 Documentation
¶
Documentation
¶
Overview ¶
Package op defines functions for adding TensorFlow operations to a Graph.
Functions for adding an operation to a graph take a Scope object as the first argument. The Scope object encapsulates a graph and a set of properties (such as a name prefix) for all operations being added to the graph.
WARNING: The API in this package has not been finalized and can change without notice.
Example ¶
// This example creates a Graph that multiplies a constant matrix with
// a matrix to be provided during graph execution (via
// tensorflow.Session).
s := NewScope()
input := Placeholder(s, tf.Float) // Matrix to be provided to Session.Run
output := MatMul(s,
Const(s, [][]float32{{10}, {20}}), // Constant 2x1 matrix
input,
MatMulTransposeB(true))
if s.Err() != nil {
panic(s.Err())
}
// Shape of the product: The number of rows is fixed by m1, but the
// number of columns will depend on m2, which is unknown.
fmt.Println(output.Shape())
Output: [2, ?]
Index ¶
- func Abort(scope *Scope, optional ...AbortAttr) (o *tf.Operation)
- func Abs(scope *Scope, x tf.Output) (y tf.Output)
- func AccumulateNV2(scope *Scope, inputs []tf.Output, shape tf.Shape) (sum tf.Output)
- func Acos(scope *Scope, x tf.Output) (y tf.Output)
- func Acosh(scope *Scope, x tf.Output) (y tf.Output)
- func Add(scope *Scope, x tf.Output, y tf.Output) (z tf.Output)
- func AddManySparseToTensorsMap(scope *Scope, sparse_indices tf.Output, sparse_values tf.Output, ...) (sparse_handles tf.Output)
- func AddN(scope *Scope, inputs []tf.Output) (sum tf.Output)
- func AddSparseToTensorsMap(scope *Scope, sparse_indices tf.Output, sparse_values tf.Output, ...) (sparse_handle tf.Output)
- func AddV2(scope *Scope, x tf.Output, y tf.Output) (z tf.Output)
- func AdjustContrast(scope *Scope, images tf.Output, contrast_factor tf.Output, min_value tf.Output, ...) (output tf.Output)
- func AdjustContrastv2(scope *Scope, images tf.Output, contrast_factor tf.Output) (output tf.Output)
- func AdjustHue(scope *Scope, images tf.Output, delta tf.Output) (output tf.Output)
- func AdjustSaturation(scope *Scope, images tf.Output, scale tf.Output) (output tf.Output)
- func All(scope *Scope, input tf.Output, axis tf.Output, optional ...AllAttr) (output tf.Output)
- func AllCandidateSampler(scope *Scope, true_classes tf.Output, num_true int64, num_sampled int64, ...) (sampled_candidates tf.Output, true_expected_count tf.Output, ...)
- func Angle(scope *Scope, input tf.Output, optional ...AngleAttr) (output tf.Output)
- func Any(scope *Scope, input tf.Output, axis tf.Output, optional ...AnyAttr) (output tf.Output)
- func ApproximateEqual(scope *Scope, x tf.Output, y tf.Output, optional ...ApproximateEqualAttr) (z tf.Output)
- func ArgMax(scope *Scope, input tf.Output, dimension tf.Output, optional ...ArgMaxAttr) (output tf.Output)
- func ArgMin(scope *Scope, input tf.Output, dimension tf.Output, optional ...ArgMinAttr) (output tf.Output)
- func AsString(scope *Scope, input tf.Output, optional ...AsStringAttr) (output tf.Output)
- func Asin(scope *Scope, x tf.Output) (y tf.Output)
- func Asinh(scope *Scope, x tf.Output) (y tf.Output)
- func Assert(scope *Scope, condition tf.Output, data []tf.Output, optional ...AssertAttr) (o *tf.Operation)
- func AssignAddVariableOp(scope *Scope, resource tf.Output, value tf.Output) (o *tf.Operation)
- func AssignSubVariableOp(scope *Scope, resource tf.Output, value tf.Output) (o *tf.Operation)
- func AssignVariableOp(scope *Scope, resource tf.Output, value tf.Output) (o *tf.Operation)
- func Atan(scope *Scope, x tf.Output) (y tf.Output)
- func Atan2(scope *Scope, y tf.Output, x tf.Output) (z tf.Output)
- func Atanh(scope *Scope, x tf.Output) (y tf.Output)
- func AudioSpectrogram(scope *Scope, input tf.Output, window_size int64, stride int64, ...) (spectrogram tf.Output)
- func AudioSummary(scope *Scope, tag tf.Output, tensor tf.Output, sample_rate float32, ...) (summary tf.Output)
- func AudioSummaryV2(scope *Scope, tag tf.Output, tensor tf.Output, sample_rate tf.Output, ...) (summary tf.Output)
- func AvgPool(scope *Scope, value tf.Output, ksize []int64, strides []int64, padding string, ...) (output tf.Output)
- func AvgPool3D(scope *Scope, input tf.Output, ksize []int64, strides []int64, padding string, ...) (output tf.Output)
- func AvgPool3DGrad(scope *Scope, orig_input_shape tf.Output, grad tf.Output, ksize []int64, ...) (output tf.Output)
- func AvgPoolGrad(scope *Scope, orig_input_shape tf.Output, grad tf.Output, ksize []int64, ...) (output tf.Output)
- func BatchDataset(scope *Scope, input_dataset tf.Output, batch_size tf.Output, ...) (handle tf.Output)
- func BatchMatMul(scope *Scope, x tf.Output, y tf.Output, optional ...BatchMatMulAttr) (output tf.Output)
- func BatchNormWithGlobalNormalization(scope *Scope, t tf.Output, m tf.Output, v tf.Output, beta tf.Output, ...) (result tf.Output)
- func BatchNormWithGlobalNormalizationGrad(scope *Scope, t tf.Output, m tf.Output, v tf.Output, gamma tf.Output, ...) (dx tf.Output, dm tf.Output, dv tf.Output, db tf.Output, dg tf.Output)
- func BatchToSpace(scope *Scope, input tf.Output, crops tf.Output, block_size int64) (output tf.Output)
- func BatchToSpaceND(scope *Scope, input tf.Output, block_shape tf.Output, crops tf.Output) (output tf.Output)
- func Betainc(scope *Scope, a tf.Output, b tf.Output, x tf.Output) (z tf.Output)
- func BiasAdd(scope *Scope, value tf.Output, bias tf.Output, optional ...BiasAddAttr) (output tf.Output)
- func BiasAddGrad(scope *Scope, out_backprop tf.Output, optional ...BiasAddGradAttr) (output tf.Output)
- func BiasAddV1(scope *Scope, value tf.Output, bias tf.Output) (output tf.Output)
- func Bincount(scope *Scope, arr tf.Output, size tf.Output, weights tf.Output) (bins tf.Output)
- func Bitcast(scope *Scope, input tf.Output, type_ tf.DataType) (output tf.Output)
- func BitwiseAnd(scope *Scope, x tf.Output, y tf.Output) (z tf.Output)
- func BitwiseOr(scope *Scope, x tf.Output, y tf.Output) (z tf.Output)
- func BitwiseXor(scope *Scope, x tf.Output, y tf.Output) (z tf.Output)
- func BroadcastArgs(scope *Scope, s0 tf.Output, s1 tf.Output) (r0 tf.Output)
- func BroadcastGradientArgs(scope *Scope, s0 tf.Output, s1 tf.Output) (r0 tf.Output, r1 tf.Output)
- func Bucketize(scope *Scope, input tf.Output, boundaries []float32) (output tf.Output)
- func BytesProducedStatsDataset(scope *Scope, input_dataset tf.Output, tag tf.Output, ...) (handle tf.Output)
- func CTCBeamSearchDecoder(scope *Scope, inputs tf.Output, sequence_length tf.Output, beam_width int64, ...) (decoded_indices []tf.Output, decoded_values []tf.Output, ...)
- func CTCGreedyDecoder(scope *Scope, inputs tf.Output, sequence_length tf.Output, ...) (decoded_indices tf.Output, decoded_values tf.Output, decoded_shape tf.Output, ...)
- func CTCLoss(scope *Scope, inputs tf.Output, labels_indices tf.Output, ...) (loss tf.Output, gradient tf.Output)
- func CacheDataset(scope *Scope, input_dataset tf.Output, filename tf.Output, ...) (handle tf.Output)
- func Cast(scope *Scope, x tf.Output, DstT tf.DataType) (y tf.Output)
- func Ceil(scope *Scope, x tf.Output) (y tf.Output)
- func CheckNumerics(scope *Scope, tensor tf.Output, message string) (output tf.Output)
- func Cholesky(scope *Scope, input tf.Output) (output tf.Output)
- func CholeskyGrad(scope *Scope, l tf.Output, grad tf.Output) (output tf.Output)
- func CloseSummaryWriter(scope *Scope, writer tf.Output) (o *tf.Operation)
- func CompareAndBitpack(scope *Scope, input tf.Output, threshold tf.Output) (output tf.Output)
- func Complex(scope *Scope, real tf.Output, imag tf.Output, optional ...ComplexAttr) (out tf.Output)
- func ComplexAbs(scope *Scope, x tf.Output, optional ...ComplexAbsAttr) (y tf.Output)
- func ComputeAccidentalHits(scope *Scope, true_classes tf.Output, sampled_candidates tf.Output, ...) (indices tf.Output, ids tf.Output, weights tf.Output)
- func Concat(scope *Scope, concat_dim tf.Output, values []tf.Output) (output tf.Output)
- func ConcatOffset(scope *Scope, concat_dim tf.Output, shape []tf.Output) (offset []tf.Output)
- func ConcatV2(scope *Scope, values []tf.Output, axis tf.Output) (output tf.Output)
- func ConcatenateDataset(scope *Scope, input_dataset tf.Output, another_dataset tf.Output, ...) (handle tf.Output)
- func Conj(scope *Scope, input tf.Output) (output tf.Output)
- func ConjugateTranspose(scope *Scope, x tf.Output, perm tf.Output) (y tf.Output)
- func Const(scope *Scope, value interface{}) (output tf.Output)
- func ControlTrigger(scope *Scope) (o *tf.Operation)
- func Conv2D(scope *Scope, input tf.Output, filter tf.Output, strides []int64, ...) (output tf.Output)
- func Conv2DBackpropFilter(scope *Scope, input tf.Output, filter_sizes tf.Output, out_backprop tf.Output, ...) (output tf.Output)
- func Conv2DBackpropInput(scope *Scope, input_sizes tf.Output, filter tf.Output, out_backprop tf.Output, ...) (output tf.Output)
- func Conv3D(scope *Scope, input tf.Output, filter tf.Output, strides []int64, ...) (output tf.Output)
- func Conv3DBackpropFilter(scope *Scope, input tf.Output, filter tf.Output, out_backprop tf.Output, ...) (output tf.Output)
- func Conv3DBackpropFilterV2(scope *Scope, input tf.Output, filter_sizes tf.Output, out_backprop tf.Output, ...) (output tf.Output)
- func Conv3DBackpropInput(scope *Scope, input tf.Output, filter tf.Output, out_backprop tf.Output, ...) (output tf.Output)
- func Conv3DBackpropInputV2(scope *Scope, input_sizes tf.Output, filter tf.Output, out_backprop tf.Output, ...) (output tf.Output)
- func Cos(scope *Scope, x tf.Output) (y tf.Output)
- func Cosh(scope *Scope, x tf.Output) (y tf.Output)
- func CreateSummaryDbWriter(scope *Scope, writer tf.Output, db_uri tf.Output, experiment_name tf.Output, ...) (o *tf.Operation)
- func CreateSummaryFileWriter(scope *Scope, writer tf.Output, logdir tf.Output, max_queue tf.Output, ...) (o *tf.Operation)
- func CropAndResize(scope *Scope, image tf.Output, boxes tf.Output, box_ind tf.Output, ...) (crops tf.Output)
- func CropAndResizeGradBoxes(scope *Scope, grads tf.Output, image tf.Output, boxes tf.Output, ...) (output tf.Output)
- func CropAndResizeGradImage(scope *Scope, grads tf.Output, boxes tf.Output, box_ind tf.Output, ...) (output tf.Output)
- func Cross(scope *Scope, a tf.Output, b tf.Output) (product tf.Output)
- func Cumprod(scope *Scope, x tf.Output, axis tf.Output, optional ...CumprodAttr) (out tf.Output)
- func Cumsum(scope *Scope, x tf.Output, axis tf.Output, optional ...CumsumAttr) (out tf.Output)
- func DataFormatDimMap(scope *Scope, x tf.Output, optional ...DataFormatDimMapAttr) (y tf.Output)
- func DataFormatVecPermute(scope *Scope, x tf.Output, optional ...DataFormatVecPermuteAttr) (y tf.Output)
- func DatasetToSingleElement(scope *Scope, dataset tf.Output, output_types []tf.DataType, ...) (components []tf.Output)
- func DebugGradientIdentity(scope *Scope, input tf.Output) (output tf.Output)
- func DecodeAndCropJpeg(scope *Scope, contents tf.Output, crop_window tf.Output, ...) (image tf.Output)
- func DecodeBase64(scope *Scope, input tf.Output) (output tf.Output)
- func DecodeBmp(scope *Scope, contents tf.Output, optional ...DecodeBmpAttr) (image tf.Output)
- func DecodeCSV(scope *Scope, records tf.Output, record_defaults []tf.Output, ...) (output []tf.Output)
- func DecodeCompressed(scope *Scope, bytes tf.Output, optional ...DecodeCompressedAttr) (output tf.Output)
- func DecodeGif(scope *Scope, contents tf.Output) (image tf.Output)
- func DecodeJSONExample(scope *Scope, json_examples tf.Output) (binary_examples tf.Output)
- func DecodeJpeg(scope *Scope, contents tf.Output, optional ...DecodeJpegAttr) (image tf.Output)
- func DecodePng(scope *Scope, contents tf.Output, optional ...DecodePngAttr) (image tf.Output)
- func DecodeRaw(scope *Scope, bytes tf.Output, out_type tf.DataType, optional ...DecodeRawAttr) (output tf.Output)
- func DecodeWav(scope *Scope, contents tf.Output, optional ...DecodeWavAttr) (audio tf.Output, sample_rate tf.Output)
- func DeleteSessionTensor(scope *Scope, handle tf.Output) (o *tf.Operation)
- func DenseToDenseSetOperation(scope *Scope, set1 tf.Output, set2 tf.Output, set_operation string, ...) (result_indices tf.Output, result_values tf.Output, result_shape tf.Output)
- func DenseToSparseBatchDataset(scope *Scope, input_dataset tf.Output, batch_size tf.Output, ...) (handle tf.Output)
- func DenseToSparseSetOperation(scope *Scope, set1 tf.Output, set2_indices tf.Output, set2_values tf.Output, ...) (result_indices tf.Output, result_values tf.Output, result_shape tf.Output)
- func DepthToSpace(scope *Scope, input tf.Output, block_size int64, optional ...DepthToSpaceAttr) (output tf.Output)
- func DepthwiseConv2dNative(scope *Scope, input tf.Output, filter tf.Output, strides []int64, ...) (output tf.Output)
- func DepthwiseConv2dNativeBackpropFilter(scope *Scope, input tf.Output, filter_sizes tf.Output, out_backprop tf.Output, ...) (output tf.Output)
- func DepthwiseConv2dNativeBackpropInput(scope *Scope, input_sizes tf.Output, filter tf.Output, out_backprop tf.Output, ...) (output tf.Output)
- func Dequantize(scope *Scope, input tf.Output, min_range tf.Output, max_range tf.Output, ...) (output tf.Output)
- func DeserializeIterator(scope *Scope, resource_handle tf.Output, serialized tf.Output) (o *tf.Operation)
- func DeserializeManySparse(scope *Scope, serialized_sparse tf.Output, dtype tf.DataType) (sparse_indices tf.Output, sparse_values tf.Output, sparse_shape tf.Output)
- func DeserializeSparse(scope *Scope, serialized_sparse tf.Output, dtype tf.DataType) (sparse_indices tf.Output, sparse_values tf.Output, sparse_shape tf.Output)
- func DestroyResourceOp(scope *Scope, resource tf.Output, optional ...DestroyResourceOpAttr) (o *tf.Operation)
- func Diag(scope *Scope, diagonal tf.Output) (output tf.Output)
- func DiagPart(scope *Scope, input tf.Output) (diagonal tf.Output)
- func Digamma(scope *Scope, x tf.Output) (y tf.Output)
- func Dilation2D(scope *Scope, input tf.Output, filter tf.Output, strides []int64, ...) (output tf.Output)
- func Dilation2DBackpropFilter(scope *Scope, input tf.Output, filter tf.Output, out_backprop tf.Output, ...) (filter_backprop tf.Output)
- func Dilation2DBackpropInput(scope *Scope, input tf.Output, filter tf.Output, out_backprop tf.Output, ...) (in_backprop tf.Output)
- func Div(scope *Scope, x tf.Output, y tf.Output) (z tf.Output)
- func DrawBoundingBoxes(scope *Scope, images tf.Output, boxes tf.Output) (output tf.Output)
- func DynamicPartition(scope *Scope, data tf.Output, partitions tf.Output, num_partitions int64) (outputs []tf.Output)
- func DynamicStitch(scope *Scope, indices []tf.Output, data []tf.Output) (merged tf.Output)
- func EagerPyFunc(scope *Scope, input []tf.Output, token string, Tout []tf.DataType) (output []tf.Output)
- func EditDistance(scope *Scope, hypothesis_indices tf.Output, hypothesis_values tf.Output, ...) (output tf.Output)
- func Elu(scope *Scope, features tf.Output) (activations tf.Output)
- func EluGrad(scope *Scope, gradients tf.Output, outputs tf.Output) (backprops tf.Output)
- func EncodeBase64(scope *Scope, input tf.Output, optional ...EncodeBase64Attr) (output tf.Output)
- func EncodeJpeg(scope *Scope, image tf.Output, optional ...EncodeJpegAttr) (contents tf.Output)
- func EncodePng(scope *Scope, image tf.Output, optional ...EncodePngAttr) (contents tf.Output)
- func EncodeWav(scope *Scope, audio tf.Output, sample_rate tf.Output) (contents tf.Output)
- func Enter(scope *Scope, data tf.Output, frame_name string, optional ...EnterAttr) (output tf.Output)
- func Equal(scope *Scope, x tf.Output, y tf.Output) (z tf.Output)
- func Erf(scope *Scope, x tf.Output) (y tf.Output)
- func Erfc(scope *Scope, x tf.Output) (y tf.Output)
- func Exit(scope *Scope, data tf.Output) (output tf.Output)
- func Exp(scope *Scope, x tf.Output) (y tf.Output)
- func ExpandDims(scope *Scope, input tf.Output, axis tf.Output) (output tf.Output)
- func Expm1(scope *Scope, x tf.Output) (y tf.Output)
- func ExtractGlimpse(scope *Scope, input tf.Output, size tf.Output, offsets tf.Output, ...) (glimpse tf.Output)
- func ExtractImagePatches(scope *Scope, images tf.Output, ksizes []int64, strides []int64, rates []int64, ...) (patches tf.Output)
- func ExtractJpegShape(scope *Scope, contents tf.Output, optional ...ExtractJpegShapeAttr) (image_shape tf.Output)
- func FFT(scope *Scope, input tf.Output) (output tf.Output)
- func FFT2D(scope *Scope, input tf.Output) (output tf.Output)
- func FFT3D(scope *Scope, input tf.Output) (output tf.Output)
- func FIFOQueueV2(scope *Scope, component_types []tf.DataType, optional ...FIFOQueueV2Attr) (handle tf.Output)
- func Fact(scope *Scope) (fact tf.Output)
- func FakeQuantWithMinMaxArgs(scope *Scope, inputs tf.Output, optional ...FakeQuantWithMinMaxArgsAttr) (outputs tf.Output)
- func FakeQuantWithMinMaxArgsGradient(scope *Scope, gradients tf.Output, inputs tf.Output, ...) (backprops tf.Output)
- func FakeQuantWithMinMaxVars(scope *Scope, inputs tf.Output, min tf.Output, max tf.Output, ...) (outputs tf.Output)
- func FakeQuantWithMinMaxVarsGradient(scope *Scope, gradients tf.Output, inputs tf.Output, min tf.Output, ...) (backprops_wrt_input tf.Output, backprop_wrt_min tf.Output, ...)
- func FakeQuantWithMinMaxVarsPerChannel(scope *Scope, inputs tf.Output, min tf.Output, max tf.Output, ...) (outputs tf.Output)
- func FakeQuantWithMinMaxVarsPerChannelGradient(scope *Scope, gradients tf.Output, inputs tf.Output, min tf.Output, ...) (backprops_wrt_input tf.Output, backprop_wrt_min tf.Output, ...)
- func Fill(scope *Scope, dims tf.Output, value tf.Output) (output tf.Output)
- func FixedLengthRecordDataset(scope *Scope, filenames tf.Output, header_bytes tf.Output, ...) (handle tf.Output)
- func FixedLengthRecordReaderV2(scope *Scope, record_bytes int64, optional ...FixedLengthRecordReaderV2Attr) (reader_handle tf.Output)
- func FixedUnigramCandidateSampler(scope *Scope, true_classes tf.Output, num_true int64, num_sampled int64, ...) (sampled_candidates tf.Output, true_expected_count tf.Output, ...)
- func Floor(scope *Scope, x tf.Output) (y tf.Output)
- func FloorDiv(scope *Scope, x tf.Output, y tf.Output) (z tf.Output)
- func FloorMod(scope *Scope, x tf.Output, y tf.Output) (z tf.Output)
- func FlushSummaryWriter(scope *Scope, writer tf.Output) (o *tf.Operation)
- func FractionalAvgPool(scope *Scope, value tf.Output, pooling_ratio []float32, ...) (output tf.Output, row_pooling_sequence tf.Output, ...)
- func FractionalAvgPoolGrad(scope *Scope, orig_input_tensor_shape tf.Output, out_backprop tf.Output, ...) (output tf.Output)
- func FractionalMaxPool(scope *Scope, value tf.Output, pooling_ratio []float32, ...) (output tf.Output, row_pooling_sequence tf.Output, ...)
- func FractionalMaxPoolGrad(scope *Scope, orig_input tf.Output, orig_output tf.Output, ...) (output tf.Output)
- func FusedBatchNorm(scope *Scope, x tf.Output, scale tf.Output, offset tf.Output, mean tf.Output, ...) (y tf.Output, batch_mean tf.Output, batch_variance tf.Output, ...)
- func FusedBatchNormGrad(scope *Scope, y_backprop tf.Output, x tf.Output, scale tf.Output, ...) (x_backprop tf.Output, scale_backprop tf.Output, offset_backprop tf.Output, ...)
- func FusedBatchNormGradV2(scope *Scope, y_backprop tf.Output, x tf.Output, scale tf.Output, ...) (x_backprop tf.Output, scale_backprop tf.Output, offset_backprop tf.Output, ...)
- func FusedBatchNormV2(scope *Scope, x tf.Output, scale tf.Output, offset tf.Output, mean tf.Output, ...) (y tf.Output, batch_mean tf.Output, batch_variance tf.Output, ...)
- func FusedPadConv2D(scope *Scope, input tf.Output, paddings tf.Output, filter tf.Output, ...) (output tf.Output)
- func FusedResizeAndPadConv2D(scope *Scope, input tf.Output, size tf.Output, paddings tf.Output, ...) (output tf.Output)
- func Gather(scope *Scope, params tf.Output, indices tf.Output, optional ...GatherAttr) (output tf.Output)
- func GatherNd(scope *Scope, params tf.Output, indices tf.Output) (output tf.Output)
- func GatherV2(scope *Scope, params tf.Output, indices tf.Output, axis tf.Output) (output tf.Output)
- func GenerateVocabRemapping(scope *Scope, new_vocab_file tf.Output, old_vocab_file tf.Output, ...) (remapping tf.Output, num_present tf.Output)
- func GetSessionHandle(scope *Scope, value tf.Output) (handle tf.Output)
- func GetSessionHandleV2(scope *Scope, value tf.Output) (handle tf.Output)
- func GetSessionTensor(scope *Scope, handle tf.Output, dtype tf.DataType) (value tf.Output)
- func Greater(scope *Scope, x tf.Output, y tf.Output) (z tf.Output)
- func GreaterEqual(scope *Scope, x tf.Output, y tf.Output) (z tf.Output)
- func GuaranteeConst(scope *Scope, input tf.Output) (output tf.Output)
- func HSVToRGB(scope *Scope, images tf.Output) (output tf.Output)
- func HashTableV2(scope *Scope, key_dtype tf.DataType, value_dtype tf.DataType, ...) (table_handle tf.Output)
- func HistogramFixedWidth(scope *Scope, values tf.Output, value_range tf.Output, nbins tf.Output, ...) (out tf.Output)
- func HistogramSummary(scope *Scope, tag tf.Output, values tf.Output) (summary tf.Output)
- func IFFT(scope *Scope, input tf.Output) (output tf.Output)
- func IFFT2D(scope *Scope, input tf.Output) (output tf.Output)
- func IFFT3D(scope *Scope, input tf.Output) (output tf.Output)
- func IRFFT(scope *Scope, input tf.Output, fft_length tf.Output) (output tf.Output)
- func IRFFT2D(scope *Scope, input tf.Output, fft_length tf.Output) (output tf.Output)
- func IRFFT3D(scope *Scope, input tf.Output, fft_length tf.Output) (output tf.Output)
- func Identity(scope *Scope, input tf.Output) (output tf.Output)
- func IdentityN(scope *Scope, input []tf.Output) (output []tf.Output)
- func IdentityReaderV2(scope *Scope, optional ...IdentityReaderV2Attr) (reader_handle tf.Output)
- func Igamma(scope *Scope, a tf.Output, x tf.Output) (z tf.Output)
- func Igammac(scope *Scope, a tf.Output, x tf.Output) (z tf.Output)
- func Imag(scope *Scope, input tf.Output, optional ...ImagAttr) (output tf.Output)
- func ImageSummary(scope *Scope, tag tf.Output, tensor tf.Output, optional ...ImageSummaryAttr) (summary tf.Output)
- func ImmutableConst(scope *Scope, dtype tf.DataType, shape tf.Shape, memory_region_name string) (tensor tf.Output)
- func ImportEvent(scope *Scope, writer tf.Output, event tf.Output) (o *tf.Operation)
- func InTopK(scope *Scope, predictions tf.Output, targets tf.Output, k int64) (precision tf.Output)
- func InTopKV2(scope *Scope, predictions tf.Output, targets tf.Output, k tf.Output) (precision tf.Output)
- func InitializeTableFromTextFileV2(scope *Scope, table_handle tf.Output, filename tf.Output, key_index int64, ...) (o *tf.Operation)
- func InitializeTableV2(scope *Scope, table_handle tf.Output, keys tf.Output, values tf.Output) (o *tf.Operation)
- func Inv(scope *Scope, x tf.Output) (y tf.Output)
- func InvGrad(scope *Scope, y tf.Output, dy tf.Output) (z tf.Output)
- func Invert(scope *Scope, x tf.Output) (y tf.Output)
- func InvertPermutation(scope *Scope, x tf.Output) (y tf.Output)
- func IsFinite(scope *Scope, x tf.Output) (y tf.Output)
- func IsInf(scope *Scope, x tf.Output) (y tf.Output)
- func IsNan(scope *Scope, x tf.Output) (y tf.Output)
- func Iterator(scope *Scope, shared_name string, container string, output_types []tf.DataType, ...) (handle tf.Output)
- func IteratorFromStringHandle(scope *Scope, string_handle tf.Output, ...) (resource_handle tf.Output)
- func IteratorGetNext(scope *Scope, iterator tf.Output, output_types []tf.DataType, ...) (components []tf.Output)
- func IteratorSetStatsAggregator(scope *Scope, iterator_handle tf.Output, stats_aggregator_handle tf.Output) (o *tf.Operation)
- func IteratorToStringHandle(scope *Scope, resource_handle tf.Output) (string_handle tf.Output)
- func L2Loss(scope *Scope, t tf.Output) (output tf.Output)
- func LRN(scope *Scope, input tf.Output, optional ...LRNAttr) (output tf.Output)
- func LRNGrad(scope *Scope, input_grads tf.Output, input_image tf.Output, ...) (output tf.Output)
- func LatencyStatsDataset(scope *Scope, input_dataset tf.Output, tag tf.Output, ...) (handle tf.Output)
- func LearnedUnigramCandidateSampler(scope *Scope, true_classes tf.Output, num_true int64, num_sampled int64, ...) (sampled_candidates tf.Output, true_expected_count tf.Output, ...)
- func LeftShift(scope *Scope, x tf.Output, y tf.Output) (z tf.Output)
- func Less(scope *Scope, x tf.Output, y tf.Output) (z tf.Output)
- func LessEqual(scope *Scope, x tf.Output, y tf.Output) (z tf.Output)
- func Lgamma(scope *Scope, x tf.Output) (y tf.Output)
- func LinSpace(scope *Scope, start tf.Output, stop tf.Output, num tf.Output) (output tf.Output)
- func ListDiff(scope *Scope, x tf.Output, y tf.Output, optional ...ListDiffAttr) (out tf.Output, idx tf.Output)
- func LoadAndRemapMatrix(scope *Scope, ckpt_path tf.Output, old_tensor_name tf.Output, ...) (output_matrix tf.Output)
- func Log(scope *Scope, x tf.Output) (y tf.Output)
- func Log1p(scope *Scope, x tf.Output) (y tf.Output)
- func LogMatrixDeterminant(scope *Scope, input tf.Output) (sign tf.Output, log_abs_determinant tf.Output)
- func LogSoftmax(scope *Scope, logits tf.Output) (logsoftmax tf.Output)
- func LogUniformCandidateSampler(scope *Scope, true_classes tf.Output, num_true int64, num_sampled int64, ...) (sampled_candidates tf.Output, true_expected_count tf.Output, ...)
- func LogicalAnd(scope *Scope, x tf.Output, y tf.Output) (z tf.Output)
- func LogicalNot(scope *Scope, x tf.Output) (y tf.Output)
- func LogicalOr(scope *Scope, x tf.Output, y tf.Output) (z tf.Output)
- func LookupTableExportV2(scope *Scope, table_handle tf.Output, Tkeys tf.DataType, Tvalues tf.DataType) (keys tf.Output, values tf.Output)
- func LookupTableFindV2(scope *Scope, table_handle tf.Output, keys tf.Output, default_value tf.Output) (values tf.Output)
- func LookupTableImportV2(scope *Scope, table_handle tf.Output, keys tf.Output, values tf.Output) (o *tf.Operation)
- func LookupTableInsertV2(scope *Scope, table_handle tf.Output, keys tf.Output, values tf.Output) (o *tf.Operation)
- func LookupTableSizeV2(scope *Scope, table_handle tf.Output) (size tf.Output)
- func LoopCond(scope *Scope, input tf.Output) (output tf.Output)
- func MakeIterator(scope *Scope, dataset tf.Output, iterator tf.Output) (o *tf.Operation)
- func MapClear(scope *Scope, dtypes []tf.DataType, optional ...MapClearAttr) (o *tf.Operation)
- func MapIncompleteSize(scope *Scope, dtypes []tf.DataType, optional ...MapIncompleteSizeAttr) (size tf.Output)
- func MapPeek(scope *Scope, key tf.Output, indices tf.Output, dtypes []tf.DataType, ...) (values []tf.Output)
- func MapSize(scope *Scope, dtypes []tf.DataType, optional ...MapSizeAttr) (size tf.Output)
- func MapStage(scope *Scope, key tf.Output, indices tf.Output, values []tf.Output, ...) (o *tf.Operation)
- func MapUnstage(scope *Scope, key tf.Output, indices tf.Output, dtypes []tf.DataType, ...) (values []tf.Output)
- func MapUnstageNoKey(scope *Scope, indices tf.Output, dtypes []tf.DataType, ...) (key tf.Output, values []tf.Output)
- func MatMul(scope *Scope, a tf.Output, b tf.Output, optional ...MatMulAttr) (product tf.Output)
- func MatchingFiles(scope *Scope, pattern tf.Output) (filenames tf.Output)
- func MatrixBandPart(scope *Scope, input tf.Output, num_lower tf.Output, num_upper tf.Output) (band tf.Output)
- func MatrixDeterminant(scope *Scope, input tf.Output) (output tf.Output)
- func MatrixDiag(scope *Scope, diagonal tf.Output) (output tf.Output)
- func MatrixDiagPart(scope *Scope, input tf.Output) (diagonal tf.Output)
- func MatrixExponential(scope *Scope, input tf.Output) (output tf.Output)
- func MatrixInverse(scope *Scope, input tf.Output, optional ...MatrixInverseAttr) (output tf.Output)
- func MatrixSetDiag(scope *Scope, input tf.Output, diagonal tf.Output) (output tf.Output)
- func MatrixSolve(scope *Scope, matrix tf.Output, rhs tf.Output, optional ...MatrixSolveAttr) (output tf.Output)
- func MatrixSolveLs(scope *Scope, matrix tf.Output, rhs tf.Output, l2_regularizer tf.Output, ...) (output tf.Output)
- func MatrixTriangularSolve(scope *Scope, matrix tf.Output, rhs tf.Output, ...) (output tf.Output)
- func Max(scope *Scope, input tf.Output, axis tf.Output, optional ...MaxAttr) (output tf.Output)
- func MaxPool(scope *Scope, input tf.Output, ksize []int64, strides []int64, padding string, ...) (output tf.Output)
- func MaxPool3D(scope *Scope, input tf.Output, ksize []int64, strides []int64, padding string, ...) (output tf.Output)
- func MaxPool3DGrad(scope *Scope, orig_input tf.Output, orig_output tf.Output, grad tf.Output, ...) (output tf.Output)
- func MaxPool3DGradGrad(scope *Scope, orig_input tf.Output, orig_output tf.Output, grad tf.Output, ...) (output tf.Output)
- func MaxPoolGrad(scope *Scope, orig_input tf.Output, orig_output tf.Output, grad tf.Output, ...) (output tf.Output)
- func MaxPoolGradGrad(scope *Scope, orig_input tf.Output, orig_output tf.Output, grad tf.Output, ...) (output tf.Output)
- func MaxPoolGradGradV2(scope *Scope, orig_input tf.Output, orig_output tf.Output, grad tf.Output, ...) (output tf.Output)
- func MaxPoolGradGradWithArgmax(scope *Scope, input tf.Output, grad tf.Output, argmax tf.Output, ksize []int64, ...) (output tf.Output)
- func MaxPoolGradV2(scope *Scope, orig_input tf.Output, orig_output tf.Output, grad tf.Output, ...) (output tf.Output)
- func MaxPoolGradWithArgmax(scope *Scope, input tf.Output, grad tf.Output, argmax tf.Output, ksize []int64, ...) (output tf.Output)
- func MaxPoolV2(scope *Scope, input tf.Output, ksize tf.Output, strides tf.Output, ...) (output tf.Output)
- func MaxPoolWithArgmax(scope *Scope, input tf.Output, ksize []int64, strides []int64, padding string, ...) (output tf.Output, argmax tf.Output)
- func Maximum(scope *Scope, x tf.Output, y tf.Output) (z tf.Output)
- func Mean(scope *Scope, input tf.Output, axis tf.Output, optional ...MeanAttr) (output tf.Output)
- func Merge(scope *Scope, inputs []tf.Output) (output tf.Output, value_index tf.Output)
- func MergeSummary(scope *Scope, inputs []tf.Output) (summary tf.Output)
- func MergeV2Checkpoints(scope *Scope, checkpoint_prefixes tf.Output, destination_prefix tf.Output, ...) (o *tf.Operation)
- func Mfcc(scope *Scope, spectrogram tf.Output, sample_rate tf.Output, ...) (output tf.Output)
- func Min(scope *Scope, input tf.Output, axis tf.Output, optional ...MinAttr) (output tf.Output)
- func Minimum(scope *Scope, x tf.Output, y tf.Output) (z tf.Output)
- func MirrorPad(scope *Scope, input tf.Output, paddings tf.Output, mode string) (output tf.Output)
- func MirrorPadGrad(scope *Scope, input tf.Output, paddings tf.Output, mode string) (output tf.Output)
- func Mod(scope *Scope, x tf.Output, y tf.Output) (z tf.Output)
- func Mul(scope *Scope, x tf.Output, y tf.Output) (z tf.Output)
- func Multinomial(scope *Scope, logits tf.Output, num_samples tf.Output, ...) (output tf.Output)
- func MutableDenseHashTableV2(scope *Scope, empty_key tf.Output, value_dtype tf.DataType, ...) (table_handle tf.Output)
- func MutableHashTableOfTensorsV2(scope *Scope, key_dtype tf.DataType, value_dtype tf.DataType, ...) (table_handle tf.Output)
- func MutableHashTableV2(scope *Scope, key_dtype tf.DataType, value_dtype tf.DataType, ...) (table_handle tf.Output)
- func Neg(scope *Scope, x tf.Output) (y tf.Output)
- func NextIteration(scope *Scope, data tf.Output) (output tf.Output)
- func NoOp(scope *Scope) (o *tf.Operation)
- func NonMaxSuppression(scope *Scope, boxes tf.Output, scores tf.Output, max_output_size tf.Output, ...) (selected_indices tf.Output)
- func NonMaxSuppressionV2(scope *Scope, boxes tf.Output, scores tf.Output, max_output_size tf.Output, ...) (selected_indices tf.Output)
- func NotEqual(scope *Scope, x tf.Output, y tf.Output) (z tf.Output)
- func NthElement(scope *Scope, input tf.Output, n tf.Output, optional ...NthElementAttr) (values tf.Output)
- func OneHot(scope *Scope, indices tf.Output, depth tf.Output, on_value tf.Output, ...) (output tf.Output)
- func OnesLike(scope *Scope, x tf.Output) (y tf.Output)
- func OrderedMapClear(scope *Scope, dtypes []tf.DataType, optional ...OrderedMapClearAttr) (o *tf.Operation)
- func OrderedMapIncompleteSize(scope *Scope, dtypes []tf.DataType, optional ...OrderedMapIncompleteSizeAttr) (size tf.Output)
- func OrderedMapPeek(scope *Scope, key tf.Output, indices tf.Output, dtypes []tf.DataType, ...) (values []tf.Output)
- func OrderedMapSize(scope *Scope, dtypes []tf.DataType, optional ...OrderedMapSizeAttr) (size tf.Output)
- func OrderedMapStage(scope *Scope, key tf.Output, indices tf.Output, values []tf.Output, ...) (o *tf.Operation)
- func OrderedMapUnstage(scope *Scope, key tf.Output, indices tf.Output, dtypes []tf.DataType, ...) (values []tf.Output)
- func OrderedMapUnstageNoKey(scope *Scope, indices tf.Output, dtypes []tf.DataType, ...) (key tf.Output, values []tf.Output)
- func Pack(scope *Scope, values []tf.Output, optional ...PackAttr) (output tf.Output)
- func Pad(scope *Scope, input tf.Output, paddings tf.Output) (output tf.Output)
- func PadV2(scope *Scope, input tf.Output, paddings tf.Output, constant_values tf.Output) (output tf.Output)
- func PaddedBatchDataset(scope *Scope, input_dataset tf.Output, batch_size tf.Output, ...) (handle tf.Output)
- func PaddingFIFOQueueV2(scope *Scope, component_types []tf.DataType, ...) (handle tf.Output)
- func ParallelConcat(scope *Scope, values []tf.Output, shape tf.Shape) (output tf.Output)
- func ParallelDynamicStitch(scope *Scope, indices []tf.Output, data []tf.Output) (merged tf.Output)
- func ParameterizedTruncatedNormal(scope *Scope, shape tf.Output, means tf.Output, stdevs tf.Output, ...) (output tf.Output)
- func ParseExample(scope *Scope, serialized tf.Output, names tf.Output, sparse_keys []tf.Output, ...) (sparse_indices []tf.Output, sparse_values []tf.Output, ...)
- func ParseSingleExample(scope *Scope, serialized tf.Output, dense_defaults []tf.Output, ...) (sparse_indices []tf.Output, sparse_values []tf.Output, ...)
- func ParseSingleSequenceExample(scope *Scope, serialized tf.Output, ...) (context_sparse_indices []tf.Output, context_sparse_values []tf.Output, ...)
- func ParseTensor(scope *Scope, serialized tf.Output, out_type tf.DataType) (output tf.Output)
- func Placeholder(scope *Scope, dtype tf.DataType, optional ...PlaceholderAttr) (output tf.Output)
- func PlaceholderV2(scope *Scope, dtype tf.DataType, shape tf.Shape) (output tf.Output)
- func PlaceholderWithDefault(scope *Scope, input tf.Output, shape tf.Shape) (output tf.Output)
- func Polygamma(scope *Scope, a tf.Output, x tf.Output) (z tf.Output)
- func PopulationCount(scope *Scope, x tf.Output) (y tf.Output)
- func Pow(scope *Scope, x tf.Output, y tf.Output) (z tf.Output)
- func PrefetchDataset(scope *Scope, input_dataset tf.Output, buffer_size tf.Output, ...) (handle tf.Output)
- func PreventGradient(scope *Scope, input tf.Output, optional ...PreventGradientAttr) (output tf.Output)
- func Print(scope *Scope, input tf.Output, data []tf.Output, optional ...PrintAttr) (output tf.Output)
- func PriorityQueueV2(scope *Scope, shapes []tf.Shape, optional ...PriorityQueueV2Attr) (handle tf.Output)
- func Prod(scope *Scope, input tf.Output, axis tf.Output, optional ...ProdAttr) (output tf.Output)
- func Qr(scope *Scope, input tf.Output, optional ...QrAttr) (q tf.Output, r tf.Output)
- func QuantizeAndDequantize(scope *Scope, input tf.Output, optional ...QuantizeAndDequantizeAttr) (output tf.Output)
- func QuantizeAndDequantizeV2(scope *Scope, input tf.Output, input_min tf.Output, input_max tf.Output, ...) (output tf.Output)
- func QuantizeAndDequantizeV3(scope *Scope, input tf.Output, input_min tf.Output, input_max tf.Output, ...) (output tf.Output)
- func QuantizeDownAndShrinkRange(scope *Scope, input tf.Output, input_min tf.Output, input_max tf.Output, ...) (output tf.Output, output_min tf.Output, output_max tf.Output)
- func QuantizeV2(scope *Scope, input tf.Output, min_range tf.Output, max_range tf.Output, ...) (output tf.Output, output_min tf.Output, output_max tf.Output)
- func QuantizedAdd(scope *Scope, x tf.Output, y tf.Output, min_x tf.Output, max_x tf.Output, ...) (z tf.Output, min_z tf.Output, max_z tf.Output)
- func QuantizedAvgPool(scope *Scope, input tf.Output, min_input tf.Output, max_input tf.Output, ...) (output tf.Output, min_output tf.Output, max_output tf.Output)
- func QuantizedBatchNormWithGlobalNormalization(scope *Scope, t tf.Output, t_min tf.Output, t_max tf.Output, m tf.Output, ...) (result tf.Output, result_min tf.Output, result_max tf.Output)
- func QuantizedBiasAdd(scope *Scope, input tf.Output, bias tf.Output, min_input tf.Output, ...) (output tf.Output, min_out tf.Output, max_out tf.Output)
- func QuantizedConcat(scope *Scope, concat_dim tf.Output, values []tf.Output, input_mins []tf.Output, ...) (output tf.Output, output_min tf.Output, output_max tf.Output)
- func QuantizedConv2D(scope *Scope, input tf.Output, filter tf.Output, min_input tf.Output, ...) (output tf.Output, min_output tf.Output, max_output tf.Output)
- func QuantizedInstanceNorm(scope *Scope, x tf.Output, x_min tf.Output, x_max tf.Output, ...) (y tf.Output, y_min tf.Output, y_max tf.Output)
- func QuantizedMatMul(scope *Scope, a tf.Output, b tf.Output, min_a tf.Output, max_a tf.Output, ...) (out tf.Output, min_out tf.Output, max_out tf.Output)
- func QuantizedMaxPool(scope *Scope, input tf.Output, min_input tf.Output, max_input tf.Output, ...) (output tf.Output, min_output tf.Output, max_output tf.Output)
- func QuantizedMul(scope *Scope, x tf.Output, y tf.Output, min_x tf.Output, max_x tf.Output, ...) (z tf.Output, min_z tf.Output, max_z tf.Output)
- func QuantizedRelu(scope *Scope, features tf.Output, min_features tf.Output, ...) (activations tf.Output, min_activations tf.Output, max_activations tf.Output)
- func QuantizedRelu6(scope *Scope, features tf.Output, min_features tf.Output, ...) (activations tf.Output, min_activations tf.Output, max_activations tf.Output)
- func QuantizedReluX(scope *Scope, features tf.Output, max_value tf.Output, min_features tf.Output, ...) (activations tf.Output, min_activations tf.Output, max_activations tf.Output)
- func QuantizedReshape(scope *Scope, tensor tf.Output, shape tf.Output, input_min tf.Output, ...) (output tf.Output, output_min tf.Output, output_max tf.Output)
- func QuantizedResizeBilinear(scope *Scope, images tf.Output, size tf.Output, min tf.Output, max tf.Output, ...) (resized_images tf.Output, out_min tf.Output, out_max tf.Output)
- func QueueCloseV2(scope *Scope, handle tf.Output, optional ...QueueCloseV2Attr) (o *tf.Operation)
- func QueueDequeueManyV2(scope *Scope, handle tf.Output, n tf.Output, component_types []tf.DataType, ...) (components []tf.Output)
- func QueueDequeueUpToV2(scope *Scope, handle tf.Output, n tf.Output, component_types []tf.DataType, ...) (components []tf.Output)
- func QueueDequeueV2(scope *Scope, handle tf.Output, component_types []tf.DataType, ...) (components []tf.Output)
- func QueueEnqueueManyV2(scope *Scope, handle tf.Output, components []tf.Output, ...) (o *tf.Operation)
- func QueueEnqueueV2(scope *Scope, handle tf.Output, components []tf.Output, ...) (o *tf.Operation)
- func QueueIsClosedV2(scope *Scope, handle tf.Output) (is_closed tf.Output)
- func QueueSizeV2(scope *Scope, handle tf.Output) (size tf.Output)
- func RFFT(scope *Scope, input tf.Output, fft_length tf.Output) (output tf.Output)
- func RFFT2D(scope *Scope, input tf.Output, fft_length tf.Output) (output tf.Output)
- func RFFT3D(scope *Scope, input tf.Output, fft_length tf.Output) (output tf.Output)
- func RGBToHSV(scope *Scope, images tf.Output) (output tf.Output)
- func RandomCrop(scope *Scope, image tf.Output, size tf.Output, optional ...RandomCropAttr) (output tf.Output)
- func RandomDataset(scope *Scope, seed tf.Output, seed2 tf.Output, output_types []tf.DataType, ...) (handle tf.Output)
- func RandomGamma(scope *Scope, shape tf.Output, alpha tf.Output, optional ...RandomGammaAttr) (output tf.Output)
- func RandomPoisson(scope *Scope, shape tf.Output, rate tf.Output, optional ...RandomPoissonAttr) (output tf.Output)
- func RandomPoissonV2(scope *Scope, shape tf.Output, rate tf.Output, optional ...RandomPoissonV2Attr) (output tf.Output)
- func RandomShuffle(scope *Scope, value tf.Output, optional ...RandomShuffleAttr) (output tf.Output)
- func RandomShuffleQueueV2(scope *Scope, component_types []tf.DataType, ...) (handle tf.Output)
- func RandomStandardNormal(scope *Scope, shape tf.Output, dtype tf.DataType, ...) (output tf.Output)
- func RandomUniform(scope *Scope, shape tf.Output, dtype tf.DataType, ...) (output tf.Output)
- func RandomUniformInt(scope *Scope, shape tf.Output, minval tf.Output, maxval tf.Output, ...) (output tf.Output)
- func Range(scope *Scope, start tf.Output, limit tf.Output, delta tf.Output) (output tf.Output)
- func RangeDataset(scope *Scope, start tf.Output, stop tf.Output, step tf.Output, ...) (handle tf.Output)
- func Rank(scope *Scope, input tf.Output) (output tf.Output)
- func ReadFile(scope *Scope, filename tf.Output) (contents tf.Output)
- func ReadVariableOp(scope *Scope, resource tf.Output, dtype tf.DataType) (value tf.Output)
- func ReaderNumRecordsProducedV2(scope *Scope, reader_handle tf.Output) (records_produced tf.Output)
- func ReaderNumWorkUnitsCompletedV2(scope *Scope, reader_handle tf.Output) (units_completed tf.Output)
- func ReaderReadUpToV2(scope *Scope, reader_handle tf.Output, queue_handle tf.Output, ...) (keys tf.Output, values tf.Output)
- func ReaderReadV2(scope *Scope, reader_handle tf.Output, queue_handle tf.Output) (key tf.Output, value tf.Output)
- func ReaderResetV2(scope *Scope, reader_handle tf.Output) (o *tf.Operation)
- func ReaderRestoreStateV2(scope *Scope, reader_handle tf.Output, state tf.Output) (o *tf.Operation)
- func ReaderSerializeStateV2(scope *Scope, reader_handle tf.Output) (state tf.Output)
- func Real(scope *Scope, input tf.Output, optional ...RealAttr) (output tf.Output)
- func RealDiv(scope *Scope, x tf.Output, y tf.Output) (z tf.Output)
- func Reciprocal(scope *Scope, x tf.Output) (y tf.Output)
- func ReciprocalGrad(scope *Scope, y tf.Output, dy tf.Output) (z tf.Output)
- func RecordInput(scope *Scope, file_pattern string, optional ...RecordInputAttr) (records tf.Output)
- func ReduceJoin(scope *Scope, inputs tf.Output, reduction_indices tf.Output, ...) (output tf.Output)
- func Relu(scope *Scope, features tf.Output) (activations tf.Output)
- func Relu6(scope *Scope, features tf.Output) (activations tf.Output)
- func Relu6Grad(scope *Scope, gradients tf.Output, features tf.Output) (backprops tf.Output)
- func ReluGrad(scope *Scope, gradients tf.Output, features tf.Output) (backprops tf.Output)
- func RemoteFusedGraphExecute(scope *Scope, inputs []tf.Output, Toutputs []tf.DataType, ...) (outputs []tf.Output)
- func RepeatDataset(scope *Scope, input_dataset tf.Output, count tf.Output, ...) (handle tf.Output)
- func RequantizationRange(scope *Scope, input tf.Output, input_min tf.Output, input_max tf.Output) (output_min tf.Output, output_max tf.Output)
- func Requantize(scope *Scope, input tf.Output, input_min tf.Output, input_max tf.Output, ...) (output tf.Output, output_min tf.Output, output_max tf.Output)
- func Reshape(scope *Scope, tensor tf.Output, shape tf.Output) (output tf.Output)
- func ResizeArea(scope *Scope, images tf.Output, size tf.Output, optional ...ResizeAreaAttr) (resized_images tf.Output)
- func ResizeBicubic(scope *Scope, images tf.Output, size tf.Output, optional ...ResizeBicubicAttr) (resized_images tf.Output)
- func ResizeBicubicGrad(scope *Scope, grads tf.Output, original_image tf.Output, ...) (output tf.Output)
- func ResizeBilinear(scope *Scope, images tf.Output, size tf.Output, optional ...ResizeBilinearAttr) (resized_images tf.Output)
- func ResizeBilinearGrad(scope *Scope, grads tf.Output, original_image tf.Output, ...) (output tf.Output)
- func ResizeNearestNeighbor(scope *Scope, images tf.Output, size tf.Output, ...) (resized_images tf.Output)
- func ResizeNearestNeighborGrad(scope *Scope, grads tf.Output, size tf.Output, ...) (output tf.Output)
- func ResourceApplyAdadelta(scope *Scope, var_ tf.Output, accum tf.Output, accum_update tf.Output, ...) (o *tf.Operation)
- func ResourceApplyAdagrad(scope *Scope, var_ tf.Output, accum tf.Output, lr tf.Output, grad tf.Output, ...) (o *tf.Operation)
- func ResourceApplyAdagradDA(scope *Scope, var_ tf.Output, gradient_accumulator tf.Output, ...) (o *tf.Operation)
- func ResourceApplyAdam(scope *Scope, var_ tf.Output, m tf.Output, v tf.Output, beta1_power tf.Output, ...) (o *tf.Operation)
- func ResourceApplyAddSign(scope *Scope, var_ tf.Output, m tf.Output, lr tf.Output, alpha tf.Output, ...) (o *tf.Operation)
- func ResourceApplyCenteredRMSProp(scope *Scope, var_ tf.Output, mg tf.Output, ms tf.Output, mom tf.Output, ...) (o *tf.Operation)
- func ResourceApplyFtrl(scope *Scope, var_ tf.Output, accum tf.Output, linear tf.Output, ...) (o *tf.Operation)
- func ResourceApplyFtrlV2(scope *Scope, var_ tf.Output, accum tf.Output, linear tf.Output, ...) (o *tf.Operation)
- func ResourceApplyGradientDescent(scope *Scope, var_ tf.Output, alpha tf.Output, delta tf.Output, ...) (o *tf.Operation)
- func ResourceApplyMomentum(scope *Scope, var_ tf.Output, accum tf.Output, lr tf.Output, grad tf.Output, ...) (o *tf.Operation)
- func ResourceApplyPowerSign(scope *Scope, var_ tf.Output, m tf.Output, lr tf.Output, logbase tf.Output, ...) (o *tf.Operation)
- func ResourceApplyProximalAdagrad(scope *Scope, var_ tf.Output, accum tf.Output, lr tf.Output, l1 tf.Output, ...) (o *tf.Operation)
- func ResourceApplyProximalGradientDescent(scope *Scope, var_ tf.Output, alpha tf.Output, l1 tf.Output, l2 tf.Output, ...) (o *tf.Operation)
- func ResourceApplyRMSProp(scope *Scope, var_ tf.Output, ms tf.Output, mom tf.Output, lr tf.Output, ...) (o *tf.Operation)
- func ResourceCountUpTo(scope *Scope, resource tf.Output, limit int64, T tf.DataType) (output tf.Output)
- func ResourceGather(scope *Scope, resource tf.Output, indices tf.Output, dtype tf.DataType, ...) (output tf.Output)
- func ResourceScatterAdd(scope *Scope, resource tf.Output, indices tf.Output, updates tf.Output) (o *tf.Operation)
- func ResourceScatterNdUpdate(scope *Scope, ref tf.Output, indices tf.Output, updates tf.Output, ...) (o *tf.Operation)
- func ResourceScatterUpdate(scope *Scope, resource tf.Output, indices tf.Output, updates tf.Output) (o *tf.Operation)
- func ResourceSparseApplyAdadelta(scope *Scope, var_ tf.Output, accum tf.Output, accum_update tf.Output, ...) (o *tf.Operation)
- func ResourceSparseApplyAdagrad(scope *Scope, var_ tf.Output, accum tf.Output, lr tf.Output, grad tf.Output, ...) (o *tf.Operation)
- func ResourceSparseApplyAdagradDA(scope *Scope, var_ tf.Output, gradient_accumulator tf.Output, ...) (o *tf.Operation)
- func ResourceSparseApplyCenteredRMSProp(scope *Scope, var_ tf.Output, mg tf.Output, ms tf.Output, mom tf.Output, ...) (o *tf.Operation)
- func ResourceSparseApplyFtrl(scope *Scope, var_ tf.Output, accum tf.Output, linear tf.Output, ...) (o *tf.Operation)
- func ResourceSparseApplyFtrlV2(scope *Scope, var_ tf.Output, accum tf.Output, linear tf.Output, ...) (o *tf.Operation)
- func ResourceSparseApplyMomentum(scope *Scope, var_ tf.Output, accum tf.Output, lr tf.Output, grad tf.Output, ...) (o *tf.Operation)
- func ResourceSparseApplyProximalAdagrad(scope *Scope, var_ tf.Output, accum tf.Output, lr tf.Output, l1 tf.Output, ...) (o *tf.Operation)
- func ResourceSparseApplyProximalGradientDescent(scope *Scope, var_ tf.Output, alpha tf.Output, l1 tf.Output, l2 tf.Output, ...) (o *tf.Operation)
- func ResourceSparseApplyRMSProp(scope *Scope, var_ tf.Output, ms tf.Output, mom tf.Output, lr tf.Output, ...) (o *tf.Operation)
- func ResourceStridedSliceAssign(scope *Scope, ref tf.Output, begin tf.Output, end tf.Output, strides tf.Output, ...) (o *tf.Operation)
- func Restore(scope *Scope, file_pattern tf.Output, tensor_name tf.Output, dt tf.DataType, ...) (tensor tf.Output)
- func RestoreSlice(scope *Scope, file_pattern tf.Output, tensor_name tf.Output, ...) (tensor tf.Output)
- func RestoreV2(scope *Scope, prefix tf.Output, tensor_names tf.Output, ...) (tensors []tf.Output)
- func Reverse(scope *Scope, tensor tf.Output, dims tf.Output) (output tf.Output)
- func ReverseSequence(scope *Scope, input tf.Output, seq_lengths tf.Output, seq_dim int64, ...) (output tf.Output)
- func ReverseV2(scope *Scope, tensor tf.Output, axis tf.Output) (output tf.Output)
- func RightShift(scope *Scope, x tf.Output, y tf.Output) (z tf.Output)
- func Rint(scope *Scope, x tf.Output) (y tf.Output)
- func Round(scope *Scope, x tf.Output) (y tf.Output)
- func Rsqrt(scope *Scope, x tf.Output) (y tf.Output)
- func RsqrtGrad(scope *Scope, y tf.Output, dy tf.Output) (z tf.Output)
- func SampleDistortedBoundingBox(scope *Scope, image_size tf.Output, bounding_boxes tf.Output, ...) (begin tf.Output, size tf.Output, bboxes tf.Output)
- func SampleDistortedBoundingBoxV2(scope *Scope, image_size tf.Output, bounding_boxes tf.Output, ...) (begin tf.Output, size tf.Output, bboxes tf.Output)
- func Save(scope *Scope, filename tf.Output, tensor_names tf.Output, data []tf.Output) (o *tf.Operation)
- func SaveSlices(scope *Scope, filename tf.Output, tensor_names tf.Output, ...) (o *tf.Operation)
- func SaveV2(scope *Scope, prefix tf.Output, tensor_names tf.Output, ...) (o *tf.Operation)
- func ScalarSummary(scope *Scope, tags tf.Output, values tf.Output) (summary tf.Output)
- func ScatterNd(scope *Scope, indices tf.Output, updates tf.Output, shape tf.Output) (output tf.Output)
- func ScatterNdNonAliasingAdd(scope *Scope, input tf.Output, indices tf.Output, updates tf.Output) (output tf.Output)
- func SdcaFprint(scope *Scope, input tf.Output) (output tf.Output)
- func SdcaOptimizer(scope *Scope, sparse_example_indices []tf.Output, ...) (out_example_state_data tf.Output, out_delta_sparse_weights []tf.Output, ...)
- func SegmentMax(scope *Scope, data tf.Output, segment_ids tf.Output) (output tf.Output)
- func SegmentMean(scope *Scope, data tf.Output, segment_ids tf.Output) (output tf.Output)
- func SegmentMin(scope *Scope, data tf.Output, segment_ids tf.Output) (output tf.Output)
- func SegmentProd(scope *Scope, data tf.Output, segment_ids tf.Output) (output tf.Output)
- func SegmentSum(scope *Scope, data tf.Output, segment_ids tf.Output) (output tf.Output)
- func Select(scope *Scope, condition tf.Output, x tf.Output, y tf.Output) (output tf.Output)
- func SelfAdjointEig(scope *Scope, input tf.Output) (output tf.Output)
- func SelfAdjointEigV2(scope *Scope, input tf.Output, optional ...SelfAdjointEigV2Attr) (e tf.Output, v tf.Output)
- func Selu(scope *Scope, features tf.Output) (activations tf.Output)
- func SeluGrad(scope *Scope, gradients tf.Output, outputs tf.Output) (backprops tf.Output)
- func SerializeIterator(scope *Scope, resource_handle tf.Output) (serialized tf.Output)
- func SerializeManySparse(scope *Scope, sparse_indices tf.Output, sparse_values tf.Output, ...) (serialized_sparse tf.Output)
- func SerializeSparse(scope *Scope, sparse_indices tf.Output, sparse_values tf.Output, ...) (serialized_sparse tf.Output)
- func SerializeTensor(scope *Scope, tensor tf.Output) (serialized tf.Output)
- func SetSize(scope *Scope, set_indices tf.Output, set_values tf.Output, set_shape tf.Output, ...) (size tf.Output)
- func Shape(scope *Scope, input tf.Output, optional ...ShapeAttr) (output tf.Output)
- func ShapeN(scope *Scope, input []tf.Output, optional ...ShapeNAttr) (output []tf.Output)
- func ShardedFilename(scope *Scope, basename tf.Output, shard tf.Output, num_shards tf.Output) (filename tf.Output)
- func ShardedFilespec(scope *Scope, basename tf.Output, num_shards tf.Output) (filename tf.Output)
- func ShuffleAndRepeatDataset(scope *Scope, input_dataset tf.Output, buffer_size tf.Output, seed tf.Output, ...) (handle tf.Output)
- func ShuffleDataset(scope *Scope, input_dataset tf.Output, buffer_size tf.Output, seed tf.Output, ...) (handle tf.Output)
- func Sigmoid(scope *Scope, x tf.Output) (y tf.Output)
- func SigmoidGrad(scope *Scope, y tf.Output, dy tf.Output) (z tf.Output)
- func Sign(scope *Scope, x tf.Output) (y tf.Output)
- func Sin(scope *Scope, x tf.Output) (y tf.Output)
- func Sinh(scope *Scope, x tf.Output) (y tf.Output)
- func Size(scope *Scope, input tf.Output, optional ...SizeAttr) (output tf.Output)
- func SkipDataset(scope *Scope, input_dataset tf.Output, count tf.Output, ...) (handle tf.Output)
- func Skipgram(scope *Scope, filename string, batch_size int64, optional ...SkipgramAttr) (vocab_word tf.Output, vocab_freq tf.Output, words_per_epoch tf.Output, ...)
- func Slice(scope *Scope, input tf.Output, begin tf.Output, size tf.Output) (output tf.Output)
- func Snapshot(scope *Scope, input tf.Output) (output tf.Output)
- func Softmax(scope *Scope, logits tf.Output) (softmax tf.Output)
- func SoftmaxCrossEntropyWithLogits(scope *Scope, features tf.Output, labels tf.Output) (loss tf.Output, backprop tf.Output)
- func Softplus(scope *Scope, features tf.Output) (activations tf.Output)
- func SoftplusGrad(scope *Scope, gradients tf.Output, features tf.Output) (backprops tf.Output)
- func Softsign(scope *Scope, features tf.Output) (activations tf.Output)
- func SoftsignGrad(scope *Scope, gradients tf.Output, features tf.Output) (backprops tf.Output)
- func SpaceToBatch(scope *Scope, input tf.Output, paddings tf.Output, block_size int64) (output tf.Output)
- func SpaceToBatchND(scope *Scope, input tf.Output, block_shape tf.Output, paddings tf.Output) (output tf.Output)
- func SpaceToDepth(scope *Scope, input tf.Output, block_size int64, optional ...SpaceToDepthAttr) (output tf.Output)
- func SparseAdd(scope *Scope, a_indices tf.Output, a_values tf.Output, a_shape tf.Output, ...) (sum_indices tf.Output, sum_values tf.Output, sum_shape tf.Output)
- func SparseAddGrad(scope *Scope, backprop_val_grad tf.Output, a_indices tf.Output, ...) (a_val_grad tf.Output, b_val_grad tf.Output)
- func SparseConcat(scope *Scope, indices []tf.Output, values []tf.Output, shapes []tf.Output, ...) (output_indices tf.Output, output_values tf.Output, output_shape tf.Output)
- func SparseCross(scope *Scope, indices []tf.Output, values []tf.Output, shapes []tf.Output, ...) (output_indices tf.Output, output_values tf.Output, output_shape tf.Output)
- func SparseDenseCwiseAdd(scope *Scope, sp_indices tf.Output, sp_values tf.Output, sp_shape tf.Output, ...) (output tf.Output)
- func SparseDenseCwiseDiv(scope *Scope, sp_indices tf.Output, sp_values tf.Output, sp_shape tf.Output, ...) (output tf.Output)
- func SparseDenseCwiseMul(scope *Scope, sp_indices tf.Output, sp_values tf.Output, sp_shape tf.Output, ...) (output tf.Output)
- func SparseFillEmptyRows(scope *Scope, indices tf.Output, values tf.Output, dense_shape tf.Output, ...) (output_indices tf.Output, output_values tf.Output, ...)
- func SparseFillEmptyRowsGrad(scope *Scope, reverse_index_map tf.Output, grad_values tf.Output) (d_values tf.Output, d_default_value tf.Output)
- func SparseMatMul(scope *Scope, a tf.Output, b tf.Output, optional ...SparseMatMulAttr) (product tf.Output)
- func SparseReduceMax(scope *Scope, input_indices tf.Output, input_values tf.Output, ...) (output tf.Output)
- func SparseReduceMaxSparse(scope *Scope, input_indices tf.Output, input_values tf.Output, ...) (output_indices tf.Output, output_values tf.Output, output_shape tf.Output)
- func SparseReduceSum(scope *Scope, input_indices tf.Output, input_values tf.Output, ...) (output tf.Output)
- func SparseReduceSumSparse(scope *Scope, input_indices tf.Output, input_values tf.Output, ...) (output_indices tf.Output, output_values tf.Output, output_shape tf.Output)
- func SparseReorder(scope *Scope, input_indices tf.Output, input_values tf.Output, ...) (output_indices tf.Output, output_values tf.Output)
- func SparseReshape(scope *Scope, input_indices tf.Output, input_shape tf.Output, ...) (output_indices tf.Output, output_shape tf.Output)
- func SparseSegmentMean(scope *Scope, data tf.Output, indices tf.Output, segment_ids tf.Output) (output tf.Output)
- func SparseSegmentMeanGrad(scope *Scope, grad tf.Output, indices tf.Output, segment_ids tf.Output, ...) (output tf.Output)
- func SparseSegmentMeanWithNumSegments(scope *Scope, data tf.Output, indices tf.Output, segment_ids tf.Output, ...) (output tf.Output)
- func SparseSegmentSqrtN(scope *Scope, data tf.Output, indices tf.Output, segment_ids tf.Output) (output tf.Output)
- func SparseSegmentSqrtNGrad(scope *Scope, grad tf.Output, indices tf.Output, segment_ids tf.Output, ...) (output tf.Output)
- func SparseSegmentSqrtNWithNumSegments(scope *Scope, data tf.Output, indices tf.Output, segment_ids tf.Output, ...) (output tf.Output)
- func SparseSegmentSum(scope *Scope, data tf.Output, indices tf.Output, segment_ids tf.Output) (output tf.Output)
- func SparseSegmentSumWithNumSegments(scope *Scope, data tf.Output, indices tf.Output, segment_ids tf.Output, ...) (output tf.Output)
- func SparseSlice(scope *Scope, indices tf.Output, values tf.Output, shape tf.Output, ...) (output_indices tf.Output, output_values tf.Output, output_shape tf.Output)
- func SparseSoftmax(scope *Scope, sp_indices tf.Output, sp_values tf.Output, sp_shape tf.Output) (output tf.Output)
- func SparseSoftmaxCrossEntropyWithLogits(scope *Scope, features tf.Output, labels tf.Output) (loss tf.Output, backprop tf.Output)
- func SparseSparseMaximum(scope *Scope, a_indices tf.Output, a_values tf.Output, a_shape tf.Output, ...) (output_indices tf.Output, output_values tf.Output)
- func SparseSparseMinimum(scope *Scope, a_indices tf.Output, a_values tf.Output, a_shape tf.Output, ...) (output_indices tf.Output, output_values tf.Output)
- func SparseSplit(scope *Scope, split_dim tf.Output, indices tf.Output, values tf.Output, ...) (output_indices []tf.Output, output_values []tf.Output, ...)
- func SparseTensorDenseAdd(scope *Scope, a_indices tf.Output, a_values tf.Output, a_shape tf.Output, ...) (output tf.Output)
- func SparseTensorDenseMatMul(scope *Scope, a_indices tf.Output, a_values tf.Output, a_shape tf.Output, ...) (product tf.Output)
- func SparseTensorSliceDataset(scope *Scope, indices tf.Output, values tf.Output, dense_shape tf.Output) (handle tf.Output)
- func SparseToDense(scope *Scope, sparse_indices tf.Output, output_shape tf.Output, ...) (dense tf.Output)
- func SparseToSparseSetOperation(scope *Scope, set1_indices tf.Output, set1_values tf.Output, ...) (result_indices tf.Output, result_values tf.Output, result_shape tf.Output)
- func Split(scope *Scope, axis tf.Output, value tf.Output, num_split int64) (output []tf.Output)
- func SplitV(scope *Scope, value tf.Output, size_splits tf.Output, axis tf.Output, ...) (output []tf.Output)
- func SqlDataset(scope *Scope, driver_name tf.Output, data_source_name tf.Output, ...) (handle tf.Output)
- func Sqrt(scope *Scope, x tf.Output) (y tf.Output)
- func SqrtGrad(scope *Scope, y tf.Output, dy tf.Output) (z tf.Output)
- func Square(scope *Scope, x tf.Output) (y tf.Output)
- func SquaredDifference(scope *Scope, x tf.Output, y tf.Output) (z tf.Output)
- func Squeeze(scope *Scope, input tf.Output, optional ...SqueezeAttr) (output tf.Output)
- func StackCloseV2(scope *Scope, handle tf.Output) (o *tf.Operation)
- func StackPopV2(scope *Scope, handle tf.Output, elem_type tf.DataType) (elem tf.Output)
- func StackPushV2(scope *Scope, handle tf.Output, elem tf.Output, optional ...StackPushV2Attr) (output tf.Output)
- func StackV2(scope *Scope, max_size tf.Output, elem_type tf.DataType, ...) (handle tf.Output)
- func Stage(scope *Scope, values []tf.Output, optional ...StageAttr) (o *tf.Operation)
- func StageClear(scope *Scope, dtypes []tf.DataType, optional ...StageClearAttr) (o *tf.Operation)
- func StagePeek(scope *Scope, index tf.Output, dtypes []tf.DataType, optional ...StagePeekAttr) (values []tf.Output)
- func StageSize(scope *Scope, dtypes []tf.DataType, optional ...StageSizeAttr) (size tf.Output)
- func StatelessRandomNormal(scope *Scope, shape tf.Output, seed tf.Output, ...) (output tf.Output)
- func StatelessRandomUniform(scope *Scope, shape tf.Output, seed tf.Output, ...) (output tf.Output)
- func StatelessTruncatedNormal(scope *Scope, shape tf.Output, seed tf.Output, ...) (output tf.Output)
- func StatsAggregatorHandle(scope *Scope, optional ...StatsAggregatorHandleAttr) (handle tf.Output)
- func StatsAggregatorSummary(scope *Scope, iterator tf.Output) (summary tf.Output)
- func StopGradient(scope *Scope, input tf.Output) (output tf.Output)
- func StridedSlice(scope *Scope, input tf.Output, begin tf.Output, end tf.Output, ...) (output tf.Output)
- func StridedSliceGrad(scope *Scope, shape tf.Output, begin tf.Output, end tf.Output, ...) (output tf.Output)
- func StringJoin(scope *Scope, inputs []tf.Output, optional ...StringJoinAttr) (output tf.Output)
- func StringSplit(scope *Scope, input tf.Output, delimiter tf.Output, ...) (indices tf.Output, values tf.Output, shape tf.Output)
- func StringToHashBucket(scope *Scope, string_tensor tf.Output, num_buckets int64) (output tf.Output)
- func StringToHashBucketFast(scope *Scope, input tf.Output, num_buckets int64) (output tf.Output)
- func StringToHashBucketStrong(scope *Scope, input tf.Output, num_buckets int64, key []int64) (output tf.Output)
- func StringToNumber(scope *Scope, string_tensor tf.Output, optional ...StringToNumberAttr) (output tf.Output)
- func Sub(scope *Scope, x tf.Output, y tf.Output) (z tf.Output)
- func Substr(scope *Scope, input tf.Output, pos tf.Output, len tf.Output) (output tf.Output)
- func Sum(scope *Scope, input tf.Output, axis tf.Output, optional ...SumAttr) (output tf.Output)
- func SummaryWriter(scope *Scope, optional ...SummaryWriterAttr) (writer tf.Output)
- func Svd(scope *Scope, input tf.Output, optional ...SvdAttr) (s tf.Output, u tf.Output, v tf.Output)
- func Switch(scope *Scope, data tf.Output, pred tf.Output) (output_false tf.Output, output_true tf.Output)
- func TFRecordDataset(scope *Scope, filenames tf.Output, compression_type tf.Output, ...) (handle tf.Output)
- func TFRecordReaderV2(scope *Scope, optional ...TFRecordReaderV2Attr) (reader_handle tf.Output)
- func TakeDataset(scope *Scope, input_dataset tf.Output, count tf.Output, ...) (handle tf.Output)
- func TakeManySparseFromTensorsMap(scope *Scope, sparse_handles tf.Output, dtype tf.DataType, ...) (sparse_indices tf.Output, sparse_values tf.Output, sparse_shape tf.Output)
- func Tan(scope *Scope, x tf.Output) (y tf.Output)
- func Tanh(scope *Scope, x tf.Output) (y tf.Output)
- func TanhGrad(scope *Scope, y tf.Output, dy tf.Output) (z tf.Output)
- func TensorArrayCloseV2(scope *Scope, handle tf.Output) (o *tf.Operation)
- func TensorArrayCloseV3(scope *Scope, handle tf.Output) (o *tf.Operation)
- func TensorArrayConcatV2(scope *Scope, handle tf.Output, flow_in tf.Output, dtype tf.DataType, ...) (value tf.Output, lengths tf.Output)
- func TensorArrayConcatV3(scope *Scope, handle tf.Output, flow_in tf.Output, dtype tf.DataType, ...) (value tf.Output, lengths tf.Output)
- func TensorArrayGatherV2(scope *Scope, handle tf.Output, indices tf.Output, flow_in tf.Output, ...) (value tf.Output)
- func TensorArrayGatherV3(scope *Scope, handle tf.Output, indices tf.Output, flow_in tf.Output, ...) (value tf.Output)
- func TensorArrayGradV2(scope *Scope, handle tf.Output, flow_in tf.Output, source string) (grad_handle tf.Output)
- func TensorArrayGradV3(scope *Scope, handle tf.Output, flow_in tf.Output, source string) (grad_handle tf.Output, flow_out tf.Output)
- func TensorArrayReadV2(scope *Scope, handle tf.Output, index tf.Output, flow_in tf.Output, ...) (value tf.Output)
- func TensorArrayReadV3(scope *Scope, handle tf.Output, index tf.Output, flow_in tf.Output, ...) (value tf.Output)
- func TensorArrayScatterV2(scope *Scope, handle tf.Output, indices tf.Output, value tf.Output, ...) (flow_out tf.Output)
- func TensorArrayScatterV3(scope *Scope, handle tf.Output, indices tf.Output, value tf.Output, ...) (flow_out tf.Output)
- func TensorArraySizeV2(scope *Scope, handle tf.Output, flow_in tf.Output) (size tf.Output)
- func TensorArraySizeV3(scope *Scope, handle tf.Output, flow_in tf.Output) (size tf.Output)
- func TensorArraySplitV2(scope *Scope, handle tf.Output, value tf.Output, lengths tf.Output, ...) (flow_out tf.Output)
- func TensorArraySplitV3(scope *Scope, handle tf.Output, value tf.Output, lengths tf.Output, ...) (flow_out tf.Output)
- func TensorArrayV2(scope *Scope, size tf.Output, dtype tf.DataType, optional ...TensorArrayV2Attr) (handle tf.Output)
- func TensorArrayV3(scope *Scope, size tf.Output, dtype tf.DataType, optional ...TensorArrayV3Attr) (handle tf.Output, flow tf.Output)
- func TensorArrayWriteV2(scope *Scope, handle tf.Output, index tf.Output, value tf.Output, ...) (flow_out tf.Output)
- func TensorArrayWriteV3(scope *Scope, handle tf.Output, index tf.Output, value tf.Output, ...) (flow_out tf.Output)
- func TensorDataset(scope *Scope, components []tf.Output, output_shapes []tf.Shape) (handle tf.Output)
- func TensorSliceDataset(scope *Scope, components []tf.Output, output_shapes []tf.Shape) (handle tf.Output)
- func TensorSummary(scope *Scope, tensor tf.Output, optional ...TensorSummaryAttr) (summary tf.Output)
- func TensorSummaryV2(scope *Scope, tag tf.Output, tensor tf.Output, ...) (summary tf.Output)
- func TextLineDataset(scope *Scope, filenames tf.Output, compression_type tf.Output, ...) (handle tf.Output)
- func TextLineReaderV2(scope *Scope, optional ...TextLineReaderV2Attr) (reader_handle tf.Output)
- func ThreadUnsafeUnigramCandidateSampler(scope *Scope, true_classes tf.Output, num_true int64, num_sampled int64, ...) (sampled_candidates tf.Output, true_expected_count tf.Output, ...)
- func Tile(scope *Scope, input tf.Output, multiples tf.Output) (output tf.Output)
- func TileGrad(scope *Scope, input tf.Output, multiples tf.Output) (output tf.Output)
- func TopK(scope *Scope, input tf.Output, k int64, optional ...TopKAttr) (values tf.Output, indices tf.Output)
- func TopKV2(scope *Scope, input tf.Output, k tf.Output, optional ...TopKV2Attr) (values tf.Output, indices tf.Output)
- func Transpose(scope *Scope, x tf.Output, perm tf.Output) (y tf.Output)
- func TruncateDiv(scope *Scope, x tf.Output, y tf.Output) (z tf.Output)
- func TruncateMod(scope *Scope, x tf.Output, y tf.Output) (z tf.Output)
- func TruncatedNormal(scope *Scope, shape tf.Output, dtype tf.DataType, ...) (output tf.Output)
- func UniformCandidateSampler(scope *Scope, true_classes tf.Output, num_true int64, num_sampled int64, ...) (sampled_candidates tf.Output, true_expected_count tf.Output, ...)
