the constraint satisfaction part is easy and is what the solution is doing.
I've implemented a fast integer exponentiation in order to have a little fun and no dependency on the math library. It's probably slower than the FPU but the actual size of inputs makes it impossible to tell for sure.
Day 25
Phew! It ends well: my program uses multi-buffering and follows closely the description of the problem. I've managed to keep memory allocations on the low side. The visualisation is mesmerizing.
Feedback is welcome and happy coding!
Post Scriptum
If you're reading this, I believe you find my programs worth studying. If you take a quick look to the commits I've made to this repository it's obvious that I've turned this aoc into an obsessive exercice de style.
My style doesn't come from nowhere: first I had the chance of becoming a student of the late Jean Méhat at paris8 university, a true 10x. He was the first to told me about K&R, The Element Of Programming Style, The Practice Of Programming (my favorite), and I started studying algorithms in Algorithms in C before going for The big book and the Dragon book. Eventually, I had to go back to this absolute source: TAOCP.
While under-graduating in CS/AI there, I also met Tristan Cazenave who introduced me to game theory. JM and him won the GGP, they were inspirationnal! This project of mine is closely related to this time and it has not been properly explored yet.
I'm currently reading the (only) Go manual: the D&K.