- func Unique(scope *Scope, x tf.Output, optional ...UniqueAttr) (y tf.Output, idx tf.Output)
- func UniqueV2(scope *Scope, x tf.Output, axis tf.Output, optional ...UniqueV2Attr) (y tf.Output, idx tf.Output)
- func UniqueWithCounts(scope *Scope, x tf.Output, optional ...UniqueWithCountsAttr) (y tf.Output, idx tf.Output, count tf.Output)
- func Unpack(scope *Scope, value tf.Output, num int64, optional ...UnpackAttr) (output []tf.Output)
- func UnsortedSegmentMax(scope *Scope, data tf.Output, segment_ids tf.Output, num_segments tf.Output) (output tf.Output)
- func UnsortedSegmentSum(scope *Scope, data tf.Output, segment_ids tf.Output, num_segments tf.Output) (output tf.Output)
- func Unstage(scope *Scope, dtypes []tf.DataType, optional ...UnstageAttr) (values []tf.Output)
- func VarHandleOp(scope *Scope, dtype tf.DataType, shape tf.Shape, optional ...VarHandleOpAttr) (resource tf.Output)
- func VarIsInitializedOp(scope *Scope, resource tf.Output) (is_initialized tf.Output)
- func VariableShape(scope *Scope, input tf.Output, optional ...VariableShapeAttr) (output tf.Output)
- func Where(scope *Scope, condition tf.Output) (index tf.Output)
- func WholeFileReaderV2(scope *Scope, optional ...WholeFileReaderV2Attr) (reader_handle tf.Output)
- func WriteAudioSummary(scope *Scope, writer tf.Output, step tf.Output, tag tf.Output, ...) (o *tf.Operation)
- func WriteFile(scope *Scope, filename tf.Output, contents tf.Output) (o *tf.Operation)
- func WriteGraphSummary(scope *Scope, writer tf.Output, step tf.Output, tensor tf.Output) (o *tf.Operation)
- func WriteHistogramSummary(scope *Scope, writer tf.Output, step tf.Output, tag tf.Output, ...) (o *tf.Operation)
- func WriteImageSummary(scope *Scope, writer tf.Output, step tf.Output, tag tf.Output, ...) (o *tf.Operation)
- func WriteScalarSummary(scope *Scope, writer tf.Output, step tf.Output, tag tf.Output, value tf.Output) (o *tf.Operation)
- func WriteSummary(scope *Scope, writer tf.Output, step tf.Output, tensor tf.Output, ...) (o *tf.Operation)
- func ZerosLike(scope *Scope, x tf.Output) (y tf.Output)
- func Zeta(scope *Scope, x tf.Output, q tf.Output) (z tf.Output)
- func ZipDataset(scope *Scope, input_datasets []tf.Output, output_types []tf.DataType, ...) (handle tf.Output)
- type AbortAttr
- type AddManySparseToTensorsMapAttr
- type AddSparseToTensorsMapAttr
- type AllAttr
- type AllCandidateSamplerAttr
- type AngleAttr
- type AnyAttr
- type ApproximateEqualAttr
- type ArgMaxAttr
- type ArgMinAttr
- type AsStringAttr
- type AssertAttr
- type AudioSpectrogramAttr
- type AudioSummaryAttr
- type AudioSummaryV2Attr
- type AvgPool3DAttr
- type AvgPool3DGradAttr
- type AvgPoolAttr
- type AvgPoolGradAttr
- type BatchMatMulAttr
- type BiasAddAttr
- type BiasAddGradAttr
- type CTCBeamSearchDecoderAttr
- type CTCGreedyDecoderAttr
- type CTCLossAttr
- type ComplexAbsAttr
- type ComplexAttr
- type ComputeAccidentalHitsAttr
- type Conv2DAttr
- type Conv2DBackpropFilterAttr
- type Conv2DBackpropInputAttr
- type Conv3DAttr
- type Conv3DBackpropFilterV2Attr
- type Conv3DBackpropInputV2Attr
- type CropAndResizeAttr
- type CropAndResizeGradBoxesAttr
- type CropAndResizeGradImageAttr
- type CumprodAttr
- type CumsumAttr
- type DataFormatDimMapAttr
- type DataFormatVecPermuteAttr
- type DecodeAndCropJpegAttr
- func DecodeAndCropJpegAcceptableFraction(value float32) DecodeAndCropJpegAttr
- func DecodeAndCropJpegChannels(value int64) DecodeAndCropJpegAttr
- func DecodeAndCropJpegDctMethod(value string) DecodeAndCropJpegAttr
- func DecodeAndCropJpegFancyUpscaling(value bool) DecodeAndCropJpegAttr
- func DecodeAndCropJpegRatio(value int64) DecodeAndCropJpegAttr
- func DecodeAndCropJpegTryRecoverTruncated(value bool) DecodeAndCropJpegAttr
- type DecodeBmpAttr
- type DecodeCSVAttr
- type DecodeCompressedAttr
- type DecodeJpegAttr
- func DecodeJpegAcceptableFraction(value float32) DecodeJpegAttr
- func DecodeJpegChannels(value int64) DecodeJpegAttr
- func DecodeJpegDctMethod(value string) DecodeJpegAttr
- func DecodeJpegFancyUpscaling(value bool) DecodeJpegAttr
- func DecodeJpegRatio(value int64) DecodeJpegAttr
- func DecodeJpegTryRecoverTruncated(value bool) DecodeJpegAttr
- type DecodePngAttr
- type DecodeRawAttr
- type DecodeWavAttr
- type DenseToDenseSetOperationAttr
- type DenseToSparseSetOperationAttr
- type DepthToSpaceAttr
- type DepthwiseConv2dNativeAttr
- type DepthwiseConv2dNativeBackpropFilterAttr
- type DepthwiseConv2dNativeBackpropInputAttr
- type DequantizeAttr
- type DestroyResourceOpAttr
- type EditDistanceAttr
- type EncodeBase64Attr
- type EncodeJpegAttr
- func EncodeJpegChromaDownsampling(value bool) EncodeJpegAttr
- func EncodeJpegDensityUnit(value string) EncodeJpegAttr
- func EncodeJpegFormat(value string) EncodeJpegAttr
- func EncodeJpegOptimizeSize(value bool) EncodeJpegAttr
- func EncodeJpegProgressive(value bool) EncodeJpegAttr
- func EncodeJpegQuality(value int64) EncodeJpegAttr
- func EncodeJpegXDensity(value int64) EncodeJpegAttr
- func EncodeJpegXmpMetadata(value string) EncodeJpegAttr
- func EncodeJpegYDensity(value int64) EncodeJpegAttr
- type EncodePngAttr
- type EnterAttr
- type ExtractGlimpseAttr
- type ExtractJpegShapeAttr
- type FIFOQueueV2Attr
- type FakeQuantWithMinMaxArgsAttr
- func FakeQuantWithMinMaxArgsMax(value float32) FakeQuantWithMinMaxArgsAttr
- func FakeQuantWithMinMaxArgsMin(value float32) FakeQuantWithMinMaxArgsAttr
- func FakeQuantWithMinMaxArgsNarrowRange(value bool) FakeQuantWithMinMaxArgsAttr
- func FakeQuantWithMinMaxArgsNumBits(value int64) FakeQuantWithMinMaxArgsAttr
- type FakeQuantWithMinMaxArgsGradientAttr
- func FakeQuantWithMinMaxArgsGradientMax(value float32) FakeQuantWithMinMaxArgsGradientAttr
- func FakeQuantWithMinMaxArgsGradientMin(value float32) FakeQuantWithMinMaxArgsGradientAttr
- func FakeQuantWithMinMaxArgsGradientNarrowRange(value bool) FakeQuantWithMinMaxArgsGradientAttr
- func FakeQuantWithMinMaxArgsGradientNumBits(value int64) FakeQuantWithMinMaxArgsGradientAttr
- type FakeQuantWithMinMaxVarsAttr
- type FakeQuantWithMinMaxVarsGradientAttr
- type FakeQuantWithMinMaxVarsPerChannelAttr
- type FakeQuantWithMinMaxVarsPerChannelGradientAttr
- type FixedLengthRecordReaderV2Attr
- func FixedLengthRecordReaderV2Container(value string) FixedLengthRecordReaderV2Attr
- func FixedLengthRecordReaderV2Encoding(value string) FixedLengthRecordReaderV2Attr
- func FixedLengthRecordReaderV2FooterBytes(value int64) FixedLengthRecordReaderV2Attr
- func FixedLengthRecordReaderV2HeaderBytes(value int64) FixedLengthRecordReaderV2Attr
- func FixedLengthRecordReaderV2HopBytes(value int64) FixedLengthRecordReaderV2Attr
- func FixedLengthRecordReaderV2SharedName(value string) FixedLengthRecordReaderV2Attr
- type FixedUnigramCandidateSamplerAttr
- func FixedUnigramCandidateSamplerDistortion(value float32) FixedUnigramCandidateSamplerAttr
- func FixedUnigramCandidateSamplerNumReservedIds(value int64) FixedUnigramCandidateSamplerAttr
- func FixedUnigramCandidateSamplerNumShards(value int64) FixedUnigramCandidateSamplerAttr
- func FixedUnigramCandidateSamplerSeed(value int64) FixedUnigramCandidateSamplerAttr
- func FixedUnigramCandidateSamplerSeed2(value int64) FixedUnigramCandidateSamplerAttr
- func FixedUnigramCandidateSamplerShard(value int64) FixedUnigramCandidateSamplerAttr
- func FixedUnigramCandidateSamplerUnigrams(value []float32) FixedUnigramCandidateSamplerAttr
- func FixedUnigramCandidateSamplerVocabFile(value string) FixedUnigramCandidateSamplerAttr
- type FractionalAvgPoolAttr
- func FractionalAvgPoolDeterministic(value bool) FractionalAvgPoolAttr
- func FractionalAvgPoolOverlapping(value bool) FractionalAvgPoolAttr
- func FractionalAvgPoolPseudoRandom(value bool) FractionalAvgPoolAttr
- func FractionalAvgPoolSeed(value int64) FractionalAvgPoolAttr
- func FractionalAvgPoolSeed2(value int64) FractionalAvgPoolAttr
- type FractionalAvgPoolGradAttr
- type FractionalMaxPoolAttr
- func FractionalMaxPoolDeterministic(value bool) FractionalMaxPoolAttr
- func FractionalMaxPoolOverlapping(value bool) FractionalMaxPoolAttr
- func FractionalMaxPoolPseudoRandom(value bool) FractionalMaxPoolAttr
- func FractionalMaxPoolSeed(value int64) FractionalMaxPoolAttr
- func FractionalMaxPoolSeed2(value int64) FractionalMaxPoolAttr
- type FractionalMaxPoolGradAttr
- type FusedBatchNormAttr
- type FusedBatchNormGradAttr
- type FusedBatchNormGradV2Attr
- type FusedBatchNormV2Attr
- type FusedResizeAndPadConv2DAttr
- type GatherAttr
- type GenerateVocabRemappingAttr
- type HashTableV2Attr
- type HistogramFixedWidthAttr
- type IdentityReaderV2Attr
- type ImagAttr
- type ImageSummaryAttr
- type InitializeTableFromTextFileV2Attr
- type IteratorFromStringHandleAttr
- type LRNAttr
- type LRNGradAttr
- type LearnedUnigramCandidateSamplerAttr
- type ListDiffAttr
- type LoadAndRemapMatrixAttr
- type LogUniformCandidateSamplerAttr
- type MapClearAttr
- type MapIncompleteSizeAttr
- type MapPeekAttr
- type MapSizeAttr
- type MapStageAttr
- type MapUnstageAttr
- type MapUnstageNoKeyAttr
- type MatMulAttr
- type MatrixInverseAttr
- type MatrixSolveAttr
- type MatrixSolveLsAttr
- type MatrixTriangularSolveAttr
- type MaxAttr
- type MaxPool3DAttr
- type MaxPool3DGradAttr
- type MaxPool3DGradGradAttr
- type MaxPoolAttr
- type MaxPoolGradAttr
- type MaxPoolGradGradAttr
- type MaxPoolGradGradV2Attr
- type MaxPoolGradV2Attr
- type MaxPoolV2Attr
- type MaxPoolWithArgmaxAttr
- type MeanAttr
- type MergeV2CheckpointsAttr
- type MfccAttr
- type MinAttr
- type MultinomialAttr
- type MutableDenseHashTableV2Attr
- func MutableDenseHashTableV2Container(value string) MutableDenseHashTableV2Attr
- func MutableDenseHashTableV2InitialNumBuckets(value int64) MutableDenseHashTableV2Attr
- func MutableDenseHashTableV2MaxLoadFactor(value float32) MutableDenseHashTableV2Attr
- func MutableDenseHashTableV2SharedName(value string) MutableDenseHashTableV2Attr
- func MutableDenseHashTableV2UseNodeNameSharing(value bool) MutableDenseHashTableV2Attr
- func MutableDenseHashTableV2ValueShape(value tf.Shape) MutableDenseHashTableV2Attr
- type MutableHashTableOfTensorsV2Attr
- func MutableHashTableOfTensorsV2Container(value string) MutableHashTableOfTensorsV2Attr
- func MutableHashTableOfTensorsV2SharedName(value string) MutableHashTableOfTensorsV2Attr
- func MutableHashTableOfTensorsV2UseNodeNameSharing(value bool) MutableHashTableOfTensorsV2Attr
- func MutableHashTableOfTensorsV2ValueShape(value tf.Shape) MutableHashTableOfTensorsV2Attr
- type MutableHashTableV2Attr
- type NonMaxSuppressionAttr
- type NthElementAttr
- type OneHotAttr
- type OrderedMapClearAttr
- type OrderedMapIncompleteSizeAttr
- func OrderedMapIncompleteSizeCapacity(value int64) OrderedMapIncompleteSizeAttr
- func OrderedMapIncompleteSizeContainer(value string) OrderedMapIncompleteSizeAttr
- func OrderedMapIncompleteSizeMemoryLimit(value int64) OrderedMapIncompleteSizeAttr
- func OrderedMapIncompleteSizeSharedName(value string) OrderedMapIncompleteSizeAttr
- type OrderedMapPeekAttr
- type OrderedMapSizeAttr
- type OrderedMapStageAttr
- type OrderedMapUnstageAttr
- type OrderedMapUnstageNoKeyAttr
- func OrderedMapUnstageNoKeyCapacity(value int64) OrderedMapUnstageNoKeyAttr
- func OrderedMapUnstageNoKeyContainer(value string) OrderedMapUnstageNoKeyAttr
- func OrderedMapUnstageNoKeyMemoryLimit(value int64) OrderedMapUnstageNoKeyAttr
- func OrderedMapUnstageNoKeySharedName(value string) OrderedMapUnstageNoKeyAttr
- type PackAttr
- type PaddingFIFOQueueV2Attr
- type ParameterizedTruncatedNormalAttr
- type ParseSingleSequenceExampleAttr
- func ParseSingleSequenceExampleContextDenseShapes(value []tf.Shape) ParseSingleSequenceExampleAttr
- func ParseSingleSequenceExampleContextSparseTypes(value []tf.DataType) ParseSingleSequenceExampleAttr
- func ParseSingleSequenceExampleFeatureListDenseShapes(value []tf.Shape) ParseSingleSequenceExampleAttr
- func ParseSingleSequenceExampleFeatureListDenseTypes(value []tf.DataType) ParseSingleSequenceExampleAttr
- func ParseSingleSequenceExampleFeatureListSparseTypes(value []tf.DataType) ParseSingleSequenceExampleAttr
- type PlaceholderAttr
- type PreventGradientAttr
- type PrintAttr
- type PriorityQueueV2Attr
- type ProdAttr
- type QrAttr
- type QuantizeAndDequantizeAttr
- func QuantizeAndDequantizeInputMax(value float32) QuantizeAndDequantizeAttr
- func QuantizeAndDequantizeInputMin(value float32) QuantizeAndDequantizeAttr
- func QuantizeAndDequantizeNumBits(value int64) QuantizeAndDequantizeAttr
- func QuantizeAndDequantizeRangeGiven(value bool) QuantizeAndDequantizeAttr
- func QuantizeAndDequantizeSignedInput(value bool) QuantizeAndDequantizeAttr
- type QuantizeAndDequantizeV2Attr
- type QuantizeAndDequantizeV3Attr
- type QuantizeV2Attr
- type QuantizedAddAttr
- type QuantizedConv2DAttr
- type QuantizedInstanceNormAttr
- func QuantizedInstanceNormGivenYMax(value float32) QuantizedInstanceNormAttr
- func QuantizedInstanceNormGivenYMin(value float32) QuantizedInstanceNormAttr
- func QuantizedInstanceNormMinSeparation(value float32) QuantizedInstanceNormAttr
- func QuantizedInstanceNormOutputRangeGiven(value bool) QuantizedInstanceNormAttr
- func QuantizedInstanceNormVarianceEpsilon(value float32) QuantizedInstanceNormAttr
- type QuantizedMatMulAttr
- type QuantizedMulAttr
- type QuantizedRelu6Attr
- type QuantizedReluAttr
- type QuantizedReluXAttr
- type QuantizedResizeBilinearAttr
- type QueueCloseV2Attr
- type QueueDequeueManyV2Attr
- type QueueDequeueUpToV2Attr
- type QueueDequeueV2Attr
- type QueueEnqueueManyV2Attr
- type QueueEnqueueV2Attr
- type RandomCropAttr
- type RandomGammaAttr
- type RandomPoissonAttr
- type RandomPoissonV2Attr
- type RandomShuffleAttr
- type RandomShuffleQueueV2Attr
- func RandomShuffleQueueV2Capacity(value int64) RandomShuffleQueueV2Attr
- func RandomShuffleQueueV2Container(value string) RandomShuffleQueueV2Attr
- func RandomShuffleQueueV2MinAfterDequeue(value int64) RandomShuffleQueueV2Attr
- func RandomShuffleQueueV2Seed(value int64) RandomShuffleQueueV2Attr
- func RandomShuffleQueueV2Seed2(value int64) RandomShuffleQueueV2Attr
- func RandomShuffleQueueV2Shapes(value []tf.Shape) RandomShuffleQueueV2Attr
- func RandomShuffleQueueV2SharedName(value string) RandomShuffleQueueV2Attr
- type RandomStandardNormalAttr
- type RandomUniformAttr
- type RandomUniformIntAttr
- type RealAttr
- type RecordInputAttr
- func RecordInputBatchSize(value int64) RecordInputAttr
- func RecordInputCompressionType(value string) RecordInputAttr
- func RecordInputFileBufferSize(value int64) RecordInputAttr
- func RecordInputFileParallelism(value int64) RecordInputAttr
- func RecordInputFileRandomSeed(value int64) RecordInputAttr
- func RecordInputFileShuffleShiftRatio(value float32) RecordInputAttr
- type ReduceJoinAttr
- type ResizeAreaAttr
- type ResizeBicubicAttr
- type ResizeBicubicGradAttr
- type ResizeBilinearAttr
- type ResizeBilinearGradAttr
- type ResizeNearestNeighborAttr
- type ResizeNearestNeighborGradAttr
- type ResourceApplyAdadeltaAttr
- type ResourceApplyAdagradAttr
- type ResourceApplyAdagradDAAttr
- type ResourceApplyAdamAttr
- type ResourceApplyAddSignAttr
- type ResourceApplyCenteredRMSPropAttr
- type ResourceApplyFtrlAttr
- type ResourceApplyFtrlV2Attr
- type ResourceApplyGradientDescentAttr
- type ResourceApplyMomentumAttr
- type ResourceApplyPowerSignAttr
- type ResourceApplyProximalAdagradAttr
- type ResourceApplyProximalGradientDescentAttr
- type ResourceApplyRMSPropAttr
- type ResourceGatherAttr
- type ResourceScatterNdUpdateAttr
- type ResourceSparseApplyAdadeltaAttr
- type ResourceSparseApplyAdagradAttr
- type ResourceSparseApplyAdagradDAAttr
- type ResourceSparseApplyCenteredRMSPropAttr
- type ResourceSparseApplyFtrlAttr
- type ResourceSparseApplyFtrlV2Attr
- type ResourceSparseApplyMomentumAttr
- type ResourceSparseApplyProximalAdagradAttr
- type ResourceSparseApplyProximalGradientDescentAttr
- type ResourceSparseApplyRMSPropAttr
- type ResourceStridedSliceAssignAttr
- func ResourceStridedSliceAssignBeginMask(value int64) ResourceStridedSliceAssignAttr
- func ResourceStridedSliceAssignEllipsisMask(value int64) ResourceStridedSliceAssignAttr
- func ResourceStridedSliceAssignEndMask(value int64) ResourceStridedSliceAssignAttr
- func ResourceStridedSliceAssignNewAxisMask(value int64) ResourceStridedSliceAssignAttr
- func ResourceStridedSliceAssignShrinkAxisMask(value int64) ResourceStridedSliceAssignAttr
- type RestoreAttr
- type RestoreSliceAttr
- type ReverseSequenceAttr
- type SampleDistortedBoundingBoxAttr
- func SampleDistortedBoundingBoxAreaRange(value []float32) SampleDistortedBoundingBoxAttr
- func SampleDistortedBoundingBoxAspectRatioRange(value []float32) SampleDistortedBoundingBoxAttr
- func SampleDistortedBoundingBoxMaxAttempts(value int64) SampleDistortedBoundingBoxAttr
- func SampleDistortedBoundingBoxMinObjectCovered(value float32) SampleDistortedBoundingBoxAttr
- func SampleDistortedBoundingBoxSeed(value int64) SampleDistortedBoundingBoxAttr
- func SampleDistortedBoundingBoxSeed2(value int64) SampleDistortedBoundingBoxAttr
- func SampleDistortedBoundingBoxUseImageIfNoBoundingBoxes(value bool) SampleDistortedBoundingBoxAttr
- type SampleDistortedBoundingBoxV2Attr
- func SampleDistortedBoundingBoxV2AreaRange(value []float32) SampleDistortedBoundingBoxV2Attr
- func SampleDistortedBoundingBoxV2AspectRatioRange(value []float32) SampleDistortedBoundingBoxV2Attr
- func SampleDistortedBoundingBoxV2MaxAttempts(value int64) SampleDistortedBoundingBoxV2Attr
- func SampleDistortedBoundingBoxV2Seed(value int64) SampleDistortedBoundingBoxV2Attr
- func SampleDistortedBoundingBoxV2Seed2(value int64) SampleDistortedBoundingBoxV2Attr
- func SampleDistortedBoundingBoxV2UseImageIfNoBoundingBoxes(value bool) SampleDistortedBoundingBoxV2Attr
- type Scope
- type SdcaOptimizerAttr
- type SelfAdjointEigV2Attr
- type SerializeManySparseAttr
- type SerializeSparseAttr
- type SetSizeAttr
- type ShapeAttr
- type ShapeNAttr
- type ShuffleDatasetAttr
- type SizeAttr
- type SkipgramAttr
- type SpaceToDepthAttr
- type SparseMatMulAttr
- type SparseReduceMaxAttr
- type SparseReduceMaxSparseAttr
- type SparseReduceSumAttr
- type SparseReduceSumSparseAttr
- type SparseTensorDenseMatMulAttr
- type SparseToDenseAttr
- type SparseToSparseSetOperationAttr
- type SqueezeAttr
- type StackPushV2Attr
- type StackV2Attr
- type StageAttr
- type StageClearAttr
- type StagePeekAttr
- type StageSizeAttr
- type StatelessRandomNormalAttr
- type StatelessRandomUniformAttr
- type StatelessTruncatedNormalAttr
- type StatsAggregatorHandleAttr
- type StridedSliceAttr
- type StridedSliceGradAttr
- func StridedSliceGradBeginMask(value int64) StridedSliceGradAttr
- func StridedSliceGradEllipsisMask(value int64) StridedSliceGradAttr
- func StridedSliceGradEndMask(value int64) StridedSliceGradAttr
- func StridedSliceGradNewAxisMask(value int64) StridedSliceGradAttr
- func StridedSliceGradShrinkAxisMask(value int64) StridedSliceGradAttr
- type StringJoinAttr
- type StringSplitAttr
- type StringToNumberAttr
- type SumAttr
- type SummaryWriterAttr
- type SvdAttr
- type TFRecordReaderV2Attr
- type TakeManySparseFromTensorsMapAttr
- type TensorArrayConcatV2Attr
- type TensorArrayConcatV3Attr
- type TensorArrayGatherV2Attr
- type TensorArrayGatherV3Attr
- type TensorArrayV2Attr
- type TensorArrayV3Attr
- func TensorArrayV3ClearAfterRead(value bool) TensorArrayV3Attr
- func TensorArrayV3DynamicSize(value bool) TensorArrayV3Attr
- func TensorArrayV3ElementShape(value tf.Shape) TensorArrayV3Attr
- func TensorArrayV3IdenticalElementShapes(value bool) TensorArrayV3Attr
- func TensorArrayV3TensorArrayName(value string) TensorArrayV3Attr
- type TensorSummaryAttr
- type TextLineReaderV2Attr
- type ThreadUnsafeUnigramCandidateSamplerAttr
- type TopKAttr
- type TopKV2Attr
- type TruncatedNormalAttr
- type UniformCandidateSamplerAttr
- type UniqueAttr
- type UniqueV2Attr
- type UniqueWithCountsAttr
- type UnpackAttr
- type UnstageAttr
- type VarHandleOpAttr
- type VariableShapeAttr
- type WholeFileReaderV2Attr
- type WriteAudioSummaryAttr
- type WriteImageSummaryAttr
Examples ¶
Constants ¶
This section is empty.
Variables ¶
This section is empty.
Functions ¶
func Abort ¶ added in v1.1.0
Raise a exception to abort the process when called.
If exit_without_error is true, the process will exit normally, otherwise it will exit with a SIGABORT signal.
Returns nothing but an exception.
Returns the created operation.
func Abs ¶ added in v1.1.0
Computes the absolute value of a tensor.
Given a tensor `x`, this operation returns a tensor containing the absolute value of each element in `x`. For example, if x is an input element and y is an output element, this operation computes \\(y = |x|\\).
func AccumulateNV2 ¶ added in v1.5.0
Returns the element-wise sum of a list of tensors.
`tf.accumulate_n_v2` performs the same operation as `tf.add_n`, but does not wait for all of its inputs to be ready before beginning to sum. This can save memory if inputs are ready at different times, since minimum temporary storage is proportional to the output size rather than the inputs size.
Unlike the original `accumulate_n`, `accumulate_n_v2` is differentiable.
Returns a `Tensor` of same shape and type as the elements of `inputs`.
Arguments:
inputs: A list of `Tensor` objects, each with same shape and type. shape: Shape of elements of `inputs`.
func Add ¶ added in v1.1.0
Returns x + y element-wise.
*NOTE*: `Add` supports broadcasting. `AddN` does not. More about broadcasting [here](http://docs.scipy.org/doc/numpy/user/basics.broadcasting.html)
func AddManySparseToTensorsMap ¶ added in v1.1.0
func AddManySparseToTensorsMap(scope *Scope, sparse_indices tf.Output, sparse_values tf.Output, sparse_shape tf.Output, optional ...AddManySparseToTensorsMapAttr) (sparse_handles tf.Output)
Add an `N`-minibatch `SparseTensor` to a `SparseTensorsMap`, return `N` handles.
A `SparseTensor` of rank `R` is represented by three tensors: `sparse_indices`, `sparse_values`, and `sparse_shape`, where
```sparse_indices.shape[1] == sparse_shape.shape[0] == R```
An `N`-minibatch of `SparseTensor` objects is represented as a `SparseTensor` having a first `sparse_indices` column taking values between `[0, N)`, where the minibatch size `N == sparse_shape[0]`.
The input `SparseTensor` must have rank `R` greater than 1, and the first dimension is treated as the minibatch dimension. Elements of the `SparseTensor` must be sorted in increasing order of this first dimension. The stored `SparseTensor` objects pointed to by each row of the output `sparse_handles` will have rank `R-1`.
The `SparseTensor` values can then be read out as part of a minibatch by passing the given keys as vector elements to `TakeManySparseFromTensorsMap`. To ensure the correct `SparseTensorsMap` is accessed, ensure that the same `container` and `shared_name` are passed to that Op. If no `shared_name` is provided here, instead use the *name* of the Operation created by calling `AddManySparseToTensorsMap` as the `shared_name` passed to `TakeManySparseFromTensorsMap`. Ensure the Operations are colocated.
Arguments:
sparse_indices: 2-D. The `indices` of the minibatch `SparseTensor`.
`sparse_indices[:, 0]` must be ordered values in `[0, N)`.
sparse_values: 1-D. The `values` of the minibatch `SparseTensor`. sparse_shape: 1-D. The `shape` of the minibatch `SparseTensor`.
The minibatch size `N == sparse_shape[0]`.
Returns 1-D. The handles of the `SparseTensor` now stored in the `SparseTensorsMap`. Shape: `[N]`.
func AddN ¶ added in v1.1.0
Add all input tensors element wise.
Arguments:
inputs: Must all be the same size and shape.
func AddSparseToTensorsMap ¶ added in v1.1.0
func AddSparseToTensorsMap(scope *Scope, sparse_indices tf.Output, sparse_values tf.Output, sparse_shape tf.Output, optional ...AddSparseToTensorsMapAttr) (sparse_handle tf.Output)
Add a `SparseTensor` to a `SparseTensorsMap` return its handle.
A `SparseTensor` is represented by three tensors: `sparse_indices`, `sparse_values`, and `sparse_shape`.
This operator takes the given `SparseTensor` and adds it to a container object (a `SparseTensorsMap`). A unique key within this container is generated in the form of an `int64`, and this is the value that is returned.
The `SparseTensor` can then be read out as part of a minibatch by passing the key as a vector element to `TakeManySparseFromTensorsMap`. To ensure the correct `SparseTensorsMap` is accessed, ensure that the same `container` and `shared_name` are passed to that Op. If no `shared_name` is provided here, instead use the *name* of the Operation created by calling `AddSparseToTensorsMap` as the `shared_name` passed to `TakeManySparseFromTensorsMap`. Ensure the Operations are colocated.
Arguments:
sparse_indices: 2-D. The `indices` of the `SparseTensor`. sparse_values: 1-D. The `values` of the `SparseTensor`. sparse_shape: 1-D. The `shape` of the `SparseTensor`.
Returns 0-D. The handle of the `SparseTensor` now stored in the `SparseTensorsMap`.
func AddV2 ¶ added in v1.5.0
Returns x + y element-wise.
*NOTE*: `Add` supports broadcasting. `AddN` does not. More about broadcasting [here](http://docs.scipy.org/doc/numpy/user/basics.broadcasting.html)
func AdjustContrast ¶ added in v1.1.0
func AdjustContrast(scope *Scope, images tf.Output, contrast_factor tf.Output, min_value tf.Output, max_value tf.Output) (output tf.Output)
Deprecated. Disallowed in GraphDef version >= 2.
DEPRECATED at GraphDef version 2: Use AdjustContrastv2 instead
func AdjustContrastv2 ¶ added in v1.1.0
Adjust the contrast of one or more images.
`images` is a tensor of at least 3 dimensions. The last 3 dimensions are interpreted as `[height, width, channels]`. The other dimensions only represent a collection of images, such as `[batch, height, width, channels].`
Contrast is adjusted independently for each channel of each image.
For each channel, the Op first computes the mean of the image pixels in the channel and then adjusts each component of each pixel to `(x - mean) * contrast_factor + mean`.
Arguments:
images: Images to adjust. At least 3-D. contrast_factor: A float multiplier for adjusting contrast.
Returns The contrast-adjusted image or images.
func AdjustHue ¶ added in v1.1.0
Adjust the hue of one or more images.
`images` is a tensor of at least 3 dimensions. The last dimension is interpretted as channels, and must be three.
The input image is considered in the RGB colorspace. Conceptually, the RGB colors are first mapped into HSV. A delta is then applied all the hue values, and then remapped back to RGB colorspace.
Arguments:
images: Images to adjust. At least 3-D. delta: A float delta to add to the hue.
Returns The hue-adjusted image or images.
func AdjustSaturation ¶ added in v1.1.0
Adjust the saturation of one or more images.
`images` is a tensor of at least 3 dimensions. The last dimension is interpretted as channels, and must be three.
The input image is considered in the RGB colorspace. Conceptually, the RGB colors are first mapped into HSV. A scale is then applied all the saturation values, and then remapped back to RGB colorspace.
Arguments:
images: Images to adjust. At least 3-D. scale: A float scale to add to the saturation.
Returns The hue-adjusted image or images.
func All ¶ added in v1.1.0
Computes the "logical and" of elements across dimensions of a tensor.
Reduces `input` along the dimensions given in `axis`. Unless `keep_dims` is true, the rank of the tensor is reduced by 1 for each entry in `axis`. If `keep_dims` is true, the reduced dimensions are retained with length 1.
Arguments:
input: The tensor to reduce. axis: The dimensions to reduce. Must be in the range
`[-rank(input), rank(input))`.
Returns The reduced tensor.
func AllCandidateSampler ¶ added in v1.1.0
func AllCandidateSampler(scope *Scope, true_classes tf.Output, num_true int64, num_sampled int64, unique bool, optional ...AllCandidateSamplerAttr) (sampled_candidates tf.Output, true_expected_count tf.Output, sampled_expected_count tf.Output)
Generates labels for candidate sampling with a learned unigram distribution.
See explanations of candidate sampling and the data formats at go/candidate-sampling.
For each batch, this op picks a single set of sampled candidate labels.
The advantages of sampling candidates per-batch are simplicity and the possibility of efficient dense matrix multiplication. The disadvantage is that the sampled candidates must be chosen independently of the context and of the true labels.
Arguments:
true_classes: A batch_size * num_true matrix, in which each row contains the
IDs of the num_true target_classes in the corresponding original label.
num_true: Number of true labels per context. num_sampled: Number of candidates to produce. unique: If unique is true, we sample with rejection, so that all sampled
candidates in a batch are unique. This requires some approximation to estimate the post-rejection sampling probabilities.
Returns A vector of length num_sampled, in which each element is the ID of a sampled candidate.A batch_size * num_true matrix, representing the number of times each candidate is expected to occur in a batch of sampled candidates. If unique=true, then this is a probability.A vector of length num_sampled, for each sampled candidate representing the number of times the candidate is expected to occur in a batch of sampled candidates. If unique=true, then this is a probability.
func Angle ¶ added in v1.4.0
Returns the argument of a complex number.
Given a tensor `input` of complex numbers, this operation returns a tensor of type `float` that is the argument of each element in `input`. All elements in `input` must be complex numbers of the form \\(a + bj\\), where *a* is the real part and *b* is the imaginary part.
The argument returned by this operation is of the form \\(atan2(b, a)\\).
For example:
``` # tensor 'input' is [-2.25 + 4.75j, 3.25 + 5.75j] tf.angle(input) ==> [2.0132, 1.056] ```
@compatibility(numpy) Equivalent to np.angle. @end_compatibility
func Any ¶ added in v1.1.0
Computes the "logical or" of elements across dimensions of a tensor.
Reduces `input` along the dimensions given in `axis`. Unless `keep_dims` is true, the rank of the tensor is reduced by 1 for each entry in `axis`. If `keep_dims` is true, the reduced dimensions are retained with length 1.
Arguments:
input: The tensor to reduce. axis: The dimensions to reduce. Must be in the range
`[-rank(input), rank(input))`.
Returns The reduced tensor.
func ApproximateEqual ¶ added in v1.1.0
func ApproximateEqual(scope *Scope, x tf.Output, y tf.Output, optional ...ApproximateEqualAttr) (z tf.Output)
Returns the truth value of abs(x-y) < tolerance element-wise.
func ArgMax ¶ added in v1.1.0
func ArgMax(scope *Scope, input tf.Output, dimension tf.Output, optional ...ArgMaxAttr) (output tf.Output)
Returns the index with the largest value across dimensions of a tensor.
Note that in case of ties the identity of the return value is not guaranteed.
Arguments:
dimension: int32 or int64, must be in the range `[-rank(input), rank(input))`.
Describes which dimension of the input Tensor to reduce across. For vectors, use dimension = 0.
func ArgMin ¶ added in v1.1.0
func ArgMin(scope *Scope, input tf.Output, dimension tf.Output, optional ...ArgMinAttr) (output tf.Output)
Returns the index with the smallest value across dimensions of a tensor.
Note that in case of ties the identity of the return value is not guaranteed.
Arguments:
dimension: int32 or int64, must be in the range `[-rank(input), rank(input))`.
Describes which dimension of the input Tensor to reduce across. For vectors, use dimension = 0.
func AsString ¶ added in v1.1.0
Converts each entry in the given tensor to strings. Supports many numeric
types and boolean.
func Assert ¶ added in v1.1.0
func Assert(scope *Scope, condition tf.Output, data []tf.Output, optional ...AssertAttr) (o *tf.Operation)
Asserts that the given condition is true.
If `condition` evaluates to false, print the list of tensors in `data`. `summarize` determines how many entries of the tensors to print.
Arguments:
condition: The condition to evaluate. data: The tensors to print out when condition is false.
Returns the created operation.
func AssignAddVariableOp ¶ added in v1.1.0
Adds a value to the current value of a variable.
Any ReadVariableOp which depends directly or indirectly on this assign is guaranteed to see the incremented value or a subsequent newer one.
Outputs the incremented value, which can be used to totally order the increments to this variable.
Arguments:
resource: handle to the resource in which to store the variable. value: the value by which the variable will be incremented.
Returns the created operation.
func AssignSubVariableOp ¶ added in v1.1.0
Subtracts a value from the current value of a variable.
Any ReadVariableOp which depends directly or indirectly on this assign is guaranteed to see the incremented value or a subsequent newer one.
Outputs the incremented value, which can be used to totally order the increments to this variable.
Arguments:
resource: handle to the resource in which to store the variable. value: the value by which the variable will be incremented.
Returns the created operation.
func AssignVariableOp ¶ added in v1.1.0
Assigns a new value to a variable.
Any ReadVariableOp with a control dependency on this op is guaranteed to return this value or a subsequent newer value of the variable.
Arguments:
resource: handle to the resource in which to store the variable. value: the value to set the new tensor to use.
Returns the created operation.
func Atan2 ¶ added in v1.2.0
Computes arctangent of `y/x` element-wise, respecting signs of the arguments.
This is the angle \( \theta \in [-\pi, \pi] \) such that \[ x = r \cos(\theta) \] and \[ y = r \sin(\theta) \] where \(r = \sqrt(x^2 + y^2) \).
func AudioSpectrogram ¶ added in v1.2.0
func AudioSpectrogram(scope *Scope, input tf.Output, window_size int64, stride int64, optional ...AudioSpectrogramAttr) (spectrogram tf.Output)
Produces a visualization of audio data over time.
Spectrograms are a standard way of representing audio information as a series of slices of frequency information, one slice for each window of time. By joining these together into a sequence, they form a distinctive fingerprint of the sound over time.
This op expects to receive audio data as an input, stored as floats in the range -1 to 1, together with a window width in samples, and a stride specifying how far to move the window between slices. From this it generates a three dimensional output. The lowest dimension has an amplitude value for each frequency during that time slice. The next dimension is time, with successive frequency slices. The final dimension is for the channels in the input, so a stereo audio input would have two here for example.
This means the layout when converted and saved as an image is rotated 90 degrees clockwise from a typical spectrogram. Time is descending down the Y axis, and the frequency decreases from left to right.
Each value in the result represents the square root of the sum of the real and imaginary parts of an FFT on the current window of samples. In this way, the lowest dimension represents the power of each frequency in the current window, and adjacent windows are concatenated in the next dimension.
To get a more intuitive and visual look at what this operation does, you can run tensorflow/examples/wav_to_spectrogram to read in an audio file and save out the resulting spectrogram as a PNG image.
Arguments:
input: Float representation of audio data. window_size: How wide the input window is in samples. For the highest efficiency
this should be a power of two, but other values are accepted.
stride: How widely apart the center of adjacent sample windows should be.
Returns 3D representation of the audio frequencies as an image.
func AudioSummary ¶ added in v1.1.0
func AudioSummary(scope *Scope, tag tf.Output, tensor tf.Output, sample_rate float32, optional ...AudioSummaryAttr) (summary tf.Output)
Outputs a `Summary` protocol buffer with audio.
DEPRECATED at GraphDef version 15: Use AudioSummaryV2.
The summary has up to `max_outputs` summary values containing audio. The audio is built from `tensor` which must be 3-D with shape `[batch_size, frames, channels]` or 2-D with shape `[batch_size, frames]`. The values are assumed to be in the range of `[-1.0, 1.0]` with a sample rate of `sample_rate`.
The `tag` argument is a scalar `Tensor` of type `string`. It is used to build the `tag` of the summary values:
- If `max_outputs` is 1, the summary value tag is '*tag*/audio'.
- If `max_outputs` is greater than 1, the summary value tags are generated sequentially as '*tag*/audio/0', '*tag*/audio/1', etc.
Arguments:
tag: Scalar. Used to build the `tag` attribute of the summary values. tensor: 2-D of shape `[batch_size, frames]`. sample_rate: The sample rate of the signal in hertz.
Returns Scalar. Serialized `Summary` protocol buffer.
func AudioSummaryV2 ¶ added in v1.1.0
func AudioSummaryV2(scope *Scope, tag tf.Output, tensor tf.Output, sample_rate tf.Output, optional ...AudioSummaryV2Attr) (summary tf.Output)
Outputs a `Summary` protocol buffer with audio.
The summary has up to `max_outputs` summary values containing audio. The audio is built from `tensor` which must be 3-D with shape `[batch_size, frames, channels]` or 2-D with shape `[batch_size, frames]`. The values are assumed to be in the range of `[-1.0, 1.0]` with a sample rate of `sample_rate`.
The `tag` argument is a scalar `Tensor` of type `string`. It is used to build the `tag` of the summary values:
- If `max_outputs` is 1, the summary value tag is '*tag*/audio'.
- If `max_outputs` is greater than 1, the summary value tags are generated sequentially as '*tag*/audio/0', '*tag*/audio/1', etc.
Arguments:
tag: Scalar. Used to build the `tag` attribute of the summary values. tensor: 2-D of shape `[batch_size, frames]`. sample_rate: The sample rate of the signal in hertz.
Returns Scalar. Serialized `Summary` protocol buffer.
func AvgPool ¶ added in v1.1.0
func AvgPool(scope *Scope, value tf.Output, ksize []int64, strides []int64, padding string, optional ...AvgPoolAttr) (output tf.Output)
Performs average pooling on the input.
Each entry in `output` is the mean of the corresponding size `ksize` window in `value`.
Arguments:
value: 4-D with shape `[batch, height, width, channels]`. ksize: The size of the sliding window for each dimension of `value`. strides: The stride of the sliding window for each dimension of `value`. padding: The type of padding algorithm to use.
Returns The average pooled output tensor.
func AvgPool3D ¶ added in v1.1.0
func AvgPool3D(scope *Scope, input tf.Output, ksize []int64, strides []int64, padding string, optional ...AvgPool3DAttr) (output tf.Output)
Performs 3D average pooling on the input.
Arguments:
input: Shape `[batch, depth, rows, cols, channels]` tensor to pool over. ksize: 1-D tensor of length 5. The size of the window for each dimension of
the input tensor. Must have `ksize[0] = ksize[4] = 1`.
strides: 1-D tensor of length 5. The stride of the sliding window for each
dimension of `input`. Must have `strides[0] = strides[4] = 1`.
padding: The type of padding algorithm to use.
Returns The average pooled output tensor.
func AvgPool3DGrad ¶ added in v1.1.0
func AvgPool3DGrad(scope *Scope, orig_input_shape tf.Output, grad tf.Output, ksize []int64, strides []int64, padding string, optional ...AvgPool3DGradAttr) (output tf.Output)
Computes gradients of average pooling function.
Arguments:
orig_input_shape: The original input dimensions. grad: Output backprop of shape `[batch, depth, rows, cols, channels]`. ksize: 1-D tensor of length 5. The size of the window for each dimension of
the input tensor. Must have `ksize[0] = ksize[4] = 1`.
strides: 1-D tensor of length 5. The stride of the sliding window for each
dimension of `input`. Must have `strides[0] = strides[4] = 1`.
padding: The type of padding algorithm to use.
Returns The backprop for input.
func AvgPoolGrad ¶ added in v1.1.0
func AvgPoolGrad(scope *Scope, orig_input_shape tf.Output, grad tf.Output, ksize []int64, strides []int64, padding string, optional ...AvgPoolGradAttr) (output tf.Output)
Computes gradients of the average pooling function.
Arguments:
orig_input_shape: 1-D. Shape of the original input to `avg_pool`. grad: 4-D with shape `[batch, height, width, channels]`. Gradients w.r.t.
the output of `avg_pool`.
ksize: The size of the sliding window for each dimension of the input. strides: The stride of the sliding window for each dimension of the input. padding: The type of padding algorithm to use.
Returns 4-D. Gradients w.r.t. the input of `avg_pool`.
func BatchDataset ¶ added in v1.2.0
func BatchDataset(scope *Scope, input_dataset tf.Output, batch_size tf.Output, output_types []tf.DataType, output_shapes []tf.Shape) (handle tf.Output)
Creates a dataset that batches `batch_size` elements from `input_dataset`.
Arguments:
batch_size: A scalar representing the number of elements to accumulate in a
batch.
func BatchMatMul ¶ added in v1.1.0
func BatchMatMul(scope *Scope, x tf.Output, y tf.Output, optional ...BatchMatMulAttr) (output tf.Output)
Multiplies slices of two tensors in batches.
Multiplies all slices of `Tensor` `x` and `y` (each slice can be viewed as an element of a batch), and arranges the individual results in a single output tensor of the same batch size. Each of the individual slices can optionally be adjointed (to adjoint a matrix means to transpose and conjugate it) before multiplication by setting the `adj_x` or `adj_y` flag to `True`, which are by default `False`.
The input tensors `x` and `y` are 2-D or higher with shape `[..., r_x, c_x]` and `[..., r_y, c_y]`.
The output tensor is 2-D or higher with shape `[..., r_o, c_o]`, where:
r_o = c_x if adj_x else r_x c_o = r_y if adj_y else c_y
It is computed as:
output[..., :, :] = matrix(x[..., :, :]) * matrix(y[..., :, :])
Arguments:
x: 2-D or higher with shape `[..., r_x, c_x]`. y: 2-D or higher with shape `[..., r_y, c_y]`.
Returns 3-D or higher with shape `[..., r_o, c_o]`
func BatchNormWithGlobalNormalization ¶ added in v1.1.0
func BatchNormWithGlobalNormalization(scope *Scope, t tf.Output, m tf.Output, v tf.Output, beta tf.Output, gamma tf.Output, variance_epsilon float32, scale_after_normalization bool) (result tf.Output)
Batch normalization.
DEPRECATED at GraphDef version 9: Use tf.nn.batch_normalization()
This op is deprecated. Prefer `tf.nn.batch_normalization`.
Arguments:
t: A 4D input Tensor. m: A 1D mean Tensor with size matching the last dimension of t.
This is the first output from tf.nn.moments, or a saved moving average thereof.
v: A 1D variance Tensor with size matching the last dimension of t.
This is the second output from tf.nn.moments, or a saved moving average thereof.
beta: A 1D beta Tensor with size matching the last dimension of t.
An offset to be added to the normalized tensor.
gamma: A 1D gamma Tensor with size matching the last dimension of t.
If "scale_after_normalization" is true, this tensor will be multiplied with the normalized tensor.
variance_epsilon: A small float number to avoid dividing by 0. scale_after_normalization: A bool indicating whether the resulted tensor
needs to be multiplied with gamma.
func BatchNormWithGlobalNormalizationGrad ¶ added in v1.1.0
func BatchNormWithGlobalNormalizationGrad(scope *Scope, t tf.Output, m tf.Output, v tf.Output, gamma tf.Output, backprop tf.Output, variance_epsilon float32, scale_after_normalization bool) (dx tf.Output, dm tf.Output, dv tf.Output, db tf.Output, dg tf.Output)
Gradients for batch normalization.
DEPRECATED at GraphDef version 9: Use tf.nn.batch_normalization()
This op is deprecated. See `tf.nn.batch_normalization`.
Arguments:
t: A 4D input Tensor. m: A 1D mean Tensor with size matching the last dimension of t.
This is the first output from tf.nn.moments, or a saved moving average thereof.
v: A 1D variance Tensor with size matching the last dimension of t.
This is the second output from tf.nn.moments, or a saved moving average thereof.
gamma: A 1D gamma Tensor with size matching the last dimension of t.
If "scale_after_normalization" is true, this Tensor will be multiplied with the normalized Tensor.
backprop: 4D backprop Tensor. variance_epsilon: A small float number to avoid dividing by 0. scale_after_normalization: A bool indicating whether the resulted tensor
needs to be multiplied with gamma.
Returns 4D backprop tensor for input.1D backprop tensor for mean.1D backprop tensor for variance.1D backprop tensor for beta.1D backprop tensor for gamma.
func BatchToSpace ¶ added in v1.1.0
func BatchToSpace(scope *Scope, input tf.Output, crops tf.Output, block_size int64) (output tf.Output)
BatchToSpace for 4-D tensors of type T.
This is a legacy version of the more general BatchToSpaceND.
Rearranges (permutes) data from batch into blocks of spatial data, followed by cropping. This is the reverse transformation of SpaceToBatch. More specifically, this op outputs a copy of the input tensor where values from the `batch` dimension are moved in spatial blocks to the `height` and `width` dimensions, followed by cropping along the `height` and `width` dimensions.
Arguments:
input: 4-D tensor with shape
`[batch*block_size*block_size, height_pad/block_size, width_pad/block_size,
depth]`. Note that the batch size of the input tensor must be divisible by
`block_size * block_size`.
crops: 2-D tensor of non-negative integers with shape `[2, 2]`. It specifies
how many elements to crop from the intermediate result across the spatial dimensions as follows:
crops = [[crop_top, crop_bottom], [crop_left, crop_right]]
Returns 4-D with shape `[batch, height, width, depth]`, where:
height = height_pad - crop_top - crop_bottom width = width_pad - crop_left - crop_right
The attr `block_size` must be greater than one. It indicates the block size.
Some examples:
(1) For the following input of shape `[4, 1, 1, 1]` and block_size of 2:
``` [[[[1]]], [[[2]]], [[[3]]], [[[4]]]] ```
The output tensor has shape `[1, 2, 2, 1]` and value:
``` x = [[[[1], [2]], [[3], [4]]]] ```
(2) For the following input of shape `[4, 1, 1, 3]` and block_size of 2:
``` [[[1, 2, 3]], [[4, 5, 6]], [[7, 8, 9]], [[10, 11, 12]]] ```
The output tensor has shape `[1, 2, 2, 3]` and value:
``` x = [[[[1, 2, 3], [4, 5, 6]],
[[7, 8, 9], [10, 11, 12]]]]
```
(3) For the following input of shape `[4, 2, 2, 1]` and block_size of 2:
``` x = [[[[1], [3]], [[9], [11]]],
[[[2], [4]], [[10], [12]]], [[[5], [7]], [[13], [15]]], [[[6], [8]], [[14], [16]]]]
```
The output tensor has shape `[1, 4, 4, 1]` and value:
``` x = [[[1], [2], [3], [4]],
[[5], [6], [7], [8]], [[9], [10], [11], [12]], [[13], [14], [15], [16]]]
```
(4) For the following input of shape `[8, 1, 2, 1]` and block_size of 2:
``` x = [[[[1], [3]]], [[[9], [11]]], [[[2], [4]]], [[[10], [12]]],
[[[5], [7]]], [[[13], [15]]], [[[6], [8]]], [[[14], [16]]]]
```
The output tensor has shape `[2, 2, 4, 1]` and value:
``` x = [[[[1], [3]], [[5], [7]]],
[[[2], [4]], [[10], [12]]], [[[5], [7]], [[13], [15]]], [[[6], [8]], [[14], [16]]]]
```
func BatchToSpaceND ¶ added in v1.1.0
func BatchToSpaceND(scope *Scope, input tf.Output, block_shape tf.Output, crops tf.Output) (output tf.Output)
BatchToSpace for N-D tensors of type T.
This operation reshapes the "batch" dimension 0 into `M + 1` dimensions of shape `block_shape + [batch]`, interleaves these blocks back into the grid defined by the spatial dimensions `[1, ..., M]`, to obtain a result with the same rank as the input. The spatial dimensions of this intermediate result are then optionally cropped according to `crops` to produce the output. This is the reverse of SpaceToBatch. See below for a precise description.
Arguments:
input: N-D with shape `input_shape = [batch] + spatial_shape + remaining_shape`,
where spatial_shape has M dimensions.
block_shape: 1-D with shape `[M]`, all values must be >= 1. crops: 2-D with shape `[M, 2]`, all values must be >= 0. `crops[i] = [crop_start, crop_end]` specifies the amount to crop from input dimension `i + 1`, which corresponds to spatial dimension `i`. It is required that `crop_start[i] + crop_end[i] <= block_shape[i] * input_shape[i + 1]`.
This operation is equivalent to the following steps:
- Reshape `input` to `reshaped` of shape: [block_shape[0], ..., block_shape[M-1], batch / prod(block_shape), input_shape[1], ..., input_shape[N-1]]
Permute dimensions of `reshaped` to produce `permuted` of shape [batch / prod(block_shape),
input_shape[1], block_shape[0], ..., input_shape[M], block_shape[M-1],
input_shape[M+1], ..., input_shape[N-1]]
Reshape `permuted` to produce `reshaped_permuted` of shape [batch / prod(block_shape),
input_shape[1] * block_shape[0], ..., input_shape[M] * block_shape[M-1],
input_shape[M+1], ..., input_shape[N-1]]
Crop the start and end of dimensions `[1, ..., M]` of `reshaped_permuted` according to `crops` to produce the output of shape: [batch / prod(block_shape),
input_shape[1] * block_shape[0] - crops[0,0] - crops[0,1], ..., input_shape[M] * block_shape[M-1] - crops[M-1,0] - crops[M-1,1],
input_shape[M+1], ..., input_shape[N-1]]
Some examples:
(1) For the following input of shape `[4, 1, 1, 1]`, `block_shape = [2, 2]`, and
`crops = [[0, 0], [0, 0]]`:
``` [[[[1]]], [[[2]]], [[[3]]], [[[4]]]] ```
The output tensor has shape `[1, 2, 2, 1]` and value:
``` x = [[[[1], [2]], [[3], [4]]]] ```
(2) For the following input of shape `[4, 1, 1, 3]`, `block_shape = [2, 2]`, and
`crops = [[0, 0], [0, 0]]`:
``` [[[1, 2, 3]], [[4, 5, 6]], [[7, 8, 9]], [[10, 11, 12]]] ```
The output tensor has shape `[1, 2, 2, 3]` and value:
``` x = [[[[1, 2, 3], [4, 5, 6]],
[[7, 8, 9], [10, 11, 12]]]]
```
(3) For the following input of shape `[4, 2, 2, 1]`, `block_shape = [2, 2]`, and
`crops = [[0, 0], [0, 0]]`:
``` x = [[[[1], [3]], [[9], [11]]],
[[[2], [4]], [[10], [12]]], [[[5], [7]], [[13], [15]]], [[[6], [8]], [[14], [16]]]]
```
The output tensor has shape `[1, 4, 4, 1]` and value:
``` x = [[[1], [2], [3], [4]],
[[5], [6], [7], [8]], [[9], [10], [11], [12]], [[13], [14], [15], [16]]]
```
(4) For the following input of shape `[8, 1, 3, 1]`, `block_shape = [2, 2]`, and
`crops = [[0, 0], [2, 0]]`:
``` x = [[[[0], [1], [3]]], [[[0], [9], [11]]],
[[[0], [2], [4]]], [[[0], [10], [12]]], [[[0], [5], [7]]], [[[0], [13], [15]]], [[[0], [6], [8]]], [[[0], [14], [16]]]]
```
The output tensor has shape `[2, 2, 4, 1]` and value:
``` x = [[[[1], [2], [3], [4]],
[[5], [6], [7], [8]]], [[[9], [10], [11], [12]], [[13], [14], [15], [16]]]]
```
func Betainc ¶ added in v1.1.0
Compute the regularized incomplete beta integral \\(I_x(a, b)\\).
The regularized incomplete beta integral is defined as:
\\(I_x(a, b) = \frac{B(x; a, b)}{B(a, b)}\\)
where
\\(B(x; a, b) = \int_0^x t^{a-1} (1 - t)^{b-1} dt\\)
is the incomplete beta function and \\(B(a, b)\\) is the *complete* beta function.
func BiasAdd ¶ added in v1.1.0
func BiasAdd(scope *Scope, value tf.Output, bias tf.Output, optional ...BiasAddAttr) (output tf.Output)
Adds `bias` to `value`.
This is a special case of `tf.add` where `bias` is restricted to be 1-D. Broadcasting is supported, so `value` may have any number of dimensions.
Arguments:
value: Any number of dimensions. bias: 1-D with size the last dimension of `value`.
Returns Broadcasted sum of `value` and `bias`.
func BiasAddGrad ¶ added in v1.1.0
func BiasAddGrad(scope *Scope, out_backprop tf.Output, optional ...BiasAddGradAttr) (output tf.Output)
The backward operation for "BiasAdd" on the "bias" tensor.
It accumulates all the values from out_backprop into the feature dimension. For NHWC data format, the feature dimension is the last. For NCHW data format, the feature dimension is the third-to-last.
Arguments:
out_backprop: Any number of dimensions.
Returns 1-D with size the feature dimension of `out_backprop`.
func BiasAddV1 ¶ added in v1.1.0
Adds `bias` to `value`.
This is a deprecated version of BiasAdd and will be soon removed.
This is a special case of `tf.add` where `bias` is restricted to be 1-D. Broadcasting is supported, so `value` may have any number of dimensions.
Arguments:
value: Any number of dimensions. bias: 1-D with size the last dimension of `value`.
Returns Broadcasted sum of `value` and `bias`.
func Bincount ¶ added in v1.1.0
Counts the number of occurrences of each value in an integer array.
Outputs a vector with length `size` and the same dtype as `weights`. If `weights` are empty, then index `i` stores the number of times the value `i` is counted in `arr`. If `weights` are non-empty, then index `i` stores the sum of the value in `weights` at each index where the corresponding value in `arr` is `i`.
Values in `arr` outside of the range [0, size) are ignored.
Arguments:
arr: int32 `Tensor`. size: non-negative int32 scalar `Tensor`. weights: is an int32, int64, float32, or float64 `Tensor` with the same
shape as `arr`, or a length-0 `Tensor`, in which case it acts as all weights equal to 1.
Returns 1D `Tensor` with length equal to `size`. The counts or summed weights for each value in the range [0, size).
func Bitcast ¶ added in v1.1.0
Bitcasts a tensor from one type to another without copying data.
Given a tensor `input`, this operation returns a tensor that has the same buffer data as `input` with datatype `type`.
If the input datatype `T` is larger than the output datatype `type` then the shape changes from [...] to [..., sizeof(`T`)/sizeof(`type`)].
If `T` is smaller than `type`, the operator requires that the rightmost dimension be equal to sizeof(`type`)/sizeof(`T`). The shape then goes from [..., sizeof(`type`)/sizeof(`T`)] to [...].
*NOTE*: Bitcast is implemented as a low-level cast, so machines with different endian orderings will give different results.
func BitwiseAnd ¶ added in v1.3.0
Elementwise computes the bitwise AND of `x` and `y`.
The result will have those bits set, that are set in both `x` and `y`. The computation is performed on the underlying representations of `x` and `y`.
func BitwiseOr ¶ added in v1.3.0
Elementwise computes the bitwise OR of `x` and `y`.
The result will have those bits set, that are set in `x`, `y` or both. The computation is performed on the underlying representations of `x` and `y`.
func BitwiseXor ¶ added in v1.3.0
Elementwise computes the bitwise XOR of `x` and `y`.
The result will have those bits set, that are different in `x` and `y`. The computation is performed on the underlying representations of `x` and `y`.
func BroadcastArgs ¶ added in v1.1.0
Return the shape of s0 op s1 with broadcast.
Given `s0` and `s1`, tensors that represent shapes, compute `r0`, the broadcasted shape. `s0`, `s1` and `r0` are all integer vectors.
func BroadcastGradientArgs ¶ added in v1.1.0
Return the reduction indices for computing gradients of s0 op s1 with broadcast.
This is typically used by gradient computations for a broadcasting operation.
func Bucketize ¶ added in v1.2.0
Bucketizes 'input' based on 'boundaries'.
For example, if the inputs are
boundaries = [0, 10, 100]
input = [[-5, 10000]
[150, 10]
[5, 100]]
then the output will be
output = [[0, 3]
[3, 2]
[1, 3]]
Arguments:
input: Any shape of Tensor contains with int or float type. boundaries: A sorted list of floats gives the boundary of the buckets.
Returns Same shape with 'input', each value of input replaced with bucket index.
@compatibility(numpy) Equivalent to np.digitize. @end_compatibility
func BytesProducedStatsDataset ¶ added in v1.5.0
func BytesProducedStatsDataset(scope *Scope, input_dataset tf.Output, tag tf.Output, output_types []tf.DataType, output_shapes []tf.Shape) (handle tf.Output)
Records the bytes size of each element of `input_dataset` in a StatsAggregator.
func CTCBeamSearchDecoder ¶ added in v1.1.0
func CTCBeamSearchDecoder(scope *Scope, inputs tf.Output, sequence_length tf.Output, beam_width int64, top_paths int64, optional ...CTCBeamSearchDecoderAttr) (decoded_indices []tf.Output, decoded_values []tf.Output, decoded_shape []tf.Output, log_probability tf.Output)
Performs beam search decoding on the logits given in input.
A note about the attribute merge_repeated: For the beam search decoder, this means that if consecutive entries in a beam are the same, only the first of these is emitted. That is, when the top path is "A B B B B", "A B" is returned if merge_repeated = True but "A B B B B" is returned if merge_repeated = False.
Arguments:
inputs: 3-D, shape: `(max_time x batch_size x num_classes)`, the logits. sequence_length: A vector containing sequence lengths, size `(batch)`. beam_width: A scalar >= 0 (beam search beam width). top_paths: A scalar >= 0, <= beam_width (controls output size).
Returns A list (length: top_paths) of indices matrices. Matrix j, size `(total_decoded_outputs[j] x 2)`, has indices of a `SparseTensor<int64, 2>`. The rows store: [batch, time].A list (length: top_paths) of values vectors. Vector j, size `(length total_decoded_outputs[j])`, has the values of a `SparseTensor<int64, 2>`. The vector stores the decoded classes for beam j.A list (length: top_paths) of shape vector. Vector j, size `(2)`, stores the shape of the decoded `SparseTensor[j]`. Its values are: `[batch_size, max_decoded_length[j]]`.A matrix, shaped: `(batch_size x top_paths)`. The sequence log-probabilities.
func CTCGreedyDecoder ¶ added in v1.1.0
func CTCGreedyDecoder(scope *Scope, inputs tf.Output, sequence_length tf.Output, optional ...CTCGreedyDecoderAttr) (decoded_indices tf.Output, decoded_values tf.Output, decoded_shape tf.Output, log_probability tf.Output)
Performs greedy decoding on the logits given in inputs.
A note about the attribute merge_repeated: if enabled, when consecutive logits' maximum indices are the same, only the first of these is emitted. Labeling the blank '*', the sequence "A B B * B B" becomes "A B B" if merge_repeated = True and "A B B B B" if merge_repeated = False.
Regardless of the value of merge_repeated, if the maximum index of a given time and batch corresponds to the blank, index `(num_classes - 1)`, no new element is emitted.
Arguments:
inputs: 3-D, shape: `(max_time x batch_size x num_classes)`, the logits. sequence_length: A vector containing sequence lengths, size `(batch_size)`.
Returns Indices matrix, size `(total_decoded_outputs x 2)`, of a `SparseTensor<int64, 2>`. The rows store: [batch, time].Values vector, size: `(total_decoded_outputs)`, of a `SparseTensor<int64, 2>`. The vector stores the decoded classes.Shape vector, size `(2)`, of the decoded SparseTensor. Values are: `[batch_size, max_decoded_length]`.Matrix, size `(batch_size x 1)`, containing sequence log-probabilities.
func CTCLoss ¶ added in v1.1.0
func CTCLoss(scope *Scope, inputs tf.Output, labels_indices tf.Output, labels_values tf.Output, sequence_length tf.Output, optional ...CTCLossAttr) (loss tf.Output, gradient tf.Output)
Calculates the CTC Loss (log probability) for each batch entry. Also calculates
the gradient. This class performs the softmax operation for you, so inputs should be e.g. linear projections of outputs by an LSTM.
Arguments:
inputs: 3-D, shape: `(max_time x batch_size x num_classes)`, the logits. labels_indices: The indices of a `SparseTensor<int32, 2>`.
`labels_indices(i, :) == [b, t]` means `labels_values(i)` stores the id for `(batch b, time t)`.
labels_values: The values (labels) associated with the given batch and time. sequence_length: A vector containing sequence lengths (batch).
Returns A vector (batch) containing log-probabilities.The gradient of `loss`. 3-D, shape: `(max_time x batch_size x num_classes)`.
func CacheDataset ¶ added in v1.3.0
func CacheDataset(scope *Scope, input_dataset tf.Output, filename tf.Output, output_types []tf.DataType, output_shapes []tf.Shape) (handle tf.Output)
Creates a dataset that caches elements from `input_dataset`.
A CacheDataset will iterate over the input_dataset, and store tensors. If the cache already exists, the cache will be used. If the cache is inappropriate (e.g. cannot be opened, contains tensors of the wrong shape / size), an error will the returned when used.
Arguments:
filename: A path on the filesystem where we should cache the dataset. Note: this
will be a directory.
func CheckNumerics ¶ added in v1.1.0
Checks a tensor for NaN and Inf values.
When run, reports an `InvalidArgument` error if `tensor` has any values that are not a number (NaN) or infinity (Inf). Otherwise, passes `tensor` as-is.
Arguments:
message: Prefix of the error message.
func Cholesky ¶ added in v1.1.0
Computes the Cholesky decomposition of one or more square matrices.
The input is a tensor of shape `[..., M, M]` whose inner-most 2 dimensions form square matrices.
The input has to be symmetric and positive definite. Only the lower-triangular part of the input will be used for this operation. The upper-triangular part will not be read.
The output is a tensor of the same shape as the input containing the Cholesky decompositions for all input submatrices `[..., :, :]`.
**Note**: The gradient computation on GPU is faster for large matrices but not for large batch dimensions when the submatrices are small. In this case it might be faster to use the CPU.
Arguments:
input: Shape is `[..., M, M]`.
Returns Shape is `[..., M, M]`.
func CholeskyGrad ¶ added in v1.1.0
Computes the reverse mode backpropagated gradient of the Cholesky algorithm.
For an explanation see "Differentiation of the Cholesky algorithm" by Iain Murray http://arxiv.org/abs/1602.07527.
Arguments:
l: Output of batch Cholesky algorithm l = cholesky(A). Shape is `[..., M, M]`.
Algorithm depends only on lower triangular part of the innermost matrices of this tensor.
grad: df/dl where f is some scalar function. Shape is `[..., M, M]`.
Algorithm depends only on lower triangular part of the innermost matrices of this tensor.
Returns Symmetrized version of df/dA . Shape is `[..., M, M]`
func CloseSummaryWriter ¶ added in v1.4.0
Flushes and closes the summary writer.
Also removes it from the resource manager. To reopen, use another CreateSummaryFileWriter op.
Arguments:
writer: A handle to the summary writer resource.
Returns the created operation.
func CompareAndBitpack ¶ added in v1.4.0
Compare values of `input` to `threshold` and pack resulting bits into a `uint8`.
Each comparison returns a boolean `true` (if `input_value > threshold`) or and `false` otherwise.
This operation is useful for Locality-Sensitive-Hashing (LSH) and other algorithms that use hashing approximations of cosine and `L2` distances; codes can be generated from an input via:
```python codebook_size = 50 codebook_bits = codebook_size * 32 codebook = tf.get_variable('codebook', [x.shape[-1].value, codebook_bits],
dtype=x.dtype, initializer=tf.orthogonal_initializer())
codes = compare_and_threshold(tf.matmul(x, codebook), threshold=0.) codes = tf.bitcast(codes, tf.int32) # go from uint8 to int32 # now codes has shape x.shape[:-1] + [codebook_size] ```
**NOTE**: Currently, the innermost dimension of the tensor must be divisible by 8.
Given an `input` shaped `[s0, s1, ..., s_n]`, the output is a `uint8` tensor shaped `[s0, s1, ..., s_n / 8]`.
Arguments:
input: Values to compare against `threshold` and bitpack. threshold: Threshold to compare against.
Returns The bitpacked comparisons.
func Complex ¶ added in v1.1.0
Converts two real numbers to a complex number.
Given a tensor `real` representing the real part of a complex number, and a tensor `imag` representing the imaginary part of a complex number, this operation returns complex numbers elementwise of the form \\(a + bj\\), where *a* represents the `real` part and *b* represents the `imag` part.
The input tensors `real` and `imag` must have the same shape.
For example:
``` # tensor 'real' is [2.25, 3.25] # tensor `imag` is [4.75, 5.75] tf.complex(real, imag) ==> [[2.25 + 4.75j], [3.25 + 5.75j]] ```
func ComplexAbs ¶ added in v1.1.0
Computes the complex absolute value of a tensor.
Given a tensor `x` of complex numbers, this operation returns a tensor of type `float` or `double` that is the absolute value of each element in `x`. All elements in `x` must be complex numbers of the form \\(a + bj\\). The absolute value is computed as \\( \sqrt{a^2 + b^2}\\).
func ComputeAccidentalHits ¶ added in v1.1.0
func ComputeAccidentalHits(scope *Scope, true_classes tf.Output, sampled_candidates tf.Output, num_true int64, optional ...ComputeAccidentalHitsAttr) (indices tf.Output, ids tf.Output, weights tf.Output)
Computes the ids of the positions in sampled_candidates that match true_labels.
When doing log-odds NCE, the result of this op should be passed through a SparseToDense op, then added to the logits of the sampled candidates. This has the effect of 'removing' the sampled labels that match the true labels by making the classifier sure that they are sampled labels.
Arguments:
true_classes: The true_classes output of UnpackSparseLabels. sampled_candidates: The sampled_candidates output of CandidateSampler. num_true: Number of true labels per context.
Returns A vector of indices corresponding to rows of true_candidates.A vector of IDs of positions in sampled_candidates that match a true_label for the row with the corresponding index in indices.A vector of the same length as indices and ids, in which each element is -FLOAT_MAX.
func Concat ¶ added in v1.1.0
Concatenates tensors along one dimension.
Arguments:
concat_dim: 0-D. The dimension along which to concatenate. Must be in the
range [0, rank(values)).
values: The `N` Tensors to concatenate. Their ranks and types must match,
and their sizes must match in all dimensions except `concat_dim`.
Returns A `Tensor` with the concatenation of values stacked along the `concat_dim` dimension. This tensor's shape matches that of `values` except in `concat_dim` where it has the sum of the sizes.
func ConcatOffset ¶ added in v1.1.0
Computes offsets of concat inputs within its output.
For example:
``` # 'x' is [2, 2, 7] # 'y' is [2, 3, 7] # 'z' is [2, 5, 7] concat_offset(2, [x, y, z]) => [0, 0, 0], [0, 2, 0], [0, 5, 0] ```
This is typically used by gradient computations for a concat operation.
Arguments:
concat_dim: The dimension along which to concatenate. shape: The `N` int32 vectors representing shape of tensors being concatenated.
Returns The `N` int32 vectors representing the starting offset of input tensors within the concatenated output.
func ConcatV2 ¶ added in v1.1.0
Concatenates tensors along one dimension.
Arguments:
values: List of `N` Tensors to concatenate. Their ranks and types must match,
and their sizes must match in all dimensions except `concat_dim`.
axis: 0-D. The dimension along which to concatenate. Must be in the
range [-rank(values), rank(values)).
Returns A `Tensor` with the concatenation of values stacked along the `concat_dim` dimension. This tensor's shape matches that of `values` except in `concat_dim` where it has the sum of the sizes.
func ConcatenateDataset ¶ added in v1.3.0
func ConcatenateDataset(scope *Scope, input_dataset tf.Output, another_dataset tf.Output, output_types []tf.DataType, output_shapes []tf.Shape) (handle tf.Output)
Creates a dataset that concatenates `input_dataset` with `another_dataset`.
func Conj ¶ added in v1.1.0
Returns the complex conjugate of a complex number.
Given a tensor `input` of complex numbers, this operation returns a tensor of complex numbers that are the complex conjugate of each element in `input`. The complex numbers in `input` must be of the form \\(a + bj\\), where *a* is the real part and *b* is the imaginary part.
The complex conjugate returned by this operation is of the form \\(a - bj\\).
For example:
``` # tensor 'input' is [-2.25 + 4.75j, 3.25 + 5.75j] tf.conj(input) ==> [-2.25 - 4.75j, 3.25 - 5.75j] ```
func ConjugateTranspose ¶ added in v1.5.0
Shuffle dimensions of x according to a permutation and conjugate the result.
The output `y` has the same rank as `x`. The shapes of `x` and `y` satisfy:
`y.shape[i] == x.shape[perm[i]] for i in [0, 1, ..., rank(x) - 1]` `y[i,j,k,...,s,t,u] == conj(x[perm[i], perm[j], perm[k],...,perm[s], perm[t], perm[u]])`
func ControlTrigger ¶ added in v1.1.0
Does nothing. Serves as a control trigger for scheduling.
Only useful as a placeholder for control edges.
Returns the created operation.
func Conv2D ¶ added in v1.1.0
func Conv2D(scope *Scope, input tf.Output, filter tf.Output, strides []int64, padding string, optional ...Conv2DAttr) (output tf.Output)
Computes a 2-D convolution given 4-D `input` and `filter` tensors.
Given an input tensor of shape `[batch, in_height, in_width, in_channels]` and a filter / kernel tensor of shape `[filter_height, filter_width, in_channels, out_channels]`, this op performs the following:
- Flattens the filter to a 2-D matrix with shape `[filter_height * filter_width * in_channels, output_channels]`.
- Extracts image patches from the input tensor to form a *virtual* tensor of shape `[batch, out_height, out_width, filter_height * filter_width * in_channels]`.
- For each patch, right-multiplies the filter matrix and the image patch vector.
In detail, with the default NHWC format,
output[b, i, j, k] =
sum_{di, dj, q} input[b, strides[1] * i + di, strides[2] * j + dj, q] *
filter[di, dj, q, k]
Must have `strides[0] = strides[3] = 1`. For the most common case of the same horizontal and vertices strides, `strides = [1, stride, stride, 1]`.
Arguments:
input: A 4-D tensor. The dimension order is interpreted according to the value
of `data_format`, see below for details.
filter: A 4-D tensor of shape
`[filter_height, filter_width, in_channels, out_channels]`
strides: 1-D tensor of length 4. The stride of the sliding window for each
dimension of `input`. The dimension order is determined by the value of `data_format`, see below for details.
padding: The type of padding algorithm to use.
Returns A 4-D tensor. The dimension order is determined by the value of `data_format`, see below for details.
func Conv2DBackpropFilter ¶ added in v1.1.0
func Conv2DBackpropFilter(scope *Scope, input tf.Output, filter_sizes tf.Output, out_backprop tf.Output, strides []int64, padding string, optional ...Conv2DBackpropFilterAttr) (output tf.Output)
Computes the gradients of convolution with respect to the filter.
Arguments:
input: 4-D with shape `[batch, in_height, in_width, in_channels]`. filter_sizes: An integer vector representing the tensor shape of `filter`,
where `filter` is a 4-D `[filter_height, filter_width, in_channels, out_channels]` tensor.
out_backprop: 4-D with shape `[batch, out_height, out_width, out_channels]`.
Gradients w.r.t. the output of the convolution.
strides: The stride of the sliding window for each dimension of the input
of the convolution. Must be in the same order as the dimension specified with format.
padding: The type of padding algorithm to use.
Returns 4-D with shape `[filter_height, filter_width, in_channels, out_channels]`. Gradient w.r.t. the `filter` input of the convolution.
func Conv2DBackpropInput ¶ added in v1.1.0
func Conv2DBackpropInput(scope *Scope, input_sizes tf.Output, filter tf.Output, out_backprop tf.Output, strides []int64, padding string, optional ...Conv2DBackpropInputAttr) (output tf.Output)
Computes the gradients of convolution with respect to the input.
Arguments:
input_sizes: An integer vector representing the shape of `input`,
where `input` is a 4-D `[batch, height, width, channels]` tensor.
filter: 4-D with shape
`[filter_height, filter_width, in_channels, out_channels]`.
out_backprop: 4-D with shape `[batch, out_height, out_width, out_channels]`.
Gradients w.r.t. the output of the convolution.
strides: The stride of the sliding window for each dimension of the input
of the convolution. Must be in the same order as the dimension specified with format.
padding: The type of padding algorithm to use.
Returns 4-D with shape `[batch, in_height, in_width, in_channels]`. Gradient w.r.t. the input of the convolution.
func Conv3D ¶ added in v1.1.0
func Conv3D(scope *Scope, input tf.Output, filter tf.Output, strides []int64, padding string, optional ...Conv3DAttr) (output tf.Output)
Computes a 3-D convolution given 5-D `input` and `filter` tensors.
In signal processing, cross-correlation is a measure of similarity of two waveforms as a function of a time-lag applied to one of them. This is also known as a sliding dot product or sliding inner-product.
Our Conv3D implements a form of cross-correlation.
Arguments:
input: Shape `[batch, in_depth, in_height, in_width, in_channels]`. filter: Shape `[filter_depth, filter_height, filter_width, in_channels,
out_channels]`. `in_channels` must match between `input` and `filter`.
strides: 1-D tensor of length 5. The stride of the sliding window for each
dimension of `input`. Must have `strides[0] = strides[4] = 1`.
padding: The type of padding algorithm to use.
func Conv3DBackpropFilter ¶ added in v1.1.0
func Conv3DBackpropFilter(scope *Scope, input tf.Output, filter tf.Output, out_backprop tf.Output, strides []int64, padding string) (output tf.Output)
Computes the gradients of 3-D convolution with respect to the filter.
DEPRECATED at GraphDef version 10: Use Conv3DBackpropFilterV2
Arguments:
input: Shape `[batch, depth, rows, cols, in_channels]`. filter: Shape `[depth, rows, cols, in_channels, out_channels]`.
`in_channels` must match between `input` and `filter`.
out_backprop: Backprop signal of shape `[batch, out_depth, out_rows, out_cols,
out_channels]`.
strides: 1-D tensor of length 5. The stride of the sliding window for each
dimension of `input`. Must have `strides[0] = strides[4] = 1`.
padding: The type of padding algorithm to use.
func Conv3DBackpropFilterV2 ¶ added in v1.1.0
func Conv3DBackpropFilterV2(scope *Scope, input tf.Output, filter_sizes tf.Output, out_backprop tf.Output, strides []int64, padding string, optional ...Conv3DBackpropFilterV2Attr) (output tf.Output)
Computes the gradients of 3-D convolution with respect to the filter.
Arguments:
input: Shape `[batch, depth, rows, cols, in_channels]`. filter_sizes: An integer vector representing the tensor shape of `filter`,
where `filter` is a 5-D `[filter_depth, filter_height, filter_width, in_channels, out_channels]` tensor.
out_backprop: Backprop signal of shape `[batch, out_depth, out_rows, out_cols,
out_channels]`.
strides: 1-D tensor of length 5. The stride of the sliding window for each
dimension of `input`. Must have `strides[0] = strides[4] = 1`.
padding: The type of padding algorithm to use.
func Conv3DBackpropInput ¶ added in v1.1.0
func Conv3DBackpropInput(scope *Scope, input tf.Output, filter tf.Output, out_backprop tf.Output, strides []int64, padding string) (output tf.Output)
Computes the gradients of 3-D convolution with respect to the input.
DEPRECATED at GraphDef version 10: Use Conv3DBackpropInputV2
Arguments:
input: Shape `[batch, depth, rows, cols, in_channels]`. filter: Shape `[depth, rows, cols, in_channels, out_channels]`.
`in_channels` must match between `input` and `filter`.
out_backprop: Backprop signal of shape `[batch, out_depth, out_rows, out_cols,
out_channels]`.
strides: 1-D tensor of length 5. The stride of the sliding window for each
dimension of `input`. Must have `strides[0] = strides[4] = 1`.
padding: The type of padding algorithm to use.
func Conv3DBackpropInputV2 ¶ added in v1.1.0
func Conv3DBackpropInputV2(scope *Scope, input_sizes tf.Output, filter tf.Output, out_backprop tf.Output, strides []int64, padding string, optional ...Conv3DBackpropInputV2Attr) (output tf.Output)
Computes the gradients of 3-D convolution with respect to the input.
Arguments:
input_sizes: An integer vector representing the tensor shape of `input`,
where `input` is a 5-D `[batch, depth, rows, cols, in_channels]` tensor.
filter: Shape `[depth, rows, cols, in_channels, out_channels]`.
`in_channels` must match between `input` and `filter`.
out_backprop: Backprop signal of shape `[batch, out_depth, out_rows, out_cols,
out_channels]`.
strides: 1-D tensor of length 5. The stride of the sliding window for each
dimension of `input`. Must have `strides[0] = strides[4] = 1`.
padding: The type of padding algorithm to use.
func CreateSummaryDbWriter ¶ added in v1.5.0
func CreateSummaryDbWriter(scope *Scope, writer tf.Output, db_uri tf.Output, experiment_name tf.Output, run_name tf.Output, user_name tf.Output) (o *tf.Operation)
Creates summary database writer accessible by given resource handle.
This can be used to write tensors from the execution graph directly to a database. Only SQLite is supported right now. This function will create the schema if it doesn't exist. Entries in the Users, Experiments, and Runs tables will be created automatically if they don't already exist.
Arguments:
writer: Handle to SummaryWriter resource to overwrite. db_uri: For example "file:/tmp/foo.sqlite". experiment_name: Can't contain ASCII control characters or <>. Case
sensitive. If empty, then the Run will not be associated with any Experiment.
run_name: Can't contain ASCII control characters or <>. Case sensitive.
If empty, then each Tag will not be associated with any Run.
user_name: Must be valid as both a DNS label and Linux username. If
empty, then the Experiment will not be associated with any User.
Returns the created operation.
func CreateSummaryFileWriter ¶ added in v1.4.0
func CreateSummaryFileWriter(scope *Scope, writer tf.Output, logdir tf.Output, max_queue tf.Output, flush_millis tf.Output, filename_suffix tf.Output) (o *tf.Operation)
Creates a summary file writer accessible by the given resource handle.
Arguments:
writer: A handle to the summary writer resource logdir: Directory where the event file will be written. max_queue: Size of the queue of pending events and summaries. flush_millis: How often, in milliseconds, to flush the pending events and
summaries to disk.
filename_suffix: Every event file's name is suffixed with this suffix.
Returns the created operation.
func CropAndResize ¶ added in v1.1.0
func CropAndResize(scope *Scope, image tf.Output, boxes tf.Output, box_ind tf.Output, crop_size tf.Output, optional ...CropAndResizeAttr) (crops tf.Output)
Extracts crops from the input image tensor and bilinearly resizes them (possibly
with aspect ratio change) to a common output size specified by `crop_size`. This is more general than the `crop_to_bounding_box` op which extracts a fixed size slice from the input image and does not allow resizing or aspect ratio change.
Returns a tensor with `crops` from the input `image` at positions defined at the bounding box locations in `boxes`. The cropped boxes are all resized (with bilinear interpolation) to a fixed `size = [crop_height, crop_width]`. The result is a 4-D tensor `[num_boxes, crop_height, crop_width, depth]`. The resizing is corner aligned. In particular, if `boxes = [[0, 0, 1, 1]]`, the method will give identical results to using `tf.image.resize_bilinear()` with `align_corners=True`.
Arguments:
image: A 4-D tensor of shape `[batch, image_height, image_width, depth]`.
Both `image_height` and `image_width` need to be positive.
boxes: A 2-D tensor of shape `[num_boxes, 4]`. The `i`-th row of the tensor
specifies the coordinates of a box in the `box_ind[i]` image and is specified in normalized coordinates `[y1, x1, y2, x2]`. A normalized coordinate value of `y` is mapped to the image coordinate at `y * (image_height - 1)`, so as the `[0, 1]` interval of normalized image height is mapped to `[0, image_height - 1]` in image height coordinates. We do allow `y1` > `y2`, in which case the sampled crop is an up-down flipped version of the original image. The width dimension is treated similarly. Normalized coordinates outside the `[0, 1]` range are allowed, in which case we use `extrapolation_value` to extrapolate the input image values.
box_ind: A 1-D tensor of shape `[num_boxes]` with int32 values in `[0, batch)`.
The value of `box_ind[i]` specifies the image that the `i`-th box refers to.
crop_size: A 1-D tensor of 2 elements, `size = [crop_height, crop_width]`. All
cropped image patches are resized to this size. The aspect ratio of the image content is not preserved. Both `crop_height` and `crop_width` need to be positive.
Returns A 4-D tensor of shape `[num_boxes, crop_height, crop_width, depth]`.
func CropAndResizeGradBoxes ¶ added in v1.1.0
func CropAndResizeGradBoxes(scope *Scope, grads tf.Output, image tf.Output, boxes tf.Output, box_ind tf.Output, optional ...CropAndResizeGradBoxesAttr) (output tf.Output)
Computes the gradient of the crop_and_resize op wrt the input boxes tensor.
Arguments:
grads: A 4-D tensor of shape `[num_boxes, crop_height, crop_width, depth]`. image: A 4-D tensor of shape `[batch, image_height, image_width, depth]`.
Both `image_height` and `image_width` need to be positive.
boxes: A 2-D tensor of shape `[num_boxes, 4]`. The `i`-th row of the tensor
specifies the coordinates of a box in the `box_ind[i]` image and is specified in normalized coordinates `[y1, x1, y2, x2]`. A normalized coordinate value of `y` is mapped to the image coordinate at `y * (image_height - 1)`, so as the `[0, 1]` interval of normalized image height is mapped to `[0, image_height - 1] in image height coordinates. We do allow y1 > y2, in which case the sampled crop is an up-down flipped version of the original image. The width dimension is treated similarly. Normalized coordinates outside the `[0, 1]` range are allowed, in which case we use `extrapolation_value` to extrapolate the input image values.
box_ind: A 1-D tensor of shape `[num_boxes]` with int32 values in `[0, batch)`.
The value of `box_ind[i]` specifies the image that the `i`-th box refers to.
Returns A 2-D tensor of shape `[num_boxes, 4]`.
func CropAndResizeGradImage ¶ added in v1.1.0
func CropAndResizeGradImage(scope *Scope, grads tf.Output, boxes tf.Output, box_ind tf.Output, image_size tf.Output, T tf.DataType, optional ...CropAndResizeGradImageAttr) (output tf.Output)
Computes the gradient of the crop_and_resize op wrt the input image tensor.
Arguments:
grads: A 4-D tensor of shape `[num_boxes, crop_height, crop_width, depth]`. boxes: A 2-D tensor of shape `[num_boxes, 4]`. The `i`-th row of the tensor
specifies the coordinates of a box in the `box_ind[i]` image and is specified in normalized coordinates `[y1, x1, y2, x2]`. A normalized coordinate value of `y` is mapped to the image coordinate at `y * (image_height - 1)`, so as the `[0, 1]` interval of normalized image height is mapped to `[0, image_height - 1] in image height coordinates. We do allow y1 > y2, in which case the sampled crop is an up-down flipped version of the original image. The width dimension is treated similarly. Normalized coordinates outside the `[0, 1]` range are allowed, in which case we use `extrapolation_value` to extrapolate the input image values.
box_ind: A 1-D tensor of shape `[num_boxes]` with int32 values in `[0, batch)`.
The value of `box_ind[i]` specifies the image that the `i`-th box refers to.
image_size: A 1-D tensor with value `[batch, image_height, image_width, depth]`
containing the original image size. Both `image_height` and `image_width` need to be positive.
Returns A 4-D tensor of shape `[batch, image_height, image_width, depth]`.
func Cross ¶ added in v1.1.0
Compute the pairwise cross product.
`a` and `b` must be the same shape; they can either be simple 3-element vectors, or any shape where the innermost dimension is 3. In the latter case, each pair of corresponding 3-element vectors is cross-multiplied independently.
Arguments:
a: A tensor containing 3-element vectors. b: Another tensor, of same type and shape as `a`.
Returns Pairwise cross product of the vectors in `a` and `b`.
func Cumprod ¶ added in v1.1.0
Compute the cumulative product of the tensor `x` along `axis`.
By default, this op performs an inclusive cumprod, which means that the first element of the input is identical to the first element of the output:
```python tf.cumprod([a, b, c]) # => [a, a * b, a * b * c] ```
By setting the `exclusive` kwarg to `True`, an exclusive cumprod is performed instead:
```python tf.cumprod([a, b, c], exclusive=True) # => [1, a, a * b] ```
By setting the `reverse` kwarg to `True`, the cumprod is performed in the opposite direction:
```python tf.cumprod([a, b, c], reverse=True) # => [a * b * c, b * c, c] ```
This is more efficient than using separate `tf.reverse` ops.
The `reverse` and `exclusive` kwargs can also be combined:
```python tf.cumprod([a, b, c], exclusive=True, reverse=True) # => [b * c, c, 1] ```
Arguments:
x: A `Tensor`. Must be one of the following types: `float32`, `float64`,
`int64`, `int32`, `uint8`, `uint16`, `int16`, `int8`, `complex64`, `complex128`, `qint8`, `quint8`, `qint32`, `half`.
axis: A `Tensor` of type `int32` (default: 0). Must be in the range
`[-rank(x), rank(x))`.
func Cumsum ¶ added in v1.1.0
Compute the cumulative sum of the tensor `x` along `axis`.
By default, this op performs an inclusive cumsum, which means that the first element of the input is identical to the first element of the output:
```python tf.cumsum([a, b, c]) # => [a, a + b, a + b + c] ```
By setting the `exclusive` kwarg to `True`, an exclusive cumsum is performed instead:
```python tf.cumsum([a, b, c], exclusive=True) # => [0, a, a + b] ```
By setting the `reverse` kwarg to `True`, the cumsum is performed in the opposite direction:
```python tf.cumsum([a, b, c], reverse=True) # => [a + b + c, b + c, c] ```
This is more efficient than using separate `tf.reverse` ops.
The `reverse` and `exclusive` kwargs can also be combined:
```python tf.cumsum([a, b, c], exclusive=True, reverse=True) # => [b + c, c, 0] ```
Arguments:
x: A `Tensor`. Must be one of the following types: `float32`, `float64`,
`int64`, `int32`, `uint8`, `uint16`, `int16`, `int8`, `complex64`, `complex128`, `qint8`, `quint8`, `qint32`, `half`.
axis: A `Tensor` of type `int32` (default: 0). Must be in the range
`[-rank(x), rank(x))`.
func DataFormatDimMap ¶ added in v1.6.0
Returns the dimension index in the destination data format given the one in
the source data format.
Arguments:
x: A Tensor with each element as a dimension index in source data format.
Must be in the range [-4, 4).
Returns A Tensor with each element as a dimension index in destination data format.
func DataFormatVecPermute ¶ added in v1.6.0
func DataFormatVecPermute(scope *Scope, x tf.Output, optional ...DataFormatVecPermuteAttr) (y tf.Output)
Returns the permuted vector/tensor in the destination data format given the
one in the source data format.
Arguments:
x: Vector of size 4 or Tensor of shape (4, 2) in source data format.
Returns Vector of size 4 or Tensor of shape (4, 2) in destination data format.
func DatasetToSingleElement ¶ added in v1.5.0
func DatasetToSingleElement(scope *Scope, dataset tf.Output, output_types []tf.DataType, output_shapes []tf.Shape) (components []tf.Output)
Outputs the single element from the given dataset.
Arguments:
dataset: A handle to a dataset that contains a single element.
Returns The components of the single element of `input`.
func DebugGradientIdentity ¶ added in v1.4.0
Identity op for gradient debugging.
This op is hidden from public in Python. It is used by TensorFlow Debugger to register gradient tensors for gradient debugging. This op operates on non-reference-type tensors.
func DecodeAndCropJpeg ¶ added in v1.4.0
func DecodeAndCropJpeg(scope *Scope, contents tf.Output, crop_window tf.Output, optional ...DecodeAndCropJpegAttr) (image tf.Output)
Decode and Crop a JPEG-encoded image to a uint8 tensor.
The attr `channels` indicates the desired number of color channels for the decoded image.
Accepted values are:
* 0: Use the number of channels in the JPEG-encoded image. * 1: output a grayscale image. * 3: output an RGB image.
If needed, the JPEG-encoded image is transformed to match the requested number of color channels.
The attr `ratio` allows downscaling the image by an integer factor during decoding. Allowed values are: 1, 2, 4, and 8. This is much faster than downscaling the image later.
It is equivalent to a combination of decode and crop, but much faster by only decoding partial jpeg image.
Arguments:
contents: 0-D. The JPEG-encoded image. crop_window: 1-D. The crop window: [crop_y, crop_x, crop_height, crop_width].
Returns 3-D with shape `[height, width, channels]`..
func DecodeBase64 ¶ added in v1.1.0
Decode web-safe base64-encoded strings.
Input may or may not have padding at the end. See EncodeBase64 for padding. Web-safe means that input must use - and _ instead of + and /.
Arguments:
input: Base64 strings to decode.
Returns Decoded strings.
func DecodeBmp ¶ added in v1.3.0
Decode the first frame of a BMP-encoded image to a uint8 tensor.
The attr `channels` indicates the desired number of color channels for the decoded image.
Accepted values are:
* 0: Use the number of channels in the BMP-encoded image. * 3: output an RGB image. * 4: output an RGBA image.
Arguments:
contents: 0-D. The BMP-encoded image.
Returns 3-D with shape `[height, width, channels]`. RGB order
func DecodeCSV ¶ added in v1.1.0
func DecodeCSV(scope *Scope, records tf.Output, record_defaults []tf.Output, optional ...DecodeCSVAttr) (output []tf.Output)
Convert CSV records to tensors. Each column maps to one tensor.
RFC 4180 format is expected for the CSV records. (https://tools.ietf.org/html/rfc4180) Note that we allow leading and trailing spaces with int or float field.
Arguments:
records: Each string is a record/row in the csv and all records should have
the same format.
record_defaults: One tensor per column of the input record, with either a
scalar default value for that column or empty if the column is required.
Returns Each tensor will have the same shape as records.
func DecodeCompressed ¶ added in v1.6.0
func DecodeCompressed(scope *Scope, bytes tf.Output, optional ...DecodeCompressedAttr) (output tf.Output)
Decompress strings.
This op decompresses each element of the `bytes` input `Tensor`, which is assumed to be compressed using the given `compression_type`.
The `output` is a string `Tensor` of the same shape as `bytes`, each element containing the decompressed data from the corresponding element in `bytes`.
Arguments:
bytes: A Tensor of string which is compressed.
Returns A Tensor with the same shape as input `bytes`, uncompressed from bytes.
func DecodeGif ¶ added in v1.1.0
Decode the first frame of a GIF-encoded image to a uint8 tensor.
GIF with frame or transparency compression are not supported convert animated GIF from compressed to uncompressed by:
convert $src.gif -coalesce $dst.gif
This op also supports decoding JPEGs and PNGs, though it is cleaner to use `tf.image.decode_image`.
Arguments:
contents: 0-D. The GIF-encoded image.
Returns 4-D with shape `[num_frames, height, width, 3]`. RGB order
func DecodeJSONExample ¶ added in v1.1.0
Convert JSON-encoded Example records to binary protocol buffer strings.
This op translates a tensor containing Example records, encoded using the [standard JSON mapping](https://developers.google.com/protocol-buffers/docs/proto3#json), into a tensor containing the same records encoded as binary protocol buffers. The resulting tensor can then be fed to any of the other Example-parsing ops.
Arguments:
json_examples: Each string is a JSON object serialized according to the JSON
mapping of the Example proto.
Returns Each string is a binary Example protocol buffer corresponding to the respective element of `json_examples`.
func DecodeJpeg ¶ added in v1.1.0
Decode a JPEG-encoded image to a uint8 tensor.
The attr `channels` indicates the desired number of color channels for the decoded image.
Accepted values are:
* 0: Use the number of channels in the JPEG-encoded image. * 1: output a grayscale image. * 3: output an RGB image.
If needed, the JPEG-encoded image is transformed to match the requested number of color channels.
The attr `ratio` allows downscaling the image by an integer factor during decoding. Allowed values are: 1, 2, 4, and 8. This is much faster than downscaling the image later.
This op also supports decoding PNGs and non-animated GIFs since the interface is the same, though it is cleaner to use `tf.image.decode_image`.
Arguments:
contents: 0-D. The JPEG-encoded image.
Returns 3-D with shape `[height, width, channels]`..
func DecodePng ¶ added in v1.1.0
Decode a PNG-encoded image to a uint8 or uint16 tensor.
The attr `channels` indicates the desired number of color channels for the decoded image.
Accepted values are:
* 0: Use the number of channels in the PNG-encoded image. * 1: output a grayscale image. * 3: output an RGB image. * 4: output an RGBA image.
If needed, the PNG-encoded image is transformed to match the requested number of color channels.
This op also supports decoding JPEGs and non-animated GIFs since the interface is the same, though it is cleaner to use `tf.image.decode_image`.
Arguments:
contents: 0-D. The PNG-encoded image.
Returns 3-D with shape `[height, width, channels]`.
func DecodeRaw ¶ added in v1.1.0
func DecodeRaw(scope *Scope, bytes tf.Output, out_type tf.DataType, optional ...DecodeRawAttr) (output tf.Output)
Reinterpret the bytes of a string as a vector of numbers.
Arguments:
bytes: All the elements must have the same length.
Returns A Tensor with one more dimension than the input `bytes`. The added dimension will have size equal to the length of the elements of `bytes` divided by the number of bytes to represent `out_type`.
func DecodeWav ¶ added in v1.2.0
func DecodeWav(scope *Scope, contents tf.Output, optional ...DecodeWavAttr) (audio tf.Output, sample_rate tf.Output)
Decode a 16-bit PCM WAV file to a float tensor.
The -32768 to 32767 signed 16-bit values will be scaled to -1.0 to 1.0 in float.
When desired_channels is set, if the input contains fewer channels than this then the last channel will be duplicated to give the requested number, else if the input has more channels than requested then the additional channels will be ignored.
If desired_samples is set, then the audio will be cropped or padded with zeroes to the requested length.
The first output contains a Tensor with the content of the audio samples. The lowest dimension will be the number of channels, and the second will be the number of samples. For example, a ten-sample-long stereo WAV file should give an output shape of [10, 2].
Arguments:
contents: The WAV-encoded audio, usually from a file.
Returns 2-D with shape `[length, channels]`.Scalar holding the sample rate found in the WAV header.
func DeleteSessionTensor ¶ added in v1.1.0
Delete the tensor specified by its handle in the session.
Arguments:
handle: The handle for a tensor stored in the session state.
Returns the created operation.
func DenseToDenseSetOperation ¶ added in v1.1.0
func DenseToDenseSetOperation(scope *Scope, set1 tf.Output, set2 tf.Output, set_operation string, optional ...DenseToDenseSetOperationAttr) (result_indices tf.Output, result_values tf.Output, result_shape tf.Output)
Applies set operation along last dimension of 2 `Tensor` inputs.
See SetOperationOp::SetOperationFromContext for values of `set_operation`.
Output `result` is a `SparseTensor` represented by `result_indices`, `result_values`, and `result_shape`. For `set1` and `set2` ranked `n`, this has rank `n` and the same 1st `n-1` dimensions as `set1` and `set2`. The `nth` dimension contains the result of `set_operation` applied to the corresponding `[0...n-1]` dimension of `set`.
Arguments:
set1: `Tensor` with rank `n`. 1st `n-1` dimensions must be the same as `set2`.
Dimension `n` contains values in a set, duplicates are allowed but ignored.
set2: `Tensor` with rank `n`. 1st `n-1` dimensions must be the same as `set1`.
Dimension `n` contains values in a set, duplicates are allowed but ignored.
Returns 2D indices of a `SparseTensor`.1D values of a `SparseTensor`.1D `Tensor` shape of a `SparseTensor`. `result_shape[0...n-1]` is the same as the 1st `n-1` dimensions of `set1` and `set2`, `result_shape[n]` is the max result set size across all `0...n-1` dimensions.
func DenseToSparseBatchDataset ¶ added in v1.2.0
func DenseToSparseBatchDataset(scope *Scope, input_dataset tf.Output, batch_size tf.Output, row_shape tf.Output, output_types []tf.DataType, output_shapes []tf.Shape) (handle tf.Output)
Creates a dataset that batches input elements into a SparseTensor.
Arguments:
input_dataset: A handle to an input dataset. Must have a single component. batch_size: A scalar representing the number of elements to accumulate in a
batch.
row_shape: A vector representing the dense shape of each row in the produced
SparseTensor. The shape may be partially specified, using `-1` to indicate that a particular dimension should use the maximum size of all batch elements.
func DenseToSparseSetOperation ¶ added in v1.1.0
func DenseToSparseSetOperation(scope *Scope, set1 tf.Output, set2_indices tf.Output, set2_values tf.Output, set2_shape tf.Output, set_operation string, optional ...DenseToSparseSetOperationAttr) (result_indices tf.Output, result_values tf.Output, result_shape tf.Output)
Applies set operation along last dimension of `Tensor` and `SparseTensor`.
See SetOperationOp::SetOperationFromContext for values of `set_operation`.
Input `set2` is a `SparseTensor` represented by `set2_indices`, `set2_values`, and `set2_shape`. For `set2` ranked `n`, 1st `n-1` dimensions must be the same as `set1`. Dimension `n` contains values in a set, duplicates are allowed but ignored.
If `validate_indices` is `True`, this op validates the order and range of `set2` indices.
Output `result` is a `SparseTensor` represented by `result_indices`, `result_values`, and `result_shape`. For `set1` and `set2` ranked `n`, this has rank `n` and the same 1st `n-1` dimensions as `set1` and `set2`. The `nth` dimension contains the result of `set_operation` applied to the corresponding `[0...n-1]` dimension of `set`.
Arguments:
set1: `Tensor` with rank `n`. 1st `n-1` dimensions must be the same as `set2`.
Dimension `n` contains values in a set, duplicates are allowed but ignored.
set2_indices: 2D `Tensor`, indices of a `SparseTensor`. Must be in row-major
order.
set2_values: 1D `Tensor`, values of a `SparseTensor`. Must be in row-major
order.
set2_shape: 1D `Tensor`, shape of a `SparseTensor`. `set2_shape[0...n-1]` must
be the same as the 1st `n-1` dimensions of `set1`, `result_shape[n]` is the max set size across `n-1` dimensions.
Returns 2D indices of a `SparseTensor`.1D values of a `SparseTensor`.1D `Tensor` shape of a `SparseTensor`. `result_shape[0...n-1]` is the same as the 1st `n-1` dimensions of `set1` and `set2`, `result_shape[n]` is the max result set size across all `0...n-1` dimensions.
func DepthToSpace ¶ added in v1.1.0
func DepthToSpace(scope *Scope, input tf.Output, block_size int64, optional ...DepthToSpaceAttr) (output tf.Output)
DepthToSpace for tensors of type T.
Rearranges data from depth into blocks of spatial data. This is the reverse transformation of SpaceToDepth. More specifically, this op outputs a copy of the input tensor where values from the `depth` dimension are moved in spatial blocks to the `height` and `width` dimensions. The attr `block_size` indicates the input block size and how the data is moved.
- Chunks of data of size `block_size * block_size` from depth are rearranged into non-overlapping blocks of size `block_size x block_size`
- The width the output tensor is `input_depth * block_size`, whereas the height is `input_height * block_size`.
- The Y, X coordinates within each block of the output image are determined by the high order component of the input channel index.
- The depth of the input tensor must be divisible by `block_size * block_size`.
The `data_format` attr specifies the layout of the input and output tensors with the following options:
"NHWC": `[ batch, height, width, channels ]`
"NCHW": `[ batch, channels, height, width ]`
"NCHW_VECT_C":
`qint8 [ batch, channels / 4, height, width, 4 ]`
It is useful to consider the operation as transforming a 6-D Tensor. e.g. for data_format = NHWC,
Each element in the input tensor can be specified via 6 coordinates,
ordered by decreasing memory layout significance as:
n,iY,iX,bY,bX,oC (where n=batch index, iX, iY means X or Y coordinates
within the input image, bX, bY means coordinates
within the output block, oC means output channels).
The output would be the input transposed to the following layout:
n,iY,bY,iX,bX,oC
This operation is useful for resizing the activations between convolutions (but keeping all data), e.g. instead of pooling. It is also useful for training purely convolutional models.
For example, given an input of shape `[1, 1, 1, 4]`, data_format = "NHWC" and block_size = 2:
``` x = [[[[1, 2, 3, 4]]]]
```
This operation will output a tensor of shape `[1, 2, 2, 1]`:
```
[[[[1], [2]], [[3], [4]]]]
```
Here, the input has a batch of 1 and each batch element has shape `[1, 1, 4]`, the corresponding output will have 2x2 elements and will have a depth of 1 channel (1 = `4 / (block_size * block_size)`). The output element shape is `[2, 2, 1]`.
For an input tensor with larger depth, here of shape `[1, 1, 1, 12]`, e.g.
``` x = [[[[1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12]]]] ```
This operation, for block size of 2, will return the following tensor of shape `[1, 2, 2, 3]`
```
[[[[1, 2, 3], [4, 5, 6]], [[7, 8, 9], [10, 11, 12]]]]
```
Similarly, for the following input of shape `[1 2 2 4]`, and a block size of 2:
``` x = [[[[1, 2, 3, 4],
[5, 6, 7, 8]], [[9, 10, 11, 12], [13, 14, 15, 16]]]]
```
the operator will return the following tensor of shape `[1 4 4 1]`:
``` x = [[[ [1], [2], [5], [6]],
[ [3], [4], [7], [8]], [ [9], [10], [13], [14]], [ [11], [12], [15], [16]]]]
```
Arguments:
block_size: The size of the spatial block, same as in Space2Depth.
func DepthwiseConv2dNative ¶ added in v1.1.0
func DepthwiseConv2dNative(scope *Scope, input tf.Output, filter tf.Output, strides []int64, padding string, optional ...DepthwiseConv2dNativeAttr) (output tf.Output)
Computes a 2-D depthwise convolution given 4-D `input` and `filter` tensors.
Given an input tensor of shape `[batch, in_height, in_width, in_channels]` and a filter / kernel tensor of shape `[filter_height, filter_width, in_channels, channel_multiplier]`, containing `in_channels` convolutional filters of depth 1, `depthwise_conv2d` applies a different filter to each input channel (expanding from 1 channel to `channel_multiplier` channels for each), then concatenates the results together. Thus, the output has `in_channels * channel_multiplier` channels.
``` for k in 0..in_channels-1
for q in 0..channel_multiplier-1
output[b, i, j, k * channel_multiplier + q] =
sum_{di, dj} input[b, strides[1] * i + di, strides[2] * j + dj, k] *
filter[di, dj, k, q]
```
Must have `strides[0] = strides[3] = 1`. For the most common case of the same horizontal and vertices strides, `strides = [1, stride, stride, 1]`.
Arguments:
strides: 1-D of length 4. The stride of the sliding window for each dimension
of `input`.
padding: The type of padding algorithm to use.
func DepthwiseConv2dNativeBackpropFilter ¶ added in v1.1.0
func DepthwiseConv2dNativeBackpropFilter(scope *Scope, input tf.Output, filter_sizes tf.Output, out_backprop tf.Output, strides []int64, padding string, optional ...DepthwiseConv2dNativeBackpropFilterAttr) (output tf.Output)
Computes the gradients of depthwise convolution with respect to the filter.
Arguments:
input: 4-D with shape based on `data_format`. For example, if
`data_format` is 'NHWC' then `input` is a 4-D `[batch, in_height, in_width, in_channels]` tensor.
filter_sizes: An integer vector representing the tensor shape of `filter`,
where `filter` is a 4-D `[filter_height, filter_width, in_channels, depthwise_multiplier]` tensor.
out_backprop: 4-D with shape based on `data_format`.
For example, if `data_format` is 'NHWC' then out_backprop shape is `[batch, out_height, out_width, out_channels]`. Gradients w.r.t. the output of the convolution.
strides: The stride of the sliding window for each dimension of the input
of the convolution.
padding: The type of padding algorithm to use.
Returns 4-D with shape `[filter_height, filter_width, in_channels, out_channels]`. Gradient w.r.t. the `filter` input of the convolution.
func DepthwiseConv2dNativeBackpropInput ¶ added in v1.1.0
func DepthwiseConv2dNativeBackpropInput(scope *Scope, input_sizes tf.Output, filter tf.Output, out_backprop tf.Output, strides []int64, padding string, optional ...DepthwiseConv2dNativeBackpropInputAttr) (output tf.Output)
Computes the gradients of depthwise convolution with respect to the input.
Arguments:
input_sizes: An integer vector representing the shape of `input`, based
on `data_format`. For example, if `data_format` is 'NHWC' then
`input` is a 4-D `[batch, height, width, channels]` tensor. filter: 4-D with shape
`[filter_height, filter_width, in_channels, depthwise_multiplier]`.
out_backprop: 4-D with shape based on `data_format`.
For example, if `data_format` is 'NHWC' then out_backprop shape is `[batch, out_height, out_width, out_channels]`. Gradients w.r.t. the output of the convolution.
strides: The stride of the sliding window for each dimension of the input
of the convolution.
padding: The type of padding algorithm to use.
Returns 4-D with shape according to `data_format`. For example, if `data_format` is 'NHWC', output shape is `[batch, in_height, in_width, in_channels]`. Gradient w.r.t. the input of the convolution.
func Dequantize ¶ added in v1.1.0
func Dequantize(scope *Scope, input tf.Output, min_range tf.Output, max_range tf.Output, optional ...DequantizeAttr) (output tf.Output)
Dequantize the 'input' tensor into a float Tensor.
[min_range, max_range] are scalar floats that specify the range for the 'input' data. The 'mode' attribute controls exactly which calculations are used to convert the float values to their quantized equivalents.
In 'MIN_COMBINED' mode, each value of the tensor will undergo the following:
``` if T == qint8, in[i] += (range(T) + 1)/ 2.0 out[i] = min_range + (in[i]* (max_range - min_range) / range(T)) ``` here `range(T) = numeric_limits<T>::max() - numeric_limits<T>::min()`
*MIN_COMBINED Mode Example*
If the input comes from a QuantizedRelu6, the output type is quint8 (range of 0-255) but the possible range of QuantizedRelu6 is 0-6. The min_range and max_range values are therefore 0.0 and 6.0. Dequantize on quint8 will take each value, cast to float, and multiply by 6 / 255. Note that if quantizedtype is qint8, the operation will additionally add each value by 128 prior to casting.
If the mode is 'MIN_FIRST', then this approach is used:
```c++ num_discrete_values = 1 << (# of bits in T) range_adjust = num_discrete_values / (num_discrete_values - 1) range = (range_max - range_min) * range_adjust range_scale = range / num_discrete_values const double offset_input = static_cast<double>(input) - lowest_quantized; result = range_min + ((input - numeric_limits<T>::min()) * range_scale) ```
*SCALED mode Example*
`SCALED` mode matches the quantization approach used in `QuantizeAndDequantize{V2|V3}`.
If the mode is `SCALED`, we do not use the full range of the output type, choosing to elide the lowest possible value for symmetry (e.g., output range is -127 to 127, not -128 to 127 for signed 8 bit quantization), so that 0.0 maps to 0.
We first find the range of values in our tensor. The range we use is always centered on 0, so we find m such that ```c++
m = max(abs(input_min), abs(input_max))
```
Our input tensor range is then `[-m, m]`.
Next, we choose our fixed-point quantization buckets, `[min_fixed, max_fixed]`. If T is signed, this is ```
num_bits = sizeof(T) * 8
[min_fixed, max_fixed] =
[-(1 << (num_bits - 1) - 1), (1 << (num_bits - 1)) - 1]
```
Otherwise, if T is unsigned, the fixed-point range is ```
[min_fixed, max_fixed] = [0, (1 << num_bits) - 1]
```
From this we compute our scaling factor, s: ```c++
s = (2 * m) / (max_fixed - min_fixed)
```
Now we can dequantize the elements of our tensor: ```c++ result = input * s ```
Arguments:
min_range: The minimum scalar value possibly produced for the input. max_range: The maximum scalar value possibly produced for the input.
func DeserializeIterator ¶ added in v1.5.0
func DeserializeIterator(scope *Scope, resource_handle tf.Output, serialized tf.Output) (o *tf.Operation)
Converts the given variant tensor to an iterator and stores it in the given resource.
Arguments:
resource_handle: A handle to an iterator resource. serialized: A variant tensor storing the state of the iterator contained in the
resource.
Returns the created operation.
func DeserializeManySparse ¶ added in v1.1.0
func DeserializeManySparse(scope *Scope, serialized_sparse tf.Output, dtype tf.DataType) (sparse_indices tf.Output, sparse_values tf.Output, sparse_shape tf.Output)
Deserialize and concatenate `SparseTensors` from a serialized minibatch.
The input `serialized_sparse` must be a string matrix of shape `[N x 3]` where `N` is the minibatch size and the rows correspond to packed outputs of `SerializeSparse`. The ranks of the original `SparseTensor` objects must all match. When the final `SparseTensor` is created, it has rank one higher than the ranks of the incoming `SparseTensor` objects (they have been concatenated along a new row dimension).
The output `SparseTensor` object's shape values for all dimensions but the first are the max across the input `SparseTensor` objects' shape values for the corresponding dimensions. Its first shape value is `N`, the minibatch size.
The input `SparseTensor` objects' indices are assumed ordered in standard lexicographic order. If this is not the case, after this step run `SparseReorder` to restore index ordering.
For example, if the serialized input is a `[2 x 3]` matrix representing two original `SparseTensor` objects:
index = [ 0]
[10]
[20]
values = [1, 2, 3]
shape = [50]
and
index = [ 2]
[10]
values = [4, 5]
shape = [30]
then the final deserialized `SparseTensor` will be:
index = [0 0]
[0 10]
[0 20]
[1 2]
[1 10]
values = [1, 2, 3, 4, 5]
shape = [2 50]
Arguments:
serialized_sparse: 2-D, The `N` serialized `SparseTensor` objects.
Must have 3 columns.
dtype: The `dtype` of the serialized `SparseTensor` objects.
func DeserializeSparse ¶ added in v1.5.0
func DeserializeSparse(scope *Scope, serialized_sparse tf.Output, dtype tf.DataType) (sparse_indices tf.Output, sparse_values tf.Output, sparse_shape tf.Output)
Deserialize `SparseTensor` objects.
The input `serialized_sparse` must have the shape `[?, ?, ..., ?, 3]` where the last dimension stores serialized `SparseTensor` objects and the other N dimensions (N >= 0) correspond to a batch. The ranks of the original `SparseTensor` objects must all match. When the final `SparseTensor` is created, its rank is the rank of the incoming `SparseTensor` objects plus N; the sparse tensors have been concatenated along new dimensions, one for each batch.
The output `SparseTensor` object's shape values for the original dimensions are the max across the input `SparseTensor` objects' shape values for the corresponding dimensions. The new dimensions match the size of the batch.
The input `SparseTensor` objects' indices are assumed ordered in standard lexicographic order. If this is not the case, after this step run `SparseReorder` to restore index ordering.
For example, if the serialized input is a `[2 x 3]` matrix representing two original `SparseTensor` objects:
index = [ 0]
[10]
[20]
values = [1, 2, 3]
shape = [50]
and
index = [ 2]
[10]
values = [4, 5]
shape = [30]
then the final deserialized `SparseTensor` will be:
index = [0 0]
[0 10]
[0 20]
[1 2]
[1 10]
values = [1, 2, 3, 4, 5]
shape = [2 50]
Arguments:
serialized_sparse: The serialized `SparseTensor` objects. The last dimension
must have 3 columns.
dtype: The `dtype` of the serialized `SparseTensor` objects.
func DestroyResourceOp ¶ added in v1.1.0
func DestroyResourceOp(scope *Scope, resource tf.Output, optional ...DestroyResourceOpAttr) (o *tf.Operation)
Deletes the resource specified by the handle.
All subsequent operations using the resource will result in a NotFound error status.
Arguments:
resource: handle to the resource to delete.
Returns the created operation.
func Diag ¶ added in v1.1.0
Returns a diagonal tensor with a given diagonal values.
Given a `diagonal`, this operation returns a tensor with the `diagonal` and everything else padded with zeros. The diagonal is computed as follows:
Assume `diagonal` has dimensions [D1,..., Dk], then the output is a tensor of rank 2k with dimensions [D1,..., Dk, D1,..., Dk] where:
`output[i1,..., ik, i1,..., ik] = diagonal[i1, ..., ik]` and 0 everywhere else.
For example:
``` # 'diagonal' is [1, 2, 3, 4] tf.diag(diagonal) ==> [[1, 0, 0, 0]
[0, 2, 0, 0] [0, 0, 3, 0] [0, 0, 0, 4]]
```
Arguments:
diagonal: Rank k tensor where k is at most 1.
func DiagPart ¶ added in v1.1.0
Returns the diagonal part of the tensor.
This operation returns a tensor with the `diagonal` part of the `input`. The `diagonal` part is computed as follows:
Assume `input` has dimensions `[D1,..., Dk, D1,..., Dk]`, then the output is a tensor of rank `k` with dimensions `[D1,..., Dk]` where:
`diagonal[i1,..., ik] = input[i1, ..., ik, i1,..., ik]`.
For example:
``` # 'input' is [[1, 0, 0, 0]
[0, 2, 0, 0] [0, 0, 3, 0] [0, 0, 0, 4]]
tf.diag_part(input) ==> [1, 2, 3, 4] ```
Arguments:
input: Rank k tensor where k is even and not zero.
Returns The extracted diagonal.
func Digamma ¶ added in v1.1.0
Computes Psi, the derivative of Lgamma (the log of the absolute value of
`Gamma(x)`), element-wise.
func Dilation2D ¶ added in v1.1.0
func Dilation2D(scope *Scope, input tf.Output, filter tf.Output, strides []int64, rates []int64, padding string) (output tf.Output)
Computes the grayscale dilation of 4-D `input` and 3-D `filter` tensors.
The `input` tensor has shape `[batch, in_height, in_width, depth]` and the `filter` tensor has shape `[filter_height, filter_width, depth]`, i.e., each input channel is processed independently of the others with its own structuring function. The `output` tensor has shape `[batch, out_height, out_width, depth]`. The spatial dimensions of the output tensor depend on the `padding` algorithm. We currently only support the default "NHWC" `data_format`.
In detail, the grayscale morphological 2-D dilation is the max-sum correlation (for consistency with `conv2d`, we use unmirrored filters):
output[b, y, x, c] =
max_{dy, dx} input[b,
strides[1] * y + rates[1] * dy,
strides[2] * x + rates[2] * dx,
c] +
filter[dy, dx, c]
Max-pooling is a special case when the filter has size equal to the pooling kernel size and contains all zeros.
Note on duality: The dilation of `input` by the `filter` is equal to the negation of the erosion of `-input` by the reflected `filter`.
Arguments:
input: 4-D with shape `[batch, in_height, in_width, depth]`. filter: 3-D with shape `[filter_height, filter_width, depth]`. strides: The stride of the sliding window for each dimension of the input
tensor. Must be: `[1, stride_height, stride_width, 1]`.
rates: The input stride for atrous morphological dilation. Must be:
`[1, rate_height, rate_width, 1]`.
padding: The type of padding algorithm to use.
Returns 4-D with shape `[batch, out_height, out_width, depth]`.
func Dilation2DBackpropFilter ¶ added in v1.1.0
func Dilation2DBackpropFilter(scope *Scope, input tf.Output, filter tf.Output, out_backprop tf.Output, strides []int64, rates []int64, padding string) (filter_backprop tf.Output)
Computes the gradient of morphological 2-D dilation with respect to the filter.
Arguments:
input: 4-D with shape `[batch, in_height, in_width, depth]`. filter: 3-D with shape `[filter_height, filter_width, depth]`. out_backprop: 4-D with shape `[batch, out_height, out_width, depth]`. strides: 1-D of length 4. The stride of the sliding window for each dimension of
the input tensor. Must be: `[1, stride_height, stride_width, 1]`.
rates: 1-D of length 4. The input stride for atrous morphological dilation.
Must be: `[1, rate_height, rate_width, 1]`.
padding: The type of padding algorithm to use.
Returns 3-D with shape `[filter_height, filter_width, depth]`.
func Dilation2DBackpropInput ¶ added in v1.1.0
func Dilation2DBackpropInput(scope *Scope, input tf.Output, filter tf.Output, out_backprop tf.Output, strides []int64, rates []int64, padding string) (in_backprop tf.Output)
Computes the gradient of morphological 2-D dilation with respect to the input.
Arguments:
input: 4-D with shape `[batch, in_height, in_width, depth]`. filter: 3-D with shape `[filter_height, filter_width, depth]`. out_backprop: 4-D with shape `[batch, out_height, out_width, depth]`. strides: 1-D of length 4. The stride of the sliding window for each dimension of
the input tensor. Must be: `[1, stride_height, stride_width, 1]`.
rates: 1-D of length 4. The input stride for atrous morphological dilation.
Must be: `[1, rate_height, rate_width, 1]`.
padding: The type of padding algorithm to use.
Returns 4-D with shape `[batch, in_height, in_width, depth]`.
func Div ¶ added in v1.1.0
Returns x / y element-wise.
*NOTE*: `Div` supports broadcasting. More about broadcasting [here](http://docs.scipy.org/doc/numpy/user/basics.broadcasting.html)
func DrawBoundingBoxes ¶ added in v1.1.0
Draw bounding boxes on a batch of images.
Outputs a copy of `images` but draws on top of the pixels zero or more bounding boxes specified by the locations in `boxes`. The coordinates of the each bounding box in `boxes` are encoded as `[y_min, x_min, y_max, x_max]`. The bounding box coordinates are floats in `[0.0, 1.0]` relative to the width and height of the underlying image.
For example, if an image is 100 x 200 pixels (height x width) and the bounding box is `[0.1, 0.2, 0.5, 0.9]`, the upper-left and bottom-right coordinates of the bounding box will be `(40, 10)` to `(100, 50)` (in (x,y) coordinates).
Parts of the bounding box may fall outside the image.
Arguments:
images: 4-D with shape `[batch, height, width, depth]`. A batch of images. boxes: 3-D with shape `[batch, num_bounding_boxes, 4]` containing bounding
boxes.
Returns 4-D with the same shape as `images`. The batch of input images with bounding boxes drawn on the images.
func DynamicPartition ¶ added in v1.1.0
func DynamicPartition(scope *Scope, data tf.Output, partitions tf.Output, num_partitions int64) (outputs []tf.Output)
Partitions `data` into `num_partitions` tensors using indices from `partitions`.
For each index tuple `js` of size `partitions.ndim`, the slice `data[js, ...]` becomes part of `outputs[partitions[js]]`. The slices with `partitions[js] = i` are placed in `outputs[i]` in lexicographic order of `js`, and the first dimension of `outputs[i]` is the number of entries in `partitions` equal to `i`. In detail,
```python
outputs[i].shape = [sum(partitions == i)] + data.shape[partitions.ndim:] outputs[i] = pack([data[js, ...] for js if partitions[js] == i])
```
`data.shape` must start with `partitions.shape`.
For example:
```python
# Scalar partitions. partitions = 1 num_partitions = 2 data = [10, 20] outputs[0] = [] # Empty with shape [0, 2] outputs[1] = [[10, 20]] # Vector partitions. partitions = [0, 0, 1, 1, 0] num_partitions = 2 data = [10, 20, 30, 40, 50] outputs[0] = [10, 20, 50] outputs[1] = [30, 40]
```
See `dynamic_stitch` for an example on how to merge partitions back.
<div style="width:70%; margin:auto; margin-bottom:10px; margin-top:20px;"> <img style="width:100%" src="https://www.tensorflow.org/images/DynamicPartition.png" alt> </div>
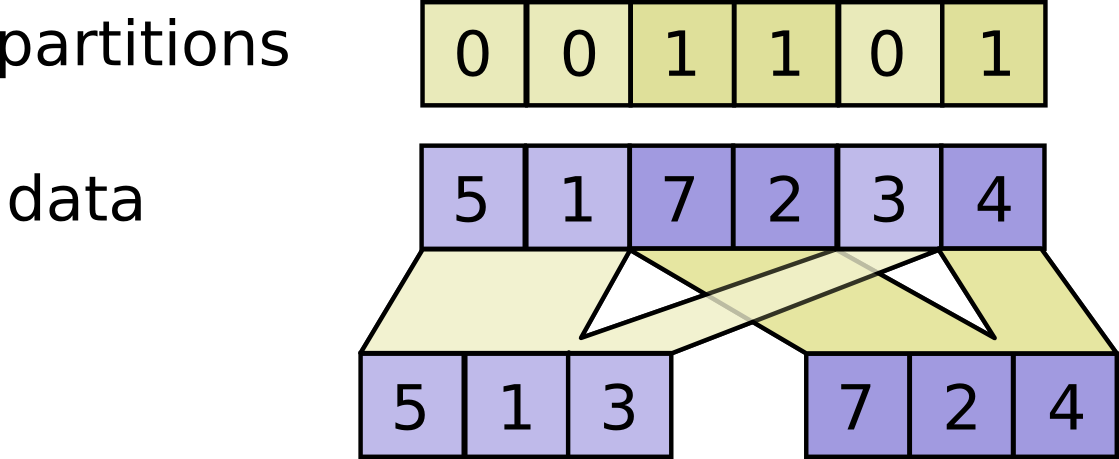{kind=link}
Arguments:
partitions: Any shape. Indices in the range `[0, num_partitions)`. num_partitions: The number of partitions to output.
func DynamicStitch ¶ added in v1.1.0
Interleave the values from the `data` tensors into a single tensor.
Builds a merged tensor such that ¶
```python
merged[indices[m][i, ..., j], ...] = data[m][i, ..., j, ...]
```
For example, if each `indices[m]` is scalar or vector, we have
```python
# Scalar indices: merged[indices[m], ...] = data[m][...] # Vector indices: merged[indices[m][i], ...] = data[m][i, ...]
```
Each `data[i].shape` must start with the corresponding `indices[i].shape`, and the rest of `data[i].shape` must be constant w.r.t. `i`. That is, we must have `data[i].shape = indices[i].shape + constant`. In terms of this `constant`, the output shape is
merged.shape = [max(indices)] + constant
Values are merged in order, so if an index appears in both `indices[m][i]` and `indices[n][j]` for `(m,i) < (n,j)` the slice `data[n][j]` will appear in the merged result. If you do not need this guarantee, ParallelDynamicStitch might perform better on some devices.
For example:
```python
indices[0] = 6
indices[1] = [4, 1]
indices[2] = [[5, 2], [0, 3]]
data[0] = [61, 62]
data[1] = [[41, 42], [11, 12]]
data[2] = [[[51, 52], [21, 22]], [[1, 2], [31, 32]]]
merged = [[1, 2], [11, 12], [21, 22], [31, 32], [41, 42],
[51, 52], [61, 62]]
```
This method can be used to merge partitions created by `dynamic_partition` as illustrated on the following example:
```python
# Apply function (increments x_i) on elements for which a certain condition
# apply (x_i != -1 in this example).
x=tf.constant([0.1, -1., 5.2, 4.3, -1., 7.4])
condition_mask=tf.not_equal(x,tf.constant(-1.))
partitioned_data = tf.dynamic_partition(
x, tf.cast(condition_mask, tf.int32) , 2)
partitioned_data[1] = partitioned_data[1] + 1.0
condition_indices = tf.dynamic_partition(
tf.range(tf.shape(x)[0]), tf.cast(condition_mask, tf.int32) , 2)
x = tf.dynamic_stitch(condition_indices, partitioned_data)
# Here x=[1.1, -1., 6.2, 5.3, -1, 8.4], the -1. values remain
# unchanged.
```
<div style="width:70%; margin:auto; margin-bottom:10px; margin-top:20px;"> <img style="width:100%" src="https://www.tensorflow.org/images/DynamicStitch.png" alt> </div>
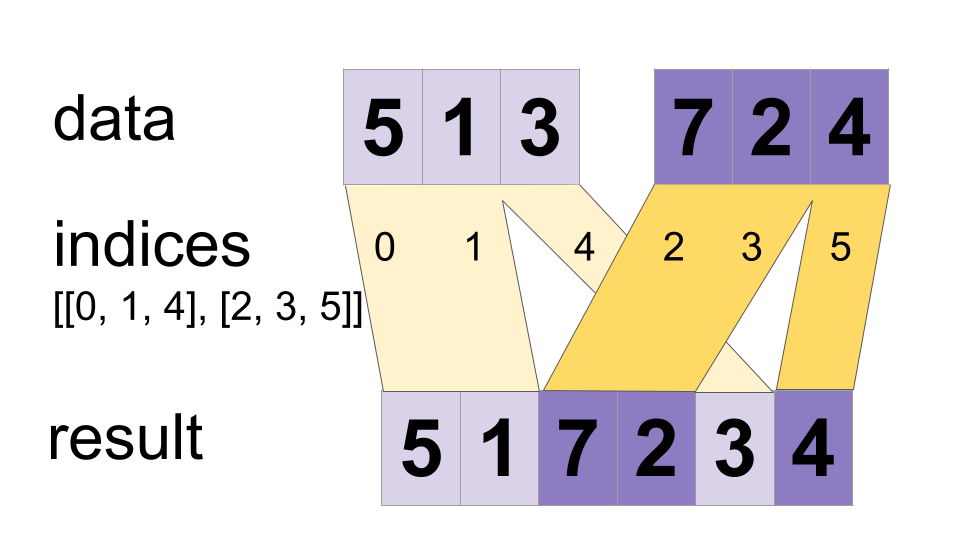{kind=link}
func EagerPyFunc ¶ added in v1.6.0
func EagerPyFunc(scope *Scope, input []tf.Output, token string, Tout []tf.DataType) (output []tf.Output)
Eagerly executes a python function to compute func(input)->output. The
semantics of the input, output, and attributes are the same as those for PyFunc.
func EditDistance ¶ added in v1.1.0
func EditDistance(scope *Scope, hypothesis_indices tf.Output, hypothesis_values tf.Output, hypothesis_shape tf.Output, truth_indices tf.Output, truth_values tf.Output, truth_shape tf.Output, optional ...EditDistanceAttr) (output tf.Output)
Computes the (possibly normalized) Levenshtein Edit Distance.
The inputs are variable-length sequences provided by SparseTensors
(hypothesis_indices, hypothesis_values, hypothesis_shape)
and
(truth_indices, truth_values, truth_shape).
The inputs are:
Arguments:
hypothesis_indices: The indices of the hypothesis list SparseTensor.
This is an N x R int64 matrix.
hypothesis_values: The values of the hypothesis list SparseTensor.
This is an N-length vector.
hypothesis_shape: The shape of the hypothesis list SparseTensor.
This is an R-length vector.
truth_indices: The indices of the truth list SparseTensor.
This is an M x R int64 matrix.
truth_values: The values of the truth list SparseTensor.
This is an M-length vector.
truth_shape: truth indices, vector.
Returns A dense float tensor with rank R - 1.
For the example input:
// hypothesis represents a 2x1 matrix with variable-length values:
// (0,0) = ["a"]
// (1,0) = ["b"]
hypothesis_indices = [[0, 0, 0],
[1, 0, 0]]
hypothesis_values = ["a", "b"]
hypothesis_shape = [2, 1, 1]
// truth represents a 2x2 matrix with variable-length values:
// (0,0) = []
// (0,1) = ["a"]
// (1,0) = ["b", "c"]
// (1,1) = ["a"]
truth_indices = [[0, 1, 0],
[1, 0, 0],
[1, 0, 1],
[1, 1, 0]]
truth_values = ["a", "b", "c", "a"]
truth_shape = [2, 2, 2]
normalize = true
The output will be:
// output is a 2x2 matrix with edit distances normalized by truth lengths.
output = [[inf, 1.0], // (0,0): no truth, (0,1): no hypothesis
[0.5, 1.0]] // (1,0): addition, (1,1): no hypothesis
func Elu ¶ added in v1.1.0
Computes exponential linear: `exp(features) - 1` if < 0, `features` otherwise.
See [Fast and Accurate Deep Network Learning by Exponential Linear Units (ELUs) ](http://arxiv.org/abs/1511.07289)
func EluGrad ¶ added in v1.1.0
Computes gradients for the exponential linear (Elu) operation.
Arguments:
gradients: The backpropagated gradients to the corresponding Elu operation. outputs: The outputs of the corresponding Elu operation.
Returns The gradients: `gradients * (outputs + 1)` if outputs < 0, `gradients` otherwise.
func EncodeBase64 ¶ added in v1.1.0
Encode strings into web-safe base64 format.
Refer to the following article for more information on base64 format: en.wikipedia.org/wiki/Base64. Base64 strings may have padding with '=' at the end so that the encoded has length multiple of 4. See Padding section of the link above.
Web-safe means that the encoder uses - and _ instead of + and /.
Arguments:
input: Strings to be encoded.
Returns Input strings encoded in base64.
func EncodeJpeg ¶ added in v1.1.0
JPEG-encode an image.
`image` is a 3-D uint8 Tensor of shape `[height, width, channels]`.
The attr `format` can be used to override the color format of the encoded output. Values can be:
- `”`: Use a default format based on the number of channels in the image.
- `grayscale`: Output a grayscale JPEG image. The `channels` dimension of `image` must be 1.
- `rgb`: Output an RGB JPEG image. The `channels` dimension of `image` must be 3.
If `format` is not specified or is the empty string, a default format is picked in function of the number of channels in `image`:
* 1: Output a grayscale image. * 3: Output an RGB image.
Arguments:
image: 3-D with shape `[height, width, channels]`.
Returns 0-D. JPEG-encoded image.
func EncodePng ¶ added in v1.1.0
PNG-encode an image.
`image` is a 3-D uint8 or uint16 Tensor of shape `[height, width, channels]` where `channels` is:
* 1: for grayscale. * 2: for grayscale + alpha. * 3: for RGB. * 4: for RGBA.
The ZLIB compression level, `compression`, can be -1 for the PNG-encoder default or a value from 0 to 9. 9 is the highest compression level, generating the smallest output, but is slower.
Arguments:
image: 3-D with shape `[height, width, channels]`.
Returns 0-D. PNG-encoded image.
func EncodeWav ¶ added in v1.2.0
Encode audio data using the WAV file format.
This operation will generate a string suitable to be saved out to create a .wav audio file. It will be encoded in the 16-bit PCM format. It takes in float values in the range -1.0f to 1.0f, and any outside that value will be clamped to that range.
`audio` is a 2-D float Tensor of shape `[length, channels]`. `sample_rate` is a scalar Tensor holding the rate to use (e.g. 44100).
Arguments:
audio: 2-D with shape `[length, channels]`. sample_rate: Scalar containing the sample frequency.
Returns 0-D. WAV-encoded file contents.
func Enter ¶ added in v1.1.0
func Enter(scope *Scope, data tf.Output, frame_name string, optional ...EnterAttr) (output tf.Output)
Creates or finds a child frame, and makes `data` available to the child frame.
This op is used together with `Exit` to create loops in the graph. The unique `frame_name` is used by the `Executor` to identify frames. If `is_constant` is true, `output` is a constant in the child frame; otherwise it may be changed in the child frame. At most `parallel_iterations` iterations are run in parallel in the child frame.
Arguments:
data: The tensor to be made available to the child frame. frame_name: The name of the child frame.
Returns The same tensor as `data`.
func Equal ¶ added in v1.1.0
Returns the truth value of (x == y) element-wise.
*NOTE*: `Equal` supports broadcasting. More about broadcasting [here](http://docs.scipy.org/doc/numpy/user/basics.broadcasting.html)
func Exit ¶ added in v1.1.0
Exits the current frame to its parent frame.
Exit makes its input `data` available to the parent frame.
Arguments:
data: The tensor to be made available to the parent frame.
Returns The same tensor as `data`.
func ExpandDims ¶ added in v1.1.0
Inserts a dimension of 1 into a tensor's shape.
Given a tensor `input`, this operation inserts a dimension of 1 at the dimension index `axis` of `input`'s shape. The dimension index `axis` starts at zero; if you specify a negative number for `axis` it is counted backward from the end.
This operation is useful if you want to add a batch dimension to a single element. For example, if you have a single image of shape `[height, width, channels]`, you can make it a batch of 1 image with `expand_dims(image, 0)`, which will make the shape `[1, height, width, channels]`.
Other examples:
``` # 't' is a tensor of shape [2] shape(expand_dims(t, 0)) ==> [1, 2] shape(expand_dims(t, 1)) ==> [2, 1] shape(expand_dims(t, -1)) ==> [2, 1]
# 't2' is a tensor of shape [2, 3, 5] shape(expand_dims(t2, 0)) ==> [1, 2, 3, 5] shape(expand_dims(t2, 2)) ==> [2, 3, 1, 5] shape(expand_dims(t2, 3)) ==> [2, 3, 5, 1] ```
This operation requires that:
`-1-input.dims() <= dim <= input.dims()`
This operation is related to `squeeze()`, which removes dimensions of size 1.
Arguments:
axis: 0-D (scalar). Specifies the dimension index at which to
expand the shape of `input`. Must be in the range `[-rank(input) - 1, rank(input)]`.
Returns Contains the same data as `input`, but its shape has an additional dimension of size 1 added.
func Expm1 ¶ added in v1.1.0
Computes exponential of x - 1 element-wise.
I.e., \\(y = (\exp x) - 1\\).
func ExtractGlimpse ¶ added in v1.1.0
func ExtractGlimpse(scope *Scope, input tf.Output, size tf.Output, offsets tf.Output, optional ...ExtractGlimpseAttr) (glimpse tf.Output)
Extracts a glimpse from the input tensor.
Returns a set of windows called glimpses extracted at location `offsets` from the input tensor. If the windows only partially overlaps the inputs, the non overlapping areas will be filled with random noise.
The result is a 4-D tensor of shape `[batch_size, glimpse_height, glimpse_width, channels]`. The channels and batch dimensions are the same as that of the input tensor. The height and width of the output windows are specified in the `size` parameter.
The argument `normalized` and `centered` controls how the windows are built:
- If the coordinates are normalized but not centered, 0.0 and 1.0 correspond to the minimum and maximum of each height and width dimension.
- If the coordinates are both normalized and centered, they range from -1.0 to 1.0. The coordinates (-1.0, -1.0) correspond to the upper left corner, the lower right corner is located at (1.0, 1.0) and the center is at (0, 0).
- If the coordinates are not normalized they are interpreted as numbers of pixels.
Arguments:
input: A 4-D float tensor of shape `[batch_size, height, width, channels]`. size: A 1-D tensor of 2 elements containing the size of the glimpses
to extract. The glimpse height must be specified first, following by the glimpse width.
offsets: A 2-D integer tensor of shape `[batch_size, 2]` containing
the y, x locations of the center of each window.
Returns A tensor representing the glimpses `[batch_size, glimpse_height, glimpse_width, channels]`.
func ExtractImagePatches ¶ added in v1.1.0
func ExtractImagePatches(scope *Scope, images tf.Output, ksizes []int64, strides []int64, rates []int64, padding string) (patches tf.Output)
Extract `patches` from `images` and put them in the "depth" output dimension.
Arguments:
images: 4-D Tensor with shape `[batch, in_rows, in_cols, depth]`. ksizes: The size of the sliding window for each dimension of `images`. strides: 1-D of length 4. How far the centers of two consecutive patches are in
the images. Must be: `[1, stride_rows, stride_cols, 1]`.
rates: 1-D of length 4. Must be: `[1, rate_rows, rate_cols, 1]`. This is the
input stride, specifying how far two consecutive patch samples are in the input. Equivalent to extracting patches with `patch_sizes_eff = patch_sizes + (patch_sizes - 1) * (rates - 1)`, followed by subsampling them spatially by a factor of `rates`. This is equivalent to `rate` in dilated (a.k.a. Atrous) convolutions.
padding: The type of padding algorithm to use.
We specify the size-related attributes as:
```python
ksizes = [1, ksize_rows, ksize_cols, 1] strides = [1, strides_rows, strides_cols, 1] rates = [1, rates_rows, rates_cols, 1]
```
Returns 4-D Tensor with shape `[batch, out_rows, out_cols, ksize_rows * ksize_cols * depth]` containing image patches with size `ksize_rows x ksize_cols x depth` vectorized in the "depth" dimension. Note `out_rows` and `out_cols` are the dimensions of the output patches.
func ExtractJpegShape ¶ added in v1.4.0
func ExtractJpegShape(scope *Scope, contents tf.Output, optional ...ExtractJpegShapeAttr) (image_shape tf.Output)
Extract the shape information of a JPEG-encoded image.
This op only parses the image header, so it is much faster than DecodeJpeg.
Arguments:
contents: 0-D. The JPEG-encoded image.
Returns 1-D. The image shape with format [height, width, channels].
func FFT ¶ added in v1.1.0
Fast Fourier transform.
Computes the 1-dimensional discrete Fourier transform over the inner-most dimension of `input`.
Arguments:
input: A complex64 tensor.
Returns A complex64 tensor of the same shape as `input`. The inner-most
dimension of `input` is replaced with its 1D Fourier transform.
@compatibility(numpy) Equivalent to np.fft.fft @end_compatibility
func FFT2D ¶ added in v1.1.0
2D fast Fourier transform.
Computes the 2-dimensional discrete Fourier transform over the inner-most 2 dimensions of `input`.
Arguments:
input: A complex64 tensor.
Returns A complex64 tensor of the same shape as `input`. The inner-most 2
dimensions of `input` are replaced with their 2D Fourier transform.
@compatibility(numpy) Equivalent to np.fft.fft2 @end_compatibility
func FFT3D ¶ added in v1.1.0
3D fast Fourier transform.
Computes the 3-dimensional discrete Fourier transform over the inner-most 3 dimensions of `input`.
Arguments:
input: A complex64 tensor.
Returns A complex64 tensor of the same shape as `input`. The inner-most 3
dimensions of `input` are replaced with their 3D Fourier transform.
@compatibility(numpy) Equivalent to np.fft.fftn with 3 dimensions. @end_compatibility
func FIFOQueueV2 ¶ added in v1.1.0
func FIFOQueueV2(scope *Scope, component_types []tf.DataType, optional ...FIFOQueueV2Attr) (handle tf.Output)
A queue that produces elements in first-in first-out order.
Arguments:
component_types: The type of each component in a value.
Returns The handle to the queue.
func FakeQuantWithMinMaxArgs ¶ added in v1.1.0
func FakeQuantWithMinMaxArgs(scope *Scope, inputs tf.Output, optional ...FakeQuantWithMinMaxArgsAttr) (outputs tf.Output)
Fake-quantize the 'inputs' tensor, type float to 'outputs' tensor of same type.
Attributes `[min; max]` define the clamping range for the `inputs` data. `inputs` values are quantized into the quantization range (`[0; 2^num_bits - 1]` when `narrow_range` is false and `[1; 2^num_bits - 1]` when it is true) and then de-quantized and output as floats in `[min; max]` interval. `num_bits` is the bitwidth of the quantization; between 2 and 8, inclusive.
Quantization is called fake since the output is still in floating point.
func FakeQuantWithMinMaxArgsGradient ¶ added in v1.1.0
func FakeQuantWithMinMaxArgsGradient(scope *Scope, gradients tf.Output, inputs tf.Output, optional ...FakeQuantWithMinMaxArgsGradientAttr) (backprops tf.Output)
Compute gradients for a FakeQuantWithMinMaxArgs operation.
Arguments:
gradients: Backpropagated gradients above the FakeQuantWithMinMaxArgs operation. inputs: Values passed as inputs to the FakeQuantWithMinMaxArgs operation.
Returns Backpropagated gradients below the FakeQuantWithMinMaxArgs operation: `gradients * (inputs >= min && inputs <= max)`.
func FakeQuantWithMinMaxVars ¶ added in v1.1.0
func FakeQuantWithMinMaxVars(scope *Scope, inputs tf.Output, min tf.Output, max tf.Output, optional ...FakeQuantWithMinMaxVarsAttr) (outputs tf.Output)
Fake-quantize the 'inputs' tensor of type float via global float scalars `min`
and `max` to 'outputs' tensor of same shape as `inputs`.
`[min; max]` define the clamping range for the `inputs` data. `inputs` values are quantized into the quantization range (`[0; 2^num_bits - 1]` when `narrow_range` is false and `[1; 2^num_bits - 1]` when it is true) and then de-quantized and output as floats in `[min; max]` interval. `num_bits` is the bitwidth of the quantization; between 2 and 8, inclusive.
This operation has a gradient and thus allows for training `min` and `max` values.
func FakeQuantWithMinMaxVarsGradient ¶ added in v1.1.0
func FakeQuantWithMinMaxVarsGradient(scope *Scope, gradients tf.Output, inputs tf.Output, min tf.Output, max tf.Output, optional ...FakeQuantWithMinMaxVarsGradientAttr) (backprops_wrt_input tf.Output, backprop_wrt_min tf.Output, backprop_wrt_max tf.Output)
Compute gradients for a FakeQuantWithMinMaxVars operation.
Arguments:
gradients: Backpropagated gradients above the FakeQuantWithMinMaxVars operation. inputs: Values passed as inputs to the FakeQuantWithMinMaxVars operation.
min, max: Quantization interval, scalar floats.
Returns Backpropagated gradients w.r.t. inputs: `gradients * (inputs >= min && inputs <= max)`.Backpropagated gradients w.r.t. min parameter: `sum(gradients * (inputs < min))`.Backpropagated gradients w.r.t. max parameter: `sum(gradients * (inputs > max))`.
func FakeQuantWithMinMaxVarsPerChannel ¶ added in v1.1.0
func FakeQuantWithMinMaxVarsPerChannel(scope *Scope, inputs tf.Output, min tf.Output, max tf.Output, optional ...FakeQuantWithMinMaxVarsPerChannelAttr) (outputs tf.Output)
Fake-quantize the 'inputs' tensor of type float and one of the shapes: `[d]`,
`[b, d]` `[b, h, w, d]` via per-channel floats `min` and `max` of shape `[d]` to 'outputs' tensor of same shape as `inputs`.
`[min; max]` define the clamping range for the `inputs` data. `inputs` values are quantized into the quantization range (`[0; 2^num_bits - 1]` when `narrow_range` is false and `[1; 2^num_bits - 1]` when it is true) and then de-quantized and output as floats in `[min; max]` interval. `num_bits` is the bitwidth of the quantization; between 2 and 8, inclusive.
This operation has a gradient and thus allows for training `min` and `max` values.
func FakeQuantWithMinMaxVarsPerChannelGradient ¶ added in v1.1.0
func FakeQuantWithMinMaxVarsPerChannelGradient(scope *Scope, gradients tf.Output, inputs tf.Output, min tf.Output, max tf.Output, optional ...FakeQuantWithMinMaxVarsPerChannelGradientAttr) (backprops_wrt_input tf.Output, backprop_wrt_min tf.Output, backprop_wrt_max tf.Output)
Compute gradients for a FakeQuantWithMinMaxVarsPerChannel operation.
Arguments:
gradients: Backpropagated gradients above the FakeQuantWithMinMaxVars operation,
shape one of: `[d]`, `[b, d]`, `[b, h, w, d]`.
inputs: Values passed as inputs to the FakeQuantWithMinMaxVars operation, shape same as `gradients`.
min, max: Quantization interval, floats of shape `[d]`.
Returns Backpropagated gradients w.r.t. inputs, shape same as `inputs`:
`gradients * (inputs >= min && inputs <= max)`.Backpropagated gradients w.r.t. min parameter, shape `[d]`:
`sum_per_d(gradients * (inputs < min))`.Backpropagated gradients w.r.t. max parameter, shape `[d]`: `sum_per_d(gradients * (inputs > max))`.
func Fill ¶ added in v1.1.0
Creates a tensor filled with a scalar value.
This operation creates a tensor of shape `dims` and fills it with `value`.
For example:
``` # Output tensor has shape [2, 3]. fill([2, 3], 9) ==> [[9, 9, 9]
[9, 9, 9]]
```
Arguments:
dims: 1-D. Represents the shape of the output tensor. value: 0-D (scalar). Value to fill the returned tensor.
@compatibility(numpy) Equivalent to np.full @end_compatibility
func FixedLengthRecordDataset ¶ added in v1.2.0
func FixedLengthRecordDataset(scope *Scope, filenames tf.Output, header_bytes tf.Output, record_bytes tf.Output, footer_bytes tf.Output, buffer_size tf.Output) (handle tf.Output)
Creates a dataset that emits the records from one or more binary files.
Arguments:
filenames: A scalar or a vector containing the name(s) of the file(s) to be
read.
header_bytes: A scalar representing the number of bytes to skip at the
beginning of a file.
record_bytes: A scalar representing the number of bytes in each record. footer_bytes: A scalar representing the number of bytes to skip at the end
of a file.
buffer_size: A scalar representing the number of bytes to buffer. Must be > 0.
func FixedLengthRecordReaderV2 ¶ added in v1.1.0
func FixedLengthRecordReaderV2(scope *Scope, record_bytes int64, optional ...FixedLengthRecordReaderV2Attr) (reader_handle tf.Output)
A Reader that outputs fixed-length records from a file.
Arguments:
record_bytes: Number of bytes in the record.
Returns The handle to reference the Reader.
func FixedUnigramCandidateSampler ¶ added in v1.1.0
func FixedUnigramCandidateSampler(scope *Scope, true_classes tf.Output, num_true int64, num_sampled int64, unique bool, range_max int64, optional ...FixedUnigramCandidateSamplerAttr) (sampled_candidates tf.Output, true_expected_count tf.Output, sampled_expected_count tf.Output)
Generates labels for candidate sampling with a learned unigram distribution.
A unigram sampler could use a fixed unigram distribution read from a file or passed in as an in-memory array instead of building up the distribution from data on the fly. There is also an option to skew the distribution by applying a distortion power to the weights.
The vocabulary file should be in CSV-like format, with the last field being the weight associated with the word.
For each batch, this op picks a single set of sampled candidate labels.
The advantages of sampling candidates per-batch are simplicity and the possibility of efficient dense matrix multiplication. The disadvantage is that the sampled candidates must be chosen independently of the context and of the true labels.
Arguments:
true_classes: A batch_size * num_true matrix, in which each row contains the
IDs of the num_true target_classes in the corresponding original label.
num_true: Number of true labels per context. num_sampled: Number of candidates to randomly sample. unique: If unique is true, we sample with rejection, so that all sampled
candidates in a batch are unique. This requires some approximation to estimate the post-rejection sampling probabilities.
range_max: The sampler will sample integers from the interval [0, range_max).
Returns A vector of length num_sampled, in which each element is the ID of a sampled candidate.A batch_size * num_true matrix, representing the number of times each candidate is expected to occur in a batch of sampled candidates. If unique=true, then this is a probability.A vector of length num_sampled, for each sampled candidate representing the number of times the candidate is expected to occur in a batch of sampled candidates. If unique=true, then this is a probability.
func FloorDiv ¶ added in v1.1.0
Returns x // y element-wise.
*NOTE*: `FloorDiv` supports broadcasting. More about broadcasting [here](http://docs.scipy.org/doc/numpy/user/basics.broadcasting.html)
func FloorMod ¶ added in v1.1.0
Returns element-wise remainder of division. When `x < 0` xor `y < 0` is
true, this follows Python semantics in that the result here is consistent with a flooring divide. E.g. `floor(x / y) * y + mod(x, y) = x`.
*NOTE*: `FloorMod` supports broadcasting. More about broadcasting [here](http://docs.scipy.org/doc/numpy/user/basics.broadcasting.html)
func FlushSummaryWriter ¶ added in v1.4.0
Flushes the writer's unwritten events.
Arguments:
writer: A handle to the summary writer resource.
Returns the created operation.
func FractionalAvgPool ¶ added in v1.1.0
func FractionalAvgPool(scope *Scope, value tf.Output, pooling_ratio []float32, optional ...FractionalAvgPoolAttr) (output tf.Output, row_pooling_sequence tf.Output, col_pooling_sequence tf.Output)
Performs fractional average pooling on the input.
Fractional average pooling is similar to Fractional max pooling in the pooling region generation step. The only difference is that after pooling regions are generated, a mean operation is performed instead of a max operation in each pooling region.
Arguments:
value: 4-D with shape `[batch, height, width, channels]`. pooling_ratio: Pooling ratio for each dimension of `value`, currently only
supports row and col dimension and should be >= 1.0. For example, a valid pooling ratio looks like [1.0, 1.44, 1.73, 1.0]. The first and last elements must be 1.0 because we don't allow pooling on batch and channels dimensions. 1.44 and 1.73 are pooling ratio on height and width dimensions respectively.
Returns output tensor after fractional avg pooling.row pooling sequence, needed to calculate gradient.column pooling sequence, needed to calculate gradient.
func FractionalAvgPoolGrad ¶ added in v1.1.0
func FractionalAvgPoolGrad(scope *Scope, orig_input_tensor_shape tf.Output, out_backprop tf.Output, row_pooling_sequence tf.Output, col_pooling_sequence tf.Output, optional ...FractionalAvgPoolGradAttr) (output tf.Output)
Computes gradient of the FractionalAvgPool function.
Unlike FractionalMaxPoolGrad, we don't need to find arg_max for FractionalAvgPoolGrad, we just need to evenly back-propagate each element of out_backprop to those indices that form the same pooling cell. Therefore, we just need to know the shape of original input tensor, instead of the whole tensor.
Arguments:
orig_input_tensor_shape: Original input tensor shape for `fractional_avg_pool` out_backprop: 4-D with shape `[batch, height, width, channels]`. Gradients
w.r.t. the output of `fractional_avg_pool`.
row_pooling_sequence: row pooling sequence, form pooling region with
col_pooling_sequence.
col_pooling_sequence: column pooling sequence, form pooling region with
row_pooling sequence.
Returns 4-D. Gradients w.r.t. the input of `fractional_avg_pool`.
func FractionalMaxPool ¶ added in v1.1.0
func FractionalMaxPool(scope *Scope, value tf.Output, pooling_ratio []float32, optional ...FractionalMaxPoolAttr) (output tf.Output, row_pooling_sequence tf.Output, col_pooling_sequence tf.Output)
Performs fractional max pooling on the input.
Fractional max pooling is slightly different than regular max pooling. In regular max pooling, you downsize an input set by taking the maximum value of smaller N x N subsections of the set (often 2x2), and try to reduce the set by a factor of N, where N is an integer. Fractional max pooling, as you might expect from the word "fractional", means that the overall reduction ratio N does not have to be an integer.
The sizes of the pooling regions are generated randomly but are fairly uniform. For example, let's look at the height dimension, and the constraints on the list of rows that will be pool boundaries.
First we define the following:
1. input_row_length : the number of rows from the input set 2. output_row_length : which will be smaller than the input 3. alpha = input_row_length / output_row_length : our reduction ratio 4. K = floor(alpha) 5. row_pooling_sequence : this is the result list of pool boundary rows
Then, row_pooling_sequence should satisfy:
1. a[0] = 0 : the first value of the sequence is 0 2. a[end] = input_row_length : the last value of the sequence is the size 3. K <= (a[i+1] - a[i]) <= K+1 : all intervals are K or K+1 size 4. length(row_pooling_sequence) = output_row_length+1
For more details on fractional max pooling, see this paper: [Benjamin Graham, Fractional Max-Pooling](http://arxiv.org/abs/1412.6071)
Arguments:
value: 4-D with shape `[batch, height, width, channels]`. pooling_ratio: Pooling ratio for each dimension of `value`, currently only
supports row and col dimension and should be >= 1.0. For example, a valid pooling ratio looks like [1.0, 1.44, 1.73, 1.0]. The first and last elements must be 1.0 because we don't allow pooling on batch and channels dimensions. 1.44 and 1.73 are pooling ratio on height and width dimensions respectively.
Returns output tensor after fractional max pooling.row pooling sequence, needed to calculate gradient.column pooling sequence, needed to calculate gradient.
func FractionalMaxPoolGrad ¶ added in v1.1.0
func FractionalMaxPoolGrad(scope *Scope, orig_input tf.Output, orig_output tf.Output, out_backprop tf.Output, row_pooling_sequence tf.Output, col_pooling_sequence tf.Output, optional ...FractionalMaxPoolGradAttr) (output tf.Output)
Computes gradient of the FractionalMaxPool function.
Arguments:
orig_input: Original input for `fractional_max_pool` orig_output: Original output for `fractional_max_pool` out_backprop: 4-D with shape `[batch, height, width, channels]`. Gradients
w.r.t. the output of `fractional_max_pool`.
row_pooling_sequence: row pooling sequence, form pooling region with
col_pooling_sequence.
col_pooling_sequence: column pooling sequence, form pooling region with
row_pooling sequence.
Returns 4-D. Gradients w.r.t. the input of `fractional_max_pool`.
func FusedBatchNorm ¶ added in v1.1.0
func FusedBatchNorm(scope *Scope, x tf.Output, scale tf.Output, offset tf.Output, mean tf.Output, variance tf.Output, optional ...FusedBatchNormAttr) (y tf.Output, batch_mean tf.Output, batch_variance tf.Output, reserve_space_1 tf.Output, reserve_space_2 tf.Output)
Batch normalization.
Note that the size of 4D Tensors are defined by either "NHWC" or "NCHW". The size of 1D Tensors matches the dimension C of the 4D Tensors.
Arguments:
x: A 4D Tensor for input data. scale: A 1D Tensor for scaling factor, to scale the normalized x. offset: A 1D Tensor for offset, to shift to the normalized x. mean: A 1D Tensor for population mean. Used for inference only;
must be empty for training.
variance: A 1D Tensor for population variance. Used for inference only;
must be empty for training.
Returns A 4D Tensor for output data.A 1D Tensor for the computed batch mean, to be used by TensorFlow to compute the running mean.A 1D Tensor for the computed batch variance, to be used by TensorFlow to compute the running variance.A 1D Tensor for the computed batch mean, to be reused in the gradient computation.A 1D Tensor for the computed batch variance (inverted variance in the cuDNN case), to be reused in the gradient computation.
func FusedBatchNormGrad ¶ added in v1.1.0
func FusedBatchNormGrad(scope *Scope, y_backprop tf.Output, x tf.Output, scale tf.Output, reserve_space_1 tf.Output, reserve_space_2 tf.Output, optional ...FusedBatchNormGradAttr) (x_backprop tf.Output, scale_backprop tf.Output, offset_backprop tf.Output, reserve_space_3 tf.Output, reserve_space_4 tf.Output)
Gradient for batch normalization.
Note that the size of 4D Tensors are defined by either "NHWC" or "NCHW". The size of 1D Tensors matches the dimension C of the 4D Tensors.
Arguments:
y_backprop: A 4D Tensor for the gradient with respect to y. x: A 4D Tensor for input data. scale: A 1D Tensor for scaling factor, to scale the normalized x. reserve_space_1: When is_training is True, a 1D Tensor for the computed batch
mean to be reused in gradient computation. When is_training is False, a 1D Tensor for the population mean to be reused in both 1st and 2nd order gradient computation.
reserve_space_2: When is_training is True, a 1D Tensor for the computed batch
variance (inverted variance in the cuDNN case) to be reused in gradient computation. When is_training is False, a 1D Tensor for the population variance to be reused in both 1st and 2nd order gradient computation.
Returns A 4D Tensor for the gradient with respect to x.A 1D Tensor for the gradient with respect to scale.A 1D Tensor for the gradient with respect to offset.Unused placeholder to match the mean input in FusedBatchNorm.Unused placeholder to match the variance input in FusedBatchNorm.
func FusedBatchNormGradV2 ¶ added in v1.4.0
func FusedBatchNormGradV2(scope *Scope, y_backprop tf.Output, x tf.Output, scale tf.Output, reserve_space_1 tf.Output, reserve_space_2 tf.Output, optional ...FusedBatchNormGradV2Attr) (x_backprop tf.Output, scale_backprop tf.Output, offset_backprop tf.Output, reserve_space_3 tf.Output, reserve_space_4 tf.Output)
Gradient for batch normalization.
Note that the size of 4D Tensors are defined by either "NHWC" or "NCHW". The size of 1D Tensors matches the dimension C of the 4D Tensors.
Arguments:
y_backprop: A 4D Tensor for the gradient with respect to y. x: A 4D Tensor for input data. scale: A 1D Tensor for scaling factor, to scale the normalized x. reserve_space_1: When is_training is True, a 1D Tensor for the computed batch
mean to be reused in gradient computation. When is_training is False, a 1D Tensor for the population mean to be reused in both 1st and 2nd order gradient computation.
reserve_space_2: When is_training is True, a 1D Tensor for the computed batch
variance (inverted variance in the cuDNN case) to be reused in gradient computation. When is_training is False, a 1D Tensor for the population variance to be reused in both 1st and 2nd order gradient computation.
Returns A 4D Tensor for the gradient with respect to x.A 1D Tensor for the gradient with respect to scale.A 1D Tensor for the gradient with respect to offset.Unused placeholder to match the mean input in FusedBatchNorm.Unused placeholder to match the variance input in FusedBatchNorm.
func FusedBatchNormV2 ¶ added in v1.4.0
func FusedBatchNormV2(scope *Scope, x tf.Output, scale tf.Output, offset tf.Output, mean tf.Output, variance tf.Output, optional ...FusedBatchNormV2Attr) (y tf.Output, batch_mean tf.Output, batch_variance tf.Output, reserve_space_1 tf.Output, reserve_space_2 tf.Output)
Batch normalization.
Note that the size of 4D Tensors are defined by either "NHWC" or "NCHW". The size of 1D Tensors matches the dimension C of the 4D Tensors.
Arguments:
x: A 4D Tensor for input data. scale: A 1D Tensor for scaling factor, to scale the normalized x. offset: A 1D Tensor for offset, to shift to the normalized x. mean: A 1D Tensor for population mean. Used for inference only;
must be empty for training.
variance: A 1D Tensor for population variance. Used for inference only;
must be empty for training.
Returns A 4D Tensor for output data.A 1D Tensor for the computed batch mean, to be used by TensorFlow to compute the running mean.A 1D Tensor for the computed batch variance, to be used by TensorFlow to compute the running variance.A 1D Tensor for the computed batch mean, to be reused in the gradient computation.A 1D Tensor for the computed batch variance (inverted variance in the cuDNN case), to be reused in the gradient computation.
func FusedPadConv2D ¶ added in v1.1.0
func FusedPadConv2D(scope *Scope, input tf.Output, paddings tf.Output, filter tf.Output, mode string, strides []int64, padding string) (output tf.Output)
Performs a padding as a preprocess during a convolution.
Similar to FusedResizeAndPadConv2d, this op allows for an optimized implementation where the spatial padding transformation stage is fused with the im2col lookup, but in this case without the bilinear filtering required for resizing. Fusing the padding prevents the need to write out the intermediate results as whole tensors, reducing memory pressure, and we can get some latency gains by merging the transformation calculations. The data_format attribute for Conv2D isn't supported by this op, and 'NHWC' order is used instead. Internally this op uses a single per-graph scratch buffer, which means that it will block if multiple versions are being run in parallel. This is because this operator is primarily an optimization to minimize memory usage.
Arguments:
input: 4-D with shape `[batch, in_height, in_width, in_channels]`. paddings: A two-column matrix specifying the padding sizes. The number of
rows must be the same as the rank of `input`.
filter: 4-D with shape
`[filter_height, filter_width, in_channels, out_channels]`.
strides: 1-D of length 4. The stride of the sliding window for each dimension
of `input`. Must be in the same order as the dimension specified with format.
padding: The type of padding algorithm to use.
func FusedResizeAndPadConv2D ¶ added in v1.1.0
func FusedResizeAndPadConv2D(scope *Scope, input tf.Output, size tf.Output, paddings tf.Output, filter tf.Output, mode string, strides []int64, padding string, optional ...FusedResizeAndPadConv2DAttr) (output tf.Output)
Performs a resize and padding as a preprocess during a convolution.
It's often possible to do spatial transformations more efficiently as part of the packing stage of a convolution, so this op allows for an optimized implementation where these stages are fused together. This prevents the need to write out the intermediate results as whole tensors, reducing memory pressure, and we can get some latency gains by merging the transformation calculations. The data_format attribute for Conv2D isn't supported by this op, and defaults to 'NHWC' order. Internally this op uses a single per-graph scratch buffer, which means that it will block if multiple versions are being run in parallel. This is because this operator is primarily an optimization to minimize memory usage.
Arguments:
input: 4-D with shape `[batch, in_height, in_width, in_channels]`. size: A 1-D int32 Tensor of 2 elements: `new_height, new_width`. The
new size for the images.
paddings: A two-column matrix specifying the padding sizes. The number of
rows must be the same as the rank of `input`.
filter: 4-D with shape
`[filter_height, filter_width, in_channels, out_channels]`.
strides: 1-D of length 4. The stride of the sliding window for each dimension
of `input`. Must be in the same order as the dimension specified with format.
padding: The type of padding algorithm to use.
func Gather ¶ added in v1.1.0
func Gather(scope *Scope, params tf.Output, indices tf.Output, optional ...GatherAttr) (output tf.Output)
Gather slices from `params` according to `indices`.
`indices` must be an integer tensor of any dimension (usually 0-D or 1-D). Produces an output tensor with shape `indices.shape + params.shape[1:]` where:
```python
# Scalar indices output[:, ..., :] = params[indices, :, ... :] # Vector indices output[i, :, ..., :] = params[indices[i], :, ... :] # Higher rank indices output[i, ..., j, :, ... :] = params[indices[i, ..., j], :, ..., :]
```
If `indices` is a permutation and `len(indices) == params.shape[0]` then this operation will permute `params` accordingly.
`validate_indices`: DEPRECATED. If this operation is assigned to CPU, values in `indices` are always validated to be within range. If assigned to GPU, out-of-bound indices result in safe but unspecified behavior, which may include raising an error.
<div style="width:70%; margin:auto; margin-bottom:10px; margin-top:20px;"> <img style="width:100%" src="https://www.tensorflow.org/images/Gather.png" alt> </div>
{kind=link}
func GatherNd ¶ added in v1.1.0
Gather slices from `params` into a Tensor with shape specified by `indices`.
`indices` is an K-dimensional integer tensor, best thought of as a (K-1)-dimensional tensor of indices into `params`, where each element defines a slice of `params`:
output[i_0, ..., i_{K-2}] = params[indices[i0, ..., i_{K-2}]]
Whereas in @{tf.gather} `indices` defines slices into the first dimension of `params`, in `tf.gather_nd`, `indices` defines slices into the first `N` dimensions of `params`, where `N = indices.shape[-1]`.
The last dimension of `indices` can be at most the rank of `params`:
indices.shape[-1] <= params.rank
The last dimension of `indices` corresponds to elements (if `indices.shape[-1] == params.rank`) or slices (if `indices.shape[-1] < params.rank`) along dimension `indices.shape[-1]` of `params`. The output tensor has shape
indices.shape[:-1] + params.shape[indices.shape[-1]:]
Some examples below.
Simple indexing into a matrix:
```python
indices = [[0, 0], [1, 1]] params = [['a', 'b'], ['c', 'd']] output = ['a', 'd']
```
Slice indexing into a matrix:
```python
indices = [[1], [0]] params = [['a', 'b'], ['c', 'd']] output = [['c', 'd'], ['a', 'b']]
```
Indexing into a 3-tensor:
```python
indices = [[1]]
params = [[['a0', 'b0'], ['c0', 'd0']],
[['a1', 'b1'], ['c1', 'd1']]]
output = [[['a1', 'b1'], ['c1', 'd1']]]
indices = [[0, 1], [1, 0]]
params = [[['a0', 'b0'], ['c0', 'd0']],
[['a1', 'b1'], ['c1', 'd1']]]
output = [['c0', 'd0'], ['a1', 'b1']]
indices = [[0, 0, 1], [1, 0, 1]]
params = [[['a0', 'b0'], ['c0', 'd0']],
[['a1', 'b1'], ['c1', 'd1']]]
output = ['b0', 'b1']
```
Batched indexing into a matrix:
```python
indices = [[[0, 0]], [[0, 1]]] params = [['a', 'b'], ['c', 'd']] output = [['a'], ['b']]
```
Batched slice indexing into a matrix:
```python
indices = [[[1]], [[0]]] params = [['a', 'b'], ['c', 'd']] output = [[['c', 'd']], [['a', 'b']]]
```
Batched indexing into a 3-tensor:
```python
indices = [[[1]], [[0]]]
params = [[['a0', 'b0'], ['c0', 'd0']],
[['a1', 'b1'], ['c1', 'd1']]]
output = [[[['a1', 'b1'], ['c1', 'd1']]],
[[['a0', 'b0'], ['c0', 'd0']]]]
indices = [[[0, 1], [1, 0]], [[0, 0], [1, 1]]]
params = [[['a0', 'b0'], ['c0', 'd0']],
[['a1', 'b1'], ['c1', 'd1']]]
output = [[['c0', 'd0'], ['a1', 'b1']],
[['a0', 'b0'], ['c1', 'd1']]]
indices = [[[0, 0, 1], [1, 0, 1]], [[0, 1, 1], [1, 1, 0]]]
params = [[['a0', 'b0'], ['c0', 'd0']],
[['a1', 'b1'], ['c1', 'd1']]]
output = [['b0', 'b1'], ['d0', 'c1']]
```
Arguments:
params: The tensor from which to gather values. indices: Index tensor.
Returns Values from `params` gathered from indices given by `indices`, with shape `indices.shape[:-1] + params.shape[indices.shape[-1]:]`.
func GatherV2 ¶ added in v1.3.0
Gather slices from `params` axis `axis` according to `indices`.
`indices` must be an integer tensor of any dimension (usually 0-D or 1-D). Produces an output tensor with shape `params.shape[:axis] + indices.shape + params.shape[axis + 1:]` where:
```python
# Scalar indices (output is rank(params) - 1). output[a_0, ..., a_n, b_0, ..., b_n] = params[a_0, ..., a_n, indices, b_0, ..., b_n] # Vector indices (output is rank(params)). output[a_0, ..., a_n, i, b_0, ..., b_n] = params[a_0, ..., a_n, indices[i], b_0, ..., b_n] # Higher rank indices (output is rank(params) + rank(indices) - 1). output[a_0, ..., a_n, i, ..., j, b_0, ... b_n] = params[a_0, ..., a_n, indices[i, ..., j], b_0, ..., b_n]
```
<div style="width:70%; margin:auto; margin-bottom:10px; margin-top:20px;"> <img style="width:100%" src="https://www.tensorflow.org/images/Gather.png" alt> </div>
Arguments:
params: The tensor from which to gather values. Must be at least rank
`axis + 1`.
indices: Index tensor. Must be in range `[0, params.shape[axis])`. axis: The axis in `params` to gather `indices` from. Defaults to the first
dimension. Supports negative indexes.
Returns Values from `params` gathered from indices given by `indices`, with shape `params.shape[:axis] + indices.shape + params.shape[axis + 1:]`.
func GenerateVocabRemapping ¶ added in v1.4.0
func GenerateVocabRemapping(scope *Scope, new_vocab_file tf.Output, old_vocab_file tf.Output, new_vocab_offset int64, num_new_vocab int64, optional ...GenerateVocabRemappingAttr) (remapping tf.Output, num_present tf.Output)
Given a path to new and old vocabulary files, returns a remapping Tensor of
length `num_new_vocab`, where `remapping[i]` contains the row number in the old vocabulary that corresponds to row `i` in the new vocabulary (starting at line `new_vocab_offset` and up to `num_new_vocab` entities), or `-1` if entry `i` in the new vocabulary is not in the old vocabulary. The old vocabulary is constrained to the first `old_vocab_size` entries if `old_vocab_size` is not the default value of -1.
`num_vocab_offset` enables use in the partitioned variable case, and should generally be set through examining partitioning info. The format of the files should be a text file, with each line containing a single entity within the vocabulary.
For example, with `new_vocab_file` a text file containing each of the following elements on a single line: `[f0, f1, f2, f3]`, old_vocab_file = [f1, f0, f3], `num_new_vocab = 3, new_vocab_offset = 1`, the returned remapping would be `[0, -1, 2]`.
The op also returns a count of how many entries in the new vocabulary were present in the old vocabulary, which is used to calculate the number of values to initialize in a weight matrix remapping
This functionality can be used to remap both row vocabularies (typically, features) and column vocabularies (typically, classes) from TensorFlow checkpoints. Note that the partitioning logic relies on contiguous vocabularies corresponding to div-partitioned variables. Moreover, the underlying remapping uses an IndexTable (as opposed to an inexact CuckooTable), so client code should use the corresponding index_table_from_file() as the FeatureColumn framework does (as opposed to tf.feature_to_id(), which uses a CuckooTable).
Arguments:
new_vocab_file: Path to the new vocab file. old_vocab_file: Path to the old vocab file. new_vocab_offset: How many entries into the new vocab file to start reading. num_new_vocab: Number of entries in the new vocab file to remap.
Returns A Tensor of length num_new_vocab where the element at index i is equal to the old ID that maps to the new ID i. This element is -1 for any new ID that is not found in the old vocabulary.Number of new vocab entries found in old vocab.
func GetSessionHandle ¶ added in v1.2.0
Store the input tensor in the state of the current session.
Arguments:
value: The tensor to be stored.
Returns The handle for the tensor stored in the session state, represented as a string.
func GetSessionHandleV2 ¶ added in v1.1.0
Store the input tensor in the state of the current session.
Arguments:
value: The tensor to be stored.
Returns The handle for the tensor stored in the session state, represented as a ResourceHandle object.
func GetSessionTensor ¶ added in v1.1.0
Get the value of the tensor specified by its handle.
Arguments:
handle: The handle for a tensor stored in the session state. dtype: The type of the output value.
Returns The tensor for the given handle.
func Greater ¶ added in v1.1.0
Returns the truth value of (x > y) element-wise.
*NOTE*: `Greater` supports broadcasting. More about broadcasting [here](http://docs.scipy.org/doc/numpy/user/basics.broadcasting.html)
func GreaterEqual ¶ added in v1.1.0
Returns the truth value of (x >= y) element-wise.
*NOTE*: `GreaterEqual` supports broadcasting. More about broadcasting [here](http://docs.scipy.org/doc/numpy/user/basics.broadcasting.html)
func GuaranteeConst ¶ added in v1.6.0
Gives a guarantee to the TF runtime that the input tensor is a constant.
The runtime is then free to make optimizations based on this.
Only accepts value typed tensors as inputs and rejects resource variable handles as input.
Returns the input tensor without modification.
func HSVToRGB ¶ added in v1.1.0
Convert one or more images from HSV to RGB.
Outputs a tensor of the same shape as the `images` tensor, containing the RGB value of the pixels. The output is only well defined if the value in `images` are in `[0,1]`.
See `rgb_to_hsv` for a description of the HSV encoding.
Arguments:
images: 1-D or higher rank. HSV data to convert. Last dimension must be size 3.
Returns `images` converted to RGB.
func HashTableV2 ¶ added in v1.2.0
func HashTableV2(scope *Scope, key_dtype tf.DataType, value_dtype tf.DataType, optional ...HashTableV2Attr) (table_handle tf.Output)
Creates a non-initialized hash table.
This op creates a hash table, specifying the type of its keys and values. Before using the table you will have to initialize it. After initialization the table will be immutable.
Arguments:
key_dtype: Type of the table keys. value_dtype: Type of the table values.
Returns Handle to a table.
func HistogramFixedWidth ¶ added in v1.5.0
func HistogramFixedWidth(scope *Scope, values tf.Output, value_range tf.Output, nbins tf.Output, optional ...HistogramFixedWidthAttr) (out tf.Output)
Return histogram of values.
Given the tensor `values`, this operation returns a rank 1 histogram counting the number of entries in `values` that fall into every bin. The bins are equal width and determined by the arguments `value_range` and `nbins`.
```python # Bins will be: (-inf, 1), [1, 2), [2, 3), [3, 4), [4, inf) nbins = 5 value_range = [0.0, 5.0] new_values = [-1.0, 0.0, 1.5, 2.0, 5.0, 15]
with tf.get_default_session() as sess:
hist = tf.histogram_fixed_width(new_values, value_range, nbins=5) variables.global_variables_initializer().run() sess.run(hist) => [2, 1, 1, 0, 2]
```
Arguments:
values: Numeric `Tensor`. value_range: Shape [2] `Tensor` of same `dtype` as `values`.
values <= value_range[0] will be mapped to hist[0], values >= value_range[1] will be mapped to hist[-1].
nbins: Scalar `int32 Tensor`. Number of histogram bins.
Returns A 1-D `Tensor` holding histogram of values.
func HistogramSummary ¶ added in v1.1.0
Outputs a `Summary` protocol buffer with a histogram.
The generated [`Summary`](https://www.tensorflow.org/code/tensorflow/core/framework/summary.proto) has one summary value containing a histogram for `values`.
This op reports an `InvalidArgument` error if any value is not finite.
Arguments:
tag: Scalar. Tag to use for the `Summary.Value`. values: Any shape. Values to use to build the histogram.
Returns Scalar. Serialized `Summary` protocol buffer.
func IFFT ¶ added in v1.1.0
Inverse fast Fourier transform.
Computes the inverse 1-dimensional discrete Fourier transform over the inner-most dimension of `input`.
Arguments:
input: A complex64 tensor.
Returns A complex64 tensor of the same shape as `input`. The inner-most
dimension of `input` is replaced with its inverse 1D Fourier transform.
@compatibility(numpy) Equivalent to np.fft.ifft @end_compatibility
func IFFT2D ¶ added in v1.1.0
Inverse 2D fast Fourier transform.
Computes the inverse 2-dimensional discrete Fourier transform over the inner-most 2 dimensions of `input`.
Arguments:
input: A complex64 tensor.
Returns A complex64 tensor of the same shape as `input`. The inner-most 2
dimensions of `input` are replaced with their inverse 2D Fourier transform.
@compatibility(numpy) Equivalent to np.fft.ifft2 @end_compatibility
func IFFT3D ¶ added in v1.1.0
Inverse 3D fast Fourier transform.
Computes the inverse 3-dimensional discrete Fourier transform over the inner-most 3 dimensions of `input`.
Arguments:
input: A complex64 tensor.
Returns A complex64 tensor of the same shape as `input`. The inner-most 3
dimensions of `input` are replaced with their inverse 3D Fourier transform.
@compatibility(numpy) Equivalent to np.fft.ifftn with 3 dimensions. @end_compatibility
func IRFFT ¶ added in v1.1.0
Inverse real-valued fast Fourier transform.
Computes the inverse 1-dimensional discrete Fourier transform of a real-valued signal over the inner-most dimension of `input`.
The inner-most dimension of `input` is assumed to be the result of `RFFT`: the `fft_length / 2 + 1` unique components of the DFT of a real-valued signal. If `fft_length` is not provided, it is computed from the size of the inner-most dimension of `input` (`fft_length = 2 * (inner - 1)`). If the FFT length used to compute `input` is odd, it should be provided since it cannot be inferred properly.
Along the axis `IRFFT` is computed on, if `fft_length / 2 + 1` is smaller than the corresponding dimension of `input`, the dimension is cropped. If it is larger, the dimension is padded with zeros.
Arguments:
input: A complex64 tensor. fft_length: An int32 tensor of shape [1]. The FFT length.
Returns A float32 tensor of the same rank as `input`. The inner-most
dimension of `input` is replaced with the `fft_length` samples of its inverse 1D Fourier transform.
@compatibility(numpy) Equivalent to np.fft.irfft @end_compatibility
func IRFFT2D ¶ added in v1.1.0
Inverse 2D real-valued fast Fourier transform.
Computes the inverse 2-dimensional discrete Fourier transform of a real-valued signal over the inner-most 2 dimensions of `input`.
The inner-most 2 dimensions of `input` are assumed to be the result of `RFFT2D`: The inner-most dimension contains the `fft_length / 2 + 1` unique components of the DFT of a real-valued signal. If `fft_length` is not provided, it is computed from the size of the inner-most 2 dimensions of `input`. If the FFT length used to compute `input` is odd, it should be provided since it cannot be inferred properly.
Along each axis `IRFFT2D` is computed on, if `fft_length` (or `fft_length / 2 + 1` for the inner-most dimension) is smaller than the corresponding dimension of `input`, the dimension is cropped. If it is larger, the dimension is padded with zeros.
Arguments:
input: A complex64 tensor. fft_length: An int32 tensor of shape [2]. The FFT length for each dimension.
Returns A float32 tensor of the same rank as `input`. The inner-most 2
dimensions of `input` are replaced with the `fft_length` samples of their inverse 2D Fourier transform.
@compatibility(numpy) Equivalent to np.fft.irfft2 @end_compatibility
func IRFFT3D ¶ added in v1.1.0
Inverse 3D real-valued fast Fourier transform.
Computes the inverse 3-dimensional discrete Fourier transform of a real-valued signal over the inner-most 3 dimensions of `input`.
The inner-most 3 dimensions of `input` are assumed to be the result of `RFFT3D`: The inner-most dimension contains the `fft_length / 2 + 1` unique components of the DFT of a real-valued signal. If `fft_length` is not provided, it is computed from the size of the inner-most 3 dimensions of `input`. If the FFT length used to compute `input` is odd, it should be provided since it cannot be inferred properly.
Along each axis `IRFFT3D` is computed on, if `fft_length` (or `fft_length / 2 + 1` for the inner-most dimension) is smaller than the corresponding dimension of `input`, the dimension is cropped. If it is larger, the dimension is padded with zeros.
Arguments:
input: A complex64 tensor. fft_length: An int32 tensor of shape [3]. The FFT length for each dimension.
Returns A float32 tensor of the same rank as `input`. The inner-most 3
dimensions of `input` are replaced with the `fft_length` samples of their inverse 3D real Fourier transform.
@compatibility(numpy) Equivalent to np.irfftn with 3 dimensions. @end_compatibility
func Identity ¶ added in v1.1.0
Return a tensor with the same shape and contents as the input tensor or value.
func IdentityN ¶ added in v1.4.0
Returns a list of tensors with the same shapes and contents as the input
tensors.
This op can be used to override the gradient for complicated functions. For example, suppose y = f(x) and we wish to apply a custom function g for backprop such that dx = g(dy). In Python,
```python with tf.get_default_graph().gradient_override_map(
{'IdentityN': 'OverrideGradientWithG'}):
y, _ = identity_n([f(x), x])
@tf.RegisterGradient('OverrideGradientWithG') def ApplyG(op, dy, _):
return [None, g(dy)] # Do not backprop to f(x).
```
func IdentityReaderV2 ¶ added in v1.1.0
func IdentityReaderV2(scope *Scope, optional ...IdentityReaderV2Attr) (reader_handle tf.Output)
A Reader that outputs the queued work as both the key and value.
To use, enqueue strings in a Queue. ReaderRead will take the front work string and output (work, work).
Returns The handle to reference the Reader.
func Igamma ¶ added in v1.1.0
Compute the lower regularized incomplete Gamma function `Q(a, x)`.
The lower regularized incomplete Gamma function is defined as:
\\(P(a, x) = gamma(a, x) / Gamma(a) = 1 - Q(a, x)\\)
where
\\(gamma(a, x) = int_{0}^{x} t^{a-1} exp(-t) dt\\)
is the lower incomplete Gamma function.
Note, above `Q(a, x)` (`Igammac`) is the upper regularized complete Gamma function.
func Igammac ¶ added in v1.1.0
Compute the upper regularized incomplete Gamma function `Q(a, x)`.
The upper regularized incomplete Gamma function is defined as:
\\(Q(a, x) = Gamma(a, x) / Gamma(a) = 1 - P(a, x)\\)
where
\\(Gamma(a, x) = int_{x}^{\infty} t^{a-1} exp(-t) dt\\)
is the upper incomplete Gama function.
Note, above `P(a, x)` (`Igamma`) is the lower regularized complete Gamma function.
func Imag ¶ added in v1.1.0
Returns the imaginary part of a complex number.
Given a tensor `input` of complex numbers, this operation returns a tensor of type `float` that is the imaginary part of each element in `input`. All elements in `input` must be complex numbers of the form \\(a + bj\\), where *a* is the real part and *b* is the imaginary part returned by this operation.
For example:
``` # tensor 'input' is [-2.25 + 4.75j, 3.25 + 5.75j] tf.imag(input) ==> [4.75, 5.75] ```
func ImageSummary ¶ added in v1.1.0
func ImageSummary(scope *Scope, tag tf.Output, tensor tf.Output, optional ...ImageSummaryAttr) (summary tf.Output)
Outputs a `Summary` protocol buffer with images.
The summary has up to `max_images` summary values containing images. The images are built from `tensor` which must be 4-D with shape `[batch_size, height, width, channels]` and where `channels` can be:
* 1: `tensor` is interpreted as Grayscale. * 3: `tensor` is interpreted as RGB. * 4: `tensor` is interpreted as RGBA.
The images have the same number of channels as the input tensor. For float input, the values are normalized one image at a time to fit in the range `[0, 255]`. `uint8` values are unchanged. The op uses two different normalization algorithms:
- If the input values are all positive, they are rescaled so the largest one is 255.
- If any input value is negative, the values are shifted so input value 0.0 is at 127. They are then rescaled so that either the smallest value is 0, or the largest one is 255.
The `tag` argument is a scalar `Tensor` of type `string`. It is used to build the `tag` of the summary values:
- If `max_images` is 1, the summary value tag is '*tag*/image'.
- If `max_images` is greater than 1, the summary value tags are generated sequentially as '*tag*/image/0', '*tag*/image/1', etc.
The `bad_color` argument is the color to use in the generated images for non-finite input values. It is a `unit8` 1-D tensor of length `channels`. Each element must be in the range `[0, 255]` (It represents the value of a pixel in the output image). Non-finite values in the input tensor are replaced by this tensor in the output image. The default value is the color red.
Arguments:
tag: Scalar. Used to build the `tag` attribute of the summary values. tensor: 4-D of shape `[batch_size, height, width, channels]` where
`channels` is 1, 3, or 4.
Returns Scalar. Serialized `Summary` protocol buffer.
func ImmutableConst ¶ added in v1.1.0
func ImmutableConst(scope *Scope, dtype tf.DataType, shape tf.Shape, memory_region_name string) (tensor tf.Output)
Returns immutable tensor from memory region.
The current implementation memmaps the tensor from a file.
Arguments:
dtype: Type of the returned tensor. shape: Shape of the returned tensor. memory_region_name: Name of readonly memory region used by the tensor, see
NewReadOnlyMemoryRegionFromFile in tensorflow::Env.
func ImportEvent ¶ added in v1.5.0
Outputs a `tf.Event` protocol buffer.
When CreateSummaryDbWriter is being used, this op can be useful for importing data from event logs.
Arguments:
writer: A handle to a summary writer. event: A string containing a binary-encoded tf.Event proto.
Returns the created operation.
func InTopK ¶ added in v1.1.0
Says whether the targets are in the top `K` predictions.
This outputs a `batch_size` bool array, an entry `out[i]` is `true` if the prediction for the target class is among the top `k` predictions among all predictions for example `i`. Note that the behavior of `InTopK` differs from the `TopK` op in its handling of ties; if multiple classes have the same prediction value and straddle the top-`k` boundary, all of those classes are considered to be in the top `k`.
More formally, let
\\(predictions_i\\) be the predictions for all classes for example `i`, \\(targets_i\\) be the target class for example `i`, \\(out_i\\) be the output for example `i`,
$$out_i = predictions_{i, targets_i} \in TopKIncludingTies(predictions_i)$$
Arguments:
predictions: A `batch_size` x `classes` tensor. targets: A `batch_size` vector of class ids. k: Number of top elements to look at for computing precision.
Returns Computed Precision at `k` as a `bool Tensor`.
func InTopKV2 ¶ added in v1.4.0
func InTopKV2(scope *Scope, predictions tf.Output, targets tf.Output, k tf.Output) (precision tf.Output)
Says whether the targets are in the top `K` predictions.
This outputs a `batch_size` bool array, an entry `out[i]` is `true` if the prediction for the target class is among the top `k` predictions among all predictions for example `i`. Note that the behavior of `InTopK` differs from the `TopK` op in its handling of ties; if multiple classes have the same prediction value and straddle the top-`k` boundary, all of those classes are considered to be in the top `k`.
More formally, let
\\(predictions_i\\) be the predictions for all classes for example `i`, \\(targets_i\\) be the target class for example `i`, \\(out_i\\) be the output for example `i`,
$$out_i = predictions_{i, targets_i} \in TopKIncludingTies(predictions_i)$$
Arguments:
predictions: A `batch_size` x `classes` tensor. targets: A `batch_size` vector of class ids. k: Number of top elements to look at for computing precision.
Returns Computed precision at `k` as a `bool Tensor`.
func InitializeTableFromTextFileV2 ¶ added in v1.2.0
func InitializeTableFromTextFileV2(scope *Scope, table_handle tf.Output, filename tf.Output, key_index int64, value_index int64, optional ...InitializeTableFromTextFileV2Attr) (o *tf.Operation)
Initializes a table from a text file.
It inserts one key-value pair into the table for each line of the file. The key and value is extracted from the whole line content, elements from the split line based on `delimiter` or the line number (starting from zero). Where to extract the key and value from a line is specified by `key_index` and `value_index`.
- A value of -1 means use the line number(starting from zero), expects `int64`.
- A value of -2 means use the whole line content, expects `string`.
- A value >= 0 means use the index (starting at zero) of the split line based on `delimiter`.
Arguments:
table_handle: Handle to a table which will be initialized. filename: Filename of a vocabulary text file. key_index: Column index in a line to get the table `key` values from. value_index: Column index that represents information of a line to get the table
`value` values from.
Returns the created operation.
func InitializeTableV2 ¶ added in v1.2.0
func InitializeTableV2(scope *Scope, table_handle tf.Output, keys tf.Output, values tf.Output) (o *tf.Operation)
Table initializer that takes two tensors for keys and values respectively.
Arguments:
table_handle: Handle to a table which will be initialized. keys: Keys of type Tkey. values: Values of type Tval.
Returns the created operation.
func InvGrad ¶ added in v1.1.0
Computes the gradient for the inverse of `x` wrt its input.
Specifically, `grad = -dy * y*y`, where `y = 1/x`, and `dy` is the corresponding input gradient.
func Invert ¶ added in v1.3.0
Flips all bits elementwise.
The result will have exactly those bits set, that are not set in `x`. The computation is performed on the underlying representation of x.
func InvertPermutation ¶ added in v1.1.0
Computes the inverse permutation of a tensor.
This operation computes the inverse of an index permutation. It takes a 1-D integer tensor `x`, which represents the indices of a zero-based array, and swaps each value with its index position. In other words, for an output tensor `y` and an input tensor `x`, this operation computes the following:
`y[x[i]] = i for i in [0, 1, ..., len(x) - 1]`
The values must include 0. There can be no duplicate values or negative values.
For example:
``` # tensor `x` is [3, 4, 0, 2, 1] invert_permutation(x) ==> [2, 4, 3, 0, 1] ```
Arguments:
x: 1-D.
Returns 1-D.
func IsFinite ¶ added in v1.1.0
Returns which elements of x are finite.
@compatibility(numpy) Equivalent to np.isfinite @end_compatibility
func IsInf ¶ added in v1.1.0
Returns which elements of x are Inf.
@compatibility(numpy) Equivalent to np.isinf @end_compatibility
func IsNan ¶ added in v1.1.0
Returns which elements of x are NaN.
@compatibility(numpy) Equivalent to np.isnan @end_compatibility
func Iterator ¶ added in v1.2.0
func Iterator(scope *Scope, shared_name string, container string, output_types []tf.DataType, output_shapes []tf.Shape) (handle tf.Output)
A container for an iterator resource.
Returns A handle to the iterator that can be passed to a "MakeIterator" or "IteratorGetNext" op.
func IteratorFromStringHandle ¶ added in v1.3.0
func IteratorFromStringHandle(scope *Scope, string_handle tf.Output, optional ...IteratorFromStringHandleAttr) (resource_handle tf.Output)
Converts the given string representing a handle to an iterator to a resource.
Arguments:
string_handle: A string representation of the given handle.
Returns A handle to an iterator resource.
func IteratorGetNext ¶ added in v1.2.0
func IteratorGetNext(scope *Scope, iterator tf.Output, output_types []tf.DataType, output_shapes []tf.Shape) (components []tf.Output)
Gets the next output from the given iterator.
func IteratorSetStatsAggregator ¶ added in v1.5.0
func IteratorSetStatsAggregator(scope *Scope, iterator_handle tf.Output, stats_aggregator_handle tf.Output) (o *tf.Operation)
Associates the given iterator with the given statistics aggregator.
Returns the created operation.
func IteratorToStringHandle ¶ added in v1.3.0
Converts the given `resource_handle` representing an iterator to a string.
Arguments:
resource_handle: A handle to an iterator resource.
Returns A string representation of the given handle.
func L2Loss ¶ added in v1.1.0
L2 Loss.
Computes half the L2 norm of a tensor without the `sqrt`:
output = sum(t ** 2) / 2
Arguments:
t: Typically 2-D, but may have any dimensions.
Returns 0-D.
func LRN ¶ added in v1.1.0
Local Response Normalization.
The 4-D `input` tensor is treated as a 3-D array of 1-D vectors (along the last dimension), and each vector is normalized independently. Within a given vector, each component is divided by the weighted, squared sum of inputs within `depth_radius`. In detail,
sqr_sum[a, b, c, d] =
sum(input[a, b, c, d - depth_radius : d + depth_radius + 1] ** 2)
output = input / (bias + alpha * sqr_sum) ** beta
For details, see [Krizhevsky et al., ImageNet classification with deep convolutional neural networks (NIPS 2012)](http://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks).
Arguments:
input: 4-D.
func LRNGrad ¶ added in v1.1.0
func LRNGrad(scope *Scope, input_grads tf.Output, input_image tf.Output, output_image tf.Output, optional ...LRNGradAttr) (output tf.Output)
Gradients for Local Response Normalization.
Arguments:
input_grads: 4-D with shape `[batch, height, width, channels]`. input_image: 4-D with shape `[batch, height, width, channels]`. output_image: 4-D with shape `[batch, height, width, channels]`.
Returns The gradients for LRN.
func LatencyStatsDataset ¶ added in v1.5.0
func LatencyStatsDataset(scope *Scope, input_dataset tf.Output, tag tf.Output, output_types []tf.DataType, output_shapes []tf.Shape) (handle tf.Output)
Records the latency of producing `input_dataset` elements in a StatsAggregator.
func LearnedUnigramCandidateSampler ¶ added in v1.1.0
func LearnedUnigramCandidateSampler(scope *Scope, true_classes tf.Output, num_true int64, num_sampled int64, unique bool, range_max int64, optional ...LearnedUnigramCandidateSamplerAttr) (sampled_candidates tf.Output, true_expected_count tf.Output, sampled_expected_count tf.Output)
Generates labels for candidate sampling with a learned unigram distribution.
See explanations of candidate sampling and the data formats at go/candidate-sampling.
For each batch, this op picks a single set of sampled candidate labels.
The advantages of sampling candidates per-batch are simplicity and the possibility of efficient dense matrix multiplication. The disadvantage is that the sampled candidates must be chosen independently of the context and of the true labels.
Arguments:
true_classes: A batch_size * num_true matrix, in which each row contains the
IDs of the num_true target_classes in the corresponding original label.
num_true: Number of true labels per context. num_sampled: Number of candidates to randomly sample. unique: If unique is true, we sample with rejection, so that all sampled
candidates in a batch are unique. This requires some approximation to estimate the post-rejection sampling probabilities.
range_max: The sampler will sample integers from the interval [0, range_max).
Returns A vector of length num_sampled, in which each element is the ID of a sampled candidate.A batch_size * num_true matrix, representing the number of times each candidate is expected to occur in a batch of sampled candidates. If unique=true, then this is a probability.A vector of length num_sampled, for each sampled candidate representing the number of times the candidate is expected to occur in a batch of sampled candidates. If unique=true, then this is a probability.
func LeftShift ¶ added in v1.5.0
Elementwise computes the bitwise left-shift of `x` and `y`.
If `y` is negative, or greater than or equal to the width of `x` in bits the result is implementation defined.
func Less ¶ added in v1.1.0
Returns the truth value of (x < y) element-wise.
*NOTE*: `Less` supports broadcasting. More about broadcasting [here](http://docs.scipy.org/doc/numpy/user/basics.broadcasting.html)
func LessEqual ¶ added in v1.1.0
Returns the truth value of (x <= y) element-wise.
*NOTE*: `LessEqual` supports broadcasting. More about broadcasting [here](http://docs.scipy.org/doc/numpy/user/basics.broadcasting.html)
func LinSpace ¶ added in v1.1.0
Generates values in an interval.
A sequence of `num` evenly-spaced values are generated beginning at `start`. If `num > 1`, the values in the sequence increase by `stop - start / num - 1`, so that the last one is exactly `stop`.
For example:
``` tf.linspace(10.0, 12.0, 3, name="linspace") => [ 10.0 11.0 12.0] ```
Arguments:
start: First entry in the range. stop: Last entry in the range. num: Number of values to generate.
Returns 1-D. The generated values.
func ListDiff ¶ added in v1.1.0
func ListDiff(scope *Scope, x tf.Output, y tf.Output, optional ...ListDiffAttr) (out tf.Output, idx tf.Output)
Computes the difference between two lists of numbers or strings.
Given a list `x` and a list `y`, this operation returns a list `out` that represents all values that are in `x` but not in `y`. The returned list `out` is sorted in the same order that the numbers appear in `x` (duplicates are preserved). This operation also returns a list `idx` that represents the position of each `out` element in `x`. In other words:
`out[i] = x[idx[i]] for i in [0, 1, ..., len(out) - 1]`
For example, given this input:
``` x = [1, 2, 3, 4, 5, 6] y = [1, 3, 5] ```
This operation would return:
``` out ==> [2, 4, 6] idx ==> [1, 3, 5] ```
Arguments:
x: 1-D. Values to keep. y: 1-D. Values to remove.
Returns 1-D. Values present in `x` but not in `y`.1-D. Positions of `x` values preserved in `out`.
func LoadAndRemapMatrix ¶ added in v1.4.0
func LoadAndRemapMatrix(scope *Scope, ckpt_path tf.Output, old_tensor_name tf.Output, row_remapping tf.Output, col_remapping tf.Output, initializing_values tf.Output, num_rows int64, num_cols int64, optional ...LoadAndRemapMatrixAttr) (output_matrix tf.Output)
Loads a 2-D (matrix) `Tensor` with name `old_tensor_name` from the checkpoint
at `ckpt_path` and potentially reorders its rows and columns using the specified remappings.
Most users should use one of the wrapper initializers (such as `tf.contrib.framework.load_and_remap_matrix_initializer`) instead of this function directly.
The remappings are 1-D tensors with the following properties:
- `row_remapping` must have exactly `num_rows` entries. Row `i` of the output matrix will be initialized from the row corresponding to index `row_remapping[i]` in the old `Tensor` from the checkpoint.
- `col_remapping` must have either 0 entries (indicating that no column reordering is needed) or `num_cols` entries. If specified, column `j` of the output matrix will be initialized from the column corresponding to index `col_remapping[j]` in the old `Tensor` from the checkpoint.
- A value of -1 in either of the remappings signifies a "missing" entry. In that case, values from the `initializing_values` tensor will be used to fill that missing row or column. If `row_remapping` has `r` missing entries and `col_remapping` has `c` missing entries, then the following condition must be true:
`(r * num_cols) + (c * num_rows) - (r * c) == len(initializing_values)`
The remapping tensors can be generated using the GenerateVocabRemapping op.
As an example, with row_remapping = [1, 0, -1], col_remapping = [0, 2, -1], initializing_values = [0.5, -0.5, 0.25, -0.25, 42], and w(i, j) representing the value from row i, column j of the old tensor in the checkpoint, the output matrix will look like the following:
[[w(1, 0), w(1, 2), 0.5],
[w(0, 0), w(0, 2), -0.5], [0.25, -0.25, 42]]
Arguments:
ckpt_path: Path to the TensorFlow checkpoint (version 2, `TensorBundle`) from
which the old matrix `Tensor` will be loaded.
old_tensor_name: Name of the 2-D `Tensor` to load from checkpoint. row_remapping: An int `Tensor` of row remappings (generally created by
`generate_vocab_remapping`). Even if no row remapping is needed, this must still be an index-valued Tensor (e.g. [0, 1, 2, ...]), or a shifted index-valued `Tensor` (e.g. [8, 9, 10, ...], for partitioned `Variables`).
col_remapping: An int `Tensor` of column remappings (generally created by
`generate_vocab_remapping`). May be a size-0 `Tensor` if only row remapping is to be done (e.g. column ordering is the same).
initializing_values: A float `Tensor` containing values to fill in for cells
in the output matrix that are not loaded from the checkpoint. Length must be exactly the same as the number of missing / new cells.
num_rows: Number of rows (length of the 1st dimension) in the output matrix. num_cols: Number of columns (length of the 2nd dimension) in the output matrix.
Returns Output matrix containing existing values loaded from the checkpoint, and with any missing values filled in from initializing_values.
func Log1p ¶ added in v1.1.0
Computes natural logarithm of (1 + x) element-wise.
I.e., \\(y = \log_e (1 + x)\\).
func LogMatrixDeterminant ¶ added in v1.4.0
func LogMatrixDeterminant(scope *Scope, input tf.Output) (sign tf.Output, log_abs_determinant tf.Output)
Computes the sign and the log of the absolute value of the determinant of
one or more square matrices.
The input is a tensor of shape `[N, M, M]` whose inner-most 2 dimensions form square matrices. The outputs are two tensors containing the signs and absolute values of the log determinants for all N input submatrices `[..., :, :]` such that the determinant = sign*exp(log_abs_determinant). The log_abs_determinant is computed as det(P)*sum(log(diag(LU))) where LU is the LU decomposition of the input and P is the corresponding permutation matrix.
Arguments:
input: Shape is `[N, M, M]`.
Returns The signs of the log determinants of the inputs. Shape is `[N]`.The logs of the absolute values of the determinants of the N input matrices. Shape is `[N]`.
func LogSoftmax ¶ added in v1.1.0
Computes log softmax activations.
For each batch `i` and class `j` we have
logsoftmax[i, j] = logits[i, j] - log(sum(exp(logits[i])))
Arguments:
logits: 2-D with shape `[batch_size, num_classes]`.
Returns Same shape as `logits`.
func LogUniformCandidateSampler ¶ added in v1.1.0
func LogUniformCandidateSampler(scope *Scope, true_classes tf.Output, num_true int64, num_sampled int64, unique bool, range_max int64, optional ...LogUniformCandidateSamplerAttr) (sampled_candidates tf.Output, true_expected_count tf.Output, sampled_expected_count tf.Output)
Generates labels for candidate sampling with a log-uniform distribution.
See explanations of candidate sampling and the data formats at go/candidate-sampling.
For each batch, this op picks a single set of sampled candidate labels.
The advantages of sampling candidates per-batch are simplicity and the possibility of efficient dense matrix multiplication. The disadvantage is that the sampled candidates must be chosen independently of the context and of the true labels.
Arguments:
true_classes: A batch_size * num_true matrix, in which each row contains the
IDs of the num_true target_classes in the corresponding original label.
num_true: Number of true labels per context. num_sampled: Number of candidates to randomly sample. unique: If unique is true, we sample with rejection, so that all sampled
candidates in a batch are unique. This requires some approximation to estimate the post-rejection sampling probabilities.
range_max: The sampler will sample integers from the interval [0, range_max).
Returns A vector of length num_sampled, in which each element is the ID of a sampled candidate.A batch_size * num_true matrix, representing the number of times each candidate is expected to occur in a batch of sampled candidates. If unique=true, then this is a probability.A vector of length num_sampled, for each sampled candidate representing the number of times the candidate is expected to occur in a batch of sampled candidates. If unique=true, then this is a probability.
func LogicalAnd ¶ added in v1.1.0
Returns the truth value of x AND y element-wise.
*NOTE*: `LogicalAnd` supports broadcasting. More about broadcasting [here](http://docs.scipy.org/doc/numpy/user/basics.broadcasting.html)
func LogicalNot ¶ added in v1.1.0
Returns the truth value of NOT x element-wise.
func LogicalOr ¶ added in v1.1.0
Returns the truth value of x OR y element-wise.
*NOTE*: `LogicalOr` supports broadcasting. More about broadcasting [here](http://docs.scipy.org/doc/numpy/user/basics.broadcasting.html)
func LookupTableExportV2 ¶ added in v1.2.0
func LookupTableExportV2(scope *Scope, table_handle tf.Output, Tkeys tf.DataType, Tvalues tf.DataType) (keys tf.Output, values tf.Output)
Outputs all keys and values in the table.
Arguments:
table_handle: Handle to the table.
Returns Vector of all keys present in the table.Tensor of all values in the table. Indexed in parallel with `keys`.
func LookupTableFindV2 ¶ added in v1.2.0
func LookupTableFindV2(scope *Scope, table_handle tf.Output, keys tf.Output, default_value tf.Output) (values tf.Output)
Looks up keys in a table, outputs the corresponding values.
The tensor `keys` must of the same type as the keys of the table. The output `values` is of the type of the table values.
The scalar `default_value` is the value output for keys not present in the table. It must also be of the same type as the table values.
Arguments:
table_handle: Handle to the table. keys: Any shape. Keys to look up.
Returns Same shape as `keys`. Values found in the table, or `default_values` for missing keys.
func LookupTableImportV2 ¶ added in v1.2.0
func LookupTableImportV2(scope *Scope, table_handle tf.Output, keys tf.Output, values tf.Output) (o *tf.Operation)
Replaces the contents of the table with the specified keys and values.
The tensor `keys` must be of the same type as the keys of the table. The tensor `values` must be of the type of the table values.
Arguments:
table_handle: Handle to the table. keys: Any shape. Keys to look up. values: Values to associate with keys.
Returns the created operation.
func LookupTableInsertV2 ¶ added in v1.2.0
func LookupTableInsertV2(scope *Scope, table_handle tf.Output, keys tf.Output, values tf.Output) (o *tf.Operation)
Updates the table to associates keys with values.
The tensor `keys` must be of the same type as the keys of the table. The tensor `values` must be of the type of the table values.
Arguments:
table_handle: Handle to the table. keys: Any shape. Keys to look up. values: Values to associate with keys.
Returns the created operation.
func LookupTableSizeV2 ¶ added in v1.2.0
Computes the number of elements in the given table.
Arguments:
table_handle: Handle to the table.
Returns Scalar that contains number of elements in the table.
func LoopCond ¶ added in v1.1.0
Forwards the input to the output.
This operator represents the loop termination condition used by the "pivot" switches of a loop.
Arguments:
input: A boolean scalar, representing the branch predicate of the Switch op.
Returns The same tensor as `input`.
func MakeIterator ¶ added in v1.2.0
Makes a new iterator from the given `dataset` and stores it in `iterator`.
This operation may be executed multiple times. Each execution will reset the iterator in `iterator` to the first element of `dataset`.
Returns the created operation.
func MapClear ¶ added in v1.3.0
Op removes all elements in the underlying container.
Returns the created operation.
func MapIncompleteSize ¶ added in v1.3.0
func MapIncompleteSize(scope *Scope, dtypes []tf.DataType, optional ...MapIncompleteSizeAttr) (size tf.Output)
Op returns the number of incomplete elements in the underlying container.
func MapPeek ¶ added in v1.3.0
func MapPeek(scope *Scope, key tf.Output, indices tf.Output, dtypes []tf.DataType, optional ...MapPeekAttr) (values []tf.Output)
Op peeks at the values at the specified key. If the
underlying container does not contain this key this op will block until it does.
func MapStage ¶ added in v1.3.0
func MapStage(scope *Scope, key tf.Output, indices tf.Output, values []tf.Output, dtypes []tf.DataType, optional ...MapStageAttr) (o *tf.Operation)
Stage (key, values) in the underlying container which behaves like a hashtable.
Arguments:
key: int64 values: a list of tensors
dtypes A list of data types that inserted values should adhere to.
Returns the created operation.
func MapUnstage ¶ added in v1.3.0
func MapUnstage(scope *Scope, key tf.Output, indices tf.Output, dtypes []tf.DataType, optional ...MapUnstageAttr) (values []tf.Output)
Op removes and returns the values associated with the key
from the underlying container. If the underlying container does not contain this key, the op will block until it does.
func MapUnstageNoKey ¶ added in v1.3.0
func MapUnstageNoKey(scope *Scope, indices tf.Output, dtypes []tf.DataType, optional ...MapUnstageNoKeyAttr) (key tf.Output, values []tf.Output)
Op removes and returns a random (key, value)
from the underlying container. If the underlying container does not contain elements, the op will block until it does.
func MatMul ¶ added in v1.1.0
Multiply the matrix "a" by the matrix "b".
The inputs must be two-dimensional matrices and the inner dimension of "a" (after being transposed if transpose_a is true) must match the outer dimension of "b" (after being transposed if transposed_b is true).
*Note*: The default kernel implementation for MatMul on GPUs uses cublas.
func MatchingFiles ¶ added in v1.1.0
Returns the set of files matching one or more glob patterns.
Note that this routine only supports wildcard characters in the basename portion of the pattern, not in the directory portion.
Arguments:
pattern: Shell wildcard pattern(s). Scalar or vector of type string.
Returns A vector of matching filenames.
func MatrixBandPart ¶ added in v1.1.0
func MatrixBandPart(scope *Scope, input tf.Output, num_lower tf.Output, num_upper tf.Output) (band tf.Output)
Copy a tensor setting everything outside a central band in each innermost matrix
to zero.
The `band` part is computed as follows: Assume `input` has `k` dimensions `[I, J, K, ..., M, N]`, then the output is a tensor with the same shape where
`band[i, j, k, ..., m, n] = in_band(m, n) * input[i, j, k, ..., m, n]`.
The indicator function ¶
`in_band(m, n) = (num_lower < 0 || (m-n) <= num_lower)) &&
(num_upper < 0 || (n-m) <= num_upper)`.
For example:
``` # if 'input' is [[ 0, 1, 2, 3]
[-1, 0, 1, 2] [-2, -1, 0, 1] [-3, -2, -1, 0]],
tf.matrix_band_part(input, 1, -1) ==> [[ 0, 1, 2, 3]
[-1, 0, 1, 2] [ 0, -1, 0, 1] [ 0, 0, -1, 0]],
tf.matrix_band_part(input, 2, 1) ==> [[ 0, 1, 0, 0]
[-1, 0, 1, 0] [-2, -1, 0, 1] [ 0, -2, -1, 0]]
```
Useful special cases:
```
tf.matrix_band_part(input, 0, -1) ==> Upper triangular part. tf.matrix_band_part(input, -1, 0) ==> Lower triangular part. tf.matrix_band_part(input, 0, 0) ==> Diagonal.
```
Arguments:
input: Rank `k` tensor. num_lower: 0-D tensor. Number of subdiagonals to keep. If negative, keep entire
lower triangle.
num_upper: 0-D tensor. Number of superdiagonals to keep. If negative, keep
entire upper triangle.
Returns Rank `k` tensor of the same shape as input. The extracted banded tensor.
func MatrixDeterminant ¶ added in v1.1.0
Computes the determinant of one or more square matrices.
The input is a tensor of shape `[..., M, M]` whose inner-most 2 dimensions form square matrices. The output is a tensor containing the determinants for all input submatrices `[..., :, :]`.
Arguments:
input: Shape is `[..., M, M]`.
Returns Shape is `[...]`.
func MatrixDiag ¶ added in v1.1.0
Returns a batched diagonal tensor with a given batched diagonal values.
Given a `diagonal`, this operation returns a tensor with the `diagonal` and everything else padded with zeros. The diagonal is computed as follows:
Assume `diagonal` has `k` dimensions `[I, J, K, ..., N]`, then the output is a tensor of rank `k+1` with dimensions [I, J, K, ..., N, N]` where:
`output[i, j, k, ..., m, n] = 1{m=n} * diagonal[i, j, k, ..., n]`.
For example:
``` # 'diagonal' is [[1, 2, 3, 4], [5, 6, 7, 8]]
and diagonal.shape = (2, 4)
tf.matrix_diag(diagonal) ==> [[[1, 0, 0, 0]
[0, 2, 0, 0] [0, 0, 3, 0] [0, 0, 0, 4]], [[5, 0, 0, 0] [0, 6, 0, 0] [0, 0, 7, 0] [0, 0, 0, 8]]]
which has shape (2, 4, 4) ```
Arguments:
diagonal: Rank `k`, where `k >= 1`.
Returns Rank `k+1`, with `output.shape = diagonal.shape + [diagonal.shape[-1]]`.
func MatrixDiagPart ¶ added in v1.1.0
Returns the batched diagonal part of a batched tensor.
This operation returns a tensor with the `diagonal` part of the batched `input`. The `diagonal` part is computed as follows:
Assume `input` has `k` dimensions `[I, J, K, ..., M, N]`, then the output is a tensor of rank `k - 1` with dimensions `[I, J, K, ..., min(M, N)]` where:
`diagonal[i, j, k, ..., n] = input[i, j, k, ..., n, n]`.
The input must be at least a matrix.
For example:
``` # 'input' is [[[1, 0, 0, 0]
[0, 2, 0, 0] [0, 0, 3, 0] [0, 0, 0, 4]], [[5, 0, 0, 0] [0, 6, 0, 0] [0, 0, 7, 0] [0, 0, 0, 8]]]
and input.shape = (2, 4, 4)
tf.matrix_diag_part(input) ==> [[1, 2, 3, 4], [5, 6, 7, 8]]
which has shape (2, 4) ```
Arguments:
input: Rank `k` tensor where `k >= 2`.
Returns The extracted diagonal(s) having shape `diagonal.shape = input.shape[:-2] + [min(input.shape[-2:])]`.
func MatrixExponential ¶ added in v1.5.0
Computes the matrix exponential of one or more square matrices:
exp(A) = \sum_{n=0}^\infty A^n/n!
The exponential is computed using a combination of the scaling and squaring method and the Pade approximation. Details can be founds in: Nicholas J. Higham, "The scaling and squaring method for the matrix exponential revisited," SIAM J. Matrix Anal. Applic., 26:1179-1193, 2005.
The input is a tensor of shape `[..., M, M]` whose inner-most 2 dimensions form square matrices. The output is a tensor of the same shape as the input containing the exponential for all input submatrices `[..., :, :]`.
Arguments:
input: Shape is `[..., M, M]`.
Returns Shape is `[..., M, M]`.
@compatibility(scipy) Equivalent to scipy.linalg.expm @end_compatibility
func MatrixInverse ¶ added in v1.1.0
Computes the inverse of one or more square invertible matrices or their
adjoints (conjugate transposes).
The input is a tensor of shape `[..., M, M]` whose inner-most 2 dimensions form square matrices. The output is a tensor of the same shape as the input containing the inverse for all input submatrices `[..., :, :]`.
The op uses LU decomposition with partial pivoting to compute the inverses.
If a matrix is not invertible there is no guarantee what the op does. It may detect the condition and raise an exception or it may simply return a garbage result.
Arguments:
input: Shape is `[..., M, M]`.
Returns Shape is `[..., M, M]`.
@compatibility(numpy) Equivalent to np.linalg.inv @end_compatibility
func MatrixSetDiag ¶ added in v1.1.0
Returns a batched matrix tensor with new batched diagonal values.
Given `input` and `diagonal`, this operation returns a tensor with the same shape and values as `input`, except for the main diagonal of the innermost matrices. These will be overwritten by the values in `diagonal`.
The output is computed as follows:
Assume `input` has `k+1` dimensions `[I, J, K, ..., M, N]` and `diagonal` has `k` dimensions `[I, J, K, ..., min(M, N)]`. Then the output is a tensor of rank `k+1` with dimensions `[I, J, K, ..., M, N]` where:
- `output[i, j, k, ..., m, n] = diagonal[i, j, k, ..., n]` for `m == n`.
- `output[i, j, k, ..., m, n] = input[i, j, k, ..., m, n]` for `m != n`.
Arguments:
input: Rank `k+1`, where `k >= 1`. diagonal: Rank `k`, where `k >= 1`.
Returns Rank `k+1`, with `output.shape = input.shape`.
func MatrixSolve ¶ added in v1.1.0
func MatrixSolve(scope *Scope, matrix tf.Output, rhs tf.Output, optional ...MatrixSolveAttr) (output tf.Output)
Solves systems of linear equations.
`Matrix` is a tensor of shape `[..., M, M]` whose inner-most 2 dimensions form square matrices. `Rhs` is a tensor of shape `[..., M, K]`. The `output` is a tensor shape `[..., M, K]`. If `adjoint` is `False` then each output matrix satisfies `matrix[..., :, :] * output[..., :, :] = rhs[..., :, :]`. If `adjoint` is `True` then each output matrix satisfies `adjoint(matrix[..., :, :]) * output[..., :, :] = rhs[..., :, :]`.
Arguments:
matrix: Shape is `[..., M, M]`. rhs: Shape is `[..., M, K]`.
Returns Shape is `[..., M, K]`.
func MatrixSolveLs ¶ added in v1.1.0
func MatrixSolveLs(scope *Scope, matrix tf.Output, rhs tf.Output, l2_regularizer tf.Output, optional ...MatrixSolveLsAttr) (output tf.Output)
Solves one or more linear least-squares problems.
`matrix` is a tensor of shape `[..., M, N]` whose inner-most 2 dimensions form real or complex matrices of size `[M, N]`. `Rhs` is a tensor of the same type as `matrix` and shape `[..., M, K]`. The output is a tensor shape `[..., N, K]` where each output matrix solves each of the equations `matrix[..., :, :]` * `output[..., :, :]` = `rhs[..., :, :]` in the least squares sense.
We use the following notation for (complex) matrix and right-hand sides in the batch:
`matrix`=\\(A \in \mathbb{C}^{m \times n}\\), `rhs`=\\(B \in \mathbb{C}^{m \times k}\\), `output`=\\(X \in \mathbb{C}^{n \times k}\\), `l2_regularizer`=\\(\lambda \in \mathbb{R}\\).
If `fast` is `True`, then the solution is computed by solving the normal equations using Cholesky decomposition. Specifically, if \\(m \ge n\\) then \\(X = (A^H A + \lambda I)^{-1} A^H B\\), which solves the least-squares problem \\(X = \mathrm{argmin}_{Z \in \Re^{n \times k} } ||A Z - B||_F^2 + \lambda ||Z||_F^2\\). If \\(m \lt n\\) then `output` is computed as \\(X = A^H (A A^H + \lambda I)^{-1} B\\), which (for \\(\lambda = 0\\)) is the minimum-norm solution to the under-determined linear system, i.e. \\(X = \mathrm{argmin}_{Z \in \mathbb{C}^{n \times k} } ||Z||_F^2 \\), subject to \\(A Z = B\\). Notice that the fast path is only numerically stable when \\(A\\) is numerically full rank and has a condition number \\(\mathrm{cond}(A) \lt \frac{1}{\sqrt{\epsilon_{mach} } }\\) or\\(\lambda\\) is sufficiently large.
If `fast` is `False` an algorithm based on the numerically robust complete orthogonal decomposition is used. This computes the minimum-norm least-squares solution, even when \\(A\\) is rank deficient. This path is typically 6-7 times slower than the fast path. If `fast` is `False` then `l2_regularizer` is ignored.
Arguments:
matrix: Shape is `[..., M, N]`. rhs: Shape is `[..., M, K]`. l2_regularizer: Scalar tensor.
@compatibility(numpy) Equivalent to np.linalg.lstsq @end_compatibility
Returns Shape is `[..., N, K]`.
func MatrixTriangularSolve ¶ added in v1.1.0
func MatrixTriangularSolve(scope *Scope, matrix tf.Output, rhs tf.Output, optional ...MatrixTriangularSolveAttr) (output tf.Output)
Solves systems of linear equations with upper or lower triangular matrices by
backsubstitution.
`matrix` is a tensor of shape `[..., M, M]` whose inner-most 2 dimensions form square matrices. If `lower` is `True` then the strictly upper triangular part of each inner-most matrix is assumed to be zero and not accessed. If `lower` is False then the strictly lower triangular part of each inner-most matrix is assumed to be zero and not accessed. `rhs` is a tensor of shape `[..., M, K]`.
The output is a tensor of shape `[..., M, K]`. If `adjoint` is `True` then the innermost matrices in `output` satisfy matrix equations `matrix[..., :, :] * output[..., :, :] = rhs[..., :, :]`. If `adjoint` is `False` then the strictly then the innermost matrices in `output` satisfy matrix equations `adjoint(matrix[..., i, k]) * output[..., k, j] = rhs[..., i, j]`.
Arguments:
matrix: Shape is `[..., M, M]`. rhs: Shape is `[..., M, K]`.
Returns Shape is `[..., M, K]`.
func Max ¶ added in v1.1.0
Computes the maximum of elements across dimensions of a tensor.
Reduces `input` along the dimensions given in `axis`. Unless `keep_dims` is true, the rank of the tensor is reduced by 1 for each entry in `axis`. If `keep_dims` is true, the reduced dimensions are retained with length 1.
Arguments:
input: The tensor to reduce. axis: The dimensions to reduce. Must be in the range
`[-rank(input), rank(input))`.
Returns The reduced tensor.
func MaxPool ¶ added in v1.1.0
func MaxPool(scope *Scope, input tf.Output, ksize []int64, strides []int64, padding string, optional ...MaxPoolAttr) (output tf.Output)
Performs max pooling on the input.
Arguments:
input: 4-D input to pool over. ksize: The size of the window for each dimension of the input tensor. strides: The stride of the sliding window for each dimension of the
input tensor.
padding: The type of padding algorithm to use.
Returns The max pooled output tensor.
func MaxPool3D ¶ added in v1.1.0
func MaxPool3D(scope *Scope, input tf.Output, ksize []int64, strides []int64, padding string, optional ...MaxPool3DAttr) (output tf.Output)
Performs 3D max pooling on the input.
Arguments:
input: Shape `[batch, depth, rows, cols, channels]` tensor to pool over. ksize: 1-D tensor of length 5. The size of the window for each dimension of
the input tensor. Must have `ksize[0] = ksize[4] = 1`.
strides: 1-D tensor of length 5. The stride of the sliding window for each
dimension of `input`. Must have `strides[0] = strides[4] = 1`.
padding: The type of padding algorithm to use.
Returns The max pooled output tensor.
func MaxPool3DGrad ¶ added in v1.1.0
func MaxPool3DGrad(scope *Scope, orig_input tf.Output, orig_output tf.Output, grad tf.Output, ksize []int64, strides []int64, padding string, optional ...MaxPool3DGradAttr) (output tf.Output)
Computes gradients of max pooling function.
Arguments:
orig_input: The original input tensor. orig_output: The original output tensor. grad: Output backprop of shape `[batch, depth, rows, cols, channels]`. ksize: 1-D tensor of length 5. The size of the window for each dimension of
the input tensor. Must have `ksize[0] = ksize[4] = 1`.
strides: 1-D tensor of length 5. The stride of the sliding window for each
dimension of `input`. Must have `strides[0] = strides[4] = 1`.
padding: The type of padding algorithm to use.
func MaxPool3DGradGrad ¶ added in v1.2.0
func MaxPool3DGradGrad(scope *Scope, orig_input tf.Output, orig_output tf.Output, grad tf.Output, ksize []int64, strides []int64, padding string, optional ...MaxPool3DGradGradAttr) (output tf.Output)
Computes second-order gradients of the maxpooling function.
Arguments:
orig_input: The original input tensor. orig_output: The original output tensor. grad: Output backprop of shape `[batch, depth, rows, cols, channels]`. ksize: 1-D tensor of length 5. The size of the window for each dimension of
the input tensor. Must have `ksize[0] = ksize[4] = 1`.
strides: 1-D tensor of length 5. The stride of the sliding window for each
dimension of `input`. Must have `strides[0] = strides[4] = 1`.
padding: The type of padding algorithm to use.
Returns Gradients of gradients w.r.t. the input to `max_pool`.
func MaxPoolGrad ¶ added in v1.1.0
func MaxPoolGrad(scope *Scope, orig_input tf.Output, orig_output tf.Output, grad tf.Output, ksize []int64, strides []int64, padding string, optional ...MaxPoolGradAttr) (output tf.Output)
Computes gradients of the maxpooling function.
Arguments:
orig_input: The original input tensor. orig_output: The original output tensor. grad: 4-D. Gradients w.r.t. the output of `max_pool`. ksize: The size of the window for each dimension of the input tensor. strides: The stride of the sliding window for each dimension of the
input tensor.
padding: The type of padding algorithm to use.
Returns Gradients w.r.t. the input to `max_pool`.
func MaxPoolGradGrad ¶ added in v1.2.0
func MaxPoolGradGrad(scope *Scope, orig_input tf.Output, orig_output tf.Output, grad tf.Output, ksize []int64, strides []int64, padding string, optional ...MaxPoolGradGradAttr) (output tf.Output)
Computes second-order gradients of the maxpooling function.
Arguments:
orig_input: The original input tensor. orig_output: The original output tensor. grad: 4-D. Gradients of gradients w.r.t. the input of `max_pool`. ksize: The size of the window for each dimension of the input tensor. strides: The stride of the sliding window for each dimension of the
input tensor.
padding: The type of padding algorithm to use.
Returns Gradients of gradients w.r.t. the input to `max_pool`.
func MaxPoolGradGradV2 ¶ added in v1.4.0
func MaxPoolGradGradV2(scope *Scope, orig_input tf.Output, orig_output tf.Output, grad tf.Output, ksize tf.Output, strides tf.Output, padding string, optional ...MaxPoolGradGradV2Attr) (output tf.Output)
Computes second-order gradients of the maxpooling function.
Arguments:
orig_input: The original input tensor. orig_output: The original output tensor. grad: 4-D. Gradients of gradients w.r.t. the input of `max_pool`. ksize: The size of the window for each dimension of the input tensor. strides: The stride of the sliding window for each dimension of the
input tensor.
padding: The type of padding algorithm to use.
Returns Gradients of gradients w.r.t. the input to `max_pool`.
func MaxPoolGradGradWithArgmax ¶ added in v1.2.0
func MaxPoolGradGradWithArgmax(scope *Scope, input tf.Output, grad tf.Output, argmax tf.Output, ksize []int64, strides []int64, padding string) (output tf.Output)
Computes second-order gradients of the maxpooling function.
Arguments:
input: The original input. grad: 4-D with shape `[batch, height, width, channels]`. Gradients w.r.t. the
input of `max_pool`.
argmax: The indices of the maximum values chosen for each output of `max_pool`. ksize: The size of the window for each dimension of the input tensor. strides: The stride of the sliding window for each dimension of the
input tensor.
padding: The type of padding algorithm to use.
Returns Gradients of gradients w.r.t. the input of `max_pool`.
func MaxPoolGradV2 ¶ added in v1.4.0
func MaxPoolGradV2(scope *Scope, orig_input tf.Output, orig_output tf.Output, grad tf.Output, ksize tf.Output, strides tf.Output, padding string, optional ...MaxPoolGradV2Attr) (output tf.Output)
Computes gradients of the maxpooling function.
Arguments:
orig_input: The original input tensor. orig_output: The original output tensor. grad: 4-D. Gradients w.r.t. the output of `max_pool`. ksize: The size of the window for each dimension of the input tensor. strides: The stride of the sliding window for each dimension of the
input tensor.
padding: The type of padding algorithm to use.
Returns Gradients w.r.t. the input to `max_pool`.
func MaxPoolGradWithArgmax ¶ added in v1.1.0
func MaxPoolGradWithArgmax(scope *Scope, input tf.Output, grad tf.Output, argmax tf.Output, ksize []int64, strides []int64, padding string) (output tf.Output)
Computes gradients of the maxpooling function.
Arguments:
input: The original input. grad: 4-D with shape `[batch, height, width, channels]`. Gradients w.r.t. the
output of `max_pool`.
argmax: The indices of the maximum values chosen for each output of `max_pool`. ksize: The size of the window for each dimension of the input tensor. strides: The stride of the sliding window for each dimension of the
input tensor.
padding: The type of padding algorithm to use.
Returns Gradients w.r.t. the input of `max_pool`.
func MaxPoolV2 ¶ added in v1.4.0
func MaxPoolV2(scope *Scope, input tf.Output, ksize tf.Output, strides tf.Output, padding string, optional ...MaxPoolV2Attr) (output tf.Output)
Performs max pooling on the input.
Arguments:
input: 4-D input to pool over. ksize: The size of the window for each dimension of the input tensor. strides: The stride of the sliding window for each dimension of the
input tensor.
padding: The type of padding algorithm to use.
Returns The max pooled output tensor.
func MaxPoolWithArgmax ¶ added in v1.1.0
func MaxPoolWithArgmax(scope *Scope, input tf.Output, ksize []int64, strides []int64, padding string, optional ...MaxPoolWithArgmaxAttr) (output tf.Output, argmax tf.Output)
Performs max pooling on the input and outputs both max values and indices.
The indices in `argmax` are flattened, so that a maximum value at position `[b, y, x, c]` becomes flattened index `((b * height + y) * width + x) * channels + c`.
The indices returned are always in `[0, height) x [0, width)` before flattening, even if padding is involved and the mathematically correct answer is outside (either negative or too large). This is a bug, but fixing it is difficult to do in a safe backwards compatible way, especially due to flattening.
Arguments:
input: 4-D with shape `[batch, height, width, channels]`. Input to pool over. ksize: The size of the window for each dimension of the input tensor. strides: The stride of the sliding window for each dimension of the
input tensor.
padding: The type of padding algorithm to use.
Returns The max pooled output tensor.4-D. The flattened indices of the max values chosen for each output.
func Maximum ¶ added in v1.1.0
Returns the max of x and y (i.e. x > y ? x : y) element-wise.
*NOTE*: `Maximum` supports broadcasting. More about broadcasting [here](http://docs.scipy.org/doc/numpy/user/basics.broadcasting.html)
func Mean ¶ added in v1.1.0
Computes the mean of elements across dimensions of a tensor.
Reduces `input` along the dimensions given in `axis`. Unless `keep_dims` is true, the rank of the tensor is reduced by 1 for each entry in `axis`. If `keep_dims` is true, the reduced dimensions are retained with length 1.
Arguments:
input: The tensor to reduce. axis: The dimensions to reduce. Must be in the range
`[-rank(input), rank(input))`.
Returns The reduced tensor.
func Merge ¶ added in v1.1.0
Forwards the value of an available tensor from `inputs` to `output`.
`Merge` waits for at least one of the tensors in `inputs` to become available. It is usually combined with `Switch` to implement branching.
`Merge` forwards the first tensor to become available to `output`, and sets `value_index` to its index in `inputs`.
Arguments:
inputs: The input tensors, exactly one of which will become available.
Returns Will be set to the available input tensor.The index of the chosen input tensor in `inputs`.
func MergeSummary ¶ added in v1.1.0
Merges summaries.
This op creates a [`Summary`](https://www.tensorflow.org/code/tensorflow/core/framework/summary.proto) protocol buffer that contains the union of all the values in the input summaries.
When the Op is run, it reports an `InvalidArgument` error if multiple values in the summaries to merge use the same tag.
Arguments:
inputs: Can be of any shape. Each must contain serialized `Summary` protocol
buffers.
Returns Scalar. Serialized `Summary` protocol buffer.
func MergeV2Checkpoints ¶ added in v1.1.0
func MergeV2Checkpoints(scope *Scope, checkpoint_prefixes tf.Output, destination_prefix tf.Output, optional ...MergeV2CheckpointsAttr) (o *tf.Operation)
V2 format specific: merges the metadata files of sharded checkpoints. The
result is one logical checkpoint, with one physical metadata file and renamed data files.
Intended for "grouping" multiple checkpoints in a sharded checkpoint setup.
If delete_old_dirs is true, attempts to delete recursively the dirname of each path in the input checkpoint_prefixes. This is useful when those paths are non user-facing temporary locations.
Arguments:
checkpoint_prefixes: prefixes of V2 checkpoints to merge. destination_prefix: scalar. The desired final prefix. Allowed to be the same
as one of the checkpoint_prefixes.
Returns the created operation.
func Mfcc ¶ added in v1.2.0
func Mfcc(scope *Scope, spectrogram tf.Output, sample_rate tf.Output, optional ...MfccAttr) (output tf.Output)
Transforms a spectrogram into a form that's useful for speech recognition.
Mel Frequency Cepstral Coefficients are a way of representing audio data that's been effective as an input feature for machine learning. They are created by taking the spectrum of a spectrogram (a 'cepstrum'), and discarding some of the higher frequencies that are less significant to the human ear. They have a long history in the speech recognition world, and https://en.wikipedia.org/wiki/Mel-frequency_cepstrum is a good resource to learn more.
Arguments:
spectrogram: Typically produced by the Spectrogram op, with magnitude_squared
set to true.
sample_rate: How many samples per second the source audio used.
func Min ¶ added in v1.1.0
Computes the minimum of elements across dimensions of a tensor.
Reduces `input` along the dimensions given in `axis`. Unless `keep_dims` is true, the rank of the tensor is reduced by 1 for each entry in `axis`. If `keep_dims` is true, the reduced dimensions are retained with length 1.
Arguments:
input: The tensor to reduce. axis: The dimensions to reduce. Must be in the range
`[-rank(input), rank(input))`.
Returns The reduced tensor.
func Minimum ¶ added in v1.1.0
Returns the min of x and y (i.e. x < y ? x : y) element-wise.
*NOTE*: `Minimum` supports broadcasting. More about broadcasting [here](http://docs.scipy.org/doc/numpy/user/basics.broadcasting.html)
func MirrorPad ¶ added in v1.1.0
Pads a tensor with mirrored values.
This operation pads a `input` with mirrored values according to the `paddings` you specify. `paddings` is an integer tensor with shape `[n, 2]`, where n is the rank of `input`. For each dimension D of `input`, `paddings[D, 0]` indicates how many values to add before the contents of `input` in that dimension, and `paddings[D, 1]` indicates how many values to add after the contents of `input` in that dimension. Both `paddings[D, 0]` and `paddings[D, 1]` must be no greater than `input.dim_size(D)` (or `input.dim_size(D) - 1`) if `copy_border` is true (if false, respectively).
The padded size of each dimension D of the output is:
`paddings(D, 0) + input.dim_size(D) + paddings(D, 1)`
For example:
``` # 't' is [[1, 2, 3], [4, 5, 6]]. # 'paddings' is [[1, 1]], [2, 2]]. # 'mode' is SYMMETRIC. # rank of 't' is 2. pad(t, paddings) ==> [[2, 1, 1, 2, 3, 3, 2]
[2, 1, 1, 2, 3, 3, 2] [5, 4, 4, 5, 6, 6, 5] [5, 4, 4, 5, 6, 6, 5]]
```
Arguments:
input: The input tensor to be padded. paddings: A two-column matrix specifying the padding sizes. The number of
rows must be the same as the rank of `input`.
mode: Either `REFLECT` or `SYMMETRIC`. In reflect mode the padded regions
do not include the borders, while in symmetric mode the padded regions do include the borders. For example, if `input` is `[1, 2, 3]` and `paddings` is `[0, 2]`, then the output is `[1, 2, 3, 2, 1]` in reflect mode, and it is `[1, 2, 3, 3, 2]` in symmetric mode.
Returns The padded tensor.
func MirrorPadGrad ¶ added in v1.1.0
func MirrorPadGrad(scope *Scope, input tf.Output, paddings tf.Output, mode string) (output tf.Output)
Gradient op for `MirrorPad` op. This op folds a mirror-padded tensor.
This operation folds the padded areas of `input` by `MirrorPad` according to the `paddings` you specify. `paddings` must be the same as `paddings` argument given to the corresponding `MirrorPad` op.
The folded size of each dimension D of the output is:
`input.dim_size(D) - paddings(D, 0) - paddings(D, 1)`
For example:
``` # 't' is [[1, 2, 3], [4, 5, 6], [7, 8, 9]]. # 'paddings' is [[0, 1]], [0, 1]]. # 'mode' is SYMMETRIC. # rank of 't' is 2. pad(t, paddings) ==> [[ 1, 5]
[11, 28]]
```
Arguments:
input: The input tensor to be folded. paddings: A two-column matrix specifying the padding sizes. The number of
rows must be the same as the rank of `input`.
mode: The mode used in the `MirrorPad` op.
Returns The folded tensor.
func Mod ¶ added in v1.1.0
Returns element-wise remainder of division. This emulates C semantics in that
the result here is consistent with a truncating divide. E.g. `tf.truncatediv(x, y) * y + truncate_mod(x, y) = x`.
*NOTE*: `Mod` supports broadcasting. More about broadcasting [here](http://docs.scipy.org/doc/numpy/user/basics.broadcasting.html)
func Mul ¶ added in v1.1.0
Returns x * y element-wise.
*NOTE*: `Multiply` supports broadcasting. More about broadcasting [here](http://docs.scipy.org/doc/numpy/user/basics.broadcasting.html)
func Multinomial ¶ added in v1.1.0
func Multinomial(scope *Scope, logits tf.Output, num_samples tf.Output, optional ...MultinomialAttr) (output tf.Output)
Draws samples from a multinomial distribution.
Arguments:
logits: 2-D Tensor with shape `[batch_size, num_classes]`. Each slice `[i, :]`
represents the unnormalized log probabilities for all classes.
num_samples: 0-D. Number of independent samples to draw for each row slice.
Returns 2-D Tensor with shape `[batch_size, num_samples]`. Each slice `[i, :]` contains the drawn class labels with range `[0, num_classes)`.
func MutableDenseHashTableV2 ¶ added in v1.2.0
func MutableDenseHashTableV2(scope *Scope, empty_key tf.Output, value_dtype tf.DataType, optional ...MutableDenseHashTableV2Attr) (table_handle tf.Output)
Creates an empty hash table that uses tensors as the backing store.
It uses "open addressing" with quadratic reprobing to resolve collisions.
This op creates a mutable hash table, specifying the type of its keys and values. Each value must be a scalar. Data can be inserted into the table using the insert operations. It does not support the initialization operation.
Arguments:
empty_key: The key used to represent empty key buckets internally. Must not
be used in insert or lookup operations.
value_dtype: Type of the table values.
Returns Handle to a table.
func MutableHashTableOfTensorsV2 ¶ added in v1.2.0
func MutableHashTableOfTensorsV2(scope *Scope, key_dtype tf.DataType, value_dtype tf.DataType, optional ...MutableHashTableOfTensorsV2Attr) (table_handle tf.Output)
Creates an empty hash table.
This op creates a mutable hash table, specifying the type of its keys and values. Each value must be a vector. Data can be inserted into the table using the insert operations. It does not support the initialization operation.
Arguments:
key_dtype: Type of the table keys. value_dtype: Type of the table values.
Returns Handle to a table.
func MutableHashTableV2 ¶ added in v1.2.0
func MutableHashTableV2(scope *Scope, key_dtype tf.DataType, value_dtype tf.DataType, optional ...MutableHashTableV2Attr) (table_handle tf.Output)
Creates an empty hash table.
This op creates a mutable hash table, specifying the type of its keys and values. Each value must be a scalar. Data can be inserted into the table using the insert operations. It does not support the initialization operation.
Arguments:
key_dtype: Type of the table keys. value_dtype: Type of the table values.
Returns Handle to a table.
func NextIteration ¶ added in v1.1.0
Makes its input available to the next iteration.
Arguments:
data: The tensor to be made available to the next iteration.
Returns The same tensor as `data`.
func NoOp ¶ added in v1.1.0
Does nothing. Only useful as a placeholder for control edges.
Returns the created operation.
func NonMaxSuppression ¶ added in v1.1.0
func NonMaxSuppression(scope *Scope, boxes tf.Output, scores tf.Output, max_output_size tf.Output, optional ...NonMaxSuppressionAttr) (selected_indices tf.Output)
Greedily selects a subset of bounding boxes in descending order of score,
pruning away boxes that have high intersection-over-union (IOU) overlap with previously selected boxes. Bounding boxes are supplied as [y1, x1, y2, x2], where (y1, x1) and (y2, x2) are the coordinates of any diagonal pair of box corners and the coordinates can be provided as normalized (i.e., lying in the interval [0, 1]) or absolute. Note that this algorithm is agnostic to where the origin is in the coordinate system. Note that this algorithm is invariant to orthogonal transformations and translations of the coordinate system; thus translating or reflections of the coordinate system result in the same boxes being selected by the algorithm. The output of this operation is a set of integers indexing into the input collection of bounding boxes representing the selected boxes. The bounding box coordinates corresponding to the selected indices can then be obtained using the `tf.gather operation`. For example:
selected_indices = tf.image.non_max_suppression(
boxes, scores, max_output_size, iou_threshold)
selected_boxes = tf.gather(boxes, selected_indices)
Arguments:
boxes: A 2-D float tensor of shape `[num_boxes, 4]`. scores: A 1-D float tensor of shape `[num_boxes]` representing a single
score corresponding to each box (each row of boxes).
max_output_size: A scalar integer tensor representing the maximum number of
boxes to be selected by non max suppression.
Returns A 1-D integer tensor of shape `[M]` representing the selected indices from the boxes tensor, where `M <= max_output_size`.
func NonMaxSuppressionV2 ¶ added in v1.3.0
func NonMaxSuppressionV2(scope *Scope, boxes tf.Output, scores tf.Output, max_output_size tf.Output, iou_threshold tf.Output) (selected_indices tf.Output)
Greedily selects a subset of bounding boxes in descending order of score,
pruning away boxes that have high intersection-over-union (IOU) overlap with previously selected boxes. Bounding boxes are supplied as [y1, x1, y2, x2], where (y1, x1) and (y2, x2) are the coordinates of any diagonal pair of box corners and the coordinates can be provided as normalized (i.e., lying in the interval [0, 1]) or absolute. Note that this algorithm is agnostic to where the origin is in the coordinate system. Note that this algorithm is invariant to orthogonal transformations and translations of the coordinate system; thus translating or reflections of the coordinate system result in the same boxes being selected by the algorithm.
The output of this operation is a set of integers indexing into the input collection of bounding boxes representing the selected boxes. The bounding box coordinates corresponding to the selected indices can then be obtained using the `tf.gather operation`. For example:
selected_indices = tf.image.non_max_suppression_v2(
boxes, scores, max_output_size, iou_threshold)
selected_boxes = tf.gather(boxes, selected_indices)
Arguments:
boxes: A 2-D float tensor of shape `[num_boxes, 4]`. scores: A 1-D float tensor of shape `[num_boxes]` representing a single
score corresponding to each box (each row of boxes).
max_output_size: A scalar integer tensor representing the maximum number of
boxes to be selected by non max suppression.
iou_threshold: A 0-D float tensor representing the threshold for deciding whether
boxes overlap too much with respect to IOU.
Returns A 1-D integer tensor of shape `[M]` representing the selected indices from the boxes tensor, where `M <= max_output_size`.
func NotEqual ¶ added in v1.1.0
Returns the truth value of (x != y) element-wise.
*NOTE*: `NotEqual` supports broadcasting. More about broadcasting [here](http://docs.scipy.org/doc/numpy/user/basics.broadcasting.html)
func NthElement ¶ added in v1.5.0
func NthElement(scope *Scope, input tf.Output, n tf.Output, optional ...NthElementAttr) (values tf.Output)
Finds values of the `n`-th order statistic for the last dimension.
If the input is a vector (rank-1), finds the entries which is the nth-smallest value in the vector and outputs their values as scalar tensor.
For matrices (resp. higher rank input), computes the entries which is the nth-smallest value in each row (resp. vector along the last dimension). Thus,
values.shape = input.shape[:-1]
Arguments:
input: 1-D or higher with last dimension at least `n+1`. n: 0-D. Position of sorted vector to select along the last dimension (along
each row for matrices). Valid range of n is `[0, input.shape[:-1])`
Returns The `n`-th order statistic along each last dimensional slice.
func OneHot ¶ added in v1.1.0
func OneHot(scope *Scope, indices tf.Output, depth tf.Output, on_value tf.Output, off_value tf.Output, optional ...OneHotAttr) (output tf.Output)
Returns a one-hot tensor.
The locations represented by indices in `indices` take value `on_value`, while all other locations take value `off_value`.
If the input `indices` is rank `N`, the output will have rank `N+1`, The new axis is created at dimension `axis` (default: the new axis is appended at the end).
If `indices` is a scalar the output shape will be a vector of length `depth`.
If `indices` is a vector of length `features`, the output shape will be: ```
features x depth if axis == -1 depth x features if axis == 0
```
If `indices` is a matrix (batch) with shape `[batch, features]`, the output shape will be: ```
batch x features x depth if axis == -1 batch x depth x features if axis == 1 depth x batch x features if axis == 0
```
Examples =========
Suppose that ¶
```
indices = [0, 2, -1, 1] depth = 3 on_value = 5.0 off_value = 0.0 axis = -1
```
Then output is `[4 x 3]`:
```output = [5.0 0.0 0.0] // one_hot(0) [0.0 0.0 5.0] // one_hot(2) [0.0 0.0 0.0] // one_hot(-1) [0.0 5.0 0.0] // one_hot(1) ```
Suppose that ¶
```
indices = [0, 2, -1, 1] depth = 3 on_value = 0.0 off_value = 3.0 axis = 0
```
Then output is `[3 x 4]`:
```output = [0.0 3.0 3.0 3.0] [3.0 3.0 3.0 0.0] [3.0 3.0 3.0 3.0] [3.0 0.0 3.0 3.0] // ^ one_hot(0) // ^ one_hot(2) // ^ one_hot(-1) // ^ one_hot(1) ```
Suppose that
```
indices = [[0, 2], [1, -1]] depth = 3 on_value = 1.0 off_value = 0.0 axis = -1
```
Then output is `[2 x 2 x 3]`:
```output =
[
[1.0, 0.0, 0.0] // one_hot(0)
[0.0, 0.0, 1.0] // one_hot(2)
][
[0.0, 1.0, 0.0] // one_hot(1)
[0.0, 0.0, 0.0] // one_hot(-1)
]```
Arguments:
indices: A tensor of indices. depth: A scalar defining the depth of the one hot dimension. on_value: A scalar defining the value to fill in output when `indices[j] = i`. off_value: A scalar defining the value to fill in output when `indices[j] != i`.
Returns The one-hot tensor.
func OnesLike ¶ added in v1.2.0
Returns a tensor of ones with the same shape and type as x.
Arguments:
x: a tensor of type T.
Returns a tensor of the same shape and type as x but filled with ones.
func OrderedMapClear ¶ added in v1.3.0
func OrderedMapClear(scope *Scope, dtypes []tf.DataType, optional ...OrderedMapClearAttr) (o *tf.Operation)
Op removes all elements in the underlying container.
Returns the created operation.
func OrderedMapIncompleteSize ¶ added in v1.3.0
func OrderedMapIncompleteSize(scope *Scope, dtypes []tf.DataType, optional ...OrderedMapIncompleteSizeAttr) (size tf.Output)
Op returns the number of incomplete elements in the underlying container.
func OrderedMapPeek ¶ added in v1.3.0
func OrderedMapPeek(scope *Scope, key tf.Output, indices tf.Output, dtypes []tf.DataType, optional ...OrderedMapPeekAttr) (values []tf.Output)
Op peeks at the values at the specified key. If the
underlying container does not contain this key this op will block until it does. This Op is optimized for performance.
func OrderedMapSize ¶ added in v1.3.0
func OrderedMapSize(scope *Scope, dtypes []tf.DataType, optional ...OrderedMapSizeAttr) (size tf.Output)
Op returns the number of elements in the underlying container.
func OrderedMapStage ¶ added in v1.3.0
func OrderedMapStage(scope *Scope, key tf.Output, indices tf.Output, values []tf.Output, dtypes []tf.DataType, optional ...OrderedMapStageAttr) (o *tf.Operation)
Stage (key, values) in the underlying container which behaves like a ordered
associative container. Elements are ordered by key.
Arguments:
key: int64 values: a list of tensors
dtypes A list of data types that inserted values should adhere to.
Returns the created operation.
func OrderedMapUnstage ¶ added in v1.3.0
func OrderedMapUnstage(scope *Scope, key tf.Output, indices tf.Output, dtypes []tf.DataType, optional ...OrderedMapUnstageAttr) (values []tf.Output)
Op removes and returns the values associated with the key
from the underlying container. If the underlying container does not contain this key, the op will block until it does.
func OrderedMapUnstageNoKey ¶ added in v1.3.0
func OrderedMapUnstageNoKey(scope *Scope, indices tf.Output, dtypes []tf.DataType, optional ...OrderedMapUnstageNoKeyAttr) (key tf.Output, values []tf.Output)
Op removes and returns the (key, value) element with the smallest
key from the underlying container. If the underlying container does not contain elements, the op will block until it does.
func Pack ¶ added in v1.1.0
Packs a list of `N` rank-`R` tensors into one rank-`(R+1)` tensor.
Packs the `N` tensors in `values` into a tensor with rank one higher than each tensor in `values`, by packing them along the `axis` dimension. Given a list of tensors of shape `(A, B, C)`;
if `axis == 0` then the `output` tensor will have the shape `(N, A, B, C)`. if `axis == 1` then the `output` tensor will have the shape `(A, N, B, C)`. Etc.
For example:
``` # 'x' is [1, 4] # 'y' is [2, 5] # 'z' is [3, 6] pack([x, y, z]) => [[1, 4], [2, 5], [3, 6]] # Pack along first dim. pack([x, y, z], axis=1) => [[1, 2, 3], [4, 5, 6]] ```
This is the opposite of `unpack`.
Arguments:
values: Must be of same shape and type.
Returns The packed tensor.
func Pad ¶ added in v1.1.0
Pads a tensor with zeros.
This operation pads a `input` with zeros according to the `paddings` you specify. `paddings` is an integer tensor with shape `[Dn, 2]`, where n is the rank of `input`. For each dimension D of `input`, `paddings[D, 0]` indicates how many zeros to add before the contents of `input` in that dimension, and `paddings[D, 1]` indicates how many zeros to add after the contents of `input` in that dimension.
The padded size of each dimension D of the output is:
`paddings(D, 0) + input.dim_size(D) + paddings(D, 1)`
For example:
``` # 't' is [[1, 1], [2, 2]] # 'paddings' is [[1, 1], [2, 2]] # rank of 't' is 2 pad(t, paddings) ==> [[0, 0, 0, 0, 0, 0]
[0, 0, 1, 1, 0, 0] [0, 0, 2, 2, 0, 0] [0, 0, 0, 0, 0, 0]]
```
func PadV2 ¶ added in v1.3.0
func PadV2(scope *Scope, input tf.Output, paddings tf.Output, constant_values tf.Output) (output tf.Output)
Pads a tensor.
This operation pads `input` according to the `paddings` and `constant_values` you specify. `paddings` is an integer tensor with shape `[Dn, 2]`, where n is the rank of `input`. For each dimension D of `input`, `paddings[D, 0]` indicates how many padding values to add before the contents of `input` in that dimension, and `paddings[D, 1]` indicates how many padding values to add after the contents of `input` in that dimension. `constant_values` is a scalar tensor of the same type as `input` that indicates the value to use for padding `input`.
The padded size of each dimension D of the output is:
`paddings(D, 0) + input.dim_size(D) + paddings(D, 1)`
For example:
``` # 't' is [[1, 1], [2, 2]] # 'paddings' is [[1, 1], [2, 2]] # 'constant_values' is 0 # rank of 't' is 2 pad(t, paddings) ==> [[0, 0, 0, 0, 0, 0]
[0, 0, 1, 1, 0, 0] [0, 0, 2, 2, 0, 0] [0, 0, 0, 0, 0, 0]]
```
func PaddedBatchDataset ¶ added in v1.2.0
func PaddedBatchDataset(scope *Scope, input_dataset tf.Output, batch_size tf.Output, padded_shapes []tf.Output, padding_values []tf.Output, output_shapes []tf.Shape) (handle tf.Output)
Creates a dataset that batches and pads `batch_size` elements from the input.
Arguments:
batch_size: A scalar representing the number of elements to accumulate in a
batch.
padded_shapes: A list of int64 tensors representing the desired padded shapes
of the corresponding output components. These shapes may be partially specified, using `-1` to indicate that a particular dimension should be padded to the maximum size of all batch elements.
padding_values: A list of scalars containing the padding value to use for
each of the outputs.
func PaddingFIFOQueueV2 ¶ added in v1.1.0
func PaddingFIFOQueueV2(scope *Scope, component_types []tf.DataType, optional ...PaddingFIFOQueueV2Attr) (handle tf.Output)
A queue that produces elements in first-in first-out order.
Variable-size shapes are allowed by setting the corresponding shape dimensions to 0 in the shape attr. In this case DequeueMany will pad up to the maximum size of any given element in the minibatch. See below for details.
Arguments:
component_types: The type of each component in a value.
Returns The handle to the queue.
func ParallelConcat ¶ added in v1.1.0
Concatenates a list of `N` tensors along the first dimension.
The input tensors are all required to have size 1 in the first dimension.
For example:
``` # 'x' is [[1, 4]] # 'y' is [[2, 5]] # 'z' is [[3, 6]] parallel_concat([x, y, z]) => [[1, 4], [2, 5], [3, 6]] # Pack along first dim. ```
The difference between concat and parallel_concat is that concat requires all of the inputs be computed before the operation will begin but doesn't require that the input shapes be known during graph construction. Parallel concat will copy pieces of the input into the output as they become available, in some situations this can provide a performance benefit.
Arguments:
values: Tensors to be concatenated. All must have size 1 in the first dimension
and same shape.
shape: the final shape of the result; should be equal to the shapes of any input
but with the number of input values in the first dimension.
Returns The concatenated tensor.
func ParallelDynamicStitch ¶ added in v1.4.0
Interleave the values from the `data` tensors into a single tensor.
Builds a merged tensor such that ¶
```python
merged[indices[m][i, ..., j], ...] = data[m][i, ..., j, ...]
```
For example, if each `indices[m]` is scalar or vector, we have
```python
# Scalar indices: merged[indices[m], ...] = data[m][...] # Vector indices: merged[indices[m][i], ...] = data[m][i, ...]
```
Each `data[i].shape` must start with the corresponding `indices[i].shape`, and the rest of `data[i].shape` must be constant w.r.t. `i`. That is, we must have `data[i].shape = indices[i].shape + constant`. In terms of this `constant`, the output shape is
merged.shape = [max(indices)] + constant
Values may be merged in parallel, so if an index appears in both `indices[m][i]` and `indices[n][j]`, the result may be invalid. This differs from the normal DynamicStitch operator that defines the behavior in that case.
For example:
```python
indices[0] = 6
indices[1] = [4, 1]
indices[2] = [[5, 2], [0, 3]]
data[0] = [61, 62]
data[1] = [[41, 42], [11, 12]]
data[2] = [[[51, 52], [21, 22]], [[1, 2], [31, 32]]]
merged = [[1, 2], [11, 12], [21, 22], [31, 32], [41, 42],
[51, 52], [61, 62]]
```
This method can be used to merge partitions created by `dynamic_partition` as illustrated on the following example:
```python
# Apply function (increments x_i) on elements for which a certain condition
# apply (x_i != -1 in this example).
x=tf.constant([0.1, -1., 5.2, 4.3, -1., 7.4])
condition_mask=tf.not_equal(x,tf.constant(-1.))
partitioned_data = tf.dynamic_partition(
x, tf.cast(condition_mask, tf.int32) , 2)
partitioned_data[1] = partitioned_data[1] + 1.0
condition_indices = tf.dynamic_partition(
tf.range(tf.shape(x)[0]), tf.cast(condition_mask, tf.int32) , 2)
x = tf.dynamic_stitch(condition_indices, partitioned_data)
# Here x=[1.1, -1., 6.2, 5.3, -1, 8.4], the -1. values remain
# unchanged.
```
<div style="width:70%; margin:auto; margin-bottom:10px; margin-top:20px;"> <img style="width:100%" src="https://www.tensorflow.org/images/DynamicStitch.png" alt> </div>
func ParameterizedTruncatedNormal ¶ added in v1.1.0
func ParameterizedTruncatedNormal(scope *Scope, shape tf.Output, means tf.Output, stdevs tf.Output, minvals tf.Output, maxvals tf.Output, optional ...ParameterizedTruncatedNormalAttr) (output tf.Output)
Outputs random values from a normal distribution. The parameters may each be a
scalar which applies to the entire output, or a vector of length shape[0] which stores the parameters for each batch.
Arguments:
shape: The shape of the output tensor. Batches are indexed by the 0th dimension. means: The mean parameter of each batch. stdevs: The standard deviation parameter of each batch. Must be greater than 0. minvals: The minimum cutoff. May be -infinity. maxvals: The maximum cutoff. May be +infinity, and must be more than the minval
for each batch.
Returns A matrix of shape num_batches x samples_per_batch, filled with random truncated normal values using the parameters for each row.
func ParseExample ¶ added in v1.1.0
func ParseExample(scope *Scope, serialized tf.Output, names tf.Output, sparse_keys []tf.Output, dense_keys []tf.Output, dense_defaults []tf.Output, sparse_types []tf.DataType, dense_shapes []tf.Shape) (sparse_indices []tf.Output, sparse_values []tf.Output, sparse_shapes []tf.Output, dense_values []tf.Output)
Transforms a vector of brain.Example protos (as strings) into typed tensors.
Arguments:
serialized: A vector containing a batch of binary serialized Example protos. names: A vector containing the names of the serialized protos.
May contain, for example, table key (descriptive) names for the corresponding serialized protos. These are purely useful for debugging purposes, and the presence of values here has no effect on the output. May also be an empty vector if no names are available. If non-empty, this vector must be the same length as "serialized".
sparse_keys: A list of Nsparse string Tensors (scalars).
The keys expected in the Examples' features associated with sparse values.
dense_keys: A list of Ndense string Tensors (scalars).
The keys expected in the Examples' features associated with dense values.
dense_defaults: A list of Ndense Tensors (some may be empty).
dense_defaults[j] provides default values when the example's feature_map lacks dense_key[j]. If an empty Tensor is provided for dense_defaults[j], then the Feature dense_keys[j] is required. The input type is inferred from dense_defaults[j], even when it's empty. If dense_defaults[j] is not empty, and dense_shapes[j] is fully defined, then the shape of dense_defaults[j] must match that of dense_shapes[j]. If dense_shapes[j] has an undefined major dimension (variable strides dense feature), dense_defaults[j] must contain a single element: the padding element.
sparse_types: A list of Nsparse types; the data types of data in each Feature
given in sparse_keys. Currently the ParseExample supports DT_FLOAT (FloatList), DT_INT64 (Int64List), and DT_STRING (BytesList).
dense_shapes: A list of Ndense shapes; the shapes of data in each Feature
given in dense_keys. The number of elements in the Feature corresponding to dense_key[j] must always equal dense_shapes[j].NumEntries(). If dense_shapes[j] == (D0, D1, ..., DN) then the shape of output Tensor dense_values[j] will be (|serialized|, D0, D1, ..., DN): The dense outputs are just the inputs row-stacked by batch. This works for dense_shapes[j] = (-1, D1, ..., DN). In this case the shape of the output Tensor dense_values[j] will be (|serialized|, M, D1, .., DN), where M is the maximum number of blocks of elements of length D1 * .... * DN, across all minibatch entries in the input. Any minibatch entry with less than M blocks of elements of length D1 * ... * DN will be padded with the corresponding default_value scalar element along the second dimension.
func ParseSingleExample ¶ added in v1.6.0
func ParseSingleExample(scope *Scope, serialized tf.Output, dense_defaults []tf.Output, num_sparse int64, sparse_keys []string, dense_keys []string, sparse_types []tf.DataType, dense_shapes []tf.Shape) (sparse_indices []tf.Output, sparse_values []tf.Output, sparse_shapes []tf.Output, dense_values []tf.Output)
Transforms a tf.Example proto (as a string) into typed tensors.
Arguments:
serialized: A vector containing a batch of binary serialized Example protos. dense_defaults: A list of Tensors (some may be empty), whose length matches
the length of `dense_keys`. dense_defaults[j] provides default values when the example's feature_map lacks dense_key[j]. If an empty Tensor is provided for dense_defaults[j], then the Feature dense_keys[j] is required. The input type is inferred from dense_defaults[j], even when it's empty. If dense_defaults[j] is not empty, and dense_shapes[j] is fully defined, then the shape of dense_defaults[j] must match that of dense_shapes[j]. If dense_shapes[j] has an undefined major dimension (variable strides dense feature), dense_defaults[j] must contain a single element: the padding element.
num_sparse: The number of sparse features to be parsed from the example. This
must match the lengths of `sparse_keys` and `sparse_types`.
sparse_keys: A list of `num_sparse` strings.
The keys expected in the Examples' features associated with sparse values.
dense_keys: The keys expected in the Examples' features associated with dense
values.
sparse_types: A list of `num_sparse` types; the data types of data in each
Feature given in sparse_keys. Currently the ParseSingleExample op supports DT_FLOAT (FloatList), DT_INT64 (Int64List), and DT_STRING (BytesList).
dense_shapes: The shapes of data in each Feature given in dense_keys.
The length of this list must match the length of `dense_keys`. The number of elements in the Feature corresponding to dense_key[j] must always equal dense_shapes[j].NumEntries(). If dense_shapes[j] == (D0, D1, ..., DN) then the shape of output Tensor dense_values[j] will be (D0, D1, ..., DN): In the case dense_shapes[j] = (-1, D1, ..., DN), the shape of the output Tensor dense_values[j] will be (M, D1, .., DN), where M is the number of blocks of elements of length D1 * .... * DN, in the input.
func ParseSingleSequenceExample ¶ added in v1.1.0
func ParseSingleSequenceExample(scope *Scope, serialized tf.Output, feature_list_dense_missing_assumed_empty tf.Output, context_sparse_keys []tf.Output, context_dense_keys []tf.Output, feature_list_sparse_keys []tf.Output, feature_list_dense_keys []tf.Output, context_dense_defaults []tf.Output, debug_name tf.Output, optional ...ParseSingleSequenceExampleAttr) (context_sparse_indices []tf.Output, context_sparse_values []tf.Output, context_sparse_shapes []tf.Output, context_dense_values []tf.Output, feature_list_sparse_indices []tf.Output, feature_list_sparse_values []tf.Output, feature_list_sparse_shapes []tf.Output, feature_list_dense_values []tf.Output)
Transforms a scalar brain.SequenceExample proto (as strings) into typed tensors.
Arguments:
serialized: A scalar containing a binary serialized SequenceExample proto. feature_list_dense_missing_assumed_empty: A vector listing the
FeatureList keys which may be missing from the SequenceExample. If the associated FeatureList is missing, it is treated as empty. By default, any FeatureList not listed in this vector must exist in the SequenceExample.
context_sparse_keys: A list of Ncontext_sparse string Tensors (scalars).
The keys expected in the Examples' features associated with context_sparse values.
context_dense_keys: A list of Ncontext_dense string Tensors (scalars).
The keys expected in the SequenceExamples' context features associated with dense values.
feature_list_sparse_keys: A list of Nfeature_list_sparse string Tensors
(scalars). The keys expected in the FeatureLists associated with sparse values.
feature_list_dense_keys: A list of Nfeature_list_dense string Tensors (scalars).
The keys expected in the SequenceExamples' feature_lists associated with lists of dense values.
context_dense_defaults: A list of Ncontext_dense Tensors (some may be empty).
context_dense_defaults[j] provides default values when the SequenceExample's context map lacks context_dense_key[j]. If an empty Tensor is provided for context_dense_defaults[j], then the Feature context_dense_keys[j] is required. The input type is inferred from context_dense_defaults[j], even when it's empty. If context_dense_defaults[j] is not empty, its shape must match context_dense_shapes[j].
debug_name: A scalar containing the name of the serialized proto.
May contain, for example, table key (descriptive) name for the corresponding serialized proto. This is purely useful for debugging purposes, and the presence of values here has no effect on the output. May also be an empty scalar if no name is available.
func ParseTensor ¶ added in v1.1.0
Transforms a serialized tensorflow.TensorProto proto into a Tensor.
Arguments:
serialized: A scalar string containing a serialized TensorProto proto. out_type: The type of the serialized tensor. The provided type must match the
type of the serialized tensor and no implicit conversion will take place.
Returns A Tensor of type `out_type`.
func Placeholder ¶ added in v1.1.0
A placeholder op for a value that will be fed into the computation.
N.B. This operation will fail with an error if it is executed. It is intended as a way to represent a value that will always be fed, and to provide attrs that enable the fed value to be checked at runtime.
Arguments:
dtype: The type of elements in the tensor.
Returns A placeholder tensor that must be replaced using the feed mechanism.
func PlaceholderV2 ¶ added in v1.1.0
A placeholder op for a value that will be fed into the computation.
DEPRECATED at GraphDef version 23: Placeholder now behaves the same as PlaceholderV2.
N.B. This operation will fail with an error if it is executed. It is intended as a way to represent a value that will always be fed, and to provide attrs that enable the fed value to be checked at runtime.
Arguments:
dtype: The type of elements in the tensor. shape: The shape of the tensor. The shape can be any partially-specified
shape. To be unconstrained, pass in a shape with unknown rank.
Returns A placeholder tensor that must be replaced using the feed mechanism.
func PlaceholderWithDefault ¶ added in v1.1.0
A placeholder op that passes through `input` when its output is not fed.
Arguments:
input: The default value to produce when `output` is not fed. shape: The (possibly partial) shape of the tensor.
Returns A placeholder tensor that defaults to `input` if it is not fed.
func Polygamma ¶ added in v1.1.0
Compute the polygamma function \\(\psi^{(n)}(x)\\).
The polygamma function is defined as:
\\(\psi^{(n)}(x) = \frac{d^n}{dx^n} \psi(x)\\)
where \\(\psi(x)\\) is the digamma function.
func PopulationCount ¶ added in v1.4.0
Computes element-wise population count (a.k.a. popcount, bitsum, bitcount).
For each entry in `x`, calculates the number of `1` (on) bits in the binary representation of that entry.
**NOTE**: It is more efficient to first `tf.bitcast` your tensors into `int32` or `int64` and perform the bitcount on the result, than to feed in 8- or 16-bit inputs and then aggregate the resulting counts.
func Pow ¶ added in v1.1.0
Computes the power of one value to another.
Given a tensor `x` and a tensor `y`, this operation computes \\(x^y\\) for corresponding elements in `x` and `y`. For example:
``` # tensor 'x' is [[2, 2]], [3, 3]] # tensor 'y' is [[8, 16], [2, 3]] tf.pow(x, y) ==> [[256, 65536], [9, 27]] ```
func PrefetchDataset ¶ added in v1.4.0
func PrefetchDataset(scope *Scope, input_dataset tf.Output, buffer_size tf.Output, output_types []tf.DataType, output_shapes []tf.Shape) (handle tf.Output)
Creates a dataset that asynchronously prefetches elements from `input_dataset`.
Arguments:
buffer_size: The maximum number of elements to buffer in an iterator over
this dataset.
func PreventGradient ¶ added in v1.1.0
func PreventGradient(scope *Scope, input tf.Output, optional ...PreventGradientAttr) (output tf.Output)
An identity op that triggers an error if a gradient is requested.
When executed in a graph, this op outputs its input tensor as-is.
When building ops to compute gradients, the TensorFlow gradient system will return an error when trying to lookup the gradient of this op, because no gradient must ever be registered for this function. This op exists to prevent subtle bugs from silently returning unimplemented gradients in some corner cases.
Arguments:
input: any tensor.
Returns the same input tensor.
func Print ¶ added in v1.1.0
func Print(scope *Scope, input tf.Output, data []tf.Output, optional ...PrintAttr) (output tf.Output)
Prints a list of tensors.
Passes `input` through to `output` and prints `data` when evaluating.
Arguments:
input: The tensor passed to `output` data: A list of tensors to print out when op is evaluated.
Returns = The unmodified `input` tensor
func PriorityQueueV2 ¶ added in v1.1.0
func PriorityQueueV2(scope *Scope, shapes []tf.Shape, optional ...PriorityQueueV2Attr) (handle tf.Output)
A queue that produces elements sorted by the first component value.
Note that the PriorityQueue requires the first component of any element to be a scalar int64, in addition to the other elements declared by component_types. Therefore calls to Enqueue and EnqueueMany (resp. Dequeue and DequeueMany) on a PriorityQueue will all require (resp. output) one extra entry in their input (resp. output) lists.
Arguments:
shapes: The shape of each component in a value. The length of this attr must
be either 0 or the same as the length of component_types. If the length of this attr is 0, the shapes of queue elements are not constrained, and only one element may be dequeued at a time.
Returns The handle to the queue.
func Prod ¶ added in v1.1.0
Computes the product of elements across dimensions of a tensor.
Reduces `input` along the dimensions given in `axis`. Unless `keep_dims` is true, the rank of the tensor is reduced by 1 for each entry in `axis`. If `keep_dims` is true, the reduced dimensions are retained with length 1.
Arguments:
input: The tensor to reduce. axis: The dimensions to reduce. Must be in the range
`[-rank(input), rank(input))`.
Returns The reduced tensor.
func Qr ¶ added in v1.1.0
Computes the QR decompositions of one or more matrices.
Computes the QR decomposition of each inner matrix in `tensor` such that `tensor[..., :, :] = q[..., :, :] * r[..., :,:])`
```python # a is a tensor. # q is a tensor of orthonormal matrices. # r is a tensor of upper triangular matrices. q, r = qr(a) q_full, r_full = qr(a, full_matrices=True) ```
Arguments:
input: A tensor of shape `[..., M, N]` whose inner-most 2 dimensions
form matrices of size `[M, N]`. Let `P` be the minimum of `M` and `N`.
Returns Orthonormal basis for range of `a`. If `full_matrices` is `False` then shape is `[..., M, P]`; if `full_matrices` is `True` then shape is `[..., M, M]`.Triangular factor. If `full_matrices` is `False` then shape is `[..., P, N]`. If `full_matrices` is `True` then shape is `[..., M, N]`.
func QuantizeAndDequantize ¶ added in v1.1.0
func QuantizeAndDequantize(scope *Scope, input tf.Output, optional ...QuantizeAndDequantizeAttr) (output tf.Output)
Use QuantizeAndDequantizeV2 instead.
DEPRECATED at GraphDef version 22: Replaced by QuantizeAndDequantizeV2
func QuantizeAndDequantizeV2 ¶ added in v1.1.0
func QuantizeAndDequantizeV2(scope *Scope, input tf.Output, input_min tf.Output, input_max tf.Output, optional ...QuantizeAndDequantizeV2Attr) (output tf.Output)
Quantizes then dequantizes a tensor.
This op simulates the precision loss from the quantized forward pass by:
- Quantizing the tensor to fixed point numbers, which should match the target quantization method when it is used in inference.
- Dequantizing it back to floating point numbers for the following ops, most likely matmul.
There are different ways to quantize. This version does not use the full range of the output type, choosing to elide the lowest possible value for symmetry (e.g., output range is -127 to 127, not -128 to 127 for signed 8 bit quantization), so that 0.0 maps to 0.
To perform this op, we first find the range of values in our tensor. The range we use is always centered on 0, so we find m such that
1. m = max(abs(input_min), abs(input_max)) if range_given is true, 2. m = max(abs(min_elem(input)), abs(max_elem(input))) otherwise.
Our input tensor range is then [-m, m].
Next, we choose our fixed-point quantization buckets, [min_fixed, max_fixed]. If signed_input is true, this is
[min_fixed, max_fixed ] =
[-(1 << (num_bits - 1) - 1), (1 << (num_bits - 1)) - 1].
Otherwise, if signed_input is false, the fixed-point range is
[min_fixed, max_fixed] = [0, (1 << num_bits) - 1].
From this we compute our scaling factor, s:
s = (max_fixed - min_fixed) / (2 * m).
Now we can quantize and dequantize the elements of our tensor. An element e is transformed into e':
e' = (e * s).round_to_nearest() / s.
Note that we have a different number of buckets in the signed vs. unsigned cases. For example, if num_bits == 8, we get 254 buckets in the signed case vs. 255 in the unsigned case.
For example, suppose num_bits = 8 and m = 1. Then
[min_fixed, max_fixed] = [-127, 127], and s = (127 + 127) / 2 = 127.
Given the vector {-1, -0.5, 0, 0.3}, this is quantized to {-127, -63, 0, 38}, and dequantized to {-1, -63.0/127, 0, 38.0/127}.
Arguments:
input: Tensor to quantize and then dequantize. input_min: If range_given, this is the min of the range, otherwise this input
will be ignored.
input_max: If range_given, this is the max of the range, otherwise this input
will be ignored.
func QuantizeAndDequantizeV3 ¶ added in v1.3.0
func QuantizeAndDequantizeV3(scope *Scope, input tf.Output, input_min tf.Output, input_max tf.Output, num_bits tf.Output, optional ...QuantizeAndDequantizeV3Attr) (output tf.Output)
Quantizes then dequantizes a tensor.
This is almost identical to QuantizeAndDequantizeV2, except that num_bits is a tensor, so its value can change during training.
func QuantizeDownAndShrinkRange ¶ added in v1.1.0
func QuantizeDownAndShrinkRange(scope *Scope, input tf.Output, input_min tf.Output, input_max tf.Output, out_type tf.DataType) (output tf.Output, output_min tf.Output, output_max tf.Output)
Convert the quantized 'input' tensor into a lower-precision 'output', using the
actual distribution of the values to maximize the usage of the lower bit depth and adjusting the output min and max ranges accordingly.
[input_min, input_max] are scalar floats that specify the range for the float interpretation of the 'input' data. For example, if input_min is -1.0f and input_max is 1.0f, and we are dealing with quint16 quantized data, then a 0 value in the 16-bit data should be interpreted as -1.0f, and a 65535 means 1.0f.
This operator tries to squeeze as much precision as possible into an output with a lower bit depth by calculating the actual min and max values found in the data. For example, maybe that quint16 input has no values lower than 16,384 and none higher than 49,152. That means only half the range is actually needed, all the float interpretations are between -0.5f and 0.5f, so if we want to compress the data into a quint8 output, we can use that range rather than the theoretical -1.0f to 1.0f that is suggested by the input min and max.
In practice, this is most useful for taking output from operations like QuantizedMatMul that can produce higher bit-depth outputs than their inputs and may have large potential output ranges, but in practice have a distribution of input values that only uses a small fraction of the possible range. By feeding that output into this operator, we can reduce it from 32 bits down to 8 with minimal loss of accuracy.
Arguments:
input_min: The float value that the minimum quantized input value represents. input_max: The float value that the maximum quantized input value represents. out_type: The type of the output. Should be a lower bit depth than Tinput.
Returns The float value that the minimum quantized output value represents.The float value that the maximum quantized output value represents.
func QuantizeV2 ¶ added in v1.1.0
func QuantizeV2(scope *Scope, input tf.Output, min_range tf.Output, max_range tf.Output, T tf.DataType, optional ...QuantizeV2Attr) (output tf.Output, output_min tf.Output, output_max tf.Output)
Quantize the 'input' tensor of type float to 'output' tensor of type 'T'.
[min_range, max_range] are scalar floats that specify the range for the 'input' data. The 'mode' attribute controls exactly which calculations are used to convert the float values to their quantized equivalents. The 'round_mode' attribute controls which rounding tie-breaking algorithm is used when rounding float values to their quantized equivalents.
In 'MIN_COMBINED' mode, each value of the tensor will undergo the following:
``` out[i] = (in[i] - min_range) * range(T) / (max_range - min_range) if T == qint8, out[i] -= (range(T) + 1) / 2.0 ``` here `range(T) = numeric_limits<T>::max() - numeric_limits<T>::min()`
*MIN_COMBINED Mode Example*
Assume the input is type float and has a possible range of [0.0, 6.0] and the output type is quint8 ([0, 255]). The min_range and max_range values should be specified as 0.0 and 6.0. Quantizing from float to quint8 will multiply each value of the input by 255/6 and cast to quint8.
If the output type was qint8 ([-128, 127]), the operation will additionally subtract each value by 128 prior to casting, so that the range of values aligns with the range of qint8.
If the mode is 'MIN_FIRST', then this approach is used:
``` num_discrete_values = 1 << (# of bits in T) range_adjust = num_discrete_values / (num_discrete_values - 1) range = (range_max - range_min) * range_adjust range_scale = num_discrete_values / range quantized = round(input * range_scale) - round(range_min * range_scale) +
numeric_limits<T>::min()
quantized = max(quantized, numeric_limits<T>::min()) quantized = min(quantized, numeric_limits<T>::max()) ```
The biggest difference between this and MIN_COMBINED is that the minimum range is rounded first, before it's subtracted from the rounded value. With MIN_COMBINED, a small bias is introduced where repeated iterations of quantizing and dequantizing will introduce a larger and larger error.
*SCALED mode Example*
`SCALED` mode matches the quantization approach used in `QuantizeAndDequantize{V2|V3}`.
If the mode is `SCALED`, we do not use the full range of the output type, choosing to elide the lowest possible value for symmetry (e.g., output range is -127 to 127, not -128 to 127 for signed 8 bit quantization), so that 0.0 maps to 0.
We first find the range of values in our tensor. The range we use is always centered on 0, so we find m such that ```c++
m = max(abs(input_min), abs(input_max))
```
Our input tensor range is then `[-m, m]`.
Next, we choose our fixed-point quantization buckets, `[min_fixed, max_fixed]`. If T is signed, this is ```
num_bits = sizeof(T) * 8
[min_fixed, max_fixed] =
[-(1 << (num_bits - 1) - 1), (1 << (num_bits - 1)) - 1]
```
Otherwise, if T is unsigned, the fixed-point range is ```
[min_fixed, max_fixed] = [0, (1 << num_bits) - 1]
```
From this we compute our scaling factor, s: ```c++
s = (max_fixed - min_fixed) / (2 * m)
```
Now we can quantize the elements of our tensor: ```c++ result = round(input * s) ```
One thing to watch out for is that the operator may choose to adjust the requested minimum and maximum values slightly during the quantization process, so you should always use the output ports as the range for further calculations. For example, if the requested minimum and maximum values are close to equal, they will be separated by a small epsilon value to prevent ill-formed quantized buffers from being created. Otherwise, you can end up with buffers where all the quantized values map to the same float value, which causes problems for operations that have to perform further calculations on them.
Arguments:
min_range: The minimum scalar value possibly produced for the input. max_range: The maximum scalar value possibly produced for the input.
Returns The quantized data produced from the float input.The actual minimum scalar value used for the output.The actual maximum scalar value used for the output.
func QuantizedAdd ¶ added in v1.3.0
func QuantizedAdd(scope *Scope, x tf.Output, y tf.Output, min_x tf.Output, max_x tf.Output, min_y tf.Output, max_y tf.Output, optional ...QuantizedAddAttr) (z tf.Output, min_z tf.Output, max_z tf.Output)
Returns x + y element-wise, working on quantized buffers.
Arguments:
min_x: The float value that the lowest quantized `x` value represents. max_x: The float value that the highest quantized `x` value represents. min_y: The float value that the lowest quantized `y` value represents. max_y: The float value that the highest quantized `y` value represents.
Returns The float value that the lowest quantized output value represents.The float value that the highest quantized output value represents.
*NOTE*: `QuantizedAdd` supports limited forms of broadcasting. More about broadcasting [here](http://docs.scipy.org/doc/numpy/user/basics.broadcasting.html)
func QuantizedAvgPool ¶ added in v1.1.0
func QuantizedAvgPool(scope *Scope, input tf.Output, min_input tf.Output, max_input tf.Output, ksize []int64, strides []int64, padding string) (output tf.Output, min_output tf.Output, max_output tf.Output)
Produces the average pool of the input tensor for quantized types.
Arguments:
input: 4-D with shape `[batch, height, width, channels]`. min_input: The float value that the lowest quantized input value represents. max_input: The float value that the highest quantized input value represents. ksize: The size of the window for each dimension of the input tensor.
The length must be 4 to match the number of dimensions of the input.
strides: The stride of the sliding window for each dimension of the input
tensor. The length must be 4 to match the number of dimensions of the input.
padding: The type of padding algorithm to use.
Returns The float value that the lowest quantized output value represents.The float value that the highest quantized output value represents.
func QuantizedBatchNormWithGlobalNormalization ¶ added in v1.1.0
func QuantizedBatchNormWithGlobalNormalization(scope *Scope, t tf.Output, t_min tf.Output, t_max tf.Output, m tf.Output, m_min tf.Output, m_max tf.Output, v tf.Output, v_min tf.Output, v_max tf.Output, beta tf.Output, beta_min tf.Output, beta_max tf.Output, gamma tf.Output, gamma_min tf.Output, gamma_max tf.Output, out_type tf.DataType, variance_epsilon float32, scale_after_normalization bool) (result tf.Output, result_min tf.Output, result_max tf.Output)
Quantized Batch normalization.
This op is deprecated and will be removed in the future. Prefer `tf.nn.batch_normalization`.
Arguments:
t: A 4D input Tensor. t_min: The value represented by the lowest quantized input. t_max: The value represented by the highest quantized input. m: A 1D mean Tensor with size matching the last dimension of t.
This is the first output from tf.nn.moments, or a saved moving average thereof.
m_min: The value represented by the lowest quantized mean. m_max: The value represented by the highest quantized mean. v: A 1D variance Tensor with size matching the last dimension of t.
This is the second output from tf.nn.moments, or a saved moving average thereof.
v_min: The value represented by the lowest quantized variance. v_max: The value represented by the highest quantized variance. beta: A 1D beta Tensor with size matching the last dimension of t.
An offset to be added to the normalized tensor.
beta_min: The value represented by the lowest quantized offset. beta_max: The value represented by the highest quantized offset. gamma: A 1D gamma Tensor with size matching the last dimension of t.
If "scale_after_normalization" is true, this tensor will be multiplied with the normalized tensor.
gamma_min: The value represented by the lowest quantized gamma. gamma_max: The value represented by the highest quantized gamma. variance_epsilon: A small float number to avoid dividing by 0. scale_after_normalization: A bool indicating whether the resulted tensor
needs to be multiplied with gamma.
func QuantizedBiasAdd ¶ added in v1.1.0
func QuantizedBiasAdd(scope *Scope, input tf.Output, bias tf.Output, min_input tf.Output, max_input tf.Output, min_bias tf.Output, max_bias tf.Output, out_type tf.DataType) (output tf.Output, min_out tf.Output, max_out tf.Output)
Adds Tensor 'bias' to Tensor 'input' for Quantized types.
Broadcasts the values of bias on dimensions 0..N-2 of 'input'.
Arguments:
bias: A 1D bias Tensor with size matching the last dimension of 'input'. min_input: The float value that the lowest quantized input value represents. max_input: The float value that the highest quantized input value represents. min_bias: The float value that the lowest quantized bias value represents. max_bias: The float value that the highest quantized bias value represents.
Returns The float value that the lowest quantized output value represents.The float value that the highest quantized output value represents.
func QuantizedConcat ¶ added in v1.1.0
func QuantizedConcat(scope *Scope, concat_dim tf.Output, values []tf.Output, input_mins []tf.Output, input_maxes []tf.Output) (output tf.Output, output_min tf.Output, output_max tf.Output)
Concatenates quantized tensors along one dimension.
Arguments:
concat_dim: 0-D. The dimension along which to concatenate. Must be in the
range [0, rank(values)).
values: The `N` Tensors to concatenate. Their ranks and types must match,
and their sizes must match in all dimensions except `concat_dim`.
input_mins: The minimum scalar values for each of the input tensors. input_maxes: The maximum scalar values for each of the input tensors.
Returns A `Tensor` with the concatenation of values stacked along the `concat_dim` dimension. This tensor's shape matches that of `values` except in `concat_dim` where it has the sum of the sizes.The float value that the minimum quantized output value represents.The float value that the maximum quantized output value represents.
func QuantizedConv2D ¶ added in v1.1.0
func QuantizedConv2D(scope *Scope, input tf.Output, filter tf.Output, min_input tf.Output, max_input tf.Output, min_filter tf.Output, max_filter tf.Output, strides []int64, padding string, optional ...QuantizedConv2DAttr) (output tf.Output, min_output tf.Output, max_output tf.Output)
Computes a 2D convolution given quantized 4D input and filter tensors.
The inputs are quantized tensors where the lowest value represents the real number of the associated minimum, and the highest represents the maximum. This means that you can only interpret the quantized output in the same way, by taking the returned minimum and maximum values into account.
Arguments:
filter: filter's input_depth dimension must match input's depth dimensions. min_input: The float value that the lowest quantized input value represents. max_input: The float value that the highest quantized input value represents. min_filter: The float value that the lowest quantized filter value represents. max_filter: The float value that the highest quantized filter value represents. strides: The stride of the sliding window for each dimension of the input
tensor.
padding: The type of padding algorithm to use.
Returns The float value that the lowest quantized output value represents.The float value that the highest quantized output value represents.
func QuantizedInstanceNorm ¶ added in v1.1.0
func QuantizedInstanceNorm(scope *Scope, x tf.Output, x_min tf.Output, x_max tf.Output, optional ...QuantizedInstanceNormAttr) (y tf.Output, y_min tf.Output, y_max tf.Output)
Quantized Instance normalization.
Arguments:
x: A 4D input Tensor. x_min: The value represented by the lowest quantized input. x_max: The value represented by the highest quantized input.
Returns A 4D Tensor.The value represented by the lowest quantized output.The value represented by the highest quantized output.
func QuantizedMatMul ¶ added in v1.1.0
func QuantizedMatMul(scope *Scope, a tf.Output, b tf.Output, min_a tf.Output, max_a tf.Output, min_b tf.Output, max_b tf.Output, optional ...QuantizedMatMulAttr) (out tf.Output, min_out tf.Output, max_out tf.Output)
Perform a quantized matrix multiplication of `a` by the matrix `b`.
The inputs must be two-dimensional matrices and the inner dimension of `a` (after being transposed if `transpose_a` is non-zero) must match the outer dimension of `b` (after being transposed if `transposed_b` is non-zero).
Arguments:
a: Must be a two-dimensional tensor. b: Must be a two-dimensional tensor. min_a: The float value that the lowest quantized `a` value represents. max_a: The float value that the highest quantized `a` value represents. min_b: The float value that the lowest quantized `b` value represents. max_b: The float value that the highest quantized `b` value represents.
Returns The float value that the lowest quantized output value represents.The float value that the highest quantized output value represents.
func QuantizedMaxPool ¶ added in v1.1.0
func QuantizedMaxPool(scope *Scope, input tf.Output, min_input tf.Output, max_input tf.Output, ksize []int64, strides []int64, padding string) (output tf.Output, min_output tf.Output, max_output tf.Output)
Produces the max pool of the input tensor for quantized types.
Arguments:
input: The 4D (batch x rows x cols x depth) Tensor to MaxReduce over. min_input: The float value that the lowest quantized input value represents. max_input: The float value that the highest quantized input value represents. ksize: The size of the window for each dimension of the input tensor.
The length must be 4 to match the number of dimensions of the input.
strides: The stride of the sliding window for each dimension of the input
tensor. The length must be 4 to match the number of dimensions of the input.
padding: The type of padding algorithm to use.
Returns The float value that the lowest quantized output value represents.The float value that the highest quantized output value represents.
func QuantizedMul ¶ added in v1.1.0
func QuantizedMul(scope *Scope, x tf.Output, y tf.Output, min_x tf.Output, max_x tf.Output, min_y tf.Output, max_y tf.Output, optional ...QuantizedMulAttr) (z tf.Output, min_z tf.Output, max_z tf.Output)
Returns x * y element-wise, working on quantized buffers.
Arguments:
min_x: The float value that the lowest quantized `x` value represents. max_x: The float value that the highest quantized `x` value represents. min_y: The float value that the lowest quantized `y` value represents. max_y: The float value that the highest quantized `y` value represents.
Returns The float value that the lowest quantized output value represents.The float value that the highest quantized output value represents.
*NOTE*: `QuantizedMul` supports limited forms of broadcasting. More about broadcasting [here](http://docs.scipy.org/doc/numpy/user/basics.broadcasting.html)
func QuantizedRelu ¶ added in v1.1.0
func QuantizedRelu(scope *Scope, features tf.Output, min_features tf.Output, max_features tf.Output, optional ...QuantizedReluAttr) (activations tf.Output, min_activations tf.Output, max_activations tf.Output)
Computes Quantized Rectified Linear: `max(features, 0)`
Arguments:
min_features: The float value that the lowest quantized value represents. max_features: The float value that the highest quantized value represents.
Returns Has the same output shape as "features".The float value that the lowest quantized value represents.The float value that the highest quantized value represents.
func QuantizedRelu6 ¶ added in v1.1.0
func QuantizedRelu6(scope *Scope, features tf.Output, min_features tf.Output, max_features tf.Output, optional ...QuantizedRelu6Attr) (activations tf.Output, min_activations tf.Output, max_activations tf.Output)
Computes Quantized Rectified Linear 6: `min(max(features, 0), 6)`
Arguments:
min_features: The float value that the lowest quantized value represents. max_features: The float value that the highest quantized value represents.
Returns Has the same output shape as "features".The float value that the lowest quantized value represents.The float value that the highest quantized value represents.
func QuantizedReluX ¶ added in v1.1.0
func QuantizedReluX(scope *Scope, features tf.Output, max_value tf.Output, min_features tf.Output, max_features tf.Output, optional ...QuantizedReluXAttr) (activations tf.Output, min_activations tf.Output, max_activations tf.Output)
Computes Quantized Rectified Linear X: `min(max(features, 0), max_value)`
Arguments:
min_features: The float value that the lowest quantized value represents. max_features: The float value that the highest quantized value represents.
Returns Has the same output shape as "features".The float value that the lowest quantized value represents.The float value that the highest quantized value represents.
func QuantizedReshape ¶ added in v1.1.0
func QuantizedReshape(scope *Scope, tensor tf.Output, shape tf.Output, input_min tf.Output, input_max tf.Output) (output tf.Output, output_min tf.Output, output_max tf.Output)
Reshapes a quantized tensor as per the Reshape op.
```
Arguments:
shape: Defines the shape of the output tensor. input_min: The minimum value of the input. input_max: The maximum value of the input.
Returns This value is copied from input_min.This value is copied from input_max.
func QuantizedResizeBilinear ¶ added in v1.3.0
func QuantizedResizeBilinear(scope *Scope, images tf.Output, size tf.Output, min tf.Output, max tf.Output, optional ...QuantizedResizeBilinearAttr) (resized_images tf.Output, out_min tf.Output, out_max tf.Output)
Resize quantized `images` to `size` using quantized bilinear interpolation.
Input images and output images must be quantized types.
Arguments:
images: 4-D with shape `[batch, height, width, channels]`. size: = A 1-D int32 Tensor of 2 elements: `new_height, new_width`. The
new size for the images.
Returns 4-D with shape `[batch, new_height, new_width, channels]`.
func QueueCloseV2 ¶ added in v1.1.0
Closes the given queue.
This operation signals that no more elements will be enqueued in the given queue. Subsequent Enqueue(Many) operations will fail. Subsequent Dequeue(Many) operations will continue to succeed if sufficient elements remain in the queue. Subsequent Dequeue(Many) operations that would block will fail immediately.
Arguments:
handle: The handle to a queue.
Returns the created operation.
func QueueDequeueManyV2 ¶ added in v1.1.0
func QueueDequeueManyV2(scope *Scope, handle tf.Output, n tf.Output, component_types []tf.DataType, optional ...QueueDequeueManyV2Attr) (components []tf.Output)
Dequeues `n` tuples of one or more tensors from the given queue.
If the queue is closed and there are fewer than `n` elements, then an OutOfRange error is returned.
This operation concatenates queue-element component tensors along the 0th dimension to make a single component tensor. All of the components in the dequeued tuple will have size `n` in the 0th dimension.
This operation has `k` outputs, where `k` is the number of components in the tuples stored in the given queue, and output `i` is the ith component of the dequeued tuple.
N.B. If the queue is empty, this operation will block until `n` elements have been dequeued (or 'timeout_ms' elapses, if specified).
Arguments:
handle: The handle to a queue. n: The number of tuples to dequeue. component_types: The type of each component in a tuple.
Returns One or more tensors that were dequeued as a tuple.
func QueueDequeueUpToV2 ¶ added in v1.1.0
func QueueDequeueUpToV2(scope *Scope, handle tf.Output, n tf.Output, component_types []tf.DataType, optional ...QueueDequeueUpToV2Attr) (components []tf.Output)
Dequeues `n` tuples of one or more tensors from the given queue.
This operation is not supported by all queues. If a queue does not support DequeueUpTo, then an Unimplemented error is returned.
If the queue is closed and there are more than 0 but less than `n` elements remaining, then instead of returning an OutOfRange error like QueueDequeueMany, less than `n` elements are returned immediately. If the queue is closed and there are 0 elements left in the queue, then an OutOfRange error is returned just like in QueueDequeueMany. Otherwise the behavior is identical to QueueDequeueMany:
This operation concatenates queue-element component tensors along the 0th dimension to make a single component tensor. All of the components in the dequeued tuple will have size n in the 0th dimension.
This operation has `k` outputs, where `k` is the number of components in the tuples stored in the given queue, and output `i` is the ith component of the dequeued tuple.
Arguments:
handle: The handle to a queue. n: The number of tuples to dequeue. component_types: The type of each component in a tuple.
Returns One or more tensors that were dequeued as a tuple.
func QueueDequeueV2 ¶ added in v1.1.0
func QueueDequeueV2(scope *Scope, handle tf.Output, component_types []tf.DataType, optional ...QueueDequeueV2Attr) (components []tf.Output)
Dequeues a tuple of one or more tensors from the given queue.
This operation has k outputs, where k is the number of components in the tuples stored in the given queue, and output i is the ith component of the dequeued tuple.
N.B. If the queue is empty, this operation will block until an element has been dequeued (or 'timeout_ms' elapses, if specified).
Arguments:
handle: The handle to a queue. component_types: The type of each component in a tuple.
Returns One or more tensors that were dequeued as a tuple.
func QueueEnqueueManyV2 ¶ added in v1.1.0
func QueueEnqueueManyV2(scope *Scope, handle tf.Output, components []tf.Output, optional ...QueueEnqueueManyV2Attr) (o *tf.Operation)
Enqueues zero or more tuples of one or more tensors in the given queue.
This operation slices each component tensor along the 0th dimension to make multiple queue elements. All of the tuple components must have the same size in the 0th dimension.
The components input has k elements, which correspond to the components of tuples stored in the given queue.
N.B. If the queue is full, this operation will block until the given elements have been enqueued (or 'timeout_ms' elapses, if specified).
Arguments:
handle: The handle to a queue. components: One or more tensors from which the enqueued tensors should
be taken.
Returns the created operation.
func QueueEnqueueV2 ¶ added in v1.1.0
func QueueEnqueueV2(scope *Scope, handle tf.Output, components []tf.Output, optional ...QueueEnqueueV2Attr) (o *tf.Operation)
Enqueues a tuple of one or more tensors in the given queue.
The components input has k elements, which correspond to the components of tuples stored in the given queue.
N.B. If the queue is full, this operation will block until the given element has been enqueued (or 'timeout_ms' elapses, if specified).
Arguments:
handle: The handle to a queue. components: One or more tensors from which the enqueued tensors should be taken.
Returns the created operation.
func QueueIsClosedV2 ¶ added in v1.3.0
Returns true if queue is closed.
This operation returns true if the queue is closed and false if the queue is open.
Arguments:
handle: The handle to a queue.
func QueueSizeV2 ¶ added in v1.1.0
Computes the number of elements in the given queue.
Arguments:
handle: The handle to a queue.
Returns The number of elements in the given queue.
func RFFT ¶ added in v1.1.0
Real-valued fast Fourier transform.
Computes the 1-dimensional discrete Fourier transform of a real-valued signal over the inner-most dimension of `input`.
Since the DFT of a real signal is Hermitian-symmetric, `RFFT` only returns the `fft_length / 2 + 1` unique components of the FFT: the zero-frequency term, followed by the `fft_length / 2` positive-frequency terms.
Along the axis `RFFT` is computed on, if `fft_length` is smaller than the corresponding dimension of `input`, the dimension is cropped. If it is larger, the dimension is padded with zeros.
Arguments:
input: A float32 tensor. fft_length: An int32 tensor of shape [1]. The FFT length.
Returns A complex64 tensor of the same rank as `input`. The inner-most
dimension of `input` is replaced with the `fft_length / 2 + 1` unique frequency components of its 1D Fourier transform.
@compatibility(numpy) Equivalent to np.fft.rfft @end_compatibility
func RFFT2D ¶ added in v1.1.0
2D real-valued fast Fourier transform.
Computes the 2-dimensional discrete Fourier transform of a real-valued signal over the inner-most 2 dimensions of `input`.
Since the DFT of a real signal is Hermitian-symmetric, `RFFT2D` only returns the `fft_length / 2 + 1` unique components of the FFT for the inner-most dimension of `output`: the zero-frequency term, followed by the `fft_length / 2` positive-frequency terms.
Along each axis `RFFT2D` is computed on, if `fft_length` is smaller than the corresponding dimension of `input`, the dimension is cropped. If it is larger, the dimension is padded with zeros.
Arguments:
input: A float32 tensor. fft_length: An int32 tensor of shape [2]. The FFT length for each dimension.
Returns A complex64 tensor of the same rank as `input`. The inner-most 2
dimensions of `input` are replaced with their 2D Fourier transform. The inner-most dimension contains `fft_length / 2 + 1` unique frequency components.
@compatibility(numpy) Equivalent to np.fft.rfft2 @end_compatibility
func RFFT3D ¶ added in v1.1.0
3D real-valued fast Fourier transform.
Computes the 3-dimensional discrete Fourier transform of a real-valued signal over the inner-most 3 dimensions of `input`.
Since the DFT of a real signal is Hermitian-symmetric, `RFFT3D` only returns the `fft_length / 2 + 1` unique components of the FFT for the inner-most dimension of `output`: the zero-frequency term, followed by the `fft_length / 2` positive-frequency terms.
Along each axis `RFFT3D` is computed on, if `fft_length` is smaller than the corresponding dimension of `input`, the dimension is cropped. If it is larger, the dimension is padded with zeros.
Arguments:
input: A float32 tensor. fft_length: An int32 tensor of shape [3]. The FFT length for each dimension.
Returns A complex64 tensor of the same rank as `input`. The inner-most 3
dimensions of `input` are replaced with the their 3D Fourier transform. The inner-most dimension contains `fft_length / 2 + 1` unique frequency components.
@compatibility(numpy) Equivalent to np.fft.rfftn with 3 dimensions. @end_compatibility
func RGBToHSV ¶ added in v1.1.0
Converts one or more images from RGB to HSV.
Outputs a tensor of the same shape as the `images` tensor, containing the HSV value of the pixels. The output is only well defined if the value in `images` are in `[0,1]`.
`output[..., 0]` contains hue, `output[..., 1]` contains saturation, and `output[..., 2]` contains value. All HSV values are in `[0,1]`. A hue of 0 corresponds to pure red, hue 1/3 is pure green, and 2/3 is pure blue.
Arguments:
images: 1-D or higher rank. RGB data to convert. Last dimension must be size 3.
Returns `images` converted to HSV.
func RandomCrop ¶ added in v1.1.0
func RandomCrop(scope *Scope, image tf.Output, size tf.Output, optional ...RandomCropAttr) (output tf.Output)
Randomly crop `image`.
DEPRECATED at GraphDef version 8: Random crop is now pure Python
`size` is a 1-D int64 tensor with 2 elements representing the crop height and width. The values must be non negative.
This Op picks a random location in `image` and crops a `height` by `width` rectangle from that location. The random location is picked so the cropped area will fit inside the original image.
Arguments:
image: 3-D of shape `[height, width, channels]`. size: 1-D of length 2 containing: `crop_height`, `crop_width`..
Returns 3-D of shape `[crop_height, crop_width, channels].`
func RandomDataset ¶ added in v1.6.0
func RandomDataset(scope *Scope, seed tf.Output, seed2 tf.Output, output_types []tf.DataType, output_shapes []tf.Shape) (handle tf.Output)
Creates a Dataset that returns pseudorandom numbers.
Arguments:
seed: A scalar seed for the random number generator. If either seed or
seed2 is set to be non-zero, the random number generator is seeded by the given seed. Otherwise, a random seed is used.
seed2: A second scalar seed to avoid seed collision.
func RandomGamma ¶ added in v1.1.0
func RandomGamma(scope *Scope, shape tf.Output, alpha tf.Output, optional ...RandomGammaAttr) (output tf.Output)
Outputs random values from the Gamma distribution(s) described by alpha.
This op uses the algorithm by Marsaglia et al. to acquire samples via transformation-rejection from pairs of uniform and normal random variables. See http://dl.acm.org/citation.cfm?id=358414
Arguments:
shape: 1-D integer tensor. Shape of independent samples to draw from each
distribution described by the shape parameters given in alpha.
alpha: A tensor in which each scalar is a "shape" parameter describing the
associated gamma distribution.
Returns A tensor with shape `shape + shape(alpha)`. Each slice `[:, ..., :, i0, i1, ...iN]` contains the samples drawn for `alpha[i0, i1, ...iN]`. The dtype of the output matches the dtype of alpha.
func RandomPoisson ¶ added in v1.1.0
func RandomPoisson(scope *Scope, shape tf.Output, rate tf.Output, optional ...RandomPoissonAttr) (output tf.Output)
Use RandomPoissonV2 instead.
DEPRECATED at GraphDef version 25: Replaced by RandomPoissonV2
func RandomPoissonV2 ¶ added in v1.4.0
func RandomPoissonV2(scope *Scope, shape tf.Output, rate tf.Output, optional ...RandomPoissonV2Attr) (output tf.Output)
Outputs random values from the Poisson distribution(s) described by rate.
This op uses two algorithms, depending on rate. If rate >= 10, then the algorithm by Hormann is used to acquire samples via transformation-rejection. See http://www.sciencedirect.com/science/article/pii/0167668793909974.
Otherwise, Knuth's algorithm is used to acquire samples via multiplying uniform random variables. See Donald E. Knuth (1969). Seminumerical Algorithms. The Art of Computer Programming, Volume 2. Addison Wesley
Arguments:
shape: 1-D integer tensor. Shape of independent samples to draw from each
distribution described by the shape parameters given in rate.
rate: A tensor in which each scalar is a "rate" parameter describing the
associated poisson distribution.
Returns A tensor with shape `shape + shape(rate)`. Each slice `[:, ..., :, i0, i1, ...iN]` contains the samples drawn for `rate[i0, i1, ...iN]`.
func RandomShuffle ¶ added in v1.1.0
Randomly shuffles a tensor along its first dimension.
The tensor is shuffled along dimension 0, such that each `value[j]` is mapped to one and only one `output[i]`. For example, a mapping that might occur for a 3x2 tensor is:
``` [[1, 2], [[5, 6],
[3, 4], ==> [1, 2], [5, 6]] [3, 4]]
```
Arguments:
value: The tensor to be shuffled.
Returns A tensor of same shape and type as `value`, shuffled along its first dimension.
func RandomShuffleQueueV2 ¶ added in v1.1.0
func RandomShuffleQueueV2(scope *Scope, component_types []tf.DataType, optional ...RandomShuffleQueueV2Attr) (handle tf.Output)
A queue that randomizes the order of elements.
Arguments:
component_types: The type of each component in a value.
Returns The handle to the queue.
func RandomStandardNormal ¶ added in v1.1.0
func RandomStandardNormal(scope *Scope, shape tf.Output, dtype tf.DataType, optional ...RandomStandardNormalAttr) (output tf.Output)
Outputs random values from a normal distribution.
The generated values will have mean 0 and standard deviation 1.
Arguments:
shape: The shape of the output tensor. dtype: The type of the output.
Returns A tensor of the specified shape filled with random normal values.
func RandomUniform ¶ added in v1.1.0
func RandomUniform(scope *Scope, shape tf.Output, dtype tf.DataType, optional ...RandomUniformAttr) (output tf.Output)
Outputs random values from a uniform distribution.
The generated values follow a uniform distribution in the range `[0, 1)`. The lower bound 0 is included in the range, while the upper bound 1 is excluded.
Arguments:
shape: The shape of the output tensor. dtype: The type of the output.
Returns A tensor of the specified shape filled with uniform random values.
func RandomUniformInt ¶ added in v1.1.0
func RandomUniformInt(scope *Scope, shape tf.Output, minval tf.Output, maxval tf.Output, optional ...RandomUniformIntAttr) (output tf.Output)
Outputs random integers from a uniform distribution.
The generated values are uniform integers in the range `[minval, maxval)`. The lower bound `minval` is included in the range, while the upper bound `maxval` is excluded.
The random integers are slightly biased unless `maxval - minval` is an exact power of two. The bias is small for values of `maxval - minval` significantly smaller than the range of the output (either `2^32` or `2^64`).
Arguments:
shape: The shape of the output tensor. minval: 0-D. Inclusive lower bound on the generated integers. maxval: 0-D. Exclusive upper bound on the generated integers.
Returns A tensor of the specified shape filled with uniform random integers.
func Range ¶ added in v1.1.0
Creates a sequence of numbers.
This operation creates a sequence of numbers that begins at `start` and extends by increments of `delta` up to but not including `limit`.
For example:
``` # 'start' is 3 # 'limit' is 18 # 'delta' is 3 tf.range(start, limit, delta) ==> [3, 6, 9, 12, 15] ```
Arguments:
start: 0-D (scalar). First entry in the sequence. limit: 0-D (scalar). Upper limit of sequence, exclusive. delta: 0-D (scalar). Optional. Default is 1. Number that increments `start`.
Returns 1-D.
func RangeDataset ¶ added in v1.2.0
func RangeDataset(scope *Scope, start tf.Output, stop tf.Output, step tf.Output, output_types []tf.DataType, output_shapes []tf.Shape) (handle tf.Output)
Creates a dataset with a range of values. Corresponds to python's xrange.
Arguments:
start: corresponds to start in python's xrange(). stop: corresponds to stop in python's xrange(). step: corresponds to step in python's xrange().
func Rank ¶ added in v1.1.0
Returns the rank of a tensor.
This operation returns an integer representing the rank of `input`.
For example:
``` # 't' is [[[1, 1, 1], [2, 2, 2]], [[3, 3, 3], [4, 4, 4]]] # shape of tensor 't' is [2, 2, 3] rank(t) ==> 3 ```
**Note**: The rank of a tensor is not the same as the rank of a matrix. The rank of a tensor is the number of indices required to uniquely select each element of the tensor. Rank is also known as "order", "degree", or "ndims."
func ReadVariableOp ¶ added in v1.1.0
Reads the value of a variable.
The tensor returned by this operation is immutable.
The value returned by this operation is guaranteed to be influenced by all the writes on which this operation depends directly or indirectly, and to not be influenced by any of the writes which depend directly or indirectly on this operation.
Arguments:
resource: handle to the resource in which to store the variable. dtype: the dtype of the value.
func ReaderNumRecordsProducedV2 ¶ added in v1.1.0
Returns the number of records this Reader has produced.
This is the same as the number of ReaderRead executions that have succeeded.
Arguments:
reader_handle: Handle to a Reader.
func ReaderNumWorkUnitsCompletedV2 ¶ added in v1.1.0
func ReaderNumWorkUnitsCompletedV2(scope *Scope, reader_handle tf.Output) (units_completed tf.Output)
Returns the number of work units this Reader has finished processing.
Arguments:
reader_handle: Handle to a Reader.
func ReaderReadUpToV2 ¶ added in v1.1.0
func ReaderReadUpToV2(scope *Scope, reader_handle tf.Output, queue_handle tf.Output, num_records tf.Output) (keys tf.Output, values tf.Output)
Returns up to `num_records` (key, value) pairs produced by a Reader.
Will dequeue from the input queue if necessary (e.g. when the Reader needs to start reading from a new file since it has finished with the previous file). It may return less than `num_records` even before the last batch.
Arguments:
reader_handle: Handle to a `Reader`. queue_handle: Handle to a `Queue`, with string work items. num_records: number of records to read from `Reader`.
Returns A 1-D tensor.A 1-D tensor.
func ReaderReadV2 ¶ added in v1.1.0
func ReaderReadV2(scope *Scope, reader_handle tf.Output, queue_handle tf.Output) (key tf.Output, value tf.Output)
Returns the next record (key, value pair) produced by a Reader.
Will dequeue from the input queue if necessary (e.g. when the Reader needs to start reading from a new file since it has finished with the previous file).
Arguments:
reader_handle: Handle to a Reader. queue_handle: Handle to a Queue, with string work items.
Returns A scalar.A scalar.
func ReaderResetV2 ¶ added in v1.1.0
Restore a Reader to its initial clean state.
Arguments:
reader_handle: Handle to a Reader.
Returns the created operation.
func ReaderRestoreStateV2 ¶ added in v1.1.0
Restore a reader to a previously saved state.
Not all Readers support being restored, so this can produce an Unimplemented error.
Arguments:
reader_handle: Handle to a Reader. state: Result of a ReaderSerializeState of a Reader with type
matching reader_handle.
Returns the created operation.
func ReaderSerializeStateV2 ¶ added in v1.1.0
Produce a string tensor that encodes the state of a Reader.
Not all Readers support being serialized, so this can produce an Unimplemented error.
Arguments:
reader_handle: Handle to a Reader.
func Real ¶ added in v1.1.0
Returns the real part of a complex number.
Given a tensor `input` of complex numbers, this operation returns a tensor of type `float` that is the real part of each element in `input`. All elements in `input` must be complex numbers of the form \\(a + bj\\), where *a* is the real
part returned by this operation and *b* is the imaginary part.
For example:
``` # tensor 'input' is [-2.25 + 4.75j, 3.25 + 5.75j] tf.real(input) ==> [-2.25, 3.25] ```
func RealDiv ¶ added in v1.1.0
Returns x / y element-wise for real types.
If `x` and `y` are reals, this will return the floating-point division.
*NOTE*: `Div` supports broadcasting. More about broadcasting [here](http://docs.scipy.org/doc/numpy/user/basics.broadcasting.html)
func ReciprocalGrad ¶ added in v1.1.0
Computes the gradient for the inverse of `x` wrt its input.
Specifically, `grad = -dy * y*y`, where `y = 1/x`, and `dy` is the corresponding input gradient.
func RecordInput ¶ added in v1.1.0
func RecordInput(scope *Scope, file_pattern string, optional ...RecordInputAttr) (records tf.Output)
Emits randomized records.
Arguments:
file_pattern: Glob pattern for the data files.
Returns A tensor of shape [batch_size].
func ReduceJoin ¶ added in v1.1.0
func ReduceJoin(scope *Scope, inputs tf.Output, reduction_indices tf.Output, optional ...ReduceJoinAttr) (output tf.Output)
Joins a string Tensor across the given dimensions.
Computes the string join across dimensions in the given string Tensor of shape `[d_0, d_1, ..., d_n-1]`. Returns a new Tensor created by joining the input strings with the given separator (default: empty string). Negative indices are counted backwards from the end, with `-1` being equivalent to `n - 1`.
For example:
```python # tensor `a` is [["a", "b"], ["c", "d"]] tf.reduce_join(a, 0) ==> ["ac", "bd"] tf.reduce_join(a, 1) ==> ["ab", "cd"] tf.reduce_join(a, -2) = tf.reduce_join(a, 0) ==> ["ac", "bd"] tf.reduce_join(a, -1) = tf.reduce_join(a, 1) ==> ["ab", "cd"] tf.reduce_join(a, 0, keep_dims=True) ==> [["ac", "bd"]] tf.reduce_join(a, 1, keep_dims=True) ==> [["ab"], ["cd"]] tf.reduce_join(a, 0, separator=".") ==> ["a.c", "b.d"] tf.reduce_join(a, [0, 1]) ==> ["acbd"] tf.reduce_join(a, [1, 0]) ==> ["abcd"] tf.reduce_join(a, []) ==> ["abcd"] ```
Arguments:
inputs: The input to be joined. All reduced indices must have non-zero size. reduction_indices: The dimensions to reduce over. Dimensions are reduced in the
order specified. Omitting `reduction_indices` is equivalent to passing `[n-1, n-2, ..., 0]`. Negative indices from `-n` to `-1` are supported.
Returns Has shape equal to that of the input with reduced dimensions removed or set to `1` depending on `keep_dims`.
func Relu6Grad ¶ added in v1.1.0
Computes rectified linear 6 gradients for a Relu6 operation.
Arguments:
gradients: The backpropagated gradients to the corresponding Relu6 operation. features: The features passed as input to the corresponding Relu6 operation, or
its output; using either one produces the same result.
Returns The gradients: `gradients * (features > 0) * (features < 6)`.
func ReluGrad ¶ added in v1.1.0
Computes rectified linear gradients for a Relu operation.
Arguments:
gradients: The backpropagated gradients to the corresponding Relu operation. features: The features passed as input to the corresponding Relu operation, OR
the outputs of that operation (both work equivalently).
Returns `gradients * (features > 0)`.
func RemoteFusedGraphExecute ¶ added in v1.1.0
func RemoteFusedGraphExecute(scope *Scope, inputs []tf.Output, Toutputs []tf.DataType, serialized_remote_fused_graph_execute_info string) (outputs []tf.Output)
Execute a sub graph on a remote processor.
The graph specifications(such as graph itself, input tensors and output names) are stored as a serialized protocol buffer of RemoteFusedGraphExecuteInfo as serialized_remote_fused_graph_execute_info. The specifications will be passed to a dedicated registered remote fused graph executor. The executor will send the graph specifications to a remote processor and execute that graph. The execution results will be passed to consumer nodes as outputs of this node.
Arguments:
inputs: Arbitrary number of tensors with arbitrary data types serialized_remote_fused_graph_execute_info: Serialized protocol buffer
of RemoteFusedGraphExecuteInfo which contains graph specifications.
Returns Arbitrary number of tensors with arbitrary data types
func RepeatDataset ¶ added in v1.2.0
func RepeatDataset(scope *Scope, input_dataset tf.Output, count tf.Output, output_types []tf.DataType, output_shapes []tf.Shape) (handle tf.Output)
Creates a dataset that emits the outputs of `input_dataset` `count` times.
Arguments:
count: A scalar representing the number of times that `input_dataset` should
be repeated. A value of `-1` indicates that it should be repeated infinitely.
func RequantizationRange ¶ added in v1.1.0
func RequantizationRange(scope *Scope, input tf.Output, input_min tf.Output, input_max tf.Output) (output_min tf.Output, output_max tf.Output)
Given a quantized tensor described by (input, input_min, input_max), outputs a
range that covers the actual values present in that tensor. This op is typically used to produce the requested_output_min and requested_output_max for Requantize.
Arguments:
input_min: The float value that the minimum quantized input value represents. input_max: The float value that the maximum quantized input value represents.
Returns The computed min output.the computed max output.
func Requantize ¶ added in v1.1.0
func Requantize(scope *Scope, input tf.Output, input_min tf.Output, input_max tf.Output, requested_output_min tf.Output, requested_output_max tf.Output, out_type tf.DataType) (output tf.Output, output_min tf.Output, output_max tf.Output)
Convert the quantized 'input' tensor into a lower-precision 'output', using the
output range specified with 'requested_output_min' and 'requested_output_max'.
[input_min, input_max] are scalar floats that specify the range for the float interpretation of the 'input' data. For example, if input_min is -1.0f and input_max is 1.0f, and we are dealing with quint16 quantized data, then a 0 value in the 16-bit data should be interpreted as -1.0f, and a 65535 means 1.0f.
Arguments:
input_min: The float value that the minimum quantized input value represents. input_max: The float value that the maximum quantized input value represents. requested_output_min: The float value that the minimum quantized output value represents. requested_output_max: The float value that the maximum quantized output value represents. out_type: The type of the output. Should be a lower bit depth than Tinput.
Returns The requested_output_min value is copied into this output.The requested_output_max value is copied into this output.
func Reshape ¶ added in v1.1.0
Reshapes a tensor.
Given `tensor`, this operation returns a tensor that has the same values as `tensor` with shape `shape`.
If one component of `shape` is the special value -1, the size of that dimension is computed so that the total size remains constant. In particular, a `shape` of `[-1]` flattens into 1-D. At most one component of `shape` can be -1.
If `shape` is 1-D or higher, then the operation returns a tensor with shape `shape` filled with the values of `tensor`. In this case, the number of elements implied by `shape` must be the same as the number of elements in `tensor`.
For example:
``` # tensor 't' is [1, 2, 3, 4, 5, 6, 7, 8, 9] # tensor 't' has shape [9] reshape(t, [3, 3]) ==> [[1, 2, 3],
[4, 5, 6], [7, 8, 9]]
# tensor 't' is [[[1, 1], [2, 2]], # [[3, 3], [4, 4]]] # tensor 't' has shape [2, 2, 2] reshape(t, [2, 4]) ==> [[1, 1, 2, 2],
[3, 3, 4, 4]]
# tensor 't' is [[[1, 1, 1], # [2, 2, 2]], # [[3, 3, 3], # [4, 4, 4]], # [[5, 5, 5], # [6, 6, 6]]] # tensor 't' has shape [3, 2, 3] # pass '[-1]' to flatten 't' reshape(t, [-1]) ==> [1, 1, 1, 2, 2, 2, 3, 3, 3, 4, 4, 4, 5, 5, 5, 6, 6, 6]
-1 can also be used to infer the shape ¶
# -1 is inferred to be 9: reshape(t, [2, -1]) ==> [[1, 1, 1, 2, 2, 2, 3, 3, 3],
[4, 4, 4, 5, 5, 5, 6, 6, 6]]
# -1 is inferred to be 2: reshape(t, [-1, 9]) ==> [[1, 1, 1, 2, 2, 2, 3, 3, 3],
[4, 4, 4, 5, 5, 5, 6, 6, 6]]
# -1 is inferred to be 3: reshape(t, [ 2, -1, 3]) ==> [[[1, 1, 1],
[2, 2, 2], [3, 3, 3]], [[4, 4, 4], [5, 5, 5], [6, 6, 6]]]
# tensor 't' is [7] # shape `[]` reshapes to a scalar reshape(t, []) ==> 7 ```
Arguments:
shape: Defines the shape of the output tensor.
func ResizeArea ¶ added in v1.1.0
func ResizeArea(scope *Scope, images tf.Output, size tf.Output, optional ...ResizeAreaAttr) (resized_images tf.Output)
Resize `images` to `size` using area interpolation.
Input images can be of different types but output images are always float.
Each output pixel is computed by first transforming the pixel's footprint into the input tensor and then averaging the pixels that intersect the footprint. An input pixel's contribution to the average is weighted by the fraction of its area that intersects the footprint. This is the same as OpenCV's INTER_AREA.
Arguments:
images: 4-D with shape `[batch, height, width, channels]`. size: = A 1-D int32 Tensor of 2 elements: `new_height, new_width`. The
new size for the images.
Returns 4-D with shape `[batch, new_height, new_width, channels]`.
func ResizeBicubic ¶ added in v1.1.0
func ResizeBicubic(scope *Scope, images tf.Output, size tf.Output, optional ...ResizeBicubicAttr) (resized_images tf.Output)
Resize `images` to `size` using bicubic interpolation.
Input images can be of different types but output images are always float.
Arguments:
images: 4-D with shape `[batch, height, width, channels]`. size: = A 1-D int32 Tensor of 2 elements: `new_height, new_width`. The
new size for the images.
Returns 4-D with shape `[batch, new_height, new_width, channels]`.
func ResizeBicubicGrad ¶ added in v1.4.0
func ResizeBicubicGrad(scope *Scope, grads tf.Output, original_image tf.Output, optional ...ResizeBicubicGradAttr) (output tf.Output)
Computes the gradient of bicubic interpolation.
Arguments:
grads: 4-D with shape `[batch, height, width, channels]`. original_image: 4-D with shape `[batch, orig_height, orig_width, channels]`,
The image tensor that was resized.
Returns 4-D with shape `[batch, orig_height, orig_width, channels]`. Gradients with respect to the input image. Input image must have been float or double.
func ResizeBilinear ¶ added in v1.1.0
func ResizeBilinear(scope *Scope, images tf.Output, size tf.Output, optional ...ResizeBilinearAttr) (resized_images tf.Output)
Resize `images` to `size` using bilinear interpolation.
Input images can be of different types but output images are always float.
Arguments:
images: 4-D with shape `[batch, height, width, channels]`. size: = A 1-D int32 Tensor of 2 elements: `new_height, new_width`. The
new size for the images.
Returns 4-D with shape `[batch, new_height, new_width, channels]`.
func ResizeBilinearGrad ¶ added in v1.1.0
func ResizeBilinearGrad(scope *Scope, grads tf.Output, original_image tf.Output, optional ...ResizeBilinearGradAttr) (output tf.Output)
Computes the gradient of bilinear interpolation.
Arguments:
grads: 4-D with shape `[batch, height, width, channels]`. original_image: 4-D with shape `[batch, orig_height, orig_width, channels]`,
The image tensor that was resized.
Returns 4-D with shape `[batch, orig_height, orig_width, channels]`. Gradients with respect to the input image. Input image must have been float or double.
func ResizeNearestNeighbor ¶ added in v1.1.0
func ResizeNearestNeighbor(scope *Scope, images tf.Output, size tf.Output, optional ...ResizeNearestNeighborAttr) (resized_images tf.Output)
Resize `images` to `size` using nearest neighbor interpolation.
Arguments:
images: 4-D with shape `[batch, height, width, channels]`. size: = A 1-D int32 Tensor of 2 elements: `new_height, new_width`. The
new size for the images.
Returns 4-D with shape `[batch, new_height, new_width, channels]`.
func ResizeNearestNeighborGrad ¶ added in v1.1.0
func ResizeNearestNeighborGrad(scope *Scope, grads tf.Output, size tf.Output, optional ...ResizeNearestNeighborGradAttr) (output tf.Output)
Computes the gradient of nearest neighbor interpolation.
Arguments:
grads: 4-D with shape `[batch, height, width, channels]`. size: = A 1-D int32 Tensor of 2 elements: `orig_height, orig_width`. The
original input size.
Returns 4-D with shape `[batch, orig_height, orig_width, channels]`. Gradients with respect to the input image.
func ResourceApplyAdadelta ¶ added in v1.1.0
func ResourceApplyAdadelta(scope *Scope, var_ tf.Output, accum tf.Output, accum_update tf.Output, lr tf.Output, rho tf.Output, epsilon tf.Output, grad tf.Output, optional ...ResourceApplyAdadeltaAttr) (o *tf.Operation)
Update '*var' according to the adadelta scheme.
accum = rho() * accum + (1 - rho()) * grad.square(); update = (update_accum + epsilon).sqrt() * (accum + epsilon()).rsqrt() * grad; update_accum = rho() * update_accum + (1 - rho()) * update.square(); var -= update;
Arguments:
var_: Should be from a Variable(). accum: Should be from a Variable(). accum_update: Should be from a Variable(). lr: Scaling factor. Must be a scalar. rho: Decay factor. Must be a scalar. epsilon: Constant factor. Must be a scalar. grad: The gradient.
Returns the created operation.
func ResourceApplyAdagrad ¶ added in v1.1.0
func ResourceApplyAdagrad(scope *Scope, var_ tf.Output, accum tf.Output, lr tf.Output, grad tf.Output, optional ...ResourceApplyAdagradAttr) (o *tf.Operation)
Update '*var' according to the adagrad scheme.
accum += grad * grad var -= lr * grad * (1 / sqrt(accum))
Arguments:
var_: Should be from a Variable(). accum: Should be from a Variable(). lr: Scaling factor. Must be a scalar. grad: The gradient.
Returns the created operation.
func ResourceApplyAdagradDA ¶ added in v1.1.0
func ResourceApplyAdagradDA(scope *Scope, var_ tf.Output, gradient_accumulator tf.Output, gradient_squared_accumulator tf.Output, grad tf.Output, lr tf.Output, l1 tf.Output, l2 tf.Output, global_step tf.Output, optional ...ResourceApplyAdagradDAAttr) (o *tf.Operation)
Update '*var' according to the proximal adagrad scheme.
Arguments:
var_: Should be from a Variable(). gradient_accumulator: Should be from a Variable(). gradient_squared_accumulator: Should be from a Variable(). grad: The gradient. lr: Scaling factor. Must be a scalar. l1: L1 regularization. Must be a scalar. l2: L2 regularization. Must be a scalar. global_step: Training step number. Must be a scalar.
Returns the created operation.
func ResourceApplyAdam ¶ added in v1.1.0
func ResourceApplyAdam(scope *Scope, var_ tf.Output, m tf.Output, v tf.Output, beta1_power tf.Output, beta2_power tf.Output, lr tf.Output, beta1 tf.Output, beta2 tf.Output, epsilon tf.Output, grad tf.Output, optional ...ResourceApplyAdamAttr) (o *tf.Operation)
Update '*var' according to the Adam algorithm.
lr_t <- learning_rate * sqrt(1 - beta2^t) / (1 - beta1^t) m_t <- beta1 * m_{t-1} + (1 - beta1) * g_t v_t <- beta2 * v_{t-1} + (1 - beta2) * g_t * g_t variable <- variable - lr_t * m_t / (sqrt(v_t) + epsilon)
Arguments:
var_: Should be from a Variable(). m: Should be from a Variable(). v: Should be from a Variable(). beta1_power: Must be a scalar. beta2_power: Must be a scalar. lr: Scaling factor. Must be a scalar. beta1: Momentum factor. Must be a scalar. beta2: Momentum factor. Must be a scalar. epsilon: Ridge term. Must be a scalar. grad: The gradient.
Returns the created operation.
func ResourceApplyAddSign ¶ added in v1.5.0
func ResourceApplyAddSign(scope *Scope, var_ tf.Output, m tf.Output, lr tf.Output, alpha tf.Output, sign_decay tf.Output, beta tf.Output, grad tf.Output, optional ...ResourceApplyAddSignAttr) (o *tf.Operation)
Update '*var' according to the AddSign update.
m_t <- beta1 * m_{t-1} + (1 - beta1) * g update <- (alpha + sign_decay * sign(g) *sign(m)) * g variable <- variable - lr_t * update
Arguments:
var_: Should be from a Variable(). m: Should be from a Variable(). lr: Scaling factor. Must be a scalar. alpha: Must be a scalar. sign_decay: Must be a scalar. beta: Must be a scalar. grad: The gradient.
Returns the created operation.
func ResourceApplyCenteredRMSProp ¶ added in v1.1.0
func ResourceApplyCenteredRMSProp(scope *Scope, var_ tf.Output, mg tf.Output, ms tf.Output, mom tf.Output, lr tf.Output, rho tf.Output, momentum tf.Output, epsilon tf.Output, grad tf.Output, optional ...ResourceApplyCenteredRMSPropAttr) (o *tf.Operation)
Update '*var' according to the centered RMSProp algorithm.
The centered RMSProp algorithm uses an estimate of the centered second moment (i.e., the variance) for normalization, as opposed to regular RMSProp, which uses the (uncentered) second moment. This often helps with training, but is slightly more expensive in terms of computation and memory.
Note that in dense implementation of this algorithm, mg, ms, and mom will update even if the grad is zero, but in this sparse implementation, mg, ms, and mom will not update in iterations during which the grad is zero.
mean_square = decay * mean_square + (1-decay) * gradient ** 2 mean_grad = decay * mean_grad + (1-decay) * gradient
Delta = learning_rate * gradient / sqrt(mean_square + epsilon - mean_grad ** 2)
mg <- rho * mg_{t-1} + (1-rho) * grad ms <- rho * ms_{t-1} + (1-rho) * grad * grad mom <- momentum * mom_{t-1} + lr * grad / sqrt(ms - mg * mg + epsilon) var <- var - mom
Arguments:
var_: Should be from a Variable(). mg: Should be from a Variable(). ms: Should be from a Variable(). mom: Should be from a Variable(). lr: Scaling factor. Must be a scalar. rho: Decay rate. Must be a scalar. epsilon: Ridge term. Must be a scalar. grad: The gradient.
Returns the created operation.
func ResourceApplyFtrl ¶ added in v1.1.0
func ResourceApplyFtrl(scope *Scope, var_ tf.Output, accum tf.Output, linear tf.Output, grad tf.Output, lr tf.Output, l1 tf.Output, l2 tf.Output, lr_power tf.Output, optional ...ResourceApplyFtrlAttr) (o *tf.Operation)
Update '*var' according to the Ftrl-proximal scheme.
accum_new = accum + grad * grad linear += grad - (accum_new^(-lr_power) - accum^(-lr_power)) / lr * var quadratic = 1.0 / (accum_new^(lr_power) * lr) + 2 * l2 var = (sign(linear) * l1 - linear) / quadratic if |linear| > l1 else 0.0 accum = accum_new
Arguments:
var_: Should be from a Variable(). accum: Should be from a Variable(). linear: Should be from a Variable(). grad: The gradient. lr: Scaling factor. Must be a scalar. l1: L1 regulariation. Must be a scalar. l2: L2 regulariation. Must be a scalar. lr_power: Scaling factor. Must be a scalar.
Returns the created operation.
func ResourceApplyFtrlV2 ¶ added in v1.3.0
func ResourceApplyFtrlV2(scope *Scope, var_ tf.Output, accum tf.Output, linear tf.Output, grad tf.Output, lr tf.Output, l1 tf.Output, l2 tf.Output, l2_shrinkage tf.Output, lr_power tf.Output, optional ...ResourceApplyFtrlV2Attr) (o *tf.Operation)
Update '*var' according to the Ftrl-proximal scheme.
grad_with_shrinkage = grad + 2 * l2_shrinkage * var accum_new = accum + grad_with_shrinkage * grad_with_shrinkage linear += grad_with_shrinkage +
(accum_new^(-lr_power) - accum^(-lr_power)) / lr * var
quadratic = 1.0 / (accum_new^(lr_power) * lr) + 2 * l2 var = (sign(linear) * l1 - linear) / quadratic if |linear| > l1 else 0.0 accum = accum_new
Arguments:
var_: Should be from a Variable(). accum: Should be from a Variable(). linear: Should be from a Variable(). grad: The gradient. lr: Scaling factor. Must be a scalar. l1: L1 regulariation. Must be a scalar. l2: L2 shrinkage regulariation. Must be a scalar. lr_power: Scaling factor. Must be a scalar.
Returns the created operation.
func ResourceApplyGradientDescent ¶ added in v1.1.0
func ResourceApplyGradientDescent(scope *Scope, var_ tf.Output, alpha tf.Output, delta tf.Output, optional ...ResourceApplyGradientDescentAttr) (o *tf.Operation)
Update '*var' by subtracting 'alpha' * 'delta' from it.
Arguments:
var_: Should be from a Variable(). alpha: Scaling factor. Must be a scalar. delta: The change.
Returns the created operation.
func ResourceApplyMomentum ¶ added in v1.1.0
func ResourceApplyMomentum(scope *Scope, var_ tf.Output, accum tf.Output, lr tf.Output, grad tf.Output, momentum tf.Output, optional ...ResourceApplyMomentumAttr) (o *tf.Operation)
Update '*var' according to the momentum scheme. Set use_nesterov = True if you
want to use Nesterov momentum.
accum = accum * momentum + grad var -= lr * accum
Arguments:
var_: Should be from a Variable(). accum: Should be from a Variable(). lr: Scaling factor. Must be a scalar. grad: The gradient. momentum: Momentum. Must be a scalar.
Returns the created operation.
func ResourceApplyPowerSign ¶ added in v1.5.0
func ResourceApplyPowerSign(scope *Scope, var_ tf.Output, m tf.Output, lr tf.Output, logbase tf.Output, sign_decay tf.Output, beta tf.Output, grad tf.Output, optional ...ResourceApplyPowerSignAttr) (o *tf.Operation)
Update '*var' according to the AddSign update.
m_t <- beta1 * m_{t-1} + (1 - beta1) * g update <- exp(logbase * sign_decay * sign(g) * sign(m_t)) * g variable <- variable - lr_t * update
Arguments:
var_: Should be from a Variable(). m: Should be from a Variable(). lr: Scaling factor. Must be a scalar. logbase: Must be a scalar. sign_decay: Must be a scalar. beta: Must be a scalar. grad: The gradient.
Returns the created operation.
func ResourceApplyProximalAdagrad ¶ added in v1.1.0
func ResourceApplyProximalAdagrad(scope *Scope, var_ tf.Output, accum tf.Output, lr tf.Output, l1 tf.Output, l2 tf.Output, grad tf.Output, optional ...ResourceApplyProximalAdagradAttr) (o *tf.Operation)
Update '*var' and '*accum' according to FOBOS with Adagrad learning rate.
accum += grad * grad prox_v = var - lr * grad * (1 / sqrt(accum)) var = sign(prox_v)/(1+lr*l2) * max{|prox_v|-lr*l1,0}
Arguments:
var_: Should be from a Variable(). accum: Should be from a Variable(). lr: Scaling factor. Must be a scalar. l1: L1 regularization. Must be a scalar. l2: L2 regularization. Must be a scalar. grad: The gradient.
Returns the created operation.
func ResourceApplyProximalGradientDescent ¶ added in v1.1.0
func ResourceApplyProximalGradientDescent(scope *Scope, var_ tf.Output, alpha tf.Output, l1 tf.Output, l2 tf.Output, delta tf.Output, optional ...ResourceApplyProximalGradientDescentAttr) (o *tf.Operation)
Update '*var' as FOBOS algorithm with fixed learning rate.
prox_v = var - alpha * delta var = sign(prox_v)/(1+alpha*l2) * max{|prox_v|-alpha*l1,0}
Arguments:
var_: Should be from a Variable(). alpha: Scaling factor. Must be a scalar. l1: L1 regularization. Must be a scalar. l2: L2 regularization. Must be a scalar. delta: The change.
Returns the created operation.
func ResourceApplyRMSProp ¶ added in v1.1.0
func ResourceApplyRMSProp(scope *Scope, var_ tf.Output, ms tf.Output, mom tf.Output, lr tf.Output, rho tf.Output, momentum tf.Output, epsilon tf.Output, grad tf.Output, optional ...ResourceApplyRMSPropAttr) (o *tf.Operation)
Update '*var' according to the RMSProp algorithm.
Note that in dense implementation of this algorithm, ms and mom will update even if the grad is zero, but in this sparse implementation, ms and mom will not update in iterations during which the grad is zero.
mean_square = decay * mean_square + (1-decay) * gradient ** 2 Delta = learning_rate * gradient / sqrt(mean_square + epsilon)
ms <- rho * ms_{t-1} + (1-rho) * grad * grad mom <- momentum * mom_{t-1} + lr * grad / sqrt(ms + epsilon) var <- var - mom
Arguments:
var_: Should be from a Variable(). ms: Should be from a Variable(). mom: Should be from a Variable(). lr: Scaling factor. Must be a scalar. rho: Decay rate. Must be a scalar. epsilon: Ridge term. Must be a scalar. grad: The gradient.
Returns the created operation.
func ResourceCountUpTo ¶ added in v1.5.0
func ResourceCountUpTo(scope *Scope, resource tf.Output, limit int64, T tf.DataType) (output tf.Output)
Increments variable pointed to by 'resource' until it reaches 'limit'.
Arguments:
resource: Should be from a scalar `Variable` node. limit: If incrementing ref would bring it above limit, instead generates an
'OutOfRange' error.
Returns A copy of the input before increment. If nothing else modifies the input, the values produced will all be distinct.
func ResourceGather ¶ added in v1.1.0
func ResourceGather(scope *Scope, resource tf.Output, indices tf.Output, dtype tf.DataType, optional ...ResourceGatherAttr) (output tf.Output)
Gather slices from the variable pointed to by `resource` according to `indices`.
`indices` must be an integer tensor of any dimension (usually 0-D or 1-D). Produces an output tensor with shape `indices.shape + params.shape[1:]` where:
```python
# Scalar indices output[:, ..., :] = params[indices, :, ... :] # Vector indices output[i, :, ..., :] = params[indices[i], :, ... :] # Higher rank indices output[i, ..., j, :, ... :] = params[indices[i, ..., j], :, ..., :]
```
func ResourceScatterAdd ¶ added in v1.1.0
func ResourceScatterAdd(scope *Scope, resource tf.Output, indices tf.Output, updates tf.Output) (o *tf.Operation)
Adds sparse updates to the variable referenced by `resource`.
This operation computes
# Scalar indices ref[indices, ...] += updates[...] # Vector indices (for each i) ref[indices[i], ...] += updates[i, ...] # High rank indices (for each i, ..., j) ref[indices[i, ..., j], ...] += updates[i, ..., j, ...]
Duplicate entries are handled correctly: if multiple `indices` reference the same location, their contributions add.
Requires `updates.shape = indices.shape + ref.shape[1:]`.
<div style="width:70%; margin:auto; margin-bottom:10px; margin-top:20px;"> <img style="width:100%" src='https://www.tensorflow.org/images/ScatterAdd.png' alt> </div>
{kind=link}
Arguments:
resource: Should be from a `Variable` node. indices: A tensor of indices into the first dimension of `ref`. updates: A tensor of updated values to add to `ref`.
Returns the created operation.
func ResourceScatterNdUpdate ¶ added in v1.6.0
func ResourceScatterNdUpdate(scope *Scope, ref tf.Output, indices tf.Output, updates tf.Output, optional ...ResourceScatterNdUpdateAttr) (o *tf.Operation)
Applies sparse `updates` to individual values or slices within a given
variable according to `indices`.
`ref` is a `Tensor` with rank `P` and `indices` is a `Tensor` of rank `Q`.
`indices` must be integer tensor, containing indices into `ref`. It must be shape `[d_0, ..., d_{Q-2}, K]` where `0 < K <= P`.
The innermost dimension of `indices` (with length `K`) corresponds to indices into elements (if `K = P`) or slices (if `K < P`) along the `K`th dimension of `ref`.
`updates` is `Tensor` of rank `Q-1+P-K` with shape:
``` [d_0, ..., d_{Q-2}, ref.shape[K], ..., ref.shape[P-1]]. ```
For example, say we want to update 4 scattered elements to a rank-1 tensor to 8 elements. In Python, that update would look like this:
```python
ref = tfe.Variable([1, 2, 3, 4, 5, 6, 7, 8]) indices = tf.constant([[4], [3], [1] ,[7]]) updates = tf.constant([9, 10, 11, 12]) update = tf.scatter_nd_update(ref, indices, updates) with tf.Session() as sess: print sess.run(update)
```
The resulting update to ref would look like this:
[1, 11, 3, 10, 9, 6, 7, 12]
See @{tf.scatter_nd} for more details about how to make updates to slices.
Arguments:
ref: A resource handle. Must be from a VarHandleOp. indices: A Tensor. Must be one of the following types: int32, int64.
A tensor of indices into ref.
updates: A Tensor. Must have the same type as ref. A tensor of updated
values to add to ref.
Returns the created operation.
func ResourceScatterUpdate ¶ added in v1.5.0
func ResourceScatterUpdate(scope *Scope, resource tf.Output, indices tf.Output, updates tf.Output) (o *tf.Operation)
Assigns sparse updates to the variable referenced by `resource`.
This operation computes
# Scalar indices ref[indices, ...] = updates[...] # Vector indices (for each i) ref[indices[i], ...] = updates[i, ...] # High rank indices (for each i, ..., j) ref[indices[i, ..., j], ...] = updates[i, ..., j, ...]
Arguments:
resource: Should be from a `Variable` node. indices: A tensor of indices into the first dimension of `ref`. updates: A tensor of updated values to add to `ref`.
Returns the created operation.
func ResourceSparseApplyAdadelta ¶ added in v1.1.0
func ResourceSparseApplyAdadelta(scope *Scope, var_ tf.Output, accum tf.Output, accum_update tf.Output, lr tf.Output, rho tf.Output, epsilon tf.Output, grad tf.Output, indices tf.Output, optional ...ResourceSparseApplyAdadeltaAttr) (o *tf.Operation)
var: Should be from a Variable().
Arguments:
accum: Should be from a Variable(). accum_update: : Should be from a Variable(). lr: Learning rate. Must be a scalar. rho: Decay factor. Must be a scalar. epsilon: Constant factor. Must be a scalar. grad: The gradient. indices: A vector of indices into the first dimension of var and accum.
Returns the created operation.
func ResourceSparseApplyAdagrad ¶ added in v1.1.0
func ResourceSparseApplyAdagrad(scope *Scope, var_ tf.Output, accum tf.Output, lr tf.Output, grad tf.Output, indices tf.Output, optional ...ResourceSparseApplyAdagradAttr) (o *tf.Operation)
Update relevant entries in '*var' and '*accum' according to the adagrad scheme.
That is for rows we have grad for, we update var and accum as follows: accum += grad * grad var -= lr * grad * (1 / sqrt(accum))
Arguments:
var_: Should be from a Variable(). accum: Should be from a Variable(). lr: Learning rate. Must be a scalar. grad: The gradient. indices: A vector of indices into the first dimension of var and accum.
Returns the created operation.
func ResourceSparseApplyAdagradDA ¶ added in v1.1.0
func ResourceSparseApplyAdagradDA(scope *Scope, var_ tf.Output, gradient_accumulator tf.Output, gradient_squared_accumulator tf.Output, grad tf.Output, indices tf.Output, lr tf.Output, l1 tf.Output, l2 tf.Output, global_step tf.Output, optional ...ResourceSparseApplyAdagradDAAttr) (o *tf.Operation)
Update entries in '*var' and '*accum' according to the proximal adagrad scheme.
Arguments:
var_: Should be from a Variable(). gradient_accumulator: Should be from a Variable(). gradient_squared_accumulator: Should be from a Variable(). grad: The gradient. indices: A vector of indices into the first dimension of var and accum. lr: Learning rate. Must be a scalar. l1: L1 regularization. Must be a scalar. l2: L2 regularization. Must be a scalar. global_step: Training step number. Must be a scalar.
Returns the created operation.
func ResourceSparseApplyCenteredRMSProp ¶ added in v1.1.0
func ResourceSparseApplyCenteredRMSProp(scope *Scope, var_ tf.Output, mg tf.Output, ms tf.Output, mom tf.Output, lr tf.Output, rho tf.Output, momentum tf.Output, epsilon tf.Output, grad tf.Output, indices tf.Output, optional ...ResourceSparseApplyCenteredRMSPropAttr) (o *tf.Operation)
Update '*var' according to the centered RMSProp algorithm.
The centered RMSProp algorithm uses an estimate of the centered second moment (i.e., the variance) for normalization, as opposed to regular RMSProp, which uses the (uncentered) second moment. This often helps with training, but is slightly more expensive in terms of computation and memory.
Note that in dense implementation of this algorithm, mg, ms, and mom will update even if the grad is zero, but in this sparse implementation, mg, ms, and mom will not update in iterations during which the grad is zero.
mean_square = decay * mean_square + (1-decay) * gradient ** 2 mean_grad = decay * mean_grad + (1-decay) * gradient Delta = learning_rate * gradient / sqrt(mean_square + epsilon - mean_grad ** 2)
ms <- rho * ms_{t-1} + (1-rho) * grad * grad mom <- momentum * mom_{t-1} + lr * grad / sqrt(ms + epsilon) var <- var - mom
Arguments:
var_: Should be from a Variable(). mg: Should be from a Variable(). ms: Should be from a Variable(). mom: Should be from a Variable(). lr: Scaling factor. Must be a scalar. rho: Decay rate. Must be a scalar. epsilon: Ridge term. Must be a scalar. grad: The gradient. indices: A vector of indices into the first dimension of var, ms and mom.
Returns the created operation.
func ResourceSparseApplyFtrl ¶ added in v1.1.0
func ResourceSparseApplyFtrl(scope *Scope, var_ tf.Output, accum tf.Output, linear tf.Output, grad tf.Output, indices tf.Output, lr tf.Output, l1 tf.Output, l2 tf.Output, lr_power tf.Output, optional ...ResourceSparseApplyFtrlAttr) (o *tf.Operation)
Update relevant entries in '*var' according to the Ftrl-proximal scheme.
That is for rows we have grad for, we update var, accum and linear as follows: accum_new = accum + grad * grad linear += grad + (accum_new^(-lr_power) - accum^(-lr_power)) / lr * var quadratic = 1.0 / (accum_new^(lr_power) * lr) + 2 * l2 var = (sign(linear) * l1 - linear) / quadratic if |linear| > l1 else 0.0 accum = accum_new
Arguments:
var_: Should be from a Variable(). accum: Should be from a Variable(). linear: Should be from a Variable(). grad: The gradient. indices: A vector of indices into the first dimension of var and accum. lr: Scaling factor. Must be a scalar. l1: L1 regularization. Must be a scalar. l2: L2 regularization. Must be a scalar. lr_power: Scaling factor. Must be a scalar.
Returns the created operation.
func ResourceSparseApplyFtrlV2 ¶ added in v1.3.0
func ResourceSparseApplyFtrlV2(scope *Scope, var_ tf.Output, accum tf.Output, linear tf.Output, grad tf.Output, indices tf.Output, lr tf.Output, l1 tf.Output, l2 tf.Output, l2_shrinkage tf.Output, lr_power tf.Output, optional ...ResourceSparseApplyFtrlV2Attr) (o *tf.Operation)
Update relevant entries in '*var' according to the Ftrl-proximal scheme.
That is for rows we have grad for, we update var, accum and linear as follows: grad_with_shrinkage = grad + 2 * l2_shrinkage * var accum_new = accum + grad_with_shrinkage * grad_with_shrinkage linear += grad_with_shrinkage +
(accum_new^(-lr_power) - accum^(-lr_power)) / lr * var
quadratic = 1.0 / (accum_new^(lr_power) * lr) + 2 * l2 var = (sign(linear) * l1 - linear) / quadratic if |linear| > l1 else 0.0 accum = accum_new
Arguments:
var_: Should be from a Variable(). accum: Should be from a Variable(). linear: Should be from a Variable(). grad: The gradient. indices: A vector of indices into the first dimension of var and accum. lr: Scaling factor. Must be a scalar. l1: L1 regularization. Must be a scalar. l2: L2 shrinkage regulariation. Must be a scalar. lr_power: Scaling factor. Must be a scalar.
Returns the created operation.
func ResourceSparseApplyMomentum ¶ added in v1.1.0
func ResourceSparseApplyMomentum(scope *Scope, var_ tf.Output, accum tf.Output, lr tf.Output, grad tf.Output, indices tf.Output, momentum tf.Output, optional ...ResourceSparseApplyMomentumAttr) (o *tf.Operation)
Update relevant entries in '*var' and '*accum' according to the momentum scheme.
Set use_nesterov = True if you want to use Nesterov momentum.
That is for rows we have grad for, we update var and accum as follows:
accum = accum * momentum + grad var -= lr * accum
Arguments:
var_: Should be from a Variable(). accum: Should be from a Variable(). lr: Learning rate. Must be a scalar. grad: The gradient. indices: A vector of indices into the first dimension of var and accum. momentum: Momentum. Must be a scalar.
Returns the created operation.
func ResourceSparseApplyProximalAdagrad ¶ added in v1.1.0
func ResourceSparseApplyProximalAdagrad(scope *Scope, var_ tf.Output, accum tf.Output, lr tf.Output, l1 tf.Output, l2 tf.Output, grad tf.Output, indices tf.Output, optional ...ResourceSparseApplyProximalAdagradAttr) (o *tf.Operation)
Sparse update entries in '*var' and '*accum' according to FOBOS algorithm.
That is for rows we have grad for, we update var and accum as follows: accum += grad * grad prox_v = var prox_v -= lr * grad * (1 / sqrt(accum)) var = sign(prox_v)/(1+lr*l2) * max{|prox_v|-lr*l1,0}
Arguments:
var_: Should be from a Variable(). accum: Should be from a Variable(). lr: Learning rate. Must be a scalar. l1: L1 regularization. Must be a scalar. l2: L2 regularization. Must be a scalar. grad: The gradient. indices: A vector of indices into the first dimension of var and accum.
Returns the created operation.
func ResourceSparseApplyProximalGradientDescent ¶ added in v1.1.0
func ResourceSparseApplyProximalGradientDescent(scope *Scope, var_ tf.Output, alpha tf.Output, l1 tf.Output, l2 tf.Output, grad tf.Output, indices tf.Output, optional ...ResourceSparseApplyProximalGradientDescentAttr) (o *tf.Operation)
Sparse update '*var' as FOBOS algorithm with fixed learning rate.
That is for rows we have grad for, we update var as follows: prox_v = var - alpha * grad var = sign(prox_v)/(1+alpha*l2) * max{|prox_v|-alpha*l1,0}
Arguments:
var_: Should be from a Variable(). alpha: Scaling factor. Must be a scalar. l1: L1 regularization. Must be a scalar. l2: L2 regularization. Must be a scalar. grad: The gradient. indices: A vector of indices into the first dimension of var and accum.
Returns the created operation.
func ResourceSparseApplyRMSProp ¶ added in v1.1.0
func ResourceSparseApplyRMSProp(scope *Scope, var_ tf.Output, ms tf.Output, mom tf.Output, lr tf.Output, rho tf.Output, momentum tf.Output, epsilon tf.Output, grad tf.Output, indices tf.Output, optional ...ResourceSparseApplyRMSPropAttr) (o *tf.Operation)
Update '*var' according to the RMSProp algorithm.
Note that in dense implementation of this algorithm, ms and mom will update even if the grad is zero, but in this sparse implementation, ms and mom will not update in iterations during which the grad is zero.
mean_square = decay * mean_square + (1-decay) * gradient ** 2 Delta = learning_rate * gradient / sqrt(mean_square + epsilon)
ms <- rho * ms_{t-1} + (1-rho) * grad * grad mom <- momentum * mom_{t-1} + lr * grad / sqrt(ms + epsilon) var <- var - mom
Arguments:
var_: Should be from a Variable(). ms: Should be from a Variable(). mom: Should be from a Variable(). lr: Scaling factor. Must be a scalar. rho: Decay rate. Must be a scalar. epsilon: Ridge term. Must be a scalar. grad: The gradient. indices: A vector of indices into the first dimension of var, ms and mom.
Returns the created operation.
func ResourceStridedSliceAssign ¶ added in v1.2.0
func ResourceStridedSliceAssign(scope *Scope, ref tf.Output, begin tf.Output, end tf.Output, strides tf.Output, value tf.Output, optional ...ResourceStridedSliceAssignAttr) (o *tf.Operation)
Assign `value` to the sliced l-value reference of `ref`.
The values of `value` are assigned to the positions in the variable `ref` that are selected by the slice parameters. The slice parameters `begin, `end`, `strides`, etc. work exactly as in `StridedSlice`.
NOTE this op currently does not support broadcasting and so `value`'s shape must be exactly the shape produced by the slice of `ref`.
Returns the created operation.
func Restore ¶ added in v1.1.0
func Restore(scope *Scope, file_pattern tf.Output, tensor_name tf.Output, dt tf.DataType, optional ...RestoreAttr) (tensor tf.Output)
Restores a tensor from checkpoint files.
Reads a tensor stored in one or several files. If there are several files (for instance because a tensor was saved as slices), `file_pattern` may contain wildcard symbols (`*` and `?`) in the filename portion only, not in the directory portion.
If a `file_pattern` matches several files, `preferred_shard` can be used to hint in which file the requested tensor is likely to be found. This op will first open the file at index `preferred_shard` in the list of matching files and try to restore tensors from that file. Only if some tensors or tensor slices are not found in that first file, then the Op opens all the files. Setting `preferred_shard` to match the value passed as the `shard` input of a matching `Save` Op may speed up Restore. This attribute only affects performance, not correctness. The default value -1 means files are processed in order.
See also `RestoreSlice`.
Arguments:
file_pattern: Must have a single element. The pattern of the files from
which we read the tensor.
tensor_name: Must have a single element. The name of the tensor to be
restored.
dt: The type of the tensor to be restored.
Returns The restored tensor.
func RestoreSlice ¶ added in v1.1.0
func RestoreSlice(scope *Scope, file_pattern tf.Output, tensor_name tf.Output, shape_and_slice tf.Output, dt tf.DataType, optional ...RestoreSliceAttr) (tensor tf.Output)
Restores a tensor from checkpoint files.
This is like `Restore` except that restored tensor can be listed as filling only a slice of a larger tensor. `shape_and_slice` specifies the shape of the larger tensor and the slice that the restored tensor covers.
The `shape_and_slice` input has the same format as the elements of the `shapes_and_slices` input of the `SaveSlices` op.
Arguments:
file_pattern: Must have a single element. The pattern of the files from
which we read the tensor.
tensor_name: Must have a single element. The name of the tensor to be
restored.
shape_and_slice: Scalar. The shapes and slice specifications to use when
restoring a tensors.
dt: The type of the tensor to be restored.
Returns The restored tensor.
func RestoreV2 ¶ added in v1.1.0
func RestoreV2(scope *Scope, prefix tf.Output, tensor_names tf.Output, shape_and_slices tf.Output, dtypes []tf.DataType) (tensors []tf.Output)
Restores tensors from a V2 checkpoint.
For backward compatibility with the V1 format, this Op currently allows restoring from a V1 checkpoint as well:
- This Op first attempts to find the V2 index file pointed to by "prefix", and if found proceed to read it as a V2 checkpoint;
- Otherwise the V1 read path is invoked.
Relying on this behavior is not recommended, as the ability to fall back to read V1 might be deprecated and eventually removed.
By default, restores the named tensors in full. If the caller wishes to restore specific slices of stored tensors, "shape_and_slices" should be non-empty strings and correspondingly well-formed.
Callers must ensure all the named tensors are indeed stored in the checkpoint.
Arguments:
prefix: Must have a single element. The prefix of a V2 checkpoint.
tensor_names: shape {N}. The names of the tensors to be restored.
shape_and_slices: shape {N}. The slice specs of the tensors to be restored.
Empty strings indicate that they are non-partitioned tensors.
dtypes: shape {N}. The list of expected dtype for the tensors. Must match
those stored in the checkpoint.
Returns shape {N}. The restored tensors, whose shapes are read from the checkpoint directly.
func Reverse ¶ added in v1.1.0
Reverses specific dimensions of a tensor.
Given a `tensor`, and a `bool` tensor `dims` representing the dimensions of `tensor`, this operation reverses each dimension i of `tensor` where `dims[i]` is `True`.
`tensor` can have up to 8 dimensions. The number of dimensions of `tensor` must equal the number of elements in `dims`. In other words:
`rank(tensor) = size(dims)`
For example:
``` # tensor 't' is [[[[ 0, 1, 2, 3], # [ 4, 5, 6, 7], # [ 8, 9, 10, 11]], # [[12, 13, 14, 15], # [16, 17, 18, 19], # [20, 21, 22, 23]]]] # tensor 't' shape is [1, 2, 3, 4]
# 'dims' is [False, False, False, True] reverse(t, dims) ==> [[[[ 3, 2, 1, 0],
[ 7, 6, 5, 4], [ 11, 10, 9, 8]], [[15, 14, 13, 12], [19, 18, 17, 16], [23, 22, 21, 20]]]]
# 'dims' is [False, True, False, False] reverse(t, dims) ==> [[[[12, 13, 14, 15],
[16, 17, 18, 19], [20, 21, 22, 23] [[ 0, 1, 2, 3], [ 4, 5, 6, 7], [ 8, 9, 10, 11]]]]
# 'dims' is [False, False, True, False] reverse(t, dims) ==> [[[[8, 9, 10, 11],
[4, 5, 6, 7], [0, 1, 2, 3]] [[20, 21, 22, 23], [16, 17, 18, 19], [12, 13, 14, 15]]]]
```
Arguments:
tensor: Up to 8-D. dims: 1-D. The dimensions to reverse.
Returns The same shape as `tensor`.
func ReverseSequence ¶ added in v1.1.0
func ReverseSequence(scope *Scope, input tf.Output, seq_lengths tf.Output, seq_dim int64, optional ...ReverseSequenceAttr) (output tf.Output)
Reverses variable length slices.
This op first slices `input` along the dimension `batch_dim`, and for each slice `i`, reverses the first `seq_lengths[i]` elements along the dimension `seq_dim`.
The elements of `seq_lengths` must obey `seq_lengths[i] <= input.dims[seq_dim]`, and `seq_lengths` must be a vector of length `input.dims[batch_dim]`.
The output slice `i` along dimension `batch_dim` is then given by input slice `i`, with the first `seq_lengths[i]` slices along dimension `seq_dim` reversed.
For example:
``` # Given this: batch_dim = 0 seq_dim = 1 input.dims = (4, 8, ...) seq_lengths = [7, 2, 3, 5]
# then slices of input are reversed on seq_dim, but only up to seq_lengths: output[0, 0:7, :, ...] = input[0, 7:0:-1, :, ...] output[1, 0:2, :, ...] = input[1, 2:0:-1, :, ...] output[2, 0:3, :, ...] = input[2, 3:0:-1, :, ...] output[3, 0:5, :, ...] = input[3, 5:0:-1, :, ...]
# while entries past seq_lens are copied through: output[0, 7:, :, ...] = input[0, 7:, :, ...] output[1, 2:, :, ...] = input[1, 2:, :, ...] output[2, 3:, :, ...] = input[2, 3:, :, ...] output[3, 2:, :, ...] = input[3, 2:, :, ...] ```
In contrast, if:
``` # Given this: batch_dim = 2 seq_dim = 0 input.dims = (8, ?, 4, ...) seq_lengths = [7, 2, 3, 5]
# then slices of input are reversed on seq_dim, but only up to seq_lengths: output[0:7, :, 0, :, ...] = input[7:0:-1, :, 0, :, ...] output[0:2, :, 1, :, ...] = input[2:0:-1, :, 1, :, ...] output[0:3, :, 2, :, ...] = input[3:0:-1, :, 2, :, ...] output[0:5, :, 3, :, ...] = input[5:0:-1, :, 3, :, ...]
# while entries past seq_lens are copied through: output[7:, :, 0, :, ...] = input[7:, :, 0, :, ...] output[2:, :, 1, :, ...] = input[2:, :, 1, :, ...] output[3:, :, 2, :, ...] = input[3:, :, 2, :, ...] output[2:, :, 3, :, ...] = input[2:, :, 3, :, ...] ```
Arguments:
input: The input to reverse. seq_lengths: 1-D with length `input.dims(batch_dim)` and
`max(seq_lengths) <= input.dims(seq_dim)`
seq_dim: The dimension which is partially reversed.
Returns The partially reversed input. It has the same shape as `input`.
func ReverseV2 ¶ added in v1.1.0
Reverses specific dimensions of a tensor.
NOTE `tf.reverse` has now changed behavior in preparation for 1.0. `tf.reverse_v2` is currently an alias that will be deprecated before TF 1.0.
Given a `tensor`, and a `int32` tensor `axis` representing the set of dimensions of `tensor` to reverse. This operation reverses each dimension `i` for which there exists `j` s.t. `axis[j] == i`.
`tensor` can have up to 8 dimensions. The number of dimensions specified in `axis` may be 0 or more entries. If an index is specified more than once, a InvalidArgument error is raised.
For example:
``` # tensor 't' is [[[[ 0, 1, 2, 3], # [ 4, 5, 6, 7], # [ 8, 9, 10, 11]], # [[12, 13, 14, 15], # [16, 17, 18, 19], # [20, 21, 22, 23]]]] # tensor 't' shape is [1, 2, 3, 4]
# 'dims' is [3] or 'dims' is [-1] reverse(t, dims) ==> [[[[ 3, 2, 1, 0],
[ 7, 6, 5, 4], [ 11, 10, 9, 8]], [[15, 14, 13, 12], [19, 18, 17, 16], [23, 22, 21, 20]]]]
# 'dims' is '[1]' (or 'dims' is '[-3]') reverse(t, dims) ==> [[[[12, 13, 14, 15],
[16, 17, 18, 19], [20, 21, 22, 23] [[ 0, 1, 2, 3], [ 4, 5, 6, 7], [ 8, 9, 10, 11]]]]
# 'dims' is '[2]' (or 'dims' is '[-2]') reverse(t, dims) ==> [[[[8, 9, 10, 11],
[4, 5, 6, 7], [0, 1, 2, 3]] [[20, 21, 22, 23], [16, 17, 18, 19], [12, 13, 14, 15]]]]
```
Arguments:
tensor: Up to 8-D. axis: 1-D. The indices of the dimensions to reverse. Must be in the range
`[-rank(tensor), rank(tensor))`.
Returns The same shape as `tensor`.
func RightShift ¶ added in v1.5.0
Elementwise computes the bitwise right-shift of `x` and `y`.
Performs a logical shift for unsigned integer types, and an arithmetic shift for signed integer types.
If `y` is negative, or greater than or equal to than the width of `x` in bits the result is implementation defined.
func Rint ¶ added in v1.1.0
Returns element-wise integer closest to x.
If the result is midway between two representable values, the even representable is chosen. For example:
``` rint(-1.5) ==> -2.0 rint(0.5000001) ==> 1.0 rint([-1.7, -1.5, -0.2, 0.2, 1.5, 1.7, 2.0]) ==> [-2., -2., -0., 0., 2., 2., 2.] ```
func Round ¶ added in v1.1.0
Rounds the values of a tensor to the nearest integer, element-wise.
Rounds half to even. Also known as bankers rounding. If you want to round according to the current system rounding mode use std::cint.
func Rsqrt ¶ added in v1.1.0
Computes reciprocal of square root of x element-wise.
I.e., \\(y = 1 / \sqrt{x}\\).
func RsqrtGrad ¶ added in v1.1.0
Computes the gradient for the rsqrt of `x` wrt its input.
Specifically, `grad = dy * -0.5 * y^3`, where `y = rsqrt(x)`, and `dy` is the corresponding input gradient.
func SampleDistortedBoundingBox ¶ added in v1.1.0
func SampleDistortedBoundingBox(scope *Scope, image_size tf.Output, bounding_boxes tf.Output, optional ...SampleDistortedBoundingBoxAttr) (begin tf.Output, size tf.Output, bboxes tf.Output)
Generate a single randomly distorted bounding box for an image.
Bounding box annotations are often supplied in addition to ground-truth labels in image recognition or object localization tasks. A common technique for training such a system is to randomly distort an image while preserving its content, i.e. *data augmentation*. This Op outputs a randomly distorted localization of an object, i.e. bounding box, given an `image_size`, `bounding_boxes` and a series of constraints.
The output of this Op is a single bounding box that may be used to crop the original image. The output is returned as 3 tensors: `begin`, `size` and `bboxes`. The first 2 tensors can be fed directly into `tf.slice` to crop the image. The latter may be supplied to `tf.image.draw_bounding_boxes` to visualize what the bounding box looks like.
Bounding boxes are supplied and returned as `[y_min, x_min, y_max, x_max]`. The bounding box coordinates are floats in `[0.0, 1.0]` relative to the width and height of the underlying image.
For example,
```python
# Generate a single distorted bounding box.
begin, size, bbox_for_draw = tf.image.sample_distorted_bounding_box(
tf.shape(image),
bounding_boxes=bounding_boxes)
# Draw the bounding box in an image summary.
image_with_box = tf.image.draw_bounding_boxes(tf.expand_dims(image, 0),
bbox_for_draw)
tf.summary.image('images_with_box', image_with_box)
# Employ the bounding box to distort the image.
distorted_image = tf.slice(image, begin, size)
```
Note that if no bounding box information is available, setting `use_image_if_no_bounding_boxes = true` will assume there is a single implicit bounding box covering the whole image. If `use_image_if_no_bounding_boxes` is false and no bounding boxes are supplied, an error is raised.
Arguments:
image_size: 1-D, containing `[height, width, channels]`. bounding_boxes: 3-D with shape `[batch, N, 4]` describing the N bounding boxes
associated with the image.
Returns 1-D, containing `[offset_height, offset_width, 0]`. Provide as input to `tf.slice`.1-D, containing `[target_height, target_width, -1]`. Provide as input to `tf.slice`.3-D with shape `[1, 1, 4]` containing the distorted bounding box. Provide as input to `tf.image.draw_bounding_boxes`.
func SampleDistortedBoundingBoxV2 ¶ added in v1.3.0
func SampleDistortedBoundingBoxV2(scope *Scope, image_size tf.Output, bounding_boxes tf.Output, min_object_covered tf.Output, optional ...SampleDistortedBoundingBoxV2Attr) (begin tf.Output, size tf.Output, bboxes tf.Output)
Generate a single randomly distorted bounding box for an image.
Bounding box annotations are often supplied in addition to ground-truth labels in image recognition or object localization tasks. A common technique for training such a system is to randomly distort an image while preserving its content, i.e. *data augmentation*. This Op outputs a randomly distorted localization of an object, i.e. bounding box, given an `image_size`, `bounding_boxes` and a series of constraints.
The output of this Op is a single bounding box that may be used to crop the original image. The output is returned as 3 tensors: `begin`, `size` and `bboxes`. The first 2 tensors can be fed directly into `tf.slice` to crop the image. The latter may be supplied to `tf.image.draw_bounding_boxes` to visualize what the bounding box looks like.
Bounding boxes are supplied and returned as `[y_min, x_min, y_max, x_max]`. The bounding box coordinates are floats in `[0.0, 1.0]` relative to the width and height of the underlying image.
For example,
```python
# Generate a single distorted bounding box.
begin, size, bbox_for_draw = tf.image.sample_distorted_bounding_box(
tf.shape(image),
bounding_boxes=bounding_boxes)
# Draw the bounding box in an image summary.
image_with_box = tf.image.draw_bounding_boxes(tf.expand_dims(image, 0),
bbox_for_draw)
tf.summary.image('images_with_box', image_with_box)
# Employ the bounding box to distort the image.
distorted_image = tf.slice(image, begin, size)
```
Note that if no bounding box information is available, setting `use_image_if_no_bounding_boxes = true` will assume there is a single implicit bounding box covering the whole image. If `use_image_if_no_bounding_boxes` is false and no bounding boxes are supplied, an error is raised.
Arguments:
image_size: 1-D, containing `[height, width, channels]`. bounding_boxes: 3-D with shape `[batch, N, 4]` describing the N bounding boxes
associated with the image.
min_object_covered: The cropped area of the image must contain at least this
fraction of any bounding box supplied. The value of this parameter should be non-negative. In the case of 0, the cropped area does not need to overlap any of the bounding boxes supplied.
Returns 1-D, containing `[offset_height, offset_width, 0]`. Provide as input to `tf.slice`.1-D, containing `[target_height, target_width, -1]`. Provide as input to `tf.slice`.3-D with shape `[1, 1, 4]` containing the distorted bounding box. Provide as input to `tf.image.draw_bounding_boxes`.
func Save ¶ added in v1.1.0
func Save(scope *Scope, filename tf.Output, tensor_names tf.Output, data []tf.Output) (o *tf.Operation)
Saves the input tensors to disk.
The size of `tensor_names` must match the number of tensors in `data`. `data[i]` is written to `filename` with name `tensor_names[i]`.
See also `SaveSlices`.
Arguments:
filename: Must have a single element. The name of the file to which we write
the tensor.
tensor_names: Shape `[N]`. The names of the tensors to be saved. data: `N` tensors to save.
Returns the created operation.
func SaveSlices ¶ added in v1.1.0
func SaveSlices(scope *Scope, filename tf.Output, tensor_names tf.Output, shapes_and_slices tf.Output, data []tf.Output) (o *tf.Operation)
Saves input tensors slices to disk.
This is like `Save` except that tensors can be listed in the saved file as being a slice of a larger tensor. `shapes_and_slices` specifies the shape of the larger tensor and the slice that this tensor covers. `shapes_and_slices` must have as many elements as `tensor_names`.
Elements of the `shapes_and_slices` input must either be:
- The empty string, in which case the corresponding tensor is saved normally.
- A string of the form `dim0 dim1 ... dimN-1 slice-spec` where the `dimI` are the dimensions of the larger tensor and `slice-spec` specifies what part is covered by the tensor to save.
`slice-spec` itself is a `:`-separated list: `slice0:slice1:...:sliceN-1` where each `sliceI` is either:
- The string `-` meaning that the slice covers all indices of this dimension
- `start,length` where `start` and `length` are integers. In that case the slice covers `length` indices starting at `start`.
See also `Save`.
Arguments:
filename: Must have a single element. The name of the file to which we write the
tensor.
tensor_names: Shape `[N]`. The names of the tensors to be saved. shapes_and_slices: Shape `[N]`. The shapes and slice specifications to use when
saving the tensors.
data: `N` tensors to save.
Returns the created operation.
func SaveV2 ¶ added in v1.1.0
func SaveV2(scope *Scope, prefix tf.Output, tensor_names tf.Output, shape_and_slices tf.Output, tensors []tf.Output) (o *tf.Operation)
Saves tensors in V2 checkpoint format.
By default, saves the named tensors in full. If the caller wishes to save specific slices of full tensors, "shape_and_slices" should be non-empty strings and correspondingly well-formed.
Arguments:
prefix: Must have a single element. The prefix of the V2 checkpoint to which we
write the tensors.
tensor_names: shape {N}. The names of the tensors to be saved.
shape_and_slices: shape {N}. The slice specs of the tensors to be saved.
Empty strings indicate that they are non-partitioned tensors.
tensors: `N` tensors to save.
Returns the created operation.
func ScalarSummary ¶ added in v1.1.0
Outputs a `Summary` protocol buffer with scalar values.
The input `tags` and `values` must have the same shape. The generated summary has a summary value for each tag-value pair in `tags` and `values`.
Arguments:
tags: Tags for the summary. values: Same shape as `tags. Values for the summary.
Returns Scalar. Serialized `Summary` protocol buffer.
func ScatterNd ¶ added in v1.1.0
func ScatterNd(scope *Scope, indices tf.Output, updates tf.Output, shape tf.Output) (output tf.Output)
Scatter `updates` into a new (initially zero) tensor according to `indices`.
Creates a new tensor by applying sparse `updates` to individual values or slices within a zero tensor of the given `shape` according to indices. This operator is the inverse of the @{tf.gather_nd} operator which extracts values or slices from a given tensor.
**WARNING**: The order in which updates are applied is nondeterministic, so the output will be nondeterministic if `indices` contains duplicates.
`indices` is an integer tensor containing indices into a new tensor of shape `shape`. The last dimension of `indices` can be at most the rank of `shape`:
indices.shape[-1] <= shape.rank
The last dimension of `indices` corresponds to indices into elements (if `indices.shape[-1] = shape.rank`) or slices (if `indices.shape[-1] < shape.rank`) along dimension `indices.shape[-1]` of `shape`. `updates` is a tensor with shape
indices.shape[:-1] + shape[indices.shape[-1]:]
The simplest form of scatter is to insert individual elements in a tensor by index. For example, say we want to insert 4 scattered elements in a rank-1 tensor with 8 elements.
<div style="width:70%; margin:auto; margin-bottom:10px; margin-top:20px;"> <img style="width:100%" src="https://www.tensorflow.org/images/ScatterNd1.png" alt> </div>
{kind=link}
In Python, this scatter operation would look like this:
```python
indices = tf.constant([[4], [3], [1], [7]]) updates = tf.constant([9, 10, 11, 12]) shape = tf.constant([8]) scatter = tf.scatter_nd(indices, updates, shape) with tf.Session() as sess: print(sess.run(scatter))
```
The resulting tensor would look like this:
[0, 11, 0, 10, 9, 0, 0, 12]
We can also, insert entire slices of a higher rank tensor all at once. For example, if we wanted to insert two slices in the first dimension of a rank-3 tensor with two matrices of new values.
<div style="width:70%; margin:auto; margin-bottom:10px; margin-top:20px;"> <img style="width:100%" src="https://www.tensorflow.org/images/ScatterNd2.png" alt> </div>
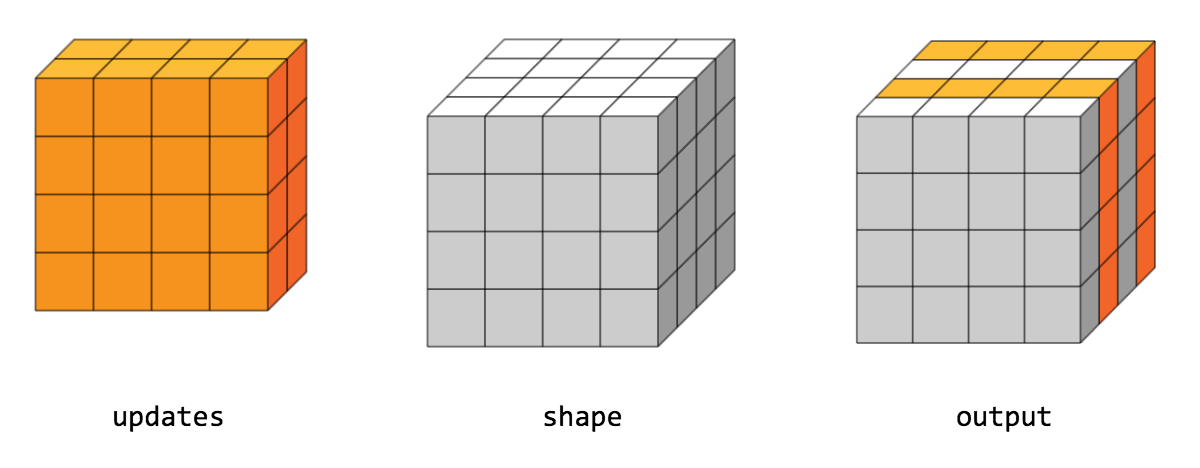{kind=link}
In Python, this scatter operation would look like this:
```python
indices = tf.constant([[0], [2]])
updates = tf.constant([[[5, 5, 5, 5], [6, 6, 6, 6],
[7, 7, 7, 7], [8, 8, 8, 8]],
[[5, 5, 5, 5], [6, 6, 6, 6],
[7, 7, 7, 7], [8, 8, 8, 8]]])
shape = tf.constant([4, 4, 4])
scatter = tf.scatter_nd(indices, updates, shape)
with tf.Session() as sess:
print(sess.run(scatter))
```
The resulting tensor would look like this:
[[[5, 5, 5, 5], [6, 6, 6, 6], [7, 7, 7, 7], [8, 8, 8, 8]], [[0, 0, 0, 0], [0, 0, 0, 0], [0, 0, 0, 0], [0, 0, 0, 0]], [[5, 5, 5, 5], [6, 6, 6, 6], [7, 7, 7, 7], [8, 8, 8, 8]], [[0, 0, 0, 0], [0, 0, 0, 0], [0, 0, 0, 0], [0, 0, 0, 0]]]
Arguments:
indices: Index tensor. updates: Updates to scatter into output. shape: 1-D. The shape of the resulting tensor.
Returns A new tensor with the given shape and updates applied according to the indices.
func ScatterNdNonAliasingAdd ¶ added in v1.3.0
func ScatterNdNonAliasingAdd(scope *Scope, input tf.Output, indices tf.Output, updates tf.Output) (output tf.Output)
Applies sparse addition to `input` using individual values or slices
from `updates` according to indices `indices`. The updates are non-aliasing: `input` is only modified in-place if no other operations will use it. Otherwise, a copy of `input` is made. This operation has a gradient with respect to both `input` and `updates`.
`input` is a `Tensor` with rank `P` and `indices` is a `Tensor` of rank `Q`.
`indices` must be integer tensor, containing indices into `input`. It must be shape `[d_0, ..., d_{Q-2}, K]` where `0 < K <= P`.
The innermost dimension of `indices` (with length `K`) corresponds to indices into elements (if `K = P`) or `(P-K)`-dimensional slices (if `K < P`) along the `K`th dimension of `input`.
`updates` is `Tensor` of rank `Q-1+P-K` with shape:
``` [d_0, ..., d_{Q-2}, input.shape[K], ..., input.shape[P-1]]. ```
For example, say we want to add 4 scattered elements to a rank-1 tensor to 8 elements. In Python, that addition would look like this:
input = tf.constant([1, 2, 3, 4, 5, 6, 7, 8]) indices = tf.constant([[4], [3], [1], [7]]) updates = tf.constant([9, 10, 11, 12]) output = tf.scatter_nd_non_aliasing_add(input, indices, updates) with tf.Session() as sess: print(sess.run(output))
The resulting value `output` would look like this:
[1, 13, 3, 14, 14, 6, 7, 20]
See @{tf.scatter_nd} for more details about how to make updates to slices.
Arguments:
input: A Tensor. indices: A Tensor. Must be one of the following types: `int32`, `int64`.
A tensor of indices into `input`.
updates: A Tensor. Must have the same type as ref. A tensor of updated values
to add to `input`.
Returns A `Tensor` with the same shape as `input`, containing values of `input` updated with `updates`.
func SdcaFprint ¶ added in v1.1.0
Computes fingerprints of the input strings.
Arguments:
input: vector of strings to compute fingerprints on.
Returns a (N,2) shaped matrix where N is the number of elements in the input vector. Each row contains the low and high parts of the fingerprint.
func SdcaOptimizer ¶ added in v1.1.0
func SdcaOptimizer(scope *Scope, sparse_example_indices []tf.Output, sparse_feature_indices []tf.Output, sparse_feature_values []tf.Output, dense_features []tf.Output, example_weights tf.Output, example_labels tf.Output, sparse_indices []tf.Output, sparse_weights []tf.Output, dense_weights []tf.Output, example_state_data tf.Output, loss_type string, l1 float32, l2 float32, num_loss_partitions int64, num_inner_iterations int64, optional ...SdcaOptimizerAttr) (out_example_state_data tf.Output, out_delta_sparse_weights []tf.Output, out_delta_dense_weights []tf.Output)
Distributed version of Stochastic Dual Coordinate Ascent (SDCA) optimizer for
linear models with L1 + L2 regularization. As global optimization objective is strongly-convex, the optimizer optimizes the dual objective at each step. The optimizer applies each update one example at a time. Examples are sampled uniformly, and the optimizer is learning rate free and enjoys linear convergence rate.
[Proximal Stochastic Dual Coordinate Ascent](http://arxiv.org/pdf/1211.2717v1.pdf).<br> Shai Shalev-Shwartz, Tong Zhang. 2012
$$Loss Objective = \sum f_{i} (wx_{i}) + (l2 / 2) * |w|^2 + l1 * |w|$$
[Adding vs. Averaging in Distributed Primal-Dual Optimization](http://arxiv.org/abs/1502.03508).<br> Chenxin Ma, Virginia Smith, Martin Jaggi, Michael I. Jordan, Peter Richtarik, Martin Takac. 2015
[Stochastic Dual Coordinate Ascent with Adaptive Probabilities](https://arxiv.org/abs/1502.08053).<br> Dominik Csiba, Zheng Qu, Peter Richtarik. 2015
Arguments:
sparse_example_indices: a list of vectors which contain example indices. sparse_feature_indices: a list of vectors which contain feature indices. sparse_feature_values: a list of vectors which contains feature value
associated with each feature group.
dense_features: a list of matrices which contains the dense feature values. example_weights: a vector which contains the weight associated with each
example.
example_labels: a vector which contains the label/target associated with each
example.
sparse_indices: a list of vectors where each value is the indices which has
corresponding weights in sparse_weights. This field maybe omitted for the dense approach.
sparse_weights: a list of vectors where each value is the weight associated with
a sparse feature group.
dense_weights: a list of vectors where the values are the weights associated
with a dense feature group.
example_state_data: a list of vectors containing the example state data. loss_type: Type of the primal loss. Currently SdcaSolver supports logistic,
squared and hinge losses.
l1: Symmetric l1 regularization strength. l2: Symmetric l2 regularization strength. num_loss_partitions: Number of partitions of the global loss function. num_inner_iterations: Number of iterations per mini-batch.
Returns a list of vectors containing the updated example state data.a list of vectors where each value is the delta weights associated with a sparse feature group.a list of vectors where the values are the delta weights associated with a dense feature group.
func SegmentMax ¶ added in v1.1.0
Computes the maximum along segments of a tensor.
Read @{$math_ops#segmentation$the section on segmentation} for an explanation of segments.
Computes a tensor such that \\(output_i = \max_j(data_j)\\) where `max` is over `j` such that `segment_ids[j] == i`.
If the max is empty for a given segment ID `i`, `output[i] = 0`.
<div style="width:70%; margin:auto; margin-bottom:10px; margin-top:20px;"> <img style="width:100%" src="https://www.tensorflow.org/images/SegmentMax.png" alt> </div>
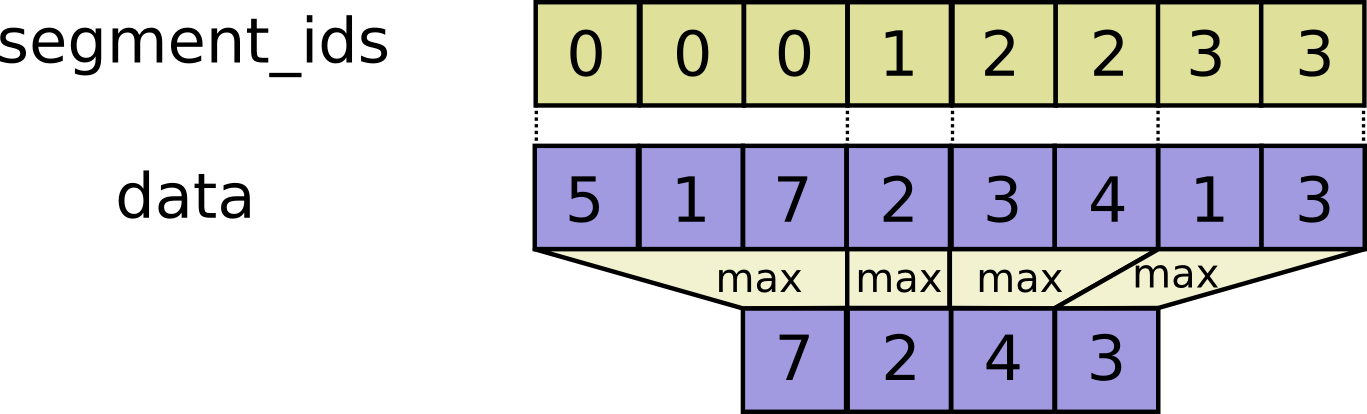{kind=link}
Arguments:
segment_ids: A 1-D tensor whose rank is equal to the rank of `data`'s
first dimension. Values should be sorted and can be repeated.
Returns Has same shape as data, except for dimension 0 which has size `k`, the number of segments.
func SegmentMean ¶ added in v1.1.0
Computes the mean along segments of a tensor.
Read @{$math_ops#segmentation$the section on segmentation} for an explanation of segments.
Computes a tensor such that \\(output_i = \frac{\sum_j data_j}{N}\\) where `mean` is over `j` such that `segment_ids[j] == i` and `N` is the total number of values summed.
If the mean is empty for a given segment ID `i`, `output[i] = 0`.
<div style="width:70%; margin:auto; margin-bottom:10px; margin-top:20px;"> <img style="width:100%" src="https://www.tensorflow.org/images/SegmentMean.png" alt> </div>
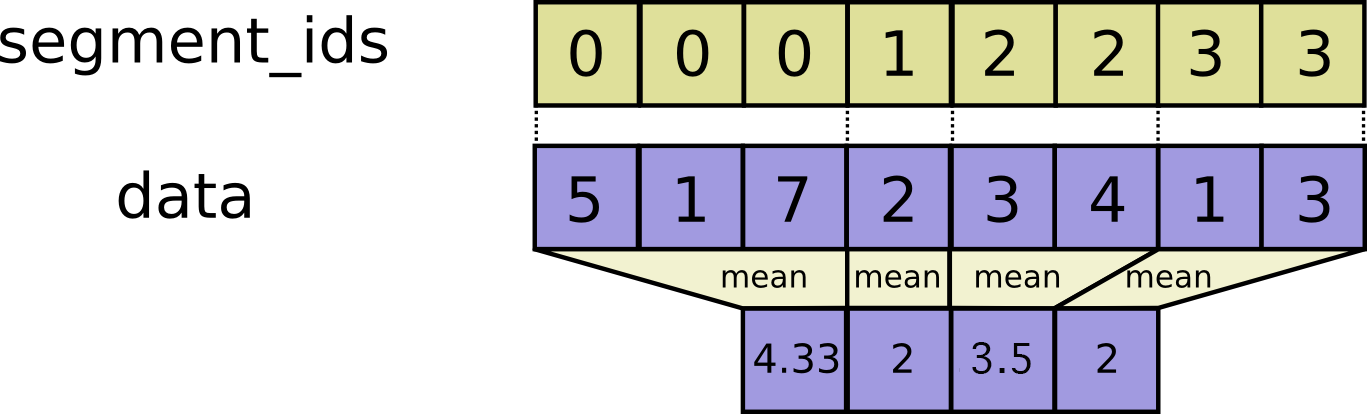{kind=link}
Arguments:
segment_ids: A 1-D tensor whose rank is equal to the rank of `data`'s
first dimension. Values should be sorted and can be repeated.
Returns Has same shape as data, except for dimension 0 which has size `k`, the number of segments.
func SegmentMin ¶ added in v1.1.0
Computes the minimum along segments of a tensor.
Read @{$math_ops#segmentation$the section on segmentation} for an explanation of segments.
Computes a tensor such that \\(output_i = \min_j(data_j)\\) where `min` is over `j` such that `segment_ids[j] == i`.
If the min is empty for a given segment ID `i`, `output[i] = 0`.
<div style="width:70%; margin:auto; margin-bottom:10px; margin-top:20px;"> <img style="width:100%" src="https://www.tensorflow.org/images/SegmentMin.png" alt> </div>
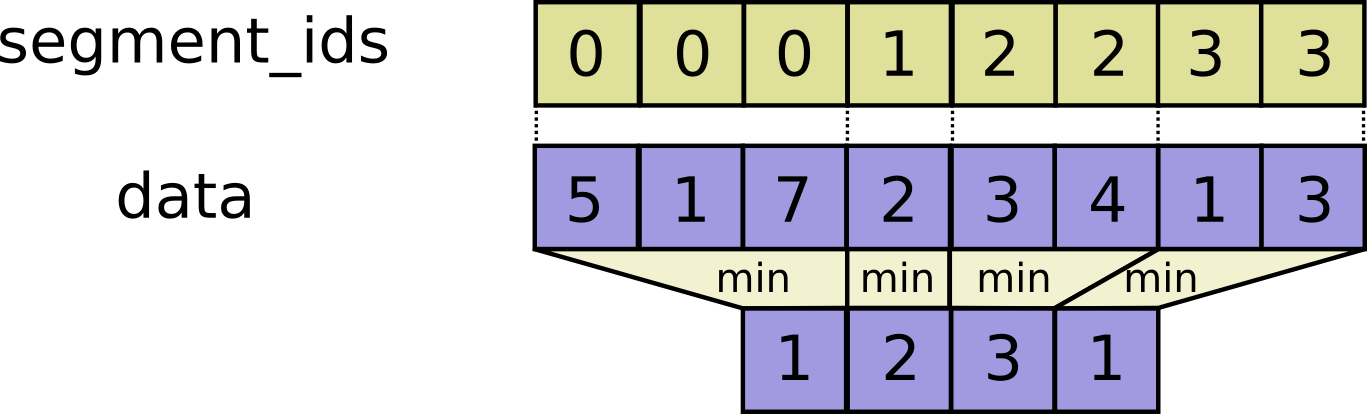{kind=link}
Arguments:
segment_ids: A 1-D tensor whose rank is equal to the rank of `data`'s
first dimension. Values should be sorted and can be repeated.
Returns Has same shape as data, except for dimension 0 which has size `k`, the number of segments.
func SegmentProd ¶ added in v1.1.0
Computes the product along segments of a tensor.
Read @{$math_ops#segmentation$the section on segmentation} for an explanation of segments.
Computes a tensor such that \\(output_i = \prod_j data_j\\) where the product is over `j` such that `segment_ids[j] == i`.
If the product is empty for a given segment ID `i`, `output[i] = 1`.
<div style="width:70%; margin:auto; margin-bottom:10px; margin-top:20px;"> <img style="width:100%" src="https://www.tensorflow.org/images/SegmentProd.png" alt> </div>
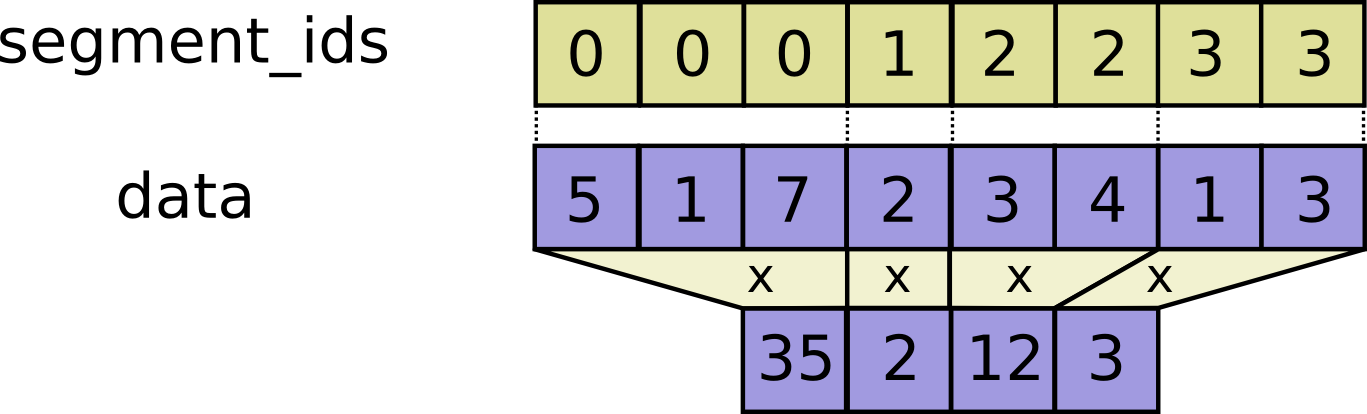{kind=link}
Arguments:
segment_ids: A 1-D tensor whose rank is equal to the rank of `data`'s
first dimension. Values should be sorted and can be repeated.
Returns Has same shape as data, except for dimension 0 which has size `k`, the number of segments.
func SegmentSum ¶ added in v1.1.0
Computes the sum along segments of a tensor.
Read @{$math_ops#segmentation$the section on segmentation} for an explanation of segments.
Computes a tensor such that \\(output_i = \sum_j data_j\\) where sum is over `j` such that `segment_ids[j] == i`.
If the sum is empty for a given segment ID `i`, `output[i] = 0`.
<div style="width:70%; margin:auto; margin-bottom:10px; margin-top:20px;"> <img style="width:100%" src="https://www.tensorflow.org/images/SegmentSum.png" alt> </div>
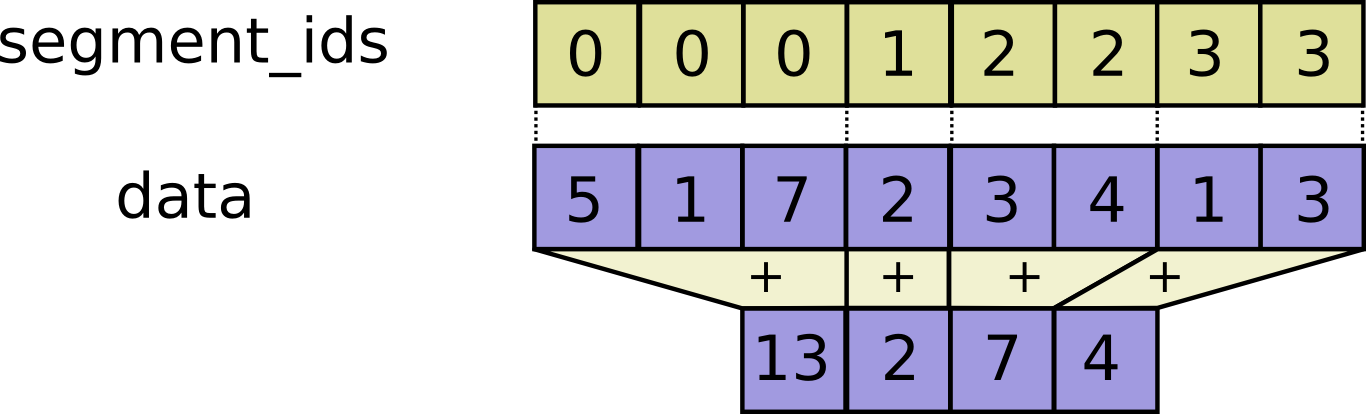{kind=link}
Arguments:
segment_ids: A 1-D tensor whose rank is equal to the rank of `data`'s
first dimension. Values should be sorted and can be repeated.
Returns Has same shape as data, except for dimension 0 which has size `k`, the number of segments.
func Select ¶ added in v1.1.0
Selects elements from `x` or `y`, depending on `condition`.
The `x`, and `y` tensors must all have the same shape, and the output will also have that shape.
The `condition` tensor must be a scalar if `x` and `y` are scalars. If `x` and `y` are vectors or higher rank, then `condition` must be either a scalar, a vector with size matching the first dimension of `x`, or must have the same shape as `x`.
The `condition` tensor acts as a mask that chooses, based on the value at each element, whether the corresponding element / row in the output should be taken from `x` (if true) or `y` (if false).
If `condition` is a vector and `x` and `y` are higher rank matrices, then it chooses which row (outer dimension) to copy from `x` and `y`. If `condition` has the same shape as `x` and `y`, then it chooses which element to copy from `x` and `y`.
For example:
```python # 'condition' tensor is [[True, False] # [False, True]] # 't' is [[1, 2], # [3, 4]] # 'e' is [[5, 6], # [7, 8]] select(condition, t, e) # => [[1, 6], [7, 4]]
# 'condition' tensor is [True, False] # 't' is [[1, 2], # [3, 4]] # 'e' is [[5, 6], # [7, 8]] select(condition, t, e) ==> [[1, 2],
[7, 8]]
```
Arguments:
x: = A `Tensor` which may have the same shape as `condition`.
If `condition` is rank 1, `x` may have higher rank, but its first dimension must match the size of `condition`.
y: = A `Tensor` with the same type and shape as `x`.
Returns = A `Tensor` with the same type and shape as `x` and `y`.
func SelfAdjointEig ¶ added in v1.1.0
Computes the Eigen Decomposition of a batch of square self-adjoint matrices.
DEPRECATED at GraphDef version 11: Use SelfAdjointEigV2 instead.
The input is a tensor of shape `[..., M, M]` whose inner-most 2 dimensions form square matrices, with the same constraints as the single matrix SelfAdjointEig.
The result is a [..., M+1, M] matrix with [..., 0,:] containing the eigenvalues, and subsequent [...,1:, :] containing the eigenvectors.
Arguments:
input: Shape is `[..., M, M]`.
Returns Shape is `[..., M+1, M]`.
func SelfAdjointEigV2 ¶ added in v1.1.0
func SelfAdjointEigV2(scope *Scope, input tf.Output, optional ...SelfAdjointEigV2Attr) (e tf.Output, v tf.Output)
Computes the eigen decomposition of one or more square self-adjoint matrices.
Computes the eigenvalues and (optionally) eigenvectors of each inner matrix in `input` such that `input[..., :, :] = v[..., :, :] * diag(e[..., :])`.
```python # a is a tensor. # e is a tensor of eigenvalues. # v is a tensor of eigenvectors. e, v = self_adjoint_eig(a) e = self_adjoint_eig(a, compute_v=False) ```
Arguments:
input: `Tensor` input of shape `[N, N]`.
Returns Eigenvalues. Shape is `[N]`.Eigenvectors. Shape is `[N, N]`.
func Selu ¶ added in v1.4.0
Computes scaled exponential linear: `scale * alpha * (exp(features) - 1)`
if < 0, `scale * features` otherwise.
See [Self-Normalizing Neural Networks](https://arxiv.org/abs/1706.02515)
func SeluGrad ¶ added in v1.4.0
Computes gradients for the scaled exponential linear (Selu) operation.
Arguments:
gradients: The backpropagated gradients to the corresponding Selu operation. outputs: The outputs of the corresponding Selu operation.
Returns The gradients: `gradients * (outputs + scale * alpha)` if outputs < 0, `scale * gradients` otherwise.
func SerializeIterator ¶ added in v1.5.0
Converts the given `resource_handle` representing an iterator to a variant tensor.
Arguments:
resource_handle: A handle to an iterator resource.
Returns A variant tensor storing the state of the iterator contained in the resource.
func SerializeManySparse ¶ added in v1.1.0
func SerializeManySparse(scope *Scope, sparse_indices tf.Output, sparse_values tf.Output, sparse_shape tf.Output, optional ...SerializeManySparseAttr) (serialized_sparse tf.Output)
Serialize an `N`-minibatch `SparseTensor` into an `[N, 3]` `Tensor` object.
The `SparseTensor` must have rank `R` greater than 1, and the first dimension is treated as the minibatch dimension. Elements of the `SparseTensor` must be sorted in increasing order of this first dimension. The serialized `SparseTensor` objects going into each row of `serialized_sparse` will have rank `R-1`.
The minibatch size `N` is extracted from `sparse_shape[0]`.
Arguments:
sparse_indices: 2-D. The `indices` of the minibatch `SparseTensor`. sparse_values: 1-D. The `values` of the minibatch `SparseTensor`. sparse_shape: 1-D. The `shape` of the minibatch `SparseTensor`.
func SerializeSparse ¶ added in v1.1.0
func SerializeSparse(scope *Scope, sparse_indices tf.Output, sparse_values tf.Output, sparse_shape tf.Output, optional ...SerializeSparseAttr) (serialized_sparse tf.Output)
Serialize a `SparseTensor` into a `[3]` `Tensor` object.
Arguments:
sparse_indices: 2-D. The `indices` of the `SparseTensor`. sparse_values: 1-D. The `values` of the `SparseTensor`. sparse_shape: 1-D. The `shape` of the `SparseTensor`.
func SerializeTensor ¶ added in v1.4.0
Transforms a Tensor into a serialized TensorProto proto.
Arguments:
tensor: A Tensor of type `T`.
Returns A serialized TensorProto proto of the input tensor.
func SetSize ¶ added in v1.1.0
func SetSize(scope *Scope, set_indices tf.Output, set_values tf.Output, set_shape tf.Output, optional ...SetSizeAttr) (size tf.Output)
Number of unique elements along last dimension of input `set`.
Input `set` is a `SparseTensor` represented by `set_indices`, `set_values`, and `set_shape`. The last dimension contains values in a set, duplicates are allowed but ignored.
If `validate_indices` is `True`, this op validates the order and range of `set` indices.
Arguments:
set_indices: 2D `Tensor`, indices of a `SparseTensor`. set_values: 1D `Tensor`, values of a `SparseTensor`. set_shape: 1D `Tensor`, shape of a `SparseTensor`.
Returns For `set` ranked `n`, this is a `Tensor` with rank `n-1`, and the same 1st `n-1` dimensions as `set`. Each value is the number of unique elements in the corresponding `[0...n-1]` dimension of `set`.
func Shape ¶ added in v1.1.0
Returns the shape of a tensor.
This operation returns a 1-D integer tensor representing the shape of `input`.
For example:
``` # 't' is [[[1, 1, 1], [2, 2, 2]], [[3, 3, 3], [4, 4, 4]]] shape(t) ==> [2, 2, 3] ```
func ShapeN ¶ added in v1.1.0
Returns shape of tensors.
This operation returns N 1-D integer tensors representing shape of `input[i]s`.
func ShardedFilename ¶ added in v1.1.0
func ShardedFilename(scope *Scope, basename tf.Output, shard tf.Output, num_shards tf.Output) (filename tf.Output)
Generate a sharded filename. The filename is printf formatted as
%s-%05d-of-%05d, basename, shard, num_shards.
func ShardedFilespec ¶ added in v1.1.0
Generate a glob pattern matching all sharded file names.
func ShuffleAndRepeatDataset ¶ added in v1.6.0
func ShuffleAndRepeatDataset(scope *Scope, input_dataset tf.Output, buffer_size tf.Output, seed tf.Output, seed2 tf.Output, count tf.Output, output_types []tf.DataType, output_shapes []tf.Shape) (handle tf.Output)
Creates a dataset that shuffles and repeats elements from `input_dataset`
pseudorandomly.
Arguments:
buffer_size: The number of output elements to buffer in an iterator over
this dataset. Compare with the `min_after_dequeue` attr when creating a `RandomShuffleQueue`.
seed: A scalar seed for the random number generator. If either `seed` or
`seed2` is set to be non-zero, the random number generator is seeded by the given seed. Otherwise, a random seed is used.
seed2: A second scalar seed to avoid seed collision. count: A scalar representing the number of times the underlying dataset
should be repeated. The default is `-1`, which results in infinite repetition.
func ShuffleDataset ¶ added in v1.2.0
func ShuffleDataset(scope *Scope, input_dataset tf.Output, buffer_size tf.Output, seed tf.Output, seed2 tf.Output, output_types []tf.DataType, output_shapes []tf.Shape, optional ...ShuffleDatasetAttr) (handle tf.Output)
Creates a dataset that shuffles elements from `input_dataset` pseudorandomly.
Arguments:
buffer_size: The number of output elements to buffer in an iterator over
this dataset. Compare with the `min_after_dequeue` attr when creating a `RandomShuffleQueue`.
seed: A scalar seed for the random number generator. If either `seed` or
`seed2` is set to be non-zero, the random number generator is seeded by the given seed. Otherwise, a random seed is used.
seed2: A second scalar seed to avoid seed collision.
func Sigmoid ¶ added in v1.1.0
Computes sigmoid of `x` element-wise.
Specifically, `y = 1 / (1 + exp(-x))`.
func SigmoidGrad ¶ added in v1.1.0
Computes the gradient of the sigmoid of `x` wrt its input.
Specifically, `grad = dy * y * (1 - y)`, where `y = sigmoid(x)`, and `dy` is the corresponding input gradient.
func Sign ¶ added in v1.1.0
Returns an element-wise indication of the sign of a number.
`y = sign(x) = -1` if `x < 0`; 0 if `x == 0`; 1 if `x > 0`.
For complex numbers, `y = sign(x) = x / |x|` if `x != 0`, otherwise `y = 0`.
func Size ¶ added in v1.1.0
Returns the size of a tensor.
This operation returns an integer representing the number of elements in `input`.
For example:
``` # 't' is [[[1, 1,, 1], [2, 2, 2]], [[3, 3, 3], [4, 4, 4]]]] size(t) ==> 12 ```
func SkipDataset ¶ added in v1.2.0
func SkipDataset(scope *Scope, input_dataset tf.Output, count tf.Output, output_types []tf.DataType, output_shapes []tf.Shape) (handle tf.Output)
Creates a dataset that skips `count` elements from the `input_dataset`.
Arguments:
count: A scalar representing the number of elements from the `input_dataset`
that should be skipped. If count is -1, skips everything.
func Skipgram ¶ added in v1.1.0
func Skipgram(scope *Scope, filename string, batch_size int64, optional ...SkipgramAttr) (vocab_word tf.Output, vocab_freq tf.Output, words_per_epoch tf.Output, current_epoch tf.Output, total_words_processed tf.Output, examples tf.Output, labels tf.Output)
Parses a text file and creates a batch of examples.
DEPRECATED at GraphDef version 19: Moving word2vec into tensorflow_models/tutorials and deprecating its ops here as a result
Arguments:
filename: The corpus's text file name. batch_size: The size of produced batch.
Returns A vector of words in the corpus.Frequencies of words. Sorted in the non-ascending order.Number of words per epoch in the data file.The current epoch number.The total number of words processed so far.A vector of word ids.A vector of word ids.
func Slice ¶ added in v1.1.0
Return a slice from 'input'.
The output tensor is a tensor with dimensions described by 'size' whose values are extracted from 'input' starting at the offsets in 'begin'.
*Requirements*:
0 <= begin[i] <= begin[i] + size[i] <= Di for i in [0, n)
Arguments:
begin: begin[i] specifies the offset into the 'i'th dimension of
'input' to slice from.
size: size[i] specifies the number of elements of the 'i'th dimension
of 'input' to slice. If size[i] is -1, all remaining elements in dimension i are included in the slice (i.e. this is equivalent to setting size[i] = input.dim_size(i) - begin[i]).
func Softmax ¶ added in v1.1.0
Computes softmax activations.
For each batch `i` and class `j` we have
softmax[i, j] = exp(logits[i, j]) / sum_j(exp(logits[i, j]))
Arguments:
logits: 2-D with shape `[batch_size, num_classes]`.
Returns Same shape as `logits`.
func SoftmaxCrossEntropyWithLogits ¶ added in v1.1.0
func SoftmaxCrossEntropyWithLogits(scope *Scope, features tf.Output, labels tf.Output) (loss tf.Output, backprop tf.Output)
Computes softmax cross entropy cost and gradients to backpropagate.
Inputs are the logits, not probabilities.
Arguments:
features: batch_size x num_classes matrix labels: batch_size x num_classes matrix
The caller must ensure that each batch of labels represents a valid probability distribution.
Returns Per example loss (batch_size vector).backpropagated gradients (batch_size x num_classes matrix).
func SoftplusGrad ¶ added in v1.1.0
Computes softplus gradients for a softplus operation.
Arguments:
gradients: The backpropagated gradients to the corresponding softplus operation. features: The features passed as input to the corresponding softplus operation.
Returns The gradients: `gradients / (1 + exp(-features))`.
func SoftsignGrad ¶ added in v1.1.0
Computes softsign gradients for a softsign operation.
Arguments:
gradients: The backpropagated gradients to the corresponding softsign operation. features: The features passed as input to the corresponding softsign operation.
Returns The gradients: `gradients / (1 + abs(features)) ** 2`.
func SpaceToBatch ¶ added in v1.1.0
func SpaceToBatch(scope *Scope, input tf.Output, paddings tf.Output, block_size int64) (output tf.Output)
SpaceToBatch for 4-D tensors of type T.
This is a legacy version of the more general SpaceToBatchND.
Zero-pads and then rearranges (permutes) blocks of spatial data into batch. More specifically, this op outputs a copy of the input tensor where values from the `height` and `width` dimensions are moved to the `batch` dimension. After the zero-padding, both `height` and `width` of the input must be divisible by the block size.
Arguments:
input: 4-D with shape `[batch, height, width, depth]`.
paddings: 2-D tensor of non-negative integers with shape `[2, 2]`. It specifies
the padding of the input with zeros across the spatial dimensions as follows:
paddings = [[pad_top, pad_bottom], [pad_left, pad_right]]
The effective spatial dimensions of the zero-padded input tensor will be:
height_pad = pad_top + height + pad_bottom
width_pad = pad_left + width + pad_right
The attr `block_size` must be greater than one. It indicates the block size.
- Non-overlapping blocks of size `block_size x block size` in the height and width dimensions are rearranged into the batch dimension at each location.
- The batch of the output tensor is `batch * block_size * block_size`.
- Both height_pad and width_pad must be divisible by block_size.
The shape of the output will be:
[batch*block_size*block_size, height_pad/block_size, width_pad/block_size, depth]
Some examples:
(1) For the following input of shape `[1, 2, 2, 1]` and block_size of 2:
``` x = [[[[1], [2]], [[3], [4]]]] ```
The output tensor has shape `[4, 1, 1, 1]` and value:
``` [[[[1]]], [[[2]]], [[[3]]], [[[4]]]] ```
(2) For the following input of shape `[1, 2, 2, 3]` and block_size of 2:
``` x = [[[[1, 2, 3], [4, 5, 6]],
[[7, 8, 9], [10, 11, 12]]]]
```
The output tensor has shape `[4, 1, 1, 3]` and value:
``` [[[1, 2, 3]], [[4, 5, 6]], [[7, 8, 9]], [[10, 11, 12]]] ```
(3) For the following input of shape `[1, 4, 4, 1]` and block_size of 2:
``` x = [[[[1], [2], [3], [4]],
[[5], [6], [7], [8]], [[9], [10], [11], [12]], [[13], [14], [15], [16]]]]
```
The output tensor has shape `[4, 2, 2, 1]` and value:
``` x = [[[[1], [3]], [[9], [11]]],
[[[2], [4]], [[10], [12]]], [[[5], [7]], [[13], [15]]], [[[6], [8]], [[14], [16]]]]
```
(4) For the following input of shape `[2, 2, 4, 1]` and block_size of 2:
``` x = [[[[1], [2], [3], [4]],
[[5], [6], [7], [8]]], [[[9], [10], [11], [12]], [[13], [14], [15], [16]]]]
```
The output tensor has shape `[8, 1, 2, 1]` and value:
``` x = [[[[1], [3]]], [[[9], [11]]], [[[2], [4]]], [[[10], [12]]],
[[[5], [7]]], [[[13], [15]]], [[[6], [8]]], [[[14], [16]]]]
```
Among others, this operation is useful for reducing atrous convolution into regular convolution.
func SpaceToBatchND ¶ added in v1.1.0
func SpaceToBatchND(scope *Scope, input tf.Output, block_shape tf.Output, paddings tf.Output) (output tf.Output)
SpaceToBatch for N-D tensors of type T.
This operation divides "spatial" dimensions `[1, ..., M]` of the input into a grid of blocks of shape `block_shape`, and interleaves these blocks with the "batch" dimension (0) such that in the output, the spatial dimensions `[1, ..., M]` correspond to the position within the grid, and the batch dimension combines both the position within a spatial block and the original batch position. Prior to division into blocks, the spatial dimensions of the input are optionally zero padded according to `paddings`. See below for a precise description.
Arguments:
input: N-D with shape `input_shape = [batch] + spatial_shape + remaining_shape`,
where spatial_shape has `M` dimensions.
block_shape: 1-D with shape `[M]`, all values must be >= 1. paddings: 2-D with shape `[M, 2]`, all values must be >= 0. `paddings[i] = [pad_start, pad_end]` specifies the padding for input dimension `i + 1`, which corresponds to spatial dimension `i`. It is required that `block_shape[i]` divides `input_shape[i + 1] + pad_start + pad_end`.
This operation is equivalent to the following steps:
- Zero-pad the start and end of dimensions `[1, ..., M]` of the input according to `paddings` to produce `padded` of shape `padded_shape`.
2. Reshape `padded` to `reshaped_padded` of shape:
[batch] + [padded_shape[1] / block_shape[0], block_shape[0], ..., padded_shape[M] / block_shape[M-1], block_shape[M-1]] + remaining_shape
Permute dimensions of `reshaped_padded` to produce `permuted_reshaped_padded` of shape:
block_shape + [batch] + [padded_shape[1] / block_shape[0], ..., padded_shape[M] / block_shape[M-1]] + remaining_shape
Reshape `permuted_reshaped_padded` to flatten `block_shape` into the batch dimension, producing an output tensor of shape:
[batch * prod(block_shape)] + [padded_shape[1] / block_shape[0], ..., padded_shape[M] / block_shape[M-1]] + remaining_shape
Some examples:
(1) For the following input of shape `[1, 2, 2, 1]`, `block_shape = [2, 2]`, and
`paddings = [[0, 0], [0, 0]]`:
``` x = [[[[1], [2]], [[3], [4]]]] ```
The output tensor has shape `[4, 1, 1, 1]` and value:
``` [[[[1]]], [[[2]]], [[[3]]], [[[4]]]] ```
(2) For the following input of shape `[1, 2, 2, 3]`, `block_shape = [2, 2]`, and
`paddings = [[0, 0], [0, 0]]`:
``` x = [[[[1, 2, 3], [4, 5, 6]],
[[7, 8, 9], [10, 11, 12]]]]
```
The output tensor has shape `[4, 1, 1, 3]` and value:
``` [[[1, 2, 3]], [[4, 5, 6]], [[7, 8, 9]], [[10, 11, 12]]] ```
(3) For the following input of shape `[1, 4, 4, 1]`, `block_shape = [2, 2]`, and
`paddings = [[0, 0], [0, 0]]`:
``` x = [[[[1], [2], [3], [4]],
[[5], [6], [7], [8]], [[9], [10], [11], [12]], [[13], [14], [15], [16]]]]
```
The output tensor has shape `[4, 2, 2, 1]` and value:
``` x = [[[[1], [3]], [[9], [11]]],
[[[2], [4]], [[10], [12]]], [[[5], [7]], [[13], [15]]], [[[6], [8]], [[14], [16]]]]
```
(4) For the following input of shape `[2, 2, 4, 1]`, block_shape = `[2, 2]`, and
paddings = `[[0, 0], [2, 0]]`:
``` x = [[[[1], [2], [3], [4]],
[[5], [6], [7], [8]]], [[[9], [10], [11], [12]], [[13], [14], [15], [16]]]]
```
The output tensor has shape `[8, 1, 3, 1]` and value:
``` x = [[[[0], [1], [3]]], [[[0], [9], [11]]],
[[[0], [2], [4]]], [[[0], [10], [12]]], [[[0], [5], [7]]], [[[0], [13], [15]]], [[[0], [6], [8]]], [[[0], [14], [16]]]]
```
Among others, this operation is useful for reducing atrous convolution into regular convolution.
func SpaceToDepth ¶ added in v1.1.0
func SpaceToDepth(scope *Scope, input tf.Output, block_size int64, optional ...SpaceToDepthAttr) (output tf.Output)
SpaceToDepth for tensors of type T.
Rearranges blocks of spatial data, into depth. More specifically, this op outputs a copy of the input tensor where values from the `height` and `width` dimensions are moved to the `depth` dimension. The attr `block_size` indicates the input block size.
- Non-overlapping blocks of size `block_size x block size` are rearranged into depth at each location.
- The depth of the output tensor is `block_size * block_size * input_depth`.
- The Y, X coordinates within each block of the input become the high order component of the output channel index.
- The input tensor's height and width must be divisible by block_size.
The `data_format` attr specifies the layout of the input and output tensors with the following options:
"NHWC": `[ batch, height, width, channels ]`
"NCHW": `[ batch, channels, height, width ]`
"NCHW_VECT_C":
`qint8 [ batch, channels / 4, height, width, 4 ]`
It is useful to consider the operation as transforming a 6-D Tensor. e.g. for data_format = NHWC,
Each element in the input tensor can be specified via 6 coordinates,
ordered by decreasing memory layout significance as:
n,oY,bY,oX,bX,iC (where n=batch index, oX, oY means X or Y coordinates
within the output image, bX, bY means coordinates
within the input block, iC means input channels).
The output would be a transpose to the following layout:
n,oY,oX,bY,bX,iC
This operation is useful for resizing the activations between convolutions (but keeping all data), e.g. instead of pooling. It is also useful for training purely convolutional models.
For example, given an input of shape `[1, 2, 2, 1]`, data_format = "NHWC" and block_size = 2:
``` x = [[[[1], [2]],
[[3], [4]]]]
```
This operation will output a tensor of shape `[1, 1, 1, 4]`:
``` [[[[1, 2, 3, 4]]]] ```
Here, the input has a batch of 1 and each batch element has shape `[2, 2, 1]`, the corresponding output will have a single element (i.e. width and height are both 1) and will have a depth of 4 channels (1 * block_size * block_size). The output element shape is `[1, 1, 4]`.
For an input tensor with larger depth, here of shape `[1, 2, 2, 3]`, e.g.
``` x = [[[[1, 2, 3], [4, 5, 6]],
[[7, 8, 9], [10, 11, 12]]]]
```
This operation, for block_size of 2, will return the following tensor of shape `[1, 1, 1, 12]`
``` [[[[1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12]]]] ```
Similarly, for the following input of shape `[1 4 4 1]`, and a block size of 2:
``` x = [[[[1], [2], [5], [6]],
[[3], [4], [7], [8]], [[9], [10], [13], [14]], [[11], [12], [15], [16]]]]
```
the operator will return the following tensor of shape `[1 2 2 4]`:
``` x = [[[[1, 2, 3, 4],
[5, 6, 7, 8]], [[9, 10, 11, 12], [13, 14, 15, 16]]]]
```
Arguments:
block_size: The size of the spatial block.
func SparseAdd ¶ added in v1.1.0
func SparseAdd(scope *Scope, a_indices tf.Output, a_values tf.Output, a_shape tf.Output, b_indices tf.Output, b_values tf.Output, b_shape tf.Output, thresh tf.Output) (sum_indices tf.Output, sum_values tf.Output, sum_shape tf.Output)
Adds two `SparseTensor` objects to produce another `SparseTensor`.
The input `SparseTensor` objects' indices are assumed ordered in standard lexicographic order. If this is not the case, before this step run `SparseReorder` to restore index ordering.
By default, if two values sum to zero at some index, the output `SparseTensor` would still include that particular location in its index, storing a zero in the corresponding value slot. To override this, callers can specify `thresh`, indicating that if the sum has a magnitude strictly smaller than `thresh`, its corresponding value and index would then not be included. In particular, `thresh == 0` (default) means everything is kept and actual thresholding happens only for a positive value.
In the following shapes, `nnz` is the count after taking `thresh` into account.
Arguments:
a_indices: 2-D. The `indices` of the first `SparseTensor`, size `[nnz, ndims]` Matrix. a_values: 1-D. The `values` of the first `SparseTensor`, size `[nnz]` Vector. a_shape: 1-D. The `shape` of the first `SparseTensor`, size `[ndims]` Vector. b_indices: 2-D. The `indices` of the second `SparseTensor`, size `[nnz, ndims]` Matrix. b_values: 1-D. The `values` of the second `SparseTensor`, size `[nnz]` Vector. b_shape: 1-D. The `shape` of the second `SparseTensor`, size `[ndims]` Vector. thresh: 0-D. The magnitude threshold that determines if an output value/index
pair takes space.
func SparseAddGrad ¶ added in v1.1.0
func SparseAddGrad(scope *Scope, backprop_val_grad tf.Output, a_indices tf.Output, b_indices tf.Output, sum_indices tf.Output) (a_val_grad tf.Output, b_val_grad tf.Output)
The gradient operator for the SparseAdd op.
The SparseAdd op calculates A + B, where A, B, and the sum are all represented as `SparseTensor` objects. This op takes in the upstream gradient w.r.t. non-empty values of the sum, and outputs the gradients w.r.t. the non-empty values of A and B.
Arguments:
backprop_val_grad: 1-D with shape `[nnz(sum)]`. The gradient with respect to
the non-empty values of the sum.
a_indices: 2-D. The `indices` of the `SparseTensor` A, size `[nnz(A), ndims]`. b_indices: 2-D. The `indices` of the `SparseTensor` B, size `[nnz(B), ndims]`. sum_indices: 2-D. The `indices` of the sum `SparseTensor`, size
`[nnz(sum), ndims]`.
Returns 1-D with shape `[nnz(A)]`. The gradient with respect to the non-empty values of A.1-D with shape `[nnz(B)]`. The gradient with respect to the non-empty values of B.
func SparseConcat ¶ added in v1.1.0
func SparseConcat(scope *Scope, indices []tf.Output, values []tf.Output, shapes []tf.Output, concat_dim int64) (output_indices tf.Output, output_values tf.Output, output_shape tf.Output)
Concatenates a list of `SparseTensor` along the specified dimension.
Concatenation is with respect to the dense versions of these sparse tensors. It is assumed that each input is a `SparseTensor` whose elements are ordered along increasing dimension number.
All inputs' shapes must match, except for the concat dimension. The `indices`, `values`, and `shapes` lists must have the same length.
The output shape is identical to the inputs', except along the concat dimension, where it is the sum of the inputs' sizes along that dimension.
The output elements will be resorted to preserve the sort order along increasing dimension number.
This op runs in `O(M log M)` time, where `M` is the total number of non-empty values across all inputs. This is due to the need for an internal sort in order to concatenate efficiently across an arbitrary dimension.
For example, if `concat_dim = 1` and the inputs are
sp_inputs[0]: shape = [2, 3] [0, 2]: "a" [1, 0]: "b" [1, 1]: "c" sp_inputs[1]: shape = [2, 4] [0, 1]: "d" [0, 2]: "e"
then the output will be
shape = [2, 7] [0, 2]: "a" [0, 4]: "d" [0, 5]: "e" [1, 0]: "b" [1, 1]: "c"
Graphically this is equivalent to doing
[ a] concat [ d e ] = [ a d e ] [b c ] [ ] [b c ]
Arguments:
indices: 2-D. Indices of each input `SparseTensor`. values: 1-D. Non-empty values of each `SparseTensor`. shapes: 1-D. Shapes of each `SparseTensor`. concat_dim: Dimension to concatenate along. Must be in range [-rank, rank),
where rank is the number of dimensions in each input `SparseTensor`.
Returns 2-D. Indices of the concatenated `SparseTensor`.1-D. Non-empty values of the concatenated `SparseTensor`.1-D. Shape of the concatenated `SparseTensor`.
func SparseCross ¶ added in v1.2.0
func SparseCross(scope *Scope, indices []tf.Output, values []tf.Output, shapes []tf.Output, dense_inputs []tf.Output, hashed_output bool, num_buckets int64, hash_key int64, out_type tf.DataType, internal_type tf.DataType) (output_indices tf.Output, output_values tf.Output, output_shape tf.Output)
Generates sparse cross from a list of sparse and dense tensors.
The op takes two lists, one of 2D `SparseTensor` and one of 2D `Tensor`, each representing features of one feature column. It outputs a 2D `SparseTensor` with the batchwise crosses of these features.
For example, if the inputs are
inputs[0]: SparseTensor with shape = [2, 2] [0, 0]: "a" [1, 0]: "b" [1, 1]: "c" inputs[1]: SparseTensor with shape = [2, 1] [0, 0]: "d" [1, 0]: "e" inputs[2]: Tensor [["f"], ["g"]]
then the output will be
shape = [2, 2] [0, 0]: "a_X_d_X_f" [1, 0]: "b_X_e_X_g" [1, 1]: "c_X_e_X_g"
if hashed_output=true then the output will be
shape = [2, 2]
[0, 0]: FingerprintCat64(
Fingerprint64("f"), FingerprintCat64(
Fingerprint64("d"), Fingerprint64("a")))
[1, 0]: FingerprintCat64(
Fingerprint64("g"), FingerprintCat64(
Fingerprint64("e"), Fingerprint64("b")))
[1, 1]: FingerprintCat64(
Fingerprint64("g"), FingerprintCat64(
Fingerprint64("e"), Fingerprint64("c")))
Arguments:
indices: 2-D. Indices of each input `SparseTensor`. values: 1-D. values of each `SparseTensor`. shapes: 1-D. Shapes of each `SparseTensor`. dense_inputs: 2-D. Columns represented by dense `Tensor`. hashed_output: If true, returns the hash of the cross instead of the string.
This will allow us avoiding string manipulations.
num_buckets: It is used if hashed_output is true.
output = hashed_value%num_buckets if num_buckets > 0 else hashed_value.
hash_key: Specify the hash_key that will be used by the `FingerprintCat64`
function to combine the crosses fingerprints.
Returns 2-D. Indices of the concatenated `SparseTensor`.1-D. Non-empty values of the concatenated or hashed `SparseTensor`.1-D. Shape of the concatenated `SparseTensor`.
func SparseDenseCwiseAdd ¶ added in v1.1.0
func SparseDenseCwiseAdd(scope *Scope, sp_indices tf.Output, sp_values tf.Output, sp_shape tf.Output, dense tf.Output) (output tf.Output)
Adds up a SparseTensor and a dense Tensor, using these special rules:
(1) Broadcasts the dense side to have the same shape as the sparse side, if
eligible;
(2) Then, only the dense values pointed to by the indices of the SparseTensor
participate in the cwise addition.
By these rules, the result is a logical SparseTensor with exactly the same indices and shape, but possibly with different non-zero values. The output of this Op is the resultant non-zero values.
Arguments:
sp_indices: 2-D. `N x R` matrix with the indices of non-empty values in a
SparseTensor, possibly not in canonical ordering.
sp_values: 1-D. `N` non-empty values corresponding to `sp_indices`. sp_shape: 1-D. Shape of the input SparseTensor. dense: `R`-D. The dense Tensor operand.
Returns 1-D. The `N` values that are operated on.
func SparseDenseCwiseDiv ¶ added in v1.1.0
func SparseDenseCwiseDiv(scope *Scope, sp_indices tf.Output, sp_values tf.Output, sp_shape tf.Output, dense tf.Output) (output tf.Output)
Component-wise divides a SparseTensor by a dense Tensor.
*Limitation*: this Op only broadcasts the dense side to the sparse side, but not the other direction.
Arguments:
sp_indices: 2-D. `N x R` matrix with the indices of non-empty values in a
SparseTensor, possibly not in canonical ordering.
sp_values: 1-D. `N` non-empty values corresponding to `sp_indices`. sp_shape: 1-D. Shape of the input SparseTensor. dense: `R`-D. The dense Tensor operand.
Returns 1-D. The `N` values that are operated on.
func SparseDenseCwiseMul ¶ added in v1.1.0
func SparseDenseCwiseMul(scope *Scope, sp_indices tf.Output, sp_values tf.Output, sp_shape tf.Output, dense tf.Output) (output tf.Output)
Component-wise multiplies a SparseTensor by a dense Tensor.
The output locations corresponding to the implicitly zero elements in the sparse tensor will be zero (i.e., will not take up storage space), regardless of the contents of the dense tensor (even if it's +/-INF and that INF*0 == NaN).
*Limitation*: this Op only broadcasts the dense side to the sparse side, but not the other direction.
Arguments:
sp_indices: 2-D. `N x R` matrix with the indices of non-empty values in a
SparseTensor, possibly not in canonical ordering.
sp_values: 1-D. `N` non-empty values corresponding to `sp_indices`. sp_shape: 1-D. Shape of the input SparseTensor. dense: `R`-D. The dense Tensor operand.
Returns 1-D. The `N` values that are operated on.
func SparseFillEmptyRows ¶ added in v1.3.0
func SparseFillEmptyRows(scope *Scope, indices tf.Output, values tf.Output, dense_shape tf.Output, default_value tf.Output) (output_indices tf.Output, output_values tf.Output, empty_row_indicator tf.Output, reverse_index_map tf.Output)
Fills empty rows in the input 2-D `SparseTensor` with a default value.
The input `SparseTensor` is represented via the tuple of inputs (`indices`, `values`, `dense_shape`). The output `SparseTensor` has the same `dense_shape` but with indices `output_indices` and values `output_values`.
This op inserts a single entry for every row that doesn't have any values. The index is created as `[row, 0, ..., 0]` and the inserted value is `default_value`.
For example, suppose `sp_input` has shape `[5, 6]` and non-empty values:
[0, 1]: a [0, 3]: b [2, 0]: c [3, 1]: d
Rows 1 and 4 are empty, so the output will be of shape `[5, 6]` with values:
[0, 1]: a [0, 3]: b [1, 0]: default_value [2, 0]: c [3, 1]: d [4, 0]: default_value
The output `SparseTensor` will be in row-major order and will have the same shape as the input.
This op also returns an indicator vector shaped `[dense_shape[0]]` such that
empty_row_indicator[i] = True iff row i was an empty row.
And a reverse index map vector shaped `[indices.shape[0]]` that is used during backpropagation,
reverse_index_map[j] = out_j s.t. indices[j, :] == output_indices[out_j, :]
Arguments:
indices: 2-D. the indices of the sparse tensor. values: 1-D. the values of the sparse tensor. dense_shape: 1-D. the shape of the sparse tensor. default_value: 0-D. default value to insert into location `[row, 0, ..., 0]` for rows missing from the input sparse tensor.
output indices: 2-D. the indices of the filled sparse tensor.
Returns 1-D. the values of the filled sparse tensor.1-D. whether the dense row was missing in the input sparse tensor.1-D. a map from the input indices to the output indices.
func SparseFillEmptyRowsGrad ¶ added in v1.3.0
func SparseFillEmptyRowsGrad(scope *Scope, reverse_index_map tf.Output, grad_values tf.Output) (d_values tf.Output, d_default_value tf.Output)
The gradient of SparseFillEmptyRows.
Takes vectors reverse_index_map, shaped `[N]`, and grad_values, shaped `[N_full]`, where `N_full >= N` and copies data into either `d_values` or `d_default_value`. Here `d_values` is shaped `[N]` and `d_default_value` is a scalar.
d_values[j] = grad_values[reverse_index_map[j]]
d_default_value = sum_{k : 0 .. N_full - 1} (
grad_values[k] * 1{k not in reverse_index_map})
Arguments:
reverse_index_map: 1-D. The reverse index map from SparseFillEmptyRows. grad_values: 1-D. The gradients from backprop.
Returns 1-D. The backprop into values.0-D. The backprop into default_value.
func SparseMatMul ¶ added in v1.1.0
func SparseMatMul(scope *Scope, a tf.Output, b tf.Output, optional ...SparseMatMulAttr) (product tf.Output)
Multiply matrix "a" by matrix "b".
The inputs must be two-dimensional matrices and the inner dimension of "a" must match the outer dimension of "b". This op is optimized for the case where at least one of "a" or "b" is sparse. The breakeven for using this versus a dense matrix multiply on one platform was 30% zero values in the sparse matrix.
The gradient computation of this operation will only take advantage of sparsity in the input gradient when that gradient comes from a Relu.
func SparseReduceMax ¶ added in v1.3.0
func SparseReduceMax(scope *Scope, input_indices tf.Output, input_values tf.Output, input_shape tf.Output, reduction_axes tf.Output, optional ...SparseReduceMaxAttr) (output tf.Output)
Computes the max of elements across dimensions of a SparseTensor.
This Op takes a SparseTensor and is the sparse counterpart to `tf.reduce_max()`. In particular, this Op also returns a dense `Tensor` instead of a sparse one.
Reduces `sp_input` along the dimensions given in `reduction_axes`. Unless `keep_dims` is true, the rank of the tensor is reduced by 1 for each entry in `reduction_axes`. If `keep_dims` is true, the reduced dimensions are retained with length 1.
If `reduction_axes` has no entries, all dimensions are reduced, and a tensor with a single element is returned. Additionally, the axes can be negative, which are interpreted according to the indexing rules in Python.
Arguments:
input_indices: 2-D. `N x R` matrix with the indices of non-empty values in a
SparseTensor, possibly not in canonical ordering.
input_values: 1-D. `N` non-empty values corresponding to `input_indices`. input_shape: 1-D. Shape of the input SparseTensor. reduction_axes: 1-D. Length-`K` vector containing the reduction axes.
Returns `R-K`-D. The reduced Tensor.
func SparseReduceMaxSparse ¶ added in v1.3.0
func SparseReduceMaxSparse(scope *Scope, input_indices tf.Output, input_values tf.Output, input_shape tf.Output, reduction_axes tf.Output, optional ...SparseReduceMaxSparseAttr) (output_indices tf.Output, output_values tf.Output, output_shape tf.Output)
Computes the max of elements across dimensions of a SparseTensor.
This Op takes a SparseTensor and is the sparse counterpart to `tf.reduce_max()`. In contrast to SparseReduceMax, this Op returns a SparseTensor.
Reduces `sp_input` along the dimensions given in `reduction_axes`. Unless `keep_dims` is true, the rank of the tensor is reduced by 1 for each entry in `reduction_axes`. If `keep_dims` is true, the reduced dimensions are retained with length 1.
If `reduction_axes` has no entries, all dimensions are reduced, and a tensor with a single element is returned. Additionally, the axes can be negative, which are interpreted according to the indexing rules in Python.
Arguments:
input_indices: 2-D. `N x R` matrix with the indices of non-empty values in a
SparseTensor, possibly not in canonical ordering.
input_values: 1-D. `N` non-empty values corresponding to `input_indices`. input_shape: 1-D. Shape of the input SparseTensor. reduction_axes: 1-D. Length-`K` vector containing the reduction axes.
func SparseReduceSum ¶ added in v1.1.0
func SparseReduceSum(scope *Scope, input_indices tf.Output, input_values tf.Output, input_shape tf.Output, reduction_axes tf.Output, optional ...SparseReduceSumAttr) (output tf.Output)
Computes the sum of elements across dimensions of a SparseTensor.
This Op takes a SparseTensor and is the sparse counterpart to `tf.reduce_sum()`. In particular, this Op also returns a dense `Tensor` instead of a sparse one.
Reduces `sp_input` along the dimensions given in `reduction_axes`. Unless `keep_dims` is true, the rank of the tensor is reduced by 1 for each entry in `reduction_axes`. If `keep_dims` is true, the reduced dimensions are retained with length 1.
If `reduction_axes` has no entries, all dimensions are reduced, and a tensor with a single element is returned. Additionally, the axes can be negative, which are interpreted according to the indexing rules in Python.
Arguments:
input_indices: 2-D. `N x R` matrix with the indices of non-empty values in a
SparseTensor, possibly not in canonical ordering.
input_values: 1-D. `N` non-empty values corresponding to `input_indices`. input_shape: 1-D. Shape of the input SparseTensor. reduction_axes: 1-D. Length-`K` vector containing the reduction axes.
Returns `R-K`-D. The reduced Tensor.
func SparseReduceSumSparse ¶ added in v1.1.0
func SparseReduceSumSparse(scope *Scope, input_indices tf.Output, input_values tf.Output, input_shape tf.Output, reduction_axes tf.Output, optional ...SparseReduceSumSparseAttr) (output_indices tf.Output, output_values tf.Output, output_shape tf.Output)
Computes the sum of elements across dimensions of a SparseTensor.
This Op takes a SparseTensor and is the sparse counterpart to `tf.reduce_sum()`. In contrast to SparseReduceSum, this Op returns a SparseTensor.
Reduces `sp_input` along the dimensions given in `reduction_axes`. Unless `keep_dims` is true, the rank of the tensor is reduced by 1 for each entry in `reduction_axes`. If `keep_dims` is true, the reduced dimensions are retained with length 1.
If `reduction_axes` has no entries, all dimensions are reduced, and a tensor with a single element is returned. Additionally, the axes can be negative, which are interpreted according to the indexing rules in Python.
Arguments:
input_indices: 2-D. `N x R` matrix with the indices of non-empty values in a
SparseTensor, possibly not in canonical ordering.
input_values: 1-D. `N` non-empty values corresponding to `input_indices`. input_shape: 1-D. Shape of the input SparseTensor. reduction_axes: 1-D. Length-`K` vector containing the reduction axes.
func SparseReorder ¶ added in v1.1.0
func SparseReorder(scope *Scope, input_indices tf.Output, input_values tf.Output, input_shape tf.Output) (output_indices tf.Output, output_values tf.Output)
Reorders a SparseTensor into the canonical, row-major ordering.
Note that by convention, all sparse ops preserve the canonical ordering along increasing dimension number. The only time ordering can be violated is during manual manipulation of the indices and values vectors to add entries.
Reordering does not affect the shape of the SparseTensor.
If the tensor has rank `R` and `N` non-empty values, `input_indices` has shape `[N, R]`, input_values has length `N`, and input_shape has length `R`.
Arguments:
input_indices: 2-D. `N x R` matrix with the indices of non-empty values in a
SparseTensor, possibly not in canonical ordering.
input_values: 1-D. `N` non-empty values corresponding to `input_indices`. input_shape: 1-D. Shape of the input SparseTensor.
Returns 2-D. `N x R` matrix with the same indices as input_indices, but in canonical row-major ordering.1-D. `N` non-empty values corresponding to `output_indices`.
func SparseReshape ¶ added in v1.1.0
func SparseReshape(scope *Scope, input_indices tf.Output, input_shape tf.Output, new_shape tf.Output) (output_indices tf.Output, output_shape tf.Output)
Reshapes a SparseTensor to represent values in a new dense shape.
This operation has the same semantics as reshape on the represented dense tensor. The `input_indices` are recomputed based on the requested `new_shape`.
If one component of `new_shape` is the special value -1, the size of that dimension is computed so that the total dense size remains constant. At most one component of `new_shape` can be -1. The number of dense elements implied by `new_shape` must be the same as the number of dense elements originally implied by `input_shape`.
Reshaping does not affect the order of values in the SparseTensor.
If the input tensor has rank `R_in` and `N` non-empty values, and `new_shape` has length `R_out`, then `input_indices` has shape `[N, R_in]`, `input_shape` has length `R_in`, `output_indices` has shape `[N, R_out]`, and `output_shape` has length `R_out`.
Arguments:
input_indices: 2-D. `N x R_in` matrix with the indices of non-empty values in a
SparseTensor.
input_shape: 1-D. `R_in` vector with the input SparseTensor's dense shape. new_shape: 1-D. `R_out` vector with the requested new dense shape.
Returns 2-D. `N x R_out` matrix with the updated indices of non-empty values in the output SparseTensor.1-D. `R_out` vector with the full dense shape of the output SparseTensor. This is the same as `new_shape` but with any -1 dimensions filled in.
func SparseSegmentMean ¶ added in v1.1.0
func SparseSegmentMean(scope *Scope, data tf.Output, indices tf.Output, segment_ids tf.Output) (output tf.Output)
Computes the mean along sparse segments of a tensor.
Read @{$math_ops#segmentation$the section on segmentation} for an explanation of segments.
Like `SegmentMean`, but `segment_ids` can have rank less than `data`'s first dimension, selecting a subset of dimension 0, specified by `indices`.
Arguments:
indices: A 1-D tensor. Has same rank as `segment_ids`. segment_ids: A 1-D tensor. Values should be sorted and can be repeated.
Returns Has same shape as data, except for dimension 0 which has size `k`, the number of segments.
func SparseSegmentMeanGrad ¶ added in v1.1.0
func SparseSegmentMeanGrad(scope *Scope, grad tf.Output, indices tf.Output, segment_ids tf.Output, output_dim0 tf.Output) (output tf.Output)
Computes gradients for SparseSegmentMean.
Returns tensor "output" with same shape as grad, except for dimension 0 whose value is output_dim0.
Arguments:
grad: gradient propagated to the SparseSegmentMean op. indices: indices passed to the corresponding SparseSegmentMean op. segment_ids: segment_ids passed to the corresponding SparseSegmentMean op. output_dim0: dimension 0 of "data" passed to SparseSegmentMean op.
func SparseSegmentMeanWithNumSegments ¶ added in v1.6.0
func SparseSegmentMeanWithNumSegments(scope *Scope, data tf.Output, indices tf.Output, segment_ids tf.Output, num_segments tf.Output) (output tf.Output)
Computes the mean along sparse segments of a tensor.
Like `SparseSegmentMean`, but allows missing ids in `segment_ids`. If an id is misisng, the `output` tensor at that position will be zeroed.
Read @{$math_ops#segmentation$the section on segmentation} for an explanation of segments.
Arguments:
indices: A 1-D tensor. Has same rank as `segment_ids`. segment_ids: A 1-D tensor. Values should be sorted and can be repeated. num_segments: Should equal the number of distinct segment IDs.
Returns Has same shape as data, except for dimension 0 which has size `num_segments`.
func SparseSegmentSqrtN ¶ added in v1.1.0
func SparseSegmentSqrtN(scope *Scope, data tf.Output, indices tf.Output, segment_ids tf.Output) (output tf.Output)
Computes the sum along sparse segments of a tensor divided by the sqrt of N.
N is the size of the segment being reduced.
Read @{$math_ops#segmentation$the section on segmentation} for an explanation of segments.
Arguments:
indices: A 1-D tensor. Has same rank as `segment_ids`. segment_ids: A 1-D tensor. Values should be sorted and can be repeated.
Returns Has same shape as data, except for dimension 0 which has size `k`, the number of segments.
func SparseSegmentSqrtNGrad ¶ added in v1.1.0
func SparseSegmentSqrtNGrad(scope *Scope, grad tf.Output, indices tf.Output, segment_ids tf.Output, output_dim0 tf.Output) (output tf.Output)
Computes gradients for SparseSegmentSqrtN.
Returns tensor "output" with same shape as grad, except for dimension 0 whose value is output_dim0.
Arguments:
grad: gradient propagated to the SparseSegmentSqrtN op. indices: indices passed to the corresponding SparseSegmentSqrtN op. segment_ids: segment_ids passed to the corresponding SparseSegmentSqrtN op. output_dim0: dimension 0 of "data" passed to SparseSegmentSqrtN op.
func SparseSegmentSqrtNWithNumSegments ¶ added in v1.6.0
func SparseSegmentSqrtNWithNumSegments(scope *Scope, data tf.Output, indices tf.Output, segment_ids tf.Output, num_segments tf.Output) (output tf.Output)
Computes the sum along sparse segments of a tensor divided by the sqrt of N.
N is the size of the segment being reduced.
Like `SparseSegmentSqrtN`, but allows missing ids in `segment_ids`. If an id is misisng, the `output` tensor at that position will be zeroed.
Read @{$math_ops#segmentation$the section on segmentation} for an explanation of segments.
Arguments:
indices: A 1-D tensor. Has same rank as `segment_ids`. segment_ids: A 1-D tensor. Values should be sorted and can be repeated. num_segments: Should equal the number of distinct segment IDs.
Returns Has same shape as data, except for dimension 0 which has size `k`, the number of segments.
func SparseSegmentSum ¶ added in v1.1.0
func SparseSegmentSum(scope *Scope, data tf.Output, indices tf.Output, segment_ids tf.Output) (output tf.Output)
Computes the sum along sparse segments of a tensor.
Read @{$math_ops#segmentation$the section on segmentation} for an explanation of segments.
Like `SegmentSum`, but `segment_ids` can have rank less than `data`'s first dimension, selecting a subset of dimension 0, specified by `indices`.
For example:
```python c = tf.constant([[1,2,3,4], [-1,-2,-3,-4], [5,6,7,8]])
# Select two rows, one segment. tf.sparse_segment_sum(c, tf.constant([0, 1]), tf.constant([0, 0])) # => [[0 0 0 0]]
# Select two rows, two segment. tf.sparse_segment_sum(c, tf.constant([0, 1]), tf.constant([0, 1])) # => [[ 1 2 3 4] # [-1 -2 -3 -4]]
# Select all rows, two segments. tf.sparse_segment_sum(c, tf.constant([0, 1, 2]), tf.constant([0, 0, 1])) # => [[0 0 0 0] # [5 6 7 8]]
# Which is equivalent to: tf.segment_sum(c, tf.constant([0, 0, 1])) ```
Arguments:
indices: A 1-D tensor. Has same rank as `segment_ids`. segment_ids: A 1-D tensor. Values should be sorted and can be repeated.
Returns Has same shape as data, except for dimension 0 which has size `k`, the number of segments.
func SparseSegmentSumWithNumSegments ¶ added in v1.6.0
func SparseSegmentSumWithNumSegments(scope *Scope, data tf.Output, indices tf.Output, segment_ids tf.Output, num_segments tf.Output) (output tf.Output)
Computes the sum along sparse segments of a tensor.
Like `SparseSegmentSum`, but allows missing ids in `segment_ids`. If an id is misisng, the `output` tensor at that position will be zeroed.
Read @{$math_ops#segmentation$the section on segmentation} for an explanation of segments.
For example:
```python c = tf.constant([[1,2,3,4], [-1,-2,-3,-4], [5,6,7,8]])
tf.sparse_segment_sum_with_num_segments(
c, tf.constant([0, 1]), tf.constant([0, 0]), num_segments=3)
# => [[0 0 0 0] # [0 0 0 0] # [0 0 0 0]]
tf.sparse_segment_sum_with_num_segments(c,
tf.constant([0, 1]), tf.constant([0, 2], num_segments=4))
# => [[ 1 2 3 4] # [ 0 0 0 0] # [-1 -2 -3 -4] # [ 0 0 0 0]] ```
Arguments:
indices: A 1-D tensor. Has same rank as `segment_ids`. segment_ids: A 1-D tensor. Values should be sorted and can be repeated. num_segments: Should equal the number of distinct segment IDs.
Returns Has same shape as data, except for dimension 0 which has size `num_segments`.
func SparseSlice ¶ added in v1.3.0
func SparseSlice(scope *Scope, indices tf.Output, values tf.Output, shape tf.Output, start tf.Output, size tf.Output) (output_indices tf.Output, output_values tf.Output, output_shape tf.Output)
Slice a `SparseTensor` based on the `start` and `size`.
For example, if the input is
input_tensor = shape = [2, 7] [ a d e ] [b c ]
Graphically the output tensors are:
sparse_slice([0, 0], [2, 4]) = shape = [2, 4] [ a ] [b c ] sparse_slice([0, 4], [2, 3]) = shape = [2, 3] [ d e ] [ ]
Arguments:
indices: 2-D tensor represents the indices of the sparse tensor. values: 1-D tensor represents the values of the sparse tensor. shape: 1-D. tensor represents the shape of the sparse tensor. start: 1-D. tensor represents the start of the slice. size: 1-D. tensor represents the size of the slice.
output indices: A list of 1-D tensors represents the indices of the output sparse tensors.
Returns A list of 1-D tensors represents the values of the output sparse tensors.A list of 1-D tensors represents the shape of the output sparse tensors.
func SparseSoftmax ¶ added in v1.1.0
func SparseSoftmax(scope *Scope, sp_indices tf.Output, sp_values tf.Output, sp_shape tf.Output) (output tf.Output)
Applies softmax to a batched N-D `SparseTensor`.
The inputs represent an N-D SparseTensor with logical shape `[..., B, C]` (where `N >= 2`), and with indices sorted in the canonical lexicographic order.
This op is equivalent to applying the normal `tf.nn.softmax()` to each innermost logical submatrix with shape `[B, C]`, but with the catch that *the implicitly zero elements do not participate*. Specifically, the algorithm is equivalent to the following:
(1) Applies `tf.nn.softmax()` to a densified view of each innermost submatrix
with shape `[B, C]`, along the size-C dimension;
(2) Masks out the original implicitly-zero locations;
(3) Renormalizes the remaining elements.
Hence, the `SparseTensor` result has exactly the same non-zero indices and shape.
Arguments:
sp_indices: 2-D. `NNZ x R` matrix with the indices of non-empty values in a
SparseTensor, in canonical ordering.
sp_values: 1-D. `NNZ` non-empty values corresponding to `sp_indices`. sp_shape: 1-D. Shape of the input SparseTensor.
Returns 1-D. The `NNZ` values for the result `SparseTensor`.
func SparseSoftmaxCrossEntropyWithLogits ¶ added in v1.1.0
func SparseSoftmaxCrossEntropyWithLogits(scope *Scope, features tf.Output, labels tf.Output) (loss tf.Output, backprop tf.Output)
Computes softmax cross entropy cost and gradients to backpropagate.
Unlike `SoftmaxCrossEntropyWithLogits`, this operation does not accept a matrix of label probabilities, but rather a single label per row of features. This label is considered to have probability 1.0 for the given row.
Inputs are the logits, not probabilities.
Arguments:
features: batch_size x num_classes matrix labels: batch_size vector with values in [0, num_classes).
This is the label for the given minibatch entry.
Returns Per example loss (batch_size vector).backpropagated gradients (batch_size x num_classes matrix).
func SparseSparseMaximum ¶ added in v1.1.0
func SparseSparseMaximum(scope *Scope, a_indices tf.Output, a_values tf.Output, a_shape tf.Output, b_indices tf.Output, b_values tf.Output, b_shape tf.Output) (output_indices tf.Output, output_values tf.Output)
Returns the element-wise max of two SparseTensors.
Assumes the two SparseTensors have the same shape, i.e., no broadcasting.
Arguments:
a_indices: 2-D. `N x R` matrix with the indices of non-empty values in a
SparseTensor, in the canonical lexicographic ordering.
a_values: 1-D. `N` non-empty values corresponding to `a_indices`. a_shape: 1-D. Shape of the input SparseTensor. b_indices: counterpart to `a_indices` for the other operand. b_values: counterpart to `a_values` for the other operand; must be of the same dtype. b_shape: counterpart to `a_shape` for the other operand; the two shapes must be equal.
Returns 2-D. The indices of the output SparseTensor.1-D. The values of the output SparseTensor.
func SparseSparseMinimum ¶ added in v1.1.0
func SparseSparseMinimum(scope *Scope, a_indices tf.Output, a_values tf.Output, a_shape tf.Output, b_indices tf.Output, b_values tf.Output, b_shape tf.Output) (output_indices tf.Output, output_values tf.Output)
Returns the element-wise min of two SparseTensors.
Assumes the two SparseTensors have the same shape, i.e., no broadcasting.
Arguments:
a_indices: 2-D. `N x R` matrix with the indices of non-empty values in a
SparseTensor, in the canonical lexicographic ordering.
a_values: 1-D. `N` non-empty values corresponding to `a_indices`. a_shape: 1-D. Shape of the input SparseTensor. b_indices: counterpart to `a_indices` for the other operand. b_values: counterpart to `a_values` for the other operand; must be of the same dtype. b_shape: counterpart to `a_shape` for the other operand; the two shapes must be equal.
Returns 2-D. The indices of the output SparseTensor.1-D. The values of the output SparseTensor.
func SparseSplit ¶ added in v1.1.0
func SparseSplit(scope *Scope, split_dim tf.Output, indices tf.Output, values tf.Output, shape tf.Output, num_split int64) (output_indices []tf.Output, output_values []tf.Output, output_shape []tf.Output)
Split a `SparseTensor` into `num_split` tensors along one dimension.
If the `shape[split_dim]` is not an integer multiple of `num_split`. Slices `[0 : shape[split_dim] % num_split]` gets one extra dimension. For example, if `split_dim = 1` and `num_split = 2` and the input is
input_tensor = shape = [2, 7] [ a d e ] [b c ]
Graphically the output tensors are:
output_tensor[0] = shape = [2, 4] [ a ] [b c ] output_tensor[1] = shape = [2, 3] [ d e ] [ ]
Arguments:
split_dim: 0-D. The dimension along which to split. Must be in the range
`[0, rank(shape))`.
indices: 2-D tensor represents the indices of the sparse tensor. values: 1-D tensor represents the values of the sparse tensor. shape: 1-D. tensor represents the shape of the sparse tensor.
output indices: A list of 1-D tensors represents the indices of the output sparse tensors.
num_split: The number of ways to split.
Returns A list of 1-D tensors represents the values of the output sparse tensors.A list of 1-D tensors represents the shape of the output sparse tensors.
func SparseTensorDenseAdd ¶ added in v1.1.0
func SparseTensorDenseAdd(scope *Scope, a_indices tf.Output, a_values tf.Output, a_shape tf.Output, b tf.Output) (output tf.Output)
Adds up a `SparseTensor` and a dense `Tensor`, producing a dense `Tensor`.
This Op does not require `a_indices` be sorted in standard lexicographic order.
Arguments:
a_indices: 2-D. The `indices` of the `SparseTensor`, with shape `[nnz, ndims]`. a_values: 1-D. The `values` of the `SparseTensor`, with shape `[nnz]`. a_shape: 1-D. The `shape` of the `SparseTensor`, with shape `[ndims]`. b: `ndims`-D Tensor. With shape `a_shape`.
func SparseTensorDenseMatMul ¶ added in v1.1.0
func SparseTensorDenseMatMul(scope *Scope, a_indices tf.Output, a_values tf.Output, a_shape tf.Output, b tf.Output, optional ...SparseTensorDenseMatMulAttr) (product tf.Output)
Multiply SparseTensor (of rank 2) "A" by dense matrix "B".
No validity checking is performed on the indices of A. However, the following input format is recommended for optimal behavior:
if adjoint_a == false:
A should be sorted in lexicographically increasing order. Use SparseReorder if you're not sure.
if adjoint_a == true:
A should be sorted in order of increasing dimension 1 (i.e., "column major" order instead of "row major" order).
Arguments:
a_indices: 2-D. The `indices` of the `SparseTensor`, size `[nnz, 2]` Matrix. a_values: 1-D. The `values` of the `SparseTensor`, size `[nnz]` Vector. a_shape: 1-D. The `shape` of the `SparseTensor`, size `[2]` Vector. b: 2-D. A dense Matrix.
func SparseTensorSliceDataset ¶ added in v1.2.0
func SparseTensorSliceDataset(scope *Scope, indices tf.Output, values tf.Output, dense_shape tf.Output) (handle tf.Output)
Creates a dataset that splits a SparseTensor into elements row-wise.
func SparseToDense ¶ added in v1.1.0
func SparseToDense(scope *Scope, sparse_indices tf.Output, output_shape tf.Output, sparse_values tf.Output, default_value tf.Output, optional ...SparseToDenseAttr) (dense tf.Output)
Converts a sparse representation into a dense tensor.
Builds an array `dense` with shape `output_shape` such that
``` # If sparse_indices is scalar dense[i] = (i == sparse_indices ? sparse_values : default_value)
# If sparse_indices is a vector, then for each i dense[sparse_indices[i]] = sparse_values[i]
# If sparse_indices is an n by d matrix, then for each i in [0, n) dense[sparse_indices[i][0], ..., sparse_indices[i][d-1]] = sparse_values[i] ```
All other values in `dense` are set to `default_value`. If `sparse_values` is a scalar, all sparse indices are set to this single value.
Indices should be sorted in lexicographic order, and indices must not contain any repeats. If `validate_indices` is true, these properties are checked during execution.
Arguments:
sparse_indices: 0-D, 1-D, or 2-D. `sparse_indices[i]` contains the complete
index where `sparse_values[i]` will be placed.
output_shape: 1-D. Shape of the dense output tensor. sparse_values: 1-D. Values corresponding to each row of `sparse_indices`,
or a scalar value to be used for all sparse indices.
default_value: Scalar value to set for indices not specified in
`sparse_indices`.
Returns Dense output tensor of shape `output_shape`.
func SparseToSparseSetOperation ¶ added in v1.1.0
func SparseToSparseSetOperation(scope *Scope, set1_indices tf.Output, set1_values tf.Output, set1_shape tf.Output, set2_indices tf.Output, set2_values tf.Output, set2_shape tf.Output, set_operation string, optional ...SparseToSparseSetOperationAttr) (result_indices tf.Output, result_values tf.Output, result_shape tf.Output)
Applies set operation along last dimension of 2 `SparseTensor` inputs.
See SetOperationOp::SetOperationFromContext for values of `set_operation`.
If `validate_indices` is `True`, `SparseToSparseSetOperation` validates the order and range of `set1` and `set2` indices.
Input `set1` is a `SparseTensor` represented by `set1_indices`, `set1_values`, and `set1_shape`. For `set1` ranked `n`, 1st `n-1` dimensions must be the same as `set2`. Dimension `n` contains values in a set, duplicates are allowed but ignored.
Input `set2` is a `SparseTensor` represented by `set2_indices`, `set2_values`, and `set2_shape`. For `set2` ranked `n`, 1st `n-1` dimensions must be the same as `set1`. Dimension `n` contains values in a set, duplicates are allowed but ignored.
If `validate_indices` is `True`, this op validates the order and range of `set1` and `set2` indices.
Output `result` is a `SparseTensor` represented by `result_indices`, `result_values`, and `result_shape`. For `set1` and `set2` ranked `n`, this has rank `n` and the same 1st `n-1` dimensions as `set1` and `set2`. The `nth` dimension contains the result of `set_operation` applied to the corresponding `[0...n-1]` dimension of `set`.
Arguments:
set1_indices: 2D `Tensor`, indices of a `SparseTensor`. Must be in row-major
order.
set1_values: 1D `Tensor`, values of a `SparseTensor`. Must be in row-major
order.
set1_shape: 1D `Tensor`, shape of a `SparseTensor`. `set1_shape[0...n-1]` must
be the same as `set2_shape[0...n-1]`, `set1_shape[n]` is the max set size across `0...n-1` dimensions.
set2_indices: 2D `Tensor`, indices of a `SparseTensor`. Must be in row-major
order.
set2_values: 1D `Tensor`, values of a `SparseTensor`. Must be in row-major
order.
set2_shape: 1D `Tensor`, shape of a `SparseTensor`. `set2_shape[0...n-1]` must
be the same as `set1_shape[0...n-1]`, `set2_shape[n]` is the max set size across `0...n-1` dimensions.
Returns 2D indices of a `SparseTensor`.1D values of a `SparseTensor`.1D `Tensor` shape of a `SparseTensor`. `result_shape[0...n-1]` is the same as the 1st `n-1` dimensions of `set1` and `set2`, `result_shape[n]` is the max result set size across all `0...n-1` dimensions.
func Split ¶ added in v1.1.0
Splits a tensor into `num_split` tensors along one dimension.
Arguments:
axis: 0-D. The dimension along which to split. Must be in the range
`[-rank(value), rank(value))`.
value: The tensor to split. num_split: The number of ways to split. Must evenly divide
`value.shape[split_dim]`.
Returns They are identically shaped tensors, whose shape matches that of `value` except along `axis`, where their sizes are `values.shape[split_dim] / num_split`.
func SplitV ¶ added in v1.1.0
func SplitV(scope *Scope, value tf.Output, size_splits tf.Output, axis tf.Output, num_split int64) (output []tf.Output)
Splits a tensor into `num_split` tensors along one dimension.
Arguments:
value: The tensor to split. size_splits: list containing the sizes of each output tensor along the split
dimension. Must sum to the dimension of value along split_dim. Can contain one -1 indicating that dimension is to be inferred.
axis: 0-D. The dimension along which to split. Must be in the range
`[-rank(value), rank(value))`.
Returns Tensors whose shape matches that of `value` except along `axis`, where their sizes are `size_splits[i]`.
func SqlDataset ¶ added in v1.4.0
func SqlDataset(scope *Scope, driver_name tf.Output, data_source_name tf.Output, query tf.Output, output_types []tf.DataType, output_shapes []tf.Shape) (handle tf.Output)
Creates a dataset that executes a SQL query and emits rows of the result set.
Arguments:
driver_name: The database type. Currently, the only supported type is 'sqlite'. data_source_name: A connection string to connect to the database. query: A SQL query to execute.
func Sqrt ¶ added in v1.1.0
Computes square root of x element-wise.
I.e., \\(y = \sqrt{x} = x^{1/2}\\).
func SqrtGrad ¶ added in v1.1.0
Computes the gradient for the sqrt of `x` wrt its input.
Specifically, `grad = dy * 0.5 / y`, where `y = sqrt(x)`, and `dy` is the corresponding input gradient.
func SquaredDifference ¶ added in v1.1.0
Returns (x - y)(x - y) element-wise.
*NOTE*: `SquaredDifference` supports broadcasting. More about broadcasting [here](http://docs.scipy.org/doc/numpy/user/basics.broadcasting.html)
func Squeeze ¶ added in v1.1.0
Removes dimensions of size 1 from the shape of a tensor.
Given a tensor `input`, this operation returns a tensor of the same type with all dimensions of size 1 removed. If you don't want to remove all size 1 dimensions, you can remove specific size 1 dimensions by specifying `axis`.
For example:
``` # 't' is a tensor of shape [1, 2, 1, 3, 1, 1] shape(squeeze(t)) ==> [2, 3] ```
Or, to remove specific size 1 dimensions:
``` # 't' is a tensor of shape [1, 2, 1, 3, 1, 1] shape(squeeze(t, [2, 4])) ==> [1, 2, 3, 1] ```
Arguments:
input: The `input` to squeeze.
Returns Contains the same data as `input`, but has one or more dimensions of size 1 removed.
func StackCloseV2 ¶ added in v1.3.0
Delete the stack from its resource container.
Arguments:
handle: The handle to a stack.
Returns the created operation.
func StackPopV2 ¶ added in v1.3.0
Pop the element at the top of the stack.
Arguments:
handle: The handle to a stack. elem_type: The type of the elem that is popped.
Returns The tensor that is popped from the top of the stack.
func StackPushV2 ¶ added in v1.3.0
func StackPushV2(scope *Scope, handle tf.Output, elem tf.Output, optional ...StackPushV2Attr) (output tf.Output)
Push an element onto the stack.
Arguments:
handle: The handle to a stack. elem: The tensor to be pushed onto the stack.
Returns The same tensor as the input 'elem'.
func StackV2 ¶ added in v1.3.0
func StackV2(scope *Scope, max_size tf.Output, elem_type tf.DataType, optional ...StackV2Attr) (handle tf.Output)
A stack that produces elements in first-in last-out order.
Arguments:
max_size: The maximum size of the stack if non-negative. If negative, the stack
size is unlimited.
elem_type: The type of the elements on the stack.
Returns The handle to the stack.
func Stage ¶ added in v1.1.0
Stage values similar to a lightweight Enqueue.
The basic functionality of this Op is similar to a queue with many fewer capabilities and options. This Op is optimized for performance.
Arguments:
values: a list of tensors
dtypes A list of data types that inserted values should adhere to.
Returns the created operation.
func StageClear ¶ added in v1.3.0
Op removes all elements in the underlying container.
Returns the created operation.
func StagePeek ¶ added in v1.3.0
func StagePeek(scope *Scope, index tf.Output, dtypes []tf.DataType, optional ...StagePeekAttr) (values []tf.Output)
Op peeks at the values at the specified index. If the
underlying container does not contain sufficient elements this op will block until it does. This Op is optimized for performance.
func StatelessRandomNormal ¶ added in v1.2.0
func StatelessRandomNormal(scope *Scope, shape tf.Output, seed tf.Output, optional ...StatelessRandomNormalAttr) (output tf.Output)
Outputs deterministic pseudorandom values from a normal distribution.
The generated values will have mean 0 and standard deviation 1.
The outputs are a deterministic function of `shape` and `seed`.
Arguments:
shape: The shape of the output tensor. seed: 2 seeds (shape [2]).
Returns Random values with specified shape.
func StatelessRandomUniform ¶ added in v1.2.0
func StatelessRandomUniform(scope *Scope, shape tf.Output, seed tf.Output, optional ...StatelessRandomUniformAttr) (output tf.Output)
Outputs deterministic pseudorandom random values from a uniform distribution.
The generated values follow a uniform distribution in the range `[0, 1)`. The lower bound 0 is included in the range, while the upper bound 1 is excluded.
The outputs are a deterministic function of `shape` and `seed`.
Arguments:
shape: The shape of the output tensor. seed: 2 seeds (shape [2]).
Returns Random values with specified shape.
func StatelessTruncatedNormal ¶ added in v1.2.0
func StatelessTruncatedNormal(scope *Scope, shape tf.Output, seed tf.Output, optional ...StatelessTruncatedNormalAttr) (output tf.Output)
Outputs deterministic pseudorandom values from a truncated normal distribution.
The generated values follow a normal distribution with mean 0 and standard deviation 1, except that values whose magnitude is more than 2 standard deviations from the mean are dropped and re-picked.
The outputs are a deterministic function of `shape` and `seed`.
Arguments:
shape: The shape of the output tensor. seed: 2 seeds (shape [2]).
Returns Random values with specified shape.
func StatsAggregatorHandle ¶ added in v1.5.0
func StatsAggregatorHandle(scope *Scope, optional ...StatsAggregatorHandleAttr) (handle tf.Output)
Creates a statistics manager resource.
func StatsAggregatorSummary ¶ added in v1.5.0
Produces a summary of any statistics recorded by the given statistics manager.
func StopGradient ¶ added in v1.1.0
Stops gradient computation.
When executed in a graph, this op outputs its input tensor as-is.
When building ops to compute gradients, this op prevents the contribution of its inputs to be taken into account. Normally, the gradient generator adds ops to a graph to compute the derivatives of a specified 'loss' by recursively finding out inputs that contributed to its computation. If you insert this op in the graph it inputs are masked from the gradient generator. They are not taken into account for computing gradients.
This is useful any time you want to compute a value with TensorFlow but need to pretend that the value was a constant. Some examples include:
- The *EM* algorithm where the *M-step* should not involve backpropagation through the output of the *E-step*.
- Contrastive divergence training of Boltzmann machines where, when differentiating the energy function, the training must not backpropagate through the graph that generated the samples from the model.
- Adversarial training, where no backprop should happen through the adversarial example generation process.
func StridedSlice ¶ added in v1.1.0
func StridedSlice(scope *Scope, input tf.Output, begin tf.Output, end tf.Output, strides tf.Output, optional ...StridedSliceAttr) (output tf.Output)
Return a strided slice from `input`.
Note, most python users will want to use the Python `Tensor.__getitem__` or `Variable.__getitem__` rather than this op directly.
The goal of this op is to produce a new tensor with a subset of the elements from the `n` dimensional `input` tensor. The subset is chosen using a sequence of `m` sparse range specifications encoded into the arguments of this function. Note, in some cases `m` could be equal to `n`, but this need not be the case. Each range specification entry can be one of the following:
- An ellipsis (...). Ellipses are used to imply zero or more dimensions of full-dimension selection and are produced using `ellipsis_mask`. For example, `foo[...]` is the identity slice.
- A new axis. This is used to insert a new shape=1 dimension and is produced using `new_axis_mask`. For example, `foo[:, ...]` where `foo` is shape `(3, 4)` produces a `(1, 3, 4)` tensor.
- A range `begin:end:stride`. This is used to specify how much to choose from a given dimension. `stride` can be any integer but 0. `begin` is an integer which represents the index of the first value to select while `end` represents the index of the last value to select. The number of values selected in each dimension is `end - begin` if `stride > 0` and `begin - end` if `stride < 0`. `begin` and `end` can be negative where `-1` is the last element, `-2` is the second to last. `begin_mask` controls whether to replace the explicitly given `begin` with an implicit effective value of `0` if `stride > 0` and `-1` if `stride < 0`. `end_mask` is analogous but produces the number required to create the largest open interval. For example, given a shape `(3,)` tensor `foo[:]`, the effective `begin` and `end` are `0` and `3`. Do not assume this is equivalent to `foo[0:-1]` which has an effective `begin` and `end` of `0` and `2`. Another example is `foo[-2::-1]` which reverses the first dimension of a tensor while dropping the last two (in the original order elements). For example `foo = [1,2,3,4]; foo[-2::-1]` is `[4,3]`.
- A single index. This is used to keep only elements that have a given index. For example (`foo[2, :]` on a shape `(5,6)` tensor produces a shape `(6,)` tensor. This is encoded in `begin` and `end` and `shrink_axis_mask`.
Each conceptual range specification is encoded in the op's argument. This encoding is best understand by considering a non-trivial example. In particular, `foo[1, 2:4, None, ..., :-3:-1, :]` will be encoded as
``` begin = [1, 2, x, x, 0, x] # x denotes don't care (usually 0) end = [2, 4, x, x, -3, x] strides = [1, 1, x, x, -1, 1] begin_mask = 1<<4 | 1 << 5 = 48 end_mask = 1<<5 = 32 ellipsis_mask = 1<<3 = 8 new_axis_mask = 1<<2 4 shrink_axis_mask = 1<<0 ```
In this case if `foo.shape` is (5, 5, 5, 5, 5, 5) the final shape of the slice becomes (2, 1, 5, 5, 2, 5). Let us walk step by step through each argument specification.
1. The first argument in the example slice is turned into `begin = 1` and `end = begin + 1 = 2`. To disambiguate from the original spec `2:4` we also set the appropriate bit in `shrink_axis_mask`.
2. `2:4` is contributes 2, 4, 1 to begin, end, and stride. All masks have zero bits contributed.
3. None is a synonym for `tf.newaxis`. This means insert a dimension of size 1 dimension in the final shape. Dummy values are contributed to begin, end and stride, while the new_axis_mask bit is set.
4. `...` grab the full ranges from as many dimensions as needed to fully specify a slice for every dimension of the input shape.
5. `:-3:-1` shows the use of negative indices. A negative index `i` associated with a dimension that has shape `s` is converted to a positive index `s + i`. So `-1` becomes `s-1` (i.e. the last element). This conversion is done internally so begin, end and strides receive x, -3, and -1. The appropriate begin_mask bit is set to indicate the start range is the full range (ignoring the x).
6. `:` indicates that the entire contents of the corresponding dimension is selected. This is equivalent to `::` or `0::1`. begin, end, and strides receive 0, 0, and 1, respectively. The appropriate bits in `begin_mask` and `end_mask` are also set.
*Requirements*:
`0 != strides[i] for i in [0, m)` `ellipsis_mask must be a power of two (only one ellipsis)`
Arguments:
begin: `begin[k]` specifies the offset into the `k`th range specification.
The exact dimension this corresponds to will be determined by context. Out-of-bounds values will be silently clamped. If the `k`th bit of `begin_mask` then `begin[k]` is ignored and the full range of the appropriate dimension is used instead. Negative values causes indexing to start from the highest element e.g. If `foo==[1,2,3]` then `foo[-1]==3`.
end: `end[i]` is like `begin` with the exception that `end_mask` is
used to determine full ranges.
strides: `strides[i]` specifies the increment in the `i`th specification
after extracting a given element. Negative indices will reverse the original order. Out or range values are clamped to `[0,dim[i]) if slice[i]>0` or `[-1,dim[i]-1] if slice[i] < 0`
func StridedSliceGrad ¶ added in v1.1.0
func StridedSliceGrad(scope *Scope, shape tf.Output, begin tf.Output, end tf.Output, strides tf.Output, dy tf.Output, optional ...StridedSliceGradAttr) (output tf.Output)
Returns the gradient of `StridedSlice`.
Since `StridedSlice` cuts out pieces of its `input` which is size `shape`, its gradient will have the same shape (which is passed here as `shape`). The gradient will be zero in any element that the slice does not select.
Arguments are the same as StridedSliceGrad with the exception that `dy` is the input gradient to be propagated and `shape` is the shape of `StridedSlice`'s `input`.
func StringJoin ¶ added in v1.1.0
Joins the strings in the given list of string tensors into one tensor;
with the given separator (default is an empty separator).
Arguments:
inputs: A list of string tensors. The tensors must all have the same shape,
or be scalars. Scalars may be mixed in; these will be broadcast to the shape of non-scalar inputs.
func StringSplit ¶ added in v1.1.0
func StringSplit(scope *Scope, input tf.Output, delimiter tf.Output, optional ...StringSplitAttr) (indices tf.Output, values tf.Output, shape tf.Output)
Split elements of `input` based on `delimiter` into a `SparseTensor`.
Let N be the size of source (typically N will be the batch size). Split each element of `input` based on `delimiter` and return a `SparseTensor` containing the splitted tokens. Empty tokens are ignored.
`delimiter` can be empty, or a string of split characters. If `delimiter` is an
empty string, each element of `input` is split into individual single-byte character strings, including splitting of UTF-8 multibyte sequences. Otherwise every character of `delimiter` is a potential split point.
For example:
N = 2, input[0] is 'hello world' and input[1] is 'a b c', then the output
will be
indices = [0, 0;
0, 1;
1, 0;
1, 1;
1, 2]
shape = [2, 3]
values = ['hello', 'world', 'a', 'b', 'c']
Arguments:
input: 1-D. Strings to split. delimiter: 0-D. Delimiter characters (bytes), or empty string.
Returns A dense matrix of int64 representing the indices of the sparse tensor.A vector of strings corresponding to the splited values.a length-2 vector of int64 representing the shape of the sparse tensor, where the first value is N and the second value is the maximum number of tokens in a single input entry.
func StringToHashBucket ¶ added in v1.1.0
func StringToHashBucket(scope *Scope, string_tensor tf.Output, num_buckets int64) (output tf.Output)
Converts each string in the input Tensor to its hash mod by a number of buckets.
The hash function is deterministic on the content of the string within the process.
Note that the hash function may change from time to time. This functionality will be deprecated and it's recommended to use `tf.string_to_hash_bucket_fast()` or `tf.string_to_hash_bucket_strong()`.
Arguments:
num_buckets: The number of buckets.
Returns A Tensor of the same shape as the input `string_tensor`.
func StringToHashBucketFast ¶ added in v1.1.0
Converts each string in the input Tensor to its hash mod by a number of buckets.
The hash function is deterministic on the content of the string within the process and will never change. However, it is not suitable for cryptography. This function may be used when CPU time is scarce and inputs are trusted or unimportant. There is a risk of adversaries constructing inputs that all hash to the same bucket. To prevent this problem, use a strong hash function with `tf.string_to_hash_bucket_strong`.
Arguments:
input: The strings to assign a hash bucket. num_buckets: The number of buckets.
Returns A Tensor of the same shape as the input `string_tensor`.
func StringToHashBucketStrong ¶ added in v1.1.0
func StringToHashBucketStrong(scope *Scope, input tf.Output, num_buckets int64, key []int64) (output tf.Output)
Converts each string in the input Tensor to its hash mod by a number of buckets.
The hash function is deterministic on the content of the string within the process. The hash function is a keyed hash function, where attribute `key` defines the key of the hash function. `key` is an array of 2 elements.
A strong hash is important when inputs may be malicious, e.g. URLs with additional components. Adversaries could try to make their inputs hash to the same bucket for a denial-of-service attack or to skew the results. A strong hash prevents this by making it difficult, if not infeasible, to compute inputs that hash to the same bucket. This comes at a cost of roughly 4x higher compute time than `tf.string_to_hash_bucket_fast`.
Arguments:
input: The strings to assign a hash bucket. num_buckets: The number of buckets. key: The key for the keyed hash function passed as a list of two uint64
elements.
Returns A Tensor of the same shape as the input `string_tensor`.
func StringToNumber ¶ added in v1.1.0
func StringToNumber(scope *Scope, string_tensor tf.Output, optional ...StringToNumberAttr) (output tf.Output)
Converts each string in the input Tensor to the specified numeric type.
(Note that int32 overflow results in an error while float overflow results in a rounded value.)
Returns A Tensor of the same shape as the input `string_tensor`.
func Sub ¶ added in v1.1.0
Returns x - y element-wise.
*NOTE*: `Subtract` supports broadcasting. More about broadcasting [here](http://docs.scipy.org/doc/numpy/user/basics.broadcasting.html)
func Substr ¶ added in v1.1.0
Return substrings from `Tensor` of strings.
For each string in the input `Tensor`, creates a substring starting at index `pos` with a total length of `len`.
If `len` defines a substring that would extend beyond the length of the input string, then as many characters as possible are used.
If `pos` is negative or specifies a character index larger than any of the input strings, then an `InvalidArgumentError` is thrown.
`pos` and `len` must have the same shape, otherwise a `ValueError` is thrown on Op creation.
*NOTE*: `Substr` supports broadcasting up to two dimensions. More about broadcasting [here](http://docs.scipy.org/doc/numpy/user/basics.broadcasting.html)
---
Examples ¶
Using scalar `pos` and `len`:
```python input = [b'Hello', b'World'] position = 1 length = 3
output = [b'ell', b'orl'] ```
Using `pos` and `len` with same shape as `input`:
```python input = [[b'ten', b'eleven', b'twelve'],
[b'thirteen', b'fourteen', b'fifteen'], [b'sixteen', b'seventeen', b'eighteen']]
position = [[1, 2, 3],
[1, 2, 3], [1, 2, 3]]
length = [[2, 3, 4],
[4, 3, 2], [5, 5, 5]]
output = [[b'en', b'eve', b'lve'],
[b'hirt', b'urt', b'te'], [b'ixtee', b'vente', b'hteen']]
```
Broadcasting `pos` and `len` onto `input`:
``` input = [[b'ten', b'eleven', b'twelve'],
[b'thirteen', b'fourteen', b'fifteen'], [b'sixteen', b'seventeen', b'eighteen'], [b'nineteen', b'twenty', b'twentyone']]
position = [1, 2, 3] length = [1, 2, 3]
output = [[b'e', b'ev', b'lve'],
[b'h', b'ur', b'tee'], [b'i', b've', b'hte'], [b'i', b'en', b'nty']]
```
Broadcasting `input` onto `pos` and `len`:
``` input = b'thirteen' position = [1, 5, 7] length = [3, 2, 1]
output = [b'hir', b'ee', b'n'] ```
Arguments:
input: Tensor of strings pos: Scalar defining the position of first character in each substring len: Scalar defining the number of characters to include in each substring
Returns Tensor of substrings
func Sum ¶ added in v1.1.0
Computes the sum of elements across dimensions of a tensor.
Reduces `input` along the dimensions given in `axis`. Unless `keep_dims` is true, the rank of the tensor is reduced by 1 for each entry in `axis`. If `keep_dims` is true, the reduced dimensions are retained with length 1.
Arguments:
input: The tensor to reduce. axis: The dimensions to reduce. Must be in the range
`[-rank(input), rank(input))`.
Returns The reduced tensor.
func SummaryWriter ¶ added in v1.4.0
func SummaryWriter(scope *Scope, optional ...SummaryWriterAttr) (writer tf.Output)
Returns a handle to be used to access a summary writer.
The summary writer is an in-graph resource which can be used by ops to write summaries to event files.
Returns the summary writer resource. Scalar handle.
func Svd ¶ added in v1.1.0
func Svd(scope *Scope, input tf.Output, optional ...SvdAttr) (s tf.Output, u tf.Output, v tf.Output)
Computes the singular value decompositions of one or more matrices.
Computes the SVD of each inner matrix in `input` such that `input[..., :, :] = u[..., :, :] * diag(s[..., :, :]) * transpose(v[..., :, :])`
```python # a is a tensor containing a batch of matrices. # s is a tensor of singular values for each matrix. # u is the tensor containing of left singular vectors for each matrix. # v is the tensor containing of right singular vectors for each matrix. s, u, v = svd(a) s, _, _ = svd(a, compute_uv=False) ```
Arguments:
input: A tensor of shape `[..., M, N]` whose inner-most 2 dimensions
form matrices of size `[M, N]`. Let `P` be the minimum of `M` and `N`.
Returns Singular values. Shape is `[..., P]`.Left singular vectors. If `full_matrices` is `False` then shape is `[..., M, P]`; if `full_matrices` is `True` then shape is `[..., M, M]`. Undefined if `compute_uv` is `False`.Left singular vectors. If `full_matrices` is `False` then shape is `[..., N, P]`. If `full_matrices` is `True` then shape is `[..., N, N]`. Undefined if `compute_uv` is false.
func Switch ¶ added in v1.1.0
func Switch(scope *Scope, data tf.Output, pred tf.Output) (output_false tf.Output, output_true tf.Output)
Forwards `data` to the output port determined by `pred`.
If `pred` is true, the `data` input is forwarded to `output_true`. Otherwise, the data goes to `output_false`.
See also `RefSwitch` and `Merge`.
Arguments:
data: The tensor to be forwarded to the appropriate output. pred: A scalar that specifies which output port will receive data.
Returns If `pred` is false, data will be forwarded to this output.If `pred` is true, data will be forwarded to this output.
func TFRecordDataset ¶ added in v1.2.0
func TFRecordDataset(scope *Scope, filenames tf.Output, compression_type tf.Output, buffer_size tf.Output) (handle tf.Output)
Creates a dataset that emits the records from one or more TFRecord files.
Arguments:
filenames: A scalar or vector containing the name(s) of the file(s) to be
read.
compression_type: A scalar containing either (i) the empty string (no
compression), (ii) "ZLIB", or (iii) "GZIP".
buffer_size: A scalar representing the number of bytes to buffer. A value of
0 means no buffering will be performed.
func TFRecordReaderV2 ¶ added in v1.1.0
func TFRecordReaderV2(scope *Scope, optional ...TFRecordReaderV2Attr) (reader_handle tf.Output)
A Reader that outputs the records from a TensorFlow Records file.
Returns The handle to reference the Reader.
func TakeDataset ¶ added in v1.2.0
func TakeDataset(scope *Scope, input_dataset tf.Output, count tf.Output, output_types []tf.DataType, output_shapes []tf.Shape) (handle tf.Output)
Creates a dataset that contains `count` elements from the `input_dataset`.
Arguments:
count: A scalar representing the number of elements from the `input_dataset`
that should be taken. A value of `-1` indicates that all of `input_dataset` is taken.
func TakeManySparseFromTensorsMap ¶ added in v1.1.0
func TakeManySparseFromTensorsMap(scope *Scope, sparse_handles tf.Output, dtype tf.DataType, optional ...TakeManySparseFromTensorsMapAttr) (sparse_indices tf.Output, sparse_values tf.Output, sparse_shape tf.Output)
Read `SparseTensors` from a `SparseTensorsMap` and concatenate them.
The input `sparse_handles` must be an `int64` matrix of shape `[N, 1]` where `N` is the minibatch size and the rows correspond to the output handles of `AddSparseToTensorsMap` or `AddManySparseToTensorsMap`. The ranks of the original `SparseTensor` objects that went into the given input ops must all match. When the final `SparseTensor` is created, it has rank one higher than the ranks of the incoming `SparseTensor` objects (they have been concatenated along a new row dimension on the left).
The output `SparseTensor` object's shape values for all dimensions but the first are the max across the input `SparseTensor` objects' shape values for the corresponding dimensions. Its first shape value is `N`, the minibatch size.
The input `SparseTensor` objects' indices are assumed ordered in standard lexicographic order. If this is not the case, after this step run `SparseReorder` to restore index ordering.
For example, if the handles represent an input, which is a `[2, 3]` matrix representing two original `SparseTensor` objects:
```
index = [ 0]
[10]
[20]
values = [1, 2, 3]
shape = [50]
```
and
```
index = [ 2]
[10]
values = [4, 5]
shape = [30]
```
then the final `SparseTensor` will be:
```
index = [0 0]
[0 10]
[0 20]
[1 2]
[1 10]
values = [1, 2, 3, 4, 5]
shape = [2 50]
```
Arguments:
sparse_handles: 1-D, The `N` serialized `SparseTensor` objects.
Shape: `[N]`.
dtype: The `dtype` of the `SparseTensor` objects stored in the
`SparseTensorsMap`.
Returns 2-D. The `indices` of the minibatch `SparseTensor`.1-D. The `values` of the minibatch `SparseTensor`.1-D. The `shape` of the minibatch `SparseTensor`.
func TanhGrad ¶ added in v1.1.0
Computes the gradient for the tanh of `x` wrt its input.
Specifically, `grad = dy * (1 - y*y)`, where `y = tanh(x)`, and `dy` is the corresponding input gradient.
func TensorArrayCloseV2 ¶ added in v1.1.0
Deprecated. Use TensorArrayCloseV3
DEPRECATED at GraphDef version 26: Use TensorArrayCloseV3
Returns the created operation.
func TensorArrayCloseV3 ¶ added in v1.1.0
Delete the TensorArray from its resource container.
This enables the user to close and release the resource in the middle of a step/run.
Arguments:
handle: The handle to a TensorArray (output of TensorArray or TensorArrayGrad).
Returns the created operation.
func TensorArrayConcatV2 ¶ added in v1.1.0
func TensorArrayConcatV2(scope *Scope, handle tf.Output, flow_in tf.Output, dtype tf.DataType, optional ...TensorArrayConcatV2Attr) (value tf.Output, lengths tf.Output)
Deprecated. Use TensorArrayConcatV3
func TensorArrayConcatV3 ¶ added in v1.1.0
func TensorArrayConcatV3(scope *Scope, handle tf.Output, flow_in tf.Output, dtype tf.DataType, optional ...TensorArrayConcatV3Attr) (value tf.Output, lengths tf.Output)
Concat the elements from the TensorArray into value `value`.
Takes `T` elements of shapes
``` (n0 x d0 x d1 x ...), (n1 x d0 x d1 x ...), ..., (n(T-1) x d0 x d1 x ...) ```
and concatenates them into a Tensor of shape:
```(n0 + n1 + ... + n(T-1) x d0 x d1 x ...)```
All elements must have the same shape (excepting the first dimension).
Arguments:
handle: The handle to a TensorArray. flow_in: A float scalar that enforces proper chaining of operations. dtype: The type of the elem that is returned.
Returns All of the elements in the TensorArray, concatenated along the first axis.A vector of the row sizes of the original T elements in the value output. In the example above, this would be the values: `(n1, n2, ..., n(T-1))`.
func TensorArrayGatherV2 ¶ added in v1.1.0
func TensorArrayGatherV2(scope *Scope, handle tf.Output, indices tf.Output, flow_in tf.Output, dtype tf.DataType, optional ...TensorArrayGatherV2Attr) (value tf.Output)
Deprecated. Use TensorArrayGatherV3
DEPRECATED at GraphDef version 26: Use TensorArrayGatherV3
func TensorArrayGatherV3 ¶ added in v1.1.0
func TensorArrayGatherV3(scope *Scope, handle tf.Output, indices tf.Output, flow_in tf.Output, dtype tf.DataType, optional ...TensorArrayGatherV3Attr) (value tf.Output)
Gather specific elements from the TensorArray into output `value`.
All elements selected by `indices` must have the same shape.
Arguments:
handle: The handle to a TensorArray. indices: The locations in the TensorArray from which to read tensor elements. flow_in: A float scalar that enforces proper chaining of operations. dtype: The type of the elem that is returned.
Returns All of the elements in the TensorArray, concatenated along a new axis (the new dimension 0).
func TensorArrayGradV2 ¶ added in v1.1.0
func TensorArrayGradV2(scope *Scope, handle tf.Output, flow_in tf.Output, source string) (grad_handle tf.Output)
Deprecated. Use TensorArrayGradV3
DEPRECATED at GraphDef version 26: Use TensorArrayGradV3
func TensorArrayGradV3 ¶ added in v1.1.0
func TensorArrayGradV3(scope *Scope, handle tf.Output, flow_in tf.Output, source string) (grad_handle tf.Output, flow_out tf.Output)
Creates a TensorArray for storing the gradients of values in the given handle.
If the given TensorArray gradient already exists, returns a reference to it.
Locks the size of the original TensorArray by disabling its dynamic size flag.
**A note about the input flow_in:**
The handle flow_in forces the execution of the gradient lookup to occur only after certain other operations have occurred. For example, when the forward TensorArray is dynamically sized, writes to this TensorArray may resize the object. The gradient TensorArray is statically sized based on the size of the forward TensorArray when this operation executes. Furthermore, the size of the forward TensorArray is frozen by this call. As a result, the flow is used to ensure that the call to generate the gradient TensorArray only happens after all writes are executed.
In the case of dynamically sized TensorArrays, gradient computation should only be performed on read operations that have themselves been chained via flow to occur only after all writes have executed. That way the final size of the forward TensorArray is known when this operation is called.
**A note about the source attribute:**
TensorArray gradient calls use an accumulator TensorArray object. If multiple gradients are calculated and run in the same session, the multiple gradient nodes may accidentally flow through the same accumulator TensorArray. This double counts and generally breaks the TensorArray gradient flow.
The solution is to identify which gradient call this particular TensorArray gradient is being called in. This is performed by identifying a unique string (e.g. "gradients", "gradients_1", ...) from the input gradient Tensor's name. This string is used as a suffix when creating the TensorArray gradient object here (the attribute `source`).
The attribute `source` is added as a suffix to the forward TensorArray's name when performing the creation / lookup, so that each separate gradient calculation gets its own TensorArray accumulator.
Arguments:
handle: The handle to the forward TensorArray. flow_in: A float scalar that enforces proper chaining of operations. source: The gradient source string, used to decide which gradient TensorArray
to return.
func TensorArrayReadV2 ¶ added in v1.1.0
func TensorArrayReadV2(scope *Scope, handle tf.Output, index tf.Output, flow_in tf.Output, dtype tf.DataType) (value tf.Output)
Deprecated. Use TensorArrayReadV3
DEPRECATED at GraphDef version 26: Use TensorArrayReadV3
func TensorArrayReadV3 ¶ added in v1.1.0
func TensorArrayReadV3(scope *Scope, handle tf.Output, index tf.Output, flow_in tf.Output, dtype tf.DataType) (value tf.Output)
Read an element from the TensorArray into output `value`.
Arguments:
handle: The handle to a TensorArray. flow_in: A float scalar that enforces proper chaining of operations. dtype: The type of the elem that is returned.
Returns The tensor that is read from the TensorArray.
func TensorArrayScatterV2 ¶ added in v1.1.0
func TensorArrayScatterV2(scope *Scope, handle tf.Output, indices tf.Output, value tf.Output, flow_in tf.Output) (flow_out tf.Output)
Deprecated. Use TensorArrayScatterV3
DEPRECATED at GraphDef version 26: Use TensorArrayScatterV3
func TensorArrayScatterV3 ¶ added in v1.1.0
func TensorArrayScatterV3(scope *Scope, handle tf.Output, indices tf.Output, value tf.Output, flow_in tf.Output) (flow_out tf.Output)
Scatter the data from the input value into specific TensorArray elements.
`indices` must be a vector, its length must match the first dim of `value`.
Arguments:
handle: The handle to a TensorArray. indices: The locations at which to write the tensor elements. value: The concatenated tensor to write to the TensorArray. flow_in: A float scalar that enforces proper chaining of operations.
Returns A float scalar that enforces proper chaining of operations.
func TensorArraySizeV2 ¶ added in v1.1.0
Deprecated. Use TensorArraySizeV3
DEPRECATED at GraphDef version 26: Use TensorArraySizeV3
func TensorArraySizeV3 ¶ added in v1.1.0
Get the current size of the TensorArray.
Arguments:
handle: The handle to a TensorArray (output of TensorArray or TensorArrayGrad). flow_in: A float scalar that enforces proper chaining of operations.
Returns The current size of the TensorArray.
func TensorArraySplitV2 ¶ added in v1.1.0
func TensorArraySplitV2(scope *Scope, handle tf.Output, value tf.Output, lengths tf.Output, flow_in tf.Output) (flow_out tf.Output)
Deprecated. Use TensorArraySplitV3
DEPRECATED at GraphDef version 26: Use TensorArraySplitV3
func TensorArraySplitV3 ¶ added in v1.1.0
func TensorArraySplitV3(scope *Scope, handle tf.Output, value tf.Output, lengths tf.Output, flow_in tf.Output) (flow_out tf.Output)
Split the data from the input value into TensorArray elements.
Assuming that `lengths` takes on values
```(n0, n1, ..., n(T-1))```
and that `value` has shape
```(n0 + n1 + ... + n(T-1) x d0 x d1 x ...)```,
this splits values into a TensorArray with T tensors.
TensorArray index t will be the subtensor of values with starting position
```(n0 + n1 + ... + n(t-1), 0, 0, ...)```
and having size
```nt x d0 x d1 x ...```
Arguments:
handle: The handle to a TensorArray. value: The concatenated tensor to write to the TensorArray. lengths: The vector of lengths, how to split the rows of value into the
TensorArray.
flow_in: A float scalar that enforces proper chaining of operations.
Returns A float scalar that enforces proper chaining of operations.
func TensorArrayV2 ¶ added in v1.1.0
func TensorArrayV2(scope *Scope, size tf.Output, dtype tf.DataType, optional ...TensorArrayV2Attr) (handle tf.Output)
Deprecated. Use TensorArrayV3
DEPRECATED at GraphDef version 26: Use TensorArrayV3
func TensorArrayV3 ¶ added in v1.1.0
func TensorArrayV3(scope *Scope, size tf.Output, dtype tf.DataType, optional ...TensorArrayV3Attr) (handle tf.Output, flow tf.Output)
An array of Tensors of given size.
Write data via Write and read via Read or Pack.
Arguments:
size: The size of the array. dtype: The type of the elements on the tensor_array.
Returns The handle to the TensorArray.A scalar used to control gradient flow.
func TensorArrayWriteV2 ¶ added in v1.1.0
func TensorArrayWriteV2(scope *Scope, handle tf.Output, index tf.Output, value tf.Output, flow_in tf.Output) (flow_out tf.Output)
Deprecated. Use TensorArrayGradV3
DEPRECATED at GraphDef version 26: Use TensorArrayWriteV3
func TensorArrayWriteV3 ¶ added in v1.1.0
func TensorArrayWriteV3(scope *Scope, handle tf.Output, index tf.Output, value tf.Output, flow_in tf.Output) (flow_out tf.Output)
Push an element onto the tensor_array.
Arguments:
handle: The handle to a TensorArray. index: The position to write to inside the TensorArray. value: The tensor to write to the TensorArray. flow_in: A float scalar that enforces proper chaining of operations.
Returns A float scalar that enforces proper chaining of operations.
func TensorDataset ¶ added in v1.2.0
func TensorDataset(scope *Scope, components []tf.Output, output_shapes []tf.Shape) (handle tf.Output)
Creates a dataset that emits `components` as a tuple of tensors once.
func TensorSliceDataset ¶ added in v1.2.0
func TensorSliceDataset(scope *Scope, components []tf.Output, output_shapes []tf.Shape) (handle tf.Output)
Creates a dataset that emits each dim-0 slice of `components` once.
func TensorSummary ¶ added in v1.1.0
func TensorSummary(scope *Scope, tensor tf.Output, optional ...TensorSummaryAttr) (summary tf.Output)
Outputs a `Summary` protocol buffer with a tensor.
This op is being phased out in favor of TensorSummaryV2, which lets callers pass a tag as well as a serialized SummaryMetadata proto string that contains plugin-specific data. We will keep this op to maintain backwards compatibility.
Arguments:
tensor: A tensor to serialize.
func TensorSummaryV2 ¶ added in v1.3.0
func TensorSummaryV2(scope *Scope, tag tf.Output, tensor tf.Output, serialized_summary_metadata tf.Output) (summary tf.Output)
Outputs a `Summary` protocol buffer with a tensor and per-plugin data.
Arguments:
tag: A string attached to this summary. Used for organization in TensorBoard. tensor: A tensor to serialize. serialized_summary_metadata: A serialized SummaryMetadata proto. Contains plugin
data.
func TextLineDataset ¶ added in v1.2.0
func TextLineDataset(scope *Scope, filenames tf.Output, compression_type tf.Output, buffer_size tf.Output) (handle tf.Output)
Creates a dataset that emits the lines of one or more text files.
Arguments:
filenames: A scalar or a vector containing the name(s) of the file(s) to be
read.
compression_type: A scalar containing either (i) the empty string (no
compression), (ii) "ZLIB", or (iii) "GZIP".
buffer_size: A scalar containing the number of bytes to buffer.
func TextLineReaderV2 ¶ added in v1.1.0
func TextLineReaderV2(scope *Scope, optional ...TextLineReaderV2Attr) (reader_handle tf.Output)
A Reader that outputs the lines of a file delimited by '\n'.
Returns The handle to reference the Reader.
func ThreadUnsafeUnigramCandidateSampler ¶ added in v1.1.0
func ThreadUnsafeUnigramCandidateSampler(scope *Scope, true_classes tf.Output, num_true int64, num_sampled int64, unique bool, range_max int64, optional ...ThreadUnsafeUnigramCandidateSamplerAttr) (sampled_candidates tf.Output, true_expected_count tf.Output, sampled_expected_count tf.Output)
Generates labels for candidate sampling with a learned unigram distribution.
See explanations of candidate sampling and the data formats at go/candidate-sampling.
For each batch, this op picks a single set of sampled candidate labels.
The advantages of sampling candidates per-batch are simplicity and the possibility of efficient dense matrix multiplication. The disadvantage is that the sampled candidates must be chosen independently of the context and of the true labels.
Arguments:
true_classes: A batch_size * num_true matrix, in which each row contains the
IDs of the num_true target_classes in the corresponding original label.
num_true: Number of true labels per context. num_sampled: Number of candidates to randomly sample. unique: If unique is true, we sample with rejection, so that all sampled
candidates in a batch are unique. This requires some approximation to estimate the post-rejection sampling probabilities.
range_max: The sampler will sample integers from the interval [0, range_max).
Returns A vector of length num_sampled, in which each element is the ID of a sampled candidate.A batch_size * num_true matrix, representing the number of times each candidate is expected to occur in a batch of sampled candidates. If unique=true, then this is a probability.A vector of length num_sampled, for each sampled candidate representing the number of times the candidate is expected to occur in a batch of sampled candidates. If unique=true, then this is a probability.
func Tile ¶ added in v1.1.0
Constructs a tensor by tiling a given tensor.
This operation creates a new tensor by replicating `input` `multiples` times. The output tensor's i'th dimension has `input.dims(i) * multiples[i]` elements, and the values of `input` are replicated `multiples[i]` times along the 'i'th dimension. For example, tiling `[a b c d]` by `[2]` produces `[a b c d a b c d]`.
Arguments:
input: 1-D or higher. multiples: 1-D. Length must be the same as the number of dimensions in `input`
func TileGrad ¶ added in v1.1.0
Returns the gradient of `Tile`.
DEPRECATED at GraphDef version 3: TileGrad has been replaced with reduce_sum
Since `Tile` takes an input and repeats the input `multiples` times along each dimension, `TileGrad` takes in `multiples` and aggregates each repeated tile of `input` into `output`.
func TopK ¶ added in v1.1.0
func TopK(scope *Scope, input tf.Output, k int64, optional ...TopKAttr) (values tf.Output, indices tf.Output)
Finds values and indices of the `k` largest elements for the last dimension.
DEPRECATED at GraphDef version 7: Use TopKV2 instead
If the input is a vector (rank-1), finds the `k` largest entries in the vector and outputs their values and indices as vectors. Thus `values[j]` is the `j`-th largest entry in `input`, and its index is `indices[j]`.
For matrices (resp. higher rank input), computes the top `k` entries in each row (resp. vector along the last dimension). Thus,
values.shape = indices.shape = input.shape[:-1] + [k]
If two elements are equal, the lower-index element appears first.
If `k` varies dynamically, use `TopKV2` below.
Arguments:
input: 1-D or higher with last dimension at least `k`. k: Number of top elements to look for along the last dimension (along each
row for matrices).
Returns The `k` largest elements along each last dimensional slice.The indices of `values` within the last dimension of `input`.
func TopKV2 ¶ added in v1.1.0
func TopKV2(scope *Scope, input tf.Output, k tf.Output, optional ...TopKV2Attr) (values tf.Output, indices tf.Output)
Finds values and indices of the `k` largest elements for the last dimension.
If the input is a vector (rank-1), finds the `k` largest entries in the vector and outputs their values and indices as vectors. Thus `values[j]` is the `j`-th largest entry in `input`, and its index is `indices[j]`.
For matrices (resp. higher rank input), computes the top `k` entries in each row (resp. vector along the last dimension). Thus,
values.shape = indices.shape = input.shape[:-1] + [k]
If two elements are equal, the lower-index element appears first.
Arguments:
input: 1-D or higher with last dimension at least `k`. k: 0-D. Number of top elements to look for along the last dimension (along each
row for matrices).
Returns The `k` largest elements along each last dimensional slice.The indices of `values` within the last dimension of `input`.
func Transpose ¶ added in v1.1.0
Shuffle dimensions of x according to a permutation.
The output `y` has the same rank as `x`. The shapes of `x` and `y` satisfy:
`y.shape[i] == x.shape[perm[i]] for i in [0, 1, ..., rank(x) - 1]`
func TruncateDiv ¶ added in v1.1.0
Returns x / y element-wise for integer types.
Truncation designates that negative numbers will round fractional quantities toward zero. I.e. -7 / 5 = -1. This matches C semantics but it is different than Python semantics. See `FloorDiv` for a division function that matches Python Semantics.
*NOTE*: `TruncateDiv` supports broadcasting. More about broadcasting [here](http://docs.scipy.org/doc/numpy/user/basics.broadcasting.html)
func TruncateMod ¶ added in v1.1.0
Returns element-wise remainder of division. This emulates C semantics in that
the result here is consistent with a truncating divide. E.g. `truncate(x / y) * y + truncate_mod(x, y) = x`.
*NOTE*: `TruncateMod` supports broadcasting. More about broadcasting [here](http://docs.scipy.org/doc/numpy/user/basics.broadcasting.html)
func TruncatedNormal ¶ added in v1.1.0
func TruncatedNormal(scope *Scope, shape tf.Output, dtype tf.DataType, optional ...TruncatedNormalAttr) (output tf.Output)
Outputs random values from a truncated normal distribution.
The generated values follow a normal distribution with mean 0 and standard deviation 1, except that values whose magnitude is more than 2 standard deviations from the mean are dropped and re-picked.
Arguments:
shape: The shape of the output tensor. dtype: The type of the output.
Returns A tensor of the specified shape filled with random truncated normal values.
func UniformCandidateSampler ¶ added in v1.1.0
func UniformCandidateSampler(scope *Scope, true_classes tf.Output, num_true int64, num_sampled int64, unique bool, range_max int64, optional ...UniformCandidateSamplerAttr) (sampled_candidates tf.Output, true_expected_count tf.Output, sampled_expected_count tf.Output)
Generates labels for candidate sampling with a uniform distribution.
See explanations of candidate sampling and the data formats at go/candidate-sampling.
For each batch, this op picks a single set of sampled candidate labels.
The advantages of sampling candidates per-batch are simplicity and the possibility of efficient dense matrix multiplication. The disadvantage is that the sampled candidates must be chosen independently of the context and of the true labels.
Arguments:
true_classes: A batch_size * num_true matrix, in which each row contains the
IDs of the num_true target_classes in the corresponding original label.
num_true: Number of true labels per context. num_sampled: Number of candidates to randomly sample. unique: If unique is true, we sample with rejection, so that all sampled
candidates in a batch are unique. This requires some approximation to estimate the post-rejection sampling probabilities.
range_max: The sampler will sample integers from the interval [0, range_max).
Returns A vector of length num_sampled, in which each element is the ID of a sampled candidate.A batch_size * num_true matrix, representing the number of times each candidate is expected to occur in a batch of sampled candidates. If unique=true, then this is a probability.A vector of length num_sampled, for each sampled candidate representing the number of times the candidate is expected to occur in a batch of sampled candidates. If unique=true, then this is a probability.
func Unique ¶ added in v1.1.0
Finds unique elements in a 1-D tensor.
This operation returns a tensor `y` containing all of the unique elements of `x` sorted in the same order that they occur in `x`. This operation also returns a tensor `idx` the same size as `x` that contains the index of each value of `x` in the unique output `y`. In other words:
`y[idx[i]] = x[i] for i in [0, 1,...,rank(x) - 1]`
For example:
``` # tensor 'x' is [1, 1, 2, 4, 4, 4, 7, 8, 8] y, idx = unique(x) y ==> [1, 2, 4, 7, 8] idx ==> [0, 0, 1, 2, 2, 2, 3, 4, 4] ```
Arguments:
x: 1-D.
Returns 1-D.1-D.
func UniqueV2 ¶ added in v1.6.0
func UniqueV2(scope *Scope, x tf.Output, axis tf.Output, optional ...UniqueV2Attr) (y tf.Output, idx tf.Output)
Finds unique elements in a 1-D tensor.
This operation returns a tensor `y` containing all of the unique elements of `x` sorted in the same order that they occur in `x`. This operation also returns a tensor `idx` the same size as `x` that contains the index of each value of `x` in the unique output `y`. In other words:
`y[idx[i]] = x[i] for i in [0, 1,...,rank(x) - 1]`
For example:
``` # tensor 'x' is [1, 1, 2, 4, 4, 4, 7, 8, 8] y, idx = unique(x) y ==> [1, 2, 4, 7, 8] idx ==> [0, 0, 1, 2, 2, 2, 3, 4, 4] ```
Arguments:
x: A `Tensor`. axis: A `Tensor` of type `int64` (default: 0). The axis of the Tensor to
find the unique elements.
Returns A `Tensor`. Unique elements along the `axis` of `Tensor` x.A 1-D Tensor. Has the same type as x that contains the index of each value of x in the output y.
func UniqueWithCounts ¶ added in v1.1.0
func UniqueWithCounts(scope *Scope, x tf.Output, optional ...UniqueWithCountsAttr) (y tf.Output, idx tf.Output, count tf.Output)
Finds unique elements in a 1-D tensor.
This operation returns a tensor `y` containing all of the unique elements of `x` sorted in the same order that they occur in `x`. This operation also returns a tensor `idx` the same size as `x` that contains the index of each value of `x` in the unique output `y`. Finally, it returns a third tensor `count` that contains the count of each element of `y` in `x`. In other words:
`y[idx[i]] = x[i] for i in [0, 1,...,rank(x) - 1]`
For example:
``` # tensor 'x' is [1, 1, 2, 4, 4, 4, 7, 8, 8] y, idx, count = unique_with_counts(x) y ==> [1, 2, 4, 7, 8] idx ==> [0, 0, 1, 2, 2, 2, 3, 4, 4] count ==> [2, 1, 3, 1, 2] ```
Arguments:
x: 1-D.
Returns 1-D.1-D.1-D.
func Unpack ¶ added in v1.1.0
Unpacks a given dimension of a rank-`R` tensor into `num` rank-`(R-1)` tensors.
Unpacks `num` tensors from `value` by chipping it along the `axis` dimension. For example, given a tensor of shape `(A, B, C, D)`;
If `axis == 0` then the i'th tensor in `output` is the slice `value[i, :, :, :]`
and each tensor in `output` will have shape `(B, C, D)`. (Note that the dimension unpacked along is gone, unlike `split`).
If `axis == 1` then the i'th tensor in `output` is the slice `value[:, i, :, :]`
and each tensor in `output` will have shape `(A, C, D)`.
Etc.
This is the opposite of `pack`.
Arguments:
value: 1-D or higher, with `axis` dimension size equal to `num`.
Returns The list of tensors unpacked from `value`.
func UnsortedSegmentMax ¶ added in v1.1.0
func UnsortedSegmentMax(scope *Scope, data tf.Output, segment_ids tf.Output, num_segments tf.Output) (output tf.Output)
Computes the Max along segments of a tensor.
Read @{$math_ops#segmentation$the section on segmentation} for an explanation of segments.
This operator is similar to the [unsorted segment sum operator](../../../api_docs/python/math_ops.md#UnsortedSegmentSum). Instead of computing the sum over segments, it computes the maximum such that:
\\(output_i = \max_j data_j\\) where max is over `j` such that `segment_ids[j] == i`.
If the maximum is empty for a given segment ID `i`, it outputs the smallest possible value for specific numeric type,
`output[i] = numeric_limits<T>::min()`.
<div style="width:70%; margin:auto; margin-bottom:10px; margin-top:20px;"> <img style="width:100%" src="https://www.tensorflow.org/images/UnsortedSegmentMax.png" alt> </div>
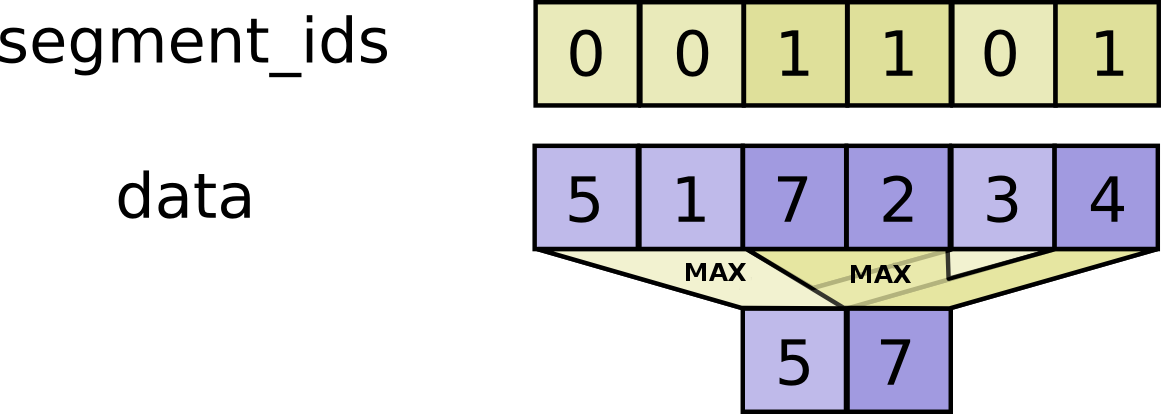{kind=link}
Arguments:
segment_ids: A 1-D tensor whose rank is equal to the rank of `data`'s
first dimension.
Returns Has same shape as data, except for dimension 0 which has size `num_segments`.
func UnsortedSegmentSum ¶ added in v1.1.0
func UnsortedSegmentSum(scope *Scope, data tf.Output, segment_ids tf.Output, num_segments tf.Output) (output tf.Output)
Computes the sum along segments of a tensor.
Read @{$math_ops#segmentation$the section on segmentation} for an explanation of segments.
Computes a tensor such that `(output[i] = sum_{j...} data[j...]` where the sum is over tuples `j...` such that `segment_ids[j...] == i`. Unlike `SegmentSum`, `segment_ids` need not be sorted and need not cover all values in the full range of valid values.
If the sum is empty for a given segment ID `i`, `output[i] = 0`. If the given segment ID `i` is negative, the value is dropped and will not be added to the sum of the segment.
`num_segments` should equal the number of distinct segment IDs.
<div style="width:70%; margin:auto; margin-bottom:10px; margin-top:20px;"> <img style="width:100%" src="https://www.tensorflow.org/images/UnsortedSegmentSum.png" alt> </div>
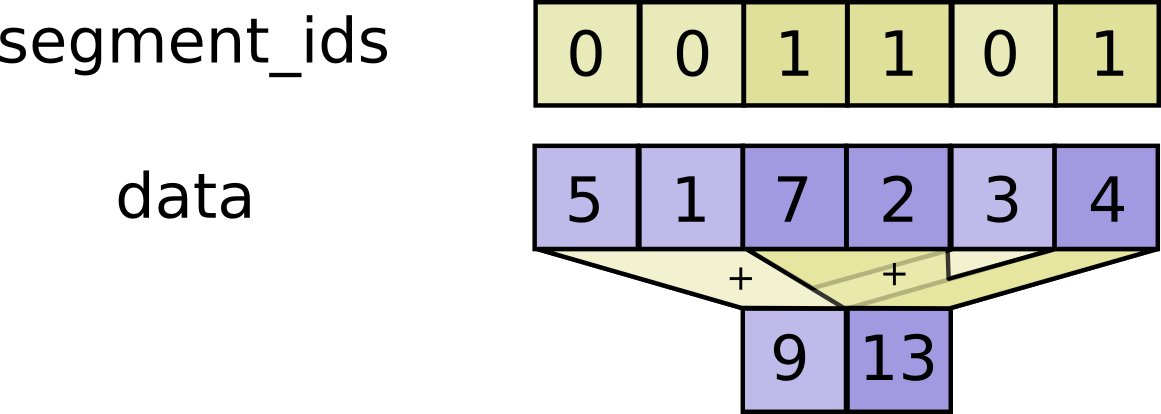{kind=link}
Arguments:
segment_ids: A tensor whose shape is a prefix of `data.shape`.
Returns Has same shape as data, except for the first `segment_ids.rank` dimensions, which are replaced with a single dimension which has size `num_segments`.
func Unstage ¶ added in v1.1.0
Op is similar to a lightweight Dequeue.
The basic functionality is similar to dequeue with many fewer capabilities and options. This Op is optimized for performance.
func VarHandleOp ¶ added in v1.1.0
func VarHandleOp(scope *Scope, dtype tf.DataType, shape tf.Shape, optional ...VarHandleOpAttr) (resource tf.Output)
Creates a handle to a Variable resource.
Arguments:
dtype: the type of this variable. Must agree with the dtypes
of all ops using this variable.
shape: The (possibly partially specified) shape of this variable.
func VarIsInitializedOp ¶ added in v1.1.0
Checks whether a resource handle-based variable has been initialized.
Arguments:
resource: the input resource handle.
Returns a scalar boolean which is true if the variable has been initialized.
func VariableShape ¶ added in v1.4.0
Returns the shape of the variable pointed to by `resource`.
This operation returns a 1-D integer tensor representing the shape of `input`.
For example:
``` # 't' is [[[1, 1, 1], [2, 2, 2]], [[3, 3, 3], [4, 4, 4]]] shape(t) ==> [2, 2, 3] ```
func Where ¶ added in v1.1.0
Returns locations of nonzero / true values in a tensor.
This operation returns the coordinates of true elements in `condition`. The coordinates are returned in a 2-D tensor where the first dimension (rows) represents the number of true elements, and the second dimension (columns) represents the coordinates of the true elements. Keep in mind, the shape of the output tensor can vary depending on how many true values there are in `condition`. Indices are output in row-major order.
For example:
``` # 'input' tensor is [[True, False] # [True, False]] # 'input' has two true values, so output has two coordinates. # 'input' has rank of 2, so coordinates have two indices. where(input) ==> [[0, 0],
[1, 0]]
# `condition` tensor is [[[True, False] # [True, False]] # [[False, True] # [False, True]] # [[False, False] # [False, True]]] # 'input' has 5 true values, so output has 5 coordinates. # 'input' has rank of 3, so coordinates have three indices. where(input) ==> [[0, 0, 0],
[0, 1, 0], [1, 0, 1], [1, 1, 1], [2, 1, 1]]
# `condition` tensor is [[[1.5, 0.0] # [-0.5, 0.0]] # [[0.0, 0.25] # [0.0, 0.75]] # [[0.0, 0.0] # [0.0, 0.01]]] # 'input' has 5 nonzero values, so output has 5 coordinates. # 'input' has rank of 3, so coordinates have three indices. where(input) ==> [[0, 0, 0],
[0, 1, 0], [1, 0, 1], [1, 1, 1], [2, 1, 1]]
# `condition` tensor is [[[1.5 + 0.0j, 0.0 + 0.0j] # [0.0 + 0.5j, 0.0 + 0.0j]] # [[0.0 + 0.0j, 0.25 + 1.5j] # [0.0 + 0.0j, 0.75 + 0.0j]] # [[0.0 + 0.0j, 0.0 + 0.0j] # [0.0 + 0.0j, 0.01 + 0.0j]]] # 'input' has 5 nonzero magnitude values, so output has 5 coordinates. # 'input' has rank of 3, so coordinates have three indices. where(input) ==> [[0, 0, 0],
[0, 1, 0], [1, 0, 1], [1, 1, 1], [2, 1, 1]]
```
func WholeFileReaderV2 ¶ added in v1.1.0
func WholeFileReaderV2(scope *Scope, optional ...WholeFileReaderV2Attr) (reader_handle tf.Output)
A Reader that outputs the entire contents of a file as a value.
To use, enqueue filenames in a Queue. The output of ReaderRead will be a filename (key) and the contents of that file (value).
Returns The handle to reference the Reader.
func WriteAudioSummary ¶ added in v1.4.0
func WriteAudioSummary(scope *Scope, writer tf.Output, step tf.Output, tag tf.Output, tensor tf.Output, sample_rate tf.Output, optional ...WriteAudioSummaryAttr) (o *tf.Operation)
Writes a `Summary` protocol buffer with audio.
The summary has up to `max_outputs` summary values containing audio. The audio is built from `tensor` which must be 3-D with shape `[batch_size, frames, channels]` or 2-D with shape `[batch_size, frames]`. The values are assumed to be in the range of `[-1.0, 1.0]` with a sample rate of `sample_rate`.
The `tag` argument is a scalar `Tensor` of type `string`. It is used to build the `tag` of the summary values:
- If `max_outputs` is 1, the summary value tag is '*tag*/audio'.
- If `max_outputs` is greater than 1, the summary value tags are generated sequentially as '*tag*/audio/0', '*tag*/audio/1', etc.
Arguments:
writer: A handle to a summary writer. step: The step to write the summary for. tag: Scalar. Used to build the `tag` attribute of the summary values. tensor: 2-D of shape `[batch_size, frames]`. sample_rate: The sample rate of the signal in hertz.
Returns the created operation.
func WriteFile ¶ added in v1.1.0
Writes contents to the file at input filename. Creates file and recursively
creates directory if not existing.
Arguments:
filename: scalar. The name of the file to which we write the contents. contents: scalar. The content to be written to the output file.
Returns the created operation.
func WriteGraphSummary ¶ added in v1.5.0
func WriteGraphSummary(scope *Scope, writer tf.Output, step tf.Output, tensor tf.Output) (o *tf.Operation)
Writes a `GraphDef` protocol buffer to a `SummaryWriter`.
Arguments:
writer: Handle of `SummaryWriter`. step: The step to write the summary for. tensor: A scalar string of the serialized tf.GraphDef proto.
Returns the created operation.
func WriteHistogramSummary ¶ added in v1.4.0
func WriteHistogramSummary(scope *Scope, writer tf.Output, step tf.Output, tag tf.Output, values tf.Output) (o *tf.Operation)
Writes a `Summary` protocol buffer with a histogram.
The generated [`Summary`](https://www.tensorflow.org/code/tensorflow/core/framework/summary.proto) has one summary value containing a histogram for `values`.
This op reports an `InvalidArgument` error if any value is not finite.
Arguments:
writer: A handle to a summary writer. step: The step to write the summary for. tag: Scalar. Tag to use for the `Summary.Value`. values: Any shape. Values to use to build the histogram.
Returns the created operation.
func WriteImageSummary ¶ added in v1.4.0
func WriteImageSummary(scope *Scope, writer tf.Output, step tf.Output, tag tf.Output, tensor tf.Output, bad_color tf.Output, optional ...WriteImageSummaryAttr) (o *tf.Operation)
Writes a `Summary` protocol buffer with images.
The summary has up to `max_images` summary values containing images. The images are built from `tensor` which must be 4-D with shape `[batch_size, height, width, channels]` and where `channels` can be:
* 1: `tensor` is interpreted as Grayscale. * 3: `tensor` is interpreted as RGB. * 4: `tensor` is interpreted as RGBA.
The images have the same number of channels as the input tensor. For float input, the values are normalized one image at a time to fit in the range `[0, 255]`. `uint8` values are unchanged. The op uses two different normalization algorithms:
- If the input values are all positive, they are rescaled so the largest one is 255.
- If any input value is negative, the values are shifted so input value 0.0 is at 127. They are then rescaled so that either the smallest value is 0, or the largest one is 255.
The `tag` argument is a scalar `Tensor` of type `string`. It is used to build the `tag` of the summary values:
- If `max_images` is 1, the summary value tag is '*tag*/image'.
- If `max_images` is greater than 1, the summary value tags are generated sequentially as '*tag*/image/0', '*tag*/image/1', etc.
The `bad_color` argument is the color to use in the generated images for non-finite input values. It is a `unit8` 1-D tensor of length `channels`. Each element must be in the range `[0, 255]` (It represents the value of a pixel in the output image). Non-finite values in the input tensor are replaced by this tensor in the output image. The default value is the color red.
Arguments:
writer: A handle to a summary writer. step: The step to write the summary for. tag: Scalar. Used to build the `tag` attribute of the summary values. tensor: 4-D of shape `[batch_size, height, width, channels]` where
`channels` is 1, 3, or 4.
bad_color: Color to use for pixels with non-finite values.
Returns the created operation.
func WriteScalarSummary ¶ added in v1.4.0
func WriteScalarSummary(scope *Scope, writer tf.Output, step tf.Output, tag tf.Output, value tf.Output) (o *tf.Operation)
Writes a `Summary` protocol buffer with scalar values.
The input `tag` and `value` must have the scalars.
Arguments:
writer: A handle to a summary writer. step: The step to write the summary for. tag: Tag for the summary. value: Value for the summary.
Returns the created operation.
func WriteSummary ¶ added in v1.4.0
func WriteSummary(scope *Scope, writer tf.Output, step tf.Output, tensor tf.Output, tag tf.Output, summary_metadata tf.Output) (o *tf.Operation)
Outputs a `Summary` protocol buffer with a tensor.
Arguments:
writer: A handle to a summary writer. step: The step to write the summary for. tensor: A tensor to serialize. tag: The summary's tag. summary_metadata: Serialized SummaryMetadata protocol buffer containing
plugin-related metadata for this summary.
Returns the created operation.
func ZerosLike ¶ added in v1.1.0
Returns a tensor of zeros with the same shape and type as x.
Arguments:
x: a tensor of type T.
Returns a tensor of the same shape and type as x but filled with zeros.
Types ¶
type AbortAttr ¶ added in v1.1.0
type AbortAttr func(optionalAttr)
AbortAttr is an optional argument to Abort.
func AbortErrorMsg ¶ added in v1.1.0
AbortErrorMsg sets the optional error_msg attribute to value.
value: A string which is the message associated with the exception. If not specified, defaults to ""
func AbortExitWithoutError ¶ added in v1.1.0
AbortExitWithoutError sets the optional exit_without_error attribute to value. If not specified, defaults to false
type AddManySparseToTensorsMapAttr ¶ added in v1.1.0
type AddManySparseToTensorsMapAttr func(optionalAttr)
AddManySparseToTensorsMapAttr is an optional argument to AddManySparseToTensorsMap.
func AddManySparseToTensorsMapContainer ¶ added in v1.1.0
func AddManySparseToTensorsMapContainer(value string) AddManySparseToTensorsMapAttr
AddManySparseToTensorsMapContainer sets the optional container attribute to value.
value: The container name for the `SparseTensorsMap` created by this op. If not specified, defaults to ""
func AddManySparseToTensorsMapSharedName ¶ added in v1.1.0
func AddManySparseToTensorsMapSharedName(value string) AddManySparseToTensorsMapAttr
AddManySparseToTensorsMapSharedName sets the optional shared_name attribute to value.
value: The shared name for the `SparseTensorsMap` created by this op. If blank, the new Operation's unique name is used. If not specified, defaults to ""
type AddSparseToTensorsMapAttr ¶ added in v1.1.0
type AddSparseToTensorsMapAttr func(optionalAttr)
AddSparseToTensorsMapAttr is an optional argument to AddSparseToTensorsMap.
func AddSparseToTensorsMapContainer ¶ added in v1.1.0
func AddSparseToTensorsMapContainer(value string) AddSparseToTensorsMapAttr
AddSparseToTensorsMapContainer sets the optional container attribute to value.
value: The container name for the `SparseTensorsMap` created by this op. If not specified, defaults to ""
func AddSparseToTensorsMapSharedName ¶ added in v1.1.0
func AddSparseToTensorsMapSharedName(value string) AddSparseToTensorsMapAttr
AddSparseToTensorsMapSharedName sets the optional shared_name attribute to value.
value: The shared name for the `SparseTensorsMap` created by this op. If blank, the new Operation's unique name is used. If not specified, defaults to ""
type AllAttr ¶ added in v1.1.0
type AllAttr func(optionalAttr)
AllAttr is an optional argument to All.
func AllKeepDims ¶ added in v1.1.0
AllKeepDims sets the optional keep_dims attribute to value.
value: If true, retain reduced dimensions with length 1. If not specified, defaults to false
type AllCandidateSamplerAttr ¶ added in v1.1.0
type AllCandidateSamplerAttr func(optionalAttr)
AllCandidateSamplerAttr is an optional argument to AllCandidateSampler.
func AllCandidateSamplerSeed ¶ added in v1.1.0
func AllCandidateSamplerSeed(value int64) AllCandidateSamplerAttr
AllCandidateSamplerSeed sets the optional seed attribute to value.
value: If either seed or seed2 are set to be non-zero, the random number generator is seeded by the given seed. Otherwise, it is seeded by a random seed. If not specified, defaults to 0
func AllCandidateSamplerSeed2 ¶ added in v1.1.0
func AllCandidateSamplerSeed2(value int64) AllCandidateSamplerAttr
AllCandidateSamplerSeed2 sets the optional seed2 attribute to value.
value: An second seed to avoid seed collision. If not specified, defaults to 0
type AngleAttr ¶ added in v1.4.0
type AngleAttr func(optionalAttr)
AngleAttr is an optional argument to Angle.
type AnyAttr ¶ added in v1.1.0
type AnyAttr func(optionalAttr)
AnyAttr is an optional argument to Any.
func AnyKeepDims ¶ added in v1.1.0
AnyKeepDims sets the optional keep_dims attribute to value.
value: If true, retain reduced dimensions with length 1. If not specified, defaults to false
type ApproximateEqualAttr ¶ added in v1.1.0
type ApproximateEqualAttr func(optionalAttr)
ApproximateEqualAttr is an optional argument to ApproximateEqual.
func ApproximateEqualTolerance ¶ added in v1.1.0
func ApproximateEqualTolerance(value float32) ApproximateEqualAttr
ApproximateEqualTolerance sets the optional tolerance attribute to value. If not specified, defaults to 1e-05
type ArgMaxAttr ¶ added in v1.3.0
type ArgMaxAttr func(optionalAttr)
ArgMaxAttr is an optional argument to ArgMax.
func ArgMaxOutputType ¶ added in v1.3.0
func ArgMaxOutputType(value tf.DataType) ArgMaxAttr
ArgMaxOutputType sets the optional output_type attribute to value. If not specified, defaults to DT_INT64
type ArgMinAttr ¶ added in v1.3.0
type ArgMinAttr func(optionalAttr)
ArgMinAttr is an optional argument to ArgMin.
func ArgMinOutputType ¶ added in v1.3.0
func ArgMinOutputType(value tf.DataType) ArgMinAttr
ArgMinOutputType sets the optional output_type attribute to value. If not specified, defaults to DT_INT64
type AsStringAttr ¶ added in v1.1.0
type AsStringAttr func(optionalAttr)
AsStringAttr is an optional argument to AsString.
func AsStringFill ¶ added in v1.1.0
func AsStringFill(value string) AsStringAttr
AsStringFill sets the optional fill attribute to value.
value: The value to pad if width > -1. If empty, pads with spaces. Another typical value is '0'. String cannot be longer than 1 character. If not specified, defaults to ""
func AsStringPrecision ¶ added in v1.1.0
func AsStringPrecision(value int64) AsStringAttr
AsStringPrecision sets the optional precision attribute to value.
value: The post-decimal precision to use for floating point numbers. Only used if precision > -1. If not specified, defaults to -1
func AsStringScientific ¶ added in v1.1.0
func AsStringScientific(value bool) AsStringAttr
AsStringScientific sets the optional scientific attribute to value.
value: Use scientific notation for floating point numbers. If not specified, defaults to false
func AsStringShortest ¶ added in v1.1.0
func AsStringShortest(value bool) AsStringAttr
AsStringShortest sets the optional shortest attribute to value.
value: Use shortest representation (either scientific or standard) for floating point numbers. If not specified, defaults to false
func AsStringWidth ¶ added in v1.1.0
func AsStringWidth(value int64) AsStringAttr
AsStringWidth sets the optional width attribute to value.
value: Pad pre-decimal numbers to this width. Applies to both floating point and integer numbers. Only used if width > -1. If not specified, defaults to -1
type AssertAttr ¶ added in v1.1.0
type AssertAttr func(optionalAttr)
AssertAttr is an optional argument to Assert.
func AssertSummarize ¶ added in v1.1.0
func AssertSummarize(value int64) AssertAttr
AssertSummarize sets the optional summarize attribute to value.
value: Print this many entries of each tensor. If not specified, defaults to 3
type AudioSpectrogramAttr ¶ added in v1.2.0
type AudioSpectrogramAttr func(optionalAttr)
AudioSpectrogramAttr is an optional argument to AudioSpectrogram.
func AudioSpectrogramMagnitudeSquared ¶ added in v1.2.0
func AudioSpectrogramMagnitudeSquared(value bool) AudioSpectrogramAttr
AudioSpectrogramMagnitudeSquared sets the optional magnitude_squared attribute to value.
value: Whether to return the squared magnitude or just the magnitude. Using squared magnitude can avoid extra calculations. If not specified, defaults to false
type AudioSummaryAttr ¶ added in v1.1.0
type AudioSummaryAttr func(optionalAttr)
AudioSummaryAttr is an optional argument to AudioSummary.
func AudioSummaryMaxOutputs ¶ added in v1.1.0
func AudioSummaryMaxOutputs(value int64) AudioSummaryAttr
AudioSummaryMaxOutputs sets the optional max_outputs attribute to value.
value: Max number of batch elements to generate audio for. If not specified, defaults to 3
REQUIRES: value >= 1
type AudioSummaryV2Attr ¶ added in v1.1.0
type AudioSummaryV2Attr func(optionalAttr)
AudioSummaryV2Attr is an optional argument to AudioSummaryV2.
func AudioSummaryV2MaxOutputs ¶ added in v1.1.0
func AudioSummaryV2MaxOutputs(value int64) AudioSummaryV2Attr
AudioSummaryV2MaxOutputs sets the optional max_outputs attribute to value.
value: Max number of batch elements to generate audio for. If not specified, defaults to 3
REQUIRES: value >= 1
type AvgPool3DAttr ¶ added in v1.2.0
type AvgPool3DAttr func(optionalAttr)
AvgPool3DAttr is an optional argument to AvgPool3D.
func AvgPool3DDataFormat ¶ added in v1.2.0
func AvgPool3DDataFormat(value string) AvgPool3DAttr
AvgPool3DDataFormat sets the optional data_format attribute to value.
value: The data format of the input and output data. With the default format "NDHWC", the data is stored in the order of:
[batch, in_depth, in_height, in_width, in_channels].
Alternatively, the format could be "NCDHW", the data storage order is:
[batch, in_channels, in_depth, in_height, in_width].
If not specified, defaults to "NDHWC"
type AvgPool3DGradAttr ¶ added in v1.2.0
type AvgPool3DGradAttr func(optionalAttr)
AvgPool3DGradAttr is an optional argument to AvgPool3DGrad.
func AvgPool3DGradDataFormat ¶ added in v1.2.0
func AvgPool3DGradDataFormat(value string) AvgPool3DGradAttr
AvgPool3DGradDataFormat sets the optional data_format attribute to value.
value: The data format of the input and output data. With the default format "NDHWC", the data is stored in the order of:
[batch, in_depth, in_height, in_width, in_channels].
Alternatively, the format could be "NCDHW", the data storage order is:
[batch, in_channels, in_depth, in_height, in_width].
If not specified, defaults to "NDHWC"
type AvgPoolAttr ¶ added in v1.1.0
type AvgPoolAttr func(optionalAttr)
AvgPoolAttr is an optional argument to AvgPool.
func AvgPoolDataFormat ¶ added in v1.1.0
func AvgPoolDataFormat(value string) AvgPoolAttr
AvgPoolDataFormat sets the optional data_format attribute to value.
value: Specify the data format of the input and output data. With the default format "NHWC", the data is stored in the order of:
[batch, in_height, in_width, in_channels].
Alternatively, the format could be "NCHW", the data storage order of:
[batch, in_channels, in_height, in_width].
If not specified, defaults to "NHWC"
type AvgPoolGradAttr ¶ added in v1.1.0
type AvgPoolGradAttr func(optionalAttr)
AvgPoolGradAttr is an optional argument to AvgPoolGrad.
func AvgPoolGradDataFormat ¶ added in v1.1.0
func AvgPoolGradDataFormat(value string) AvgPoolGradAttr
AvgPoolGradDataFormat sets the optional data_format attribute to value.
value: Specify the data format of the input and output data. With the default format "NHWC", the data is stored in the order of:
[batch, in_height, in_width, in_channels].
Alternatively, the format could be "NCHW", the data storage order of:
[batch, in_channels, in_height, in_width].
If not specified, defaults to "NHWC"
type BatchMatMulAttr ¶ added in v1.1.0
type BatchMatMulAttr func(optionalAttr)
BatchMatMulAttr is an optional argument to BatchMatMul.
func BatchMatMulAdjX ¶ added in v1.1.0
func BatchMatMulAdjX(value bool) BatchMatMulAttr
BatchMatMulAdjX sets the optional adj_x attribute to value.
value: If `True`, adjoint the slices of `x`. Defaults to `False`. If not specified, defaults to false
func BatchMatMulAdjY ¶ added in v1.1.0
func BatchMatMulAdjY(value bool) BatchMatMulAttr
BatchMatMulAdjY sets the optional adj_y attribute to value.
value: If `True`, adjoint the slices of `y`. Defaults to `False`. If not specified, defaults to false
type BiasAddAttr ¶ added in v1.1.0
type BiasAddAttr func(optionalAttr)
BiasAddAttr is an optional argument to BiasAdd.
func BiasAddDataFormat ¶ added in v1.1.0
func BiasAddDataFormat(value string) BiasAddAttr
BiasAddDataFormat sets the optional data_format attribute to value.
value: Specify the data format of the input and output data. With the default format "NHWC", the bias tensor will be added to the last dimension of the value tensor. Alternatively, the format could be "NCHW", the data storage order of:
[batch, in_channels, in_height, in_width].
The tensor will be added to "in_channels", the third-to-the-last
dimension.
If not specified, defaults to "NHWC"
type BiasAddGradAttr ¶ added in v1.1.0
type BiasAddGradAttr func(optionalAttr)
BiasAddGradAttr is an optional argument to BiasAddGrad.
func BiasAddGradDataFormat ¶ added in v1.1.0
func BiasAddGradDataFormat(value string) BiasAddGradAttr
BiasAddGradDataFormat sets the optional data_format attribute to value.
value: Specify the data format of the input and output data. With the default format "NHWC", the bias tensor will be added to the last dimension of the value tensor. Alternatively, the format could be "NCHW", the data storage order of:
[batch, in_channels, in_height, in_width].
The tensor will be added to "in_channels", the third-to-the-last
dimension.
If not specified, defaults to "NHWC"
type CTCBeamSearchDecoderAttr ¶ added in v1.1.0
type CTCBeamSearchDecoderAttr func(optionalAttr)
CTCBeamSearchDecoderAttr is an optional argument to CTCBeamSearchDecoder.
func CTCBeamSearchDecoderMergeRepeated ¶ added in v1.1.0
func CTCBeamSearchDecoderMergeRepeated(value bool) CTCBeamSearchDecoderAttr
CTCBeamSearchDecoderMergeRepeated sets the optional merge_repeated attribute to value.
value: If true, merge repeated classes in output. If not specified, defaults to true
type CTCGreedyDecoderAttr ¶ added in v1.1.0
type CTCGreedyDecoderAttr func(optionalAttr)
CTCGreedyDecoderAttr is an optional argument to CTCGreedyDecoder.
func CTCGreedyDecoderMergeRepeated ¶ added in v1.1.0
func CTCGreedyDecoderMergeRepeated(value bool) CTCGreedyDecoderAttr
CTCGreedyDecoderMergeRepeated sets the optional merge_repeated attribute to value.
value: If True, merge repeated classes in output. If not specified, defaults to false
type CTCLossAttr ¶ added in v1.1.0
type CTCLossAttr func(optionalAttr)
CTCLossAttr is an optional argument to CTCLoss.
func CTCLossCtcMergeRepeated ¶ added in v1.1.0
func CTCLossCtcMergeRepeated(value bool) CTCLossAttr
CTCLossCtcMergeRepeated sets the optional ctc_merge_repeated attribute to value.
value: Scalar. If set to false, *during* CTC calculation repeated non-blank labels will not be merged and are interpreted as individual labels. This is a simplified version of CTC. If not specified, defaults to true
func CTCLossIgnoreLongerOutputsThanInputs ¶ added in v1.2.0
func CTCLossIgnoreLongerOutputsThanInputs(value bool) CTCLossAttr
CTCLossIgnoreLongerOutputsThanInputs sets the optional ignore_longer_outputs_than_inputs attribute to value.
value: Scalar. If set to true, during CTC calculation, items that have longer output sequences than input sequences are skipped: they don't contribute to the loss term and have zero-gradient. If not specified, defaults to false
func CTCLossPreprocessCollapseRepeated ¶ added in v1.1.0
func CTCLossPreprocessCollapseRepeated(value bool) CTCLossAttr
CTCLossPreprocessCollapseRepeated sets the optional preprocess_collapse_repeated attribute to value.
value: Scalar, if true then repeated labels are collapsed prior to the CTC calculation. If not specified, defaults to false
type ComplexAbsAttr ¶ added in v1.1.0
type ComplexAbsAttr func(optionalAttr)
ComplexAbsAttr is an optional argument to ComplexAbs.
func ComplexAbsTout ¶ added in v1.1.0
func ComplexAbsTout(value tf.DataType) ComplexAbsAttr
ComplexAbsTout sets the optional Tout attribute to value. If not specified, defaults to DT_FLOAT
type ComplexAttr ¶ added in v1.1.0
type ComplexAttr func(optionalAttr)
ComplexAttr is an optional argument to Complex.
func ComplexTout ¶ added in v1.1.0
func ComplexTout(value tf.DataType) ComplexAttr
ComplexTout sets the optional Tout attribute to value. If not specified, defaults to DT_COMPLEX64
type ComputeAccidentalHitsAttr ¶ added in v1.1.0
type ComputeAccidentalHitsAttr func(optionalAttr)
ComputeAccidentalHitsAttr is an optional argument to ComputeAccidentalHits.
func ComputeAccidentalHitsSeed ¶ added in v1.1.0
func ComputeAccidentalHitsSeed(value int64) ComputeAccidentalHitsAttr
ComputeAccidentalHitsSeed sets the optional seed attribute to value.
value: If either seed or seed2 are set to be non-zero, the random number generator is seeded by the given seed. Otherwise, it is seeded by a random seed. If not specified, defaults to 0
func ComputeAccidentalHitsSeed2 ¶ added in v1.1.0
func ComputeAccidentalHitsSeed2(value int64) ComputeAccidentalHitsAttr
ComputeAccidentalHitsSeed2 sets the optional seed2 attribute to value.
value: An second seed to avoid seed collision. If not specified, defaults to 0
type Conv2DAttr ¶ added in v1.1.0
type Conv2DAttr func(optionalAttr)
Conv2DAttr is an optional argument to Conv2D.
func Conv2DDataFormat ¶ added in v1.1.0
func Conv2DDataFormat(value string) Conv2DAttr
Conv2DDataFormat sets the optional data_format attribute to value.
value: Specify the data format of the input and output data. With the default format "NHWC", the data is stored in the order of:
[batch, height, width, channels].
Alternatively, the format could be "NCHW", the data storage order of:
[batch, channels, height, width].
If not specified, defaults to "NHWC"
func Conv2DDilations ¶ added in v1.6.0
func Conv2DDilations(value []int64) Conv2DAttr
Conv2DDilations sets the optional dilations attribute to value.
value: 1-D tensor of length 4. The dilation factor for each dimension of `input`. If set to k > 1, there will be k-1 skipped cells between each filter element on that dimension. The dimension order is determined by the value of `data_format`, see above for details. Dilations in the batch and depth dimensions must be 1. If not specified, defaults to <i:1 i:1 i:1 i:1 >
func Conv2DUseCudnnOnGpu ¶ added in v1.1.0
func Conv2DUseCudnnOnGpu(value bool) Conv2DAttr
Conv2DUseCudnnOnGpu sets the optional use_cudnn_on_gpu attribute to value. If not specified, defaults to true
type Conv2DBackpropFilterAttr ¶ added in v1.1.0
type Conv2DBackpropFilterAttr func(optionalAttr)
Conv2DBackpropFilterAttr is an optional argument to Conv2DBackpropFilter.
func Conv2DBackpropFilterDataFormat ¶ added in v1.1.0
func Conv2DBackpropFilterDataFormat(value string) Conv2DBackpropFilterAttr
Conv2DBackpropFilterDataFormat sets the optional data_format attribute to value.
value: Specify the data format of the input and output data. With the default format "NHWC", the data is stored in the order of:
[batch, in_height, in_width, in_channels].
Alternatively, the format could be "NCHW", the data storage order of:
[batch, in_channels, in_height, in_width].
If not specified, defaults to "NHWC"
func Conv2DBackpropFilterDilations ¶ added in v1.6.0
func Conv2DBackpropFilterDilations(value []int64) Conv2DBackpropFilterAttr
Conv2DBackpropFilterDilations sets the optional dilations attribute to value.
value: 1-D tensor of length 4. The dilation factor for each dimension of `input`. If set to k > 1, there will be k-1 skipped cells between each filter element on that dimension. The dimension order is determined by the value of `data_format`, see above for details. Dilations in the batch and depth dimensions must be 1. If not specified, defaults to <i:1 i:1 i:1 i:1 >
func Conv2DBackpropFilterUseCudnnOnGpu ¶ added in v1.1.0
func Conv2DBackpropFilterUseCudnnOnGpu(value bool) Conv2DBackpropFilterAttr
Conv2DBackpropFilterUseCudnnOnGpu sets the optional use_cudnn_on_gpu attribute to value. If not specified, defaults to true
type Conv2DBackpropInputAttr ¶ added in v1.1.0
type Conv2DBackpropInputAttr func(optionalAttr)
Conv2DBackpropInputAttr is an optional argument to Conv2DBackpropInput.
func Conv2DBackpropInputDataFormat ¶ added in v1.1.0
func Conv2DBackpropInputDataFormat(value string) Conv2DBackpropInputAttr
Conv2DBackpropInputDataFormat sets the optional data_format attribute to value.
value: Specify the data format of the input and output data. With the default format "NHWC", the data is stored in the order of:
[batch, in_height, in_width, in_channels].
Alternatively, the format could be "NCHW", the data storage order of:
[batch, in_channels, in_height, in_width].
If not specified, defaults to "NHWC"
func Conv2DBackpropInputDilations ¶ added in v1.6.0
func Conv2DBackpropInputDilations(value []int64) Conv2DBackpropInputAttr
Conv2DBackpropInputDilations sets the optional dilations attribute to value.
value: 1-D tensor of length 4. The dilation factor for each dimension of `input`. If set to k > 1, there will be k-1 skipped cells between each filter element on that dimension. The dimension order is determined by the value of `data_format`, see above for details. Dilations in the batch and depth dimensions must be 1. If not specified, defaults to <i:1 i:1 i:1 i:1 >
func Conv2DBackpropInputUseCudnnOnGpu ¶ added in v1.1.0
func Conv2DBackpropInputUseCudnnOnGpu(value bool) Conv2DBackpropInputAttr
Conv2DBackpropInputUseCudnnOnGpu sets the optional use_cudnn_on_gpu attribute to value. If not specified, defaults to true
type Conv3DAttr ¶ added in v1.2.0
type Conv3DAttr func(optionalAttr)
Conv3DAttr is an optional argument to Conv3D.
func Conv3DDataFormat ¶ added in v1.2.0
func Conv3DDataFormat(value string) Conv3DAttr
Conv3DDataFormat sets the optional data_format attribute to value.
value: The data format of the input and output data. With the default format "NDHWC", the data is stored in the order of:
[batch, in_depth, in_height, in_width, in_channels].
Alternatively, the format could be "NCDHW", the data storage order is:
[batch, in_channels, in_depth, in_height, in_width].
If not specified, defaults to "NDHWC"
func Conv3DDilations ¶ added in v1.6.0
func Conv3DDilations(value []int64) Conv3DAttr
Conv3DDilations sets the optional dilations attribute to value.
value: 1-D tensor of length 5. The dilation factor for each dimension of `input`. If set to k > 1, there will be k-1 skipped cells between each filter element on that dimension. The dimension order is determined by the value of `data_format`, see above for details. Dilations in the batch and depth dimensions must be 1. If not specified, defaults to <i:1 i:1 i:1 i:1 i:1 >
type Conv3DBackpropFilterV2Attr ¶ added in v1.2.0
type Conv3DBackpropFilterV2Attr func(optionalAttr)
Conv3DBackpropFilterV2Attr is an optional argument to Conv3DBackpropFilterV2.
func Conv3DBackpropFilterV2DataFormat ¶ added in v1.2.0
func Conv3DBackpropFilterV2DataFormat(value string) Conv3DBackpropFilterV2Attr
Conv3DBackpropFilterV2DataFormat sets the optional data_format attribute to value.
value: The data format of the input and output data. With the default format "NDHWC", the data is stored in the order of:
[batch, in_depth, in_height, in_width, in_channels].
Alternatively, the format could be "NCDHW", the data storage order is:
[batch, in_channels, in_depth, in_height, in_width].
If not specified, defaults to "NDHWC"
func Conv3DBackpropFilterV2Dilations ¶ added in v1.6.0
func Conv3DBackpropFilterV2Dilations(value []int64) Conv3DBackpropFilterV2Attr
Conv3DBackpropFilterV2Dilations sets the optional dilations attribute to value.
value: 1-D tensor of length 5. The dilation factor for each dimension of `input`. If set to k > 1, there will be k-1 skipped cells between each filter element on that dimension. The dimension order is determined by the value of `data_format`, see above for details. Dilations in the batch and depth dimensions must be 1. If not specified, defaults to <i:1 i:1 i:1 i:1 i:1 >
type Conv3DBackpropInputV2Attr ¶ added in v1.2.0
type Conv3DBackpropInputV2Attr func(optionalAttr)
Conv3DBackpropInputV2Attr is an optional argument to Conv3DBackpropInputV2.
func Conv3DBackpropInputV2DataFormat ¶ added in v1.2.0
func Conv3DBackpropInputV2DataFormat(value string) Conv3DBackpropInputV2Attr
Conv3DBackpropInputV2DataFormat sets the optional data_format attribute to value.
value: The data format of the input and output data. With the default format "NDHWC", the data is stored in the order of:
[batch, in_depth, in_height, in_width, in_channels].
Alternatively, the format could be "NCDHW", the data storage order is:
[batch, in_channels, in_depth, in_height, in_width].
If not specified, defaults to "NDHWC"
func Conv3DBackpropInputV2Dilations ¶ added in v1.6.0
func Conv3DBackpropInputV2Dilations(value []int64) Conv3DBackpropInputV2Attr
Conv3DBackpropInputV2Dilations sets the optional dilations attribute to value.
value: 1-D tensor of length 5. The dilation factor for each dimension of `input`. If set to k > 1, there will be k-1 skipped cells between each filter element on that dimension. The dimension order is determined by the value of `data_format`, see above for details. Dilations in the batch and depth dimensions must be 1. If not specified, defaults to <i:1 i:1 i:1 i:1 i:1 >
type CropAndResizeAttr ¶ added in v1.1.0
type CropAndResizeAttr func(optionalAttr)
CropAndResizeAttr is an optional argument to CropAndResize.
func CropAndResizeExtrapolationValue ¶ added in v1.1.0
func CropAndResizeExtrapolationValue(value float32) CropAndResizeAttr
CropAndResizeExtrapolationValue sets the optional extrapolation_value attribute to value.
value: Value used for extrapolation, when applicable. If not specified, defaults to 0
func CropAndResizeMethod ¶ added in v1.1.0
func CropAndResizeMethod(value string) CropAndResizeAttr
CropAndResizeMethod sets the optional method attribute to value.
value: A string specifying the interpolation method. Only 'bilinear' is supported for now. If not specified, defaults to "bilinear"
type CropAndResizeGradBoxesAttr ¶ added in v1.1.0
type CropAndResizeGradBoxesAttr func(optionalAttr)
CropAndResizeGradBoxesAttr is an optional argument to CropAndResizeGradBoxes.
func CropAndResizeGradBoxesMethod ¶ added in v1.1.0
func CropAndResizeGradBoxesMethod(value string) CropAndResizeGradBoxesAttr
CropAndResizeGradBoxesMethod sets the optional method attribute to value.
value: A string specifying the interpolation method. Only 'bilinear' is supported for now. If not specified, defaults to "bilinear"
type CropAndResizeGradImageAttr ¶ added in v1.1.0
type CropAndResizeGradImageAttr func(optionalAttr)
CropAndResizeGradImageAttr is an optional argument to CropAndResizeGradImage.
func CropAndResizeGradImageMethod ¶ added in v1.1.0
func CropAndResizeGradImageMethod(value string) CropAndResizeGradImageAttr
CropAndResizeGradImageMethod sets the optional method attribute to value.
value: A string specifying the interpolation method. Only 'bilinear' is supported for now. If not specified, defaults to "bilinear"
type CumprodAttr ¶ added in v1.1.0
type CumprodAttr func(optionalAttr)
CumprodAttr is an optional argument to Cumprod.
func CumprodExclusive ¶ added in v1.1.0
func CumprodExclusive(value bool) CumprodAttr
CumprodExclusive sets the optional exclusive attribute to value.
value: If `True`, perform exclusive cumprod. If not specified, defaults to false
func CumprodReverse ¶ added in v1.1.0
func CumprodReverse(value bool) CumprodAttr
CumprodReverse sets the optional reverse attribute to value.
value: A `bool` (default: False). If not specified, defaults to false
type CumsumAttr ¶ added in v1.1.0
type CumsumAttr func(optionalAttr)
CumsumAttr is an optional argument to Cumsum.
func CumsumExclusive ¶ added in v1.1.0
func CumsumExclusive(value bool) CumsumAttr
CumsumExclusive sets the optional exclusive attribute to value.
value: If `True`, perform exclusive cumsum. If not specified, defaults to false
func CumsumReverse ¶ added in v1.1.0
func CumsumReverse(value bool) CumsumAttr
CumsumReverse sets the optional reverse attribute to value.
value: A `bool` (default: False). If not specified, defaults to false
type DataFormatDimMapAttr ¶ added in v1.6.0
type DataFormatDimMapAttr func(optionalAttr)
DataFormatDimMapAttr is an optional argument to DataFormatDimMap.
func DataFormatDimMapDstFormat ¶ added in v1.6.0
func DataFormatDimMapDstFormat(value string) DataFormatDimMapAttr
DataFormatDimMapDstFormat sets the optional dst_format attribute to value.
value: destination data format. If not specified, defaults to "NCHW"
func DataFormatDimMapSrcFormat ¶ added in v1.6.0
func DataFormatDimMapSrcFormat(value string) DataFormatDimMapAttr
DataFormatDimMapSrcFormat sets the optional src_format attribute to value.
value: source data format. If not specified, defaults to "NHWC"
type DataFormatVecPermuteAttr ¶ added in v1.6.0
type DataFormatVecPermuteAttr func(optionalAttr)
DataFormatVecPermuteAttr is an optional argument to DataFormatVecPermute.
func DataFormatVecPermuteDstFormat ¶ added in v1.6.0
func DataFormatVecPermuteDstFormat(value string) DataFormatVecPermuteAttr
DataFormatVecPermuteDstFormat sets the optional dst_format attribute to value.
value: destination data format. If not specified, defaults to "NCHW"
func DataFormatVecPermuteSrcFormat ¶ added in v1.6.0
func DataFormatVecPermuteSrcFormat(value string) DataFormatVecPermuteAttr
DataFormatVecPermuteSrcFormat sets the optional src_format attribute to value.
value: source data format. If not specified, defaults to "NHWC"
type DecodeAndCropJpegAttr ¶ added in v1.4.0
type DecodeAndCropJpegAttr func(optionalAttr)
DecodeAndCropJpegAttr is an optional argument to DecodeAndCropJpeg.
func DecodeAndCropJpegAcceptableFraction ¶ added in v1.4.0
func DecodeAndCropJpegAcceptableFraction(value float32) DecodeAndCropJpegAttr
DecodeAndCropJpegAcceptableFraction sets the optional acceptable_fraction attribute to value.
value: The minimum required fraction of lines before a truncated input is accepted. If not specified, defaults to 1
func DecodeAndCropJpegChannels ¶ added in v1.4.0
func DecodeAndCropJpegChannels(value int64) DecodeAndCropJpegAttr
DecodeAndCropJpegChannels sets the optional channels attribute to value.
value: Number of color channels for the decoded image. If not specified, defaults to 0
func DecodeAndCropJpegDctMethod ¶ added in v1.4.0
func DecodeAndCropJpegDctMethod(value string) DecodeAndCropJpegAttr
DecodeAndCropJpegDctMethod sets the optional dct_method attribute to value.
value: string specifying a hint about the algorithm used for decompression. Defaults to "" which maps to a system-specific default. Currently valid values are ["INTEGER_FAST", "INTEGER_ACCURATE"]. The hint may be ignored (e.g., the internal jpeg library changes to a version that does not have that specific option.) If not specified, defaults to ""
func DecodeAndCropJpegFancyUpscaling ¶ added in v1.4.0
func DecodeAndCropJpegFancyUpscaling(value bool) DecodeAndCropJpegAttr
DecodeAndCropJpegFancyUpscaling sets the optional fancy_upscaling attribute to value.
value: If true use a slower but nicer upscaling of the chroma planes (yuv420/422 only). If not specified, defaults to true
func DecodeAndCropJpegRatio ¶ added in v1.4.0
func DecodeAndCropJpegRatio(value int64) DecodeAndCropJpegAttr
DecodeAndCropJpegRatio sets the optional ratio attribute to value.
value: Downscaling ratio. If not specified, defaults to 1
func DecodeAndCropJpegTryRecoverTruncated ¶ added in v1.4.0
func DecodeAndCropJpegTryRecoverTruncated(value bool) DecodeAndCropJpegAttr
DecodeAndCropJpegTryRecoverTruncated sets the optional try_recover_truncated attribute to value.
value: If true try to recover an image from truncated input. If not specified, defaults to false
type DecodeBmpAttr ¶ added in v1.3.0
type DecodeBmpAttr func(optionalAttr)
DecodeBmpAttr is an optional argument to DecodeBmp.
func DecodeBmpChannels ¶ added in v1.3.0
func DecodeBmpChannels(value int64) DecodeBmpAttr
DecodeBmpChannels sets the optional channels attribute to value. If not specified, defaults to 0
type DecodeCSVAttr ¶ added in v1.1.0
type DecodeCSVAttr func(optionalAttr)
DecodeCSVAttr is an optional argument to DecodeCSV.
func DecodeCSVFieldDelim ¶ added in v1.1.0
func DecodeCSVFieldDelim(value string) DecodeCSVAttr
DecodeCSVFieldDelim sets the optional field_delim attribute to value.
value: char delimiter to separate fields in a record. If not specified, defaults to ","
func DecodeCSVNaValue ¶ added in v1.5.0
func DecodeCSVNaValue(value string) DecodeCSVAttr
DecodeCSVNaValue sets the optional na_value attribute to value.
value: Additional string to recognize as NA/NaN. If not specified, defaults to ""
func DecodeCSVUseQuoteDelim ¶ added in v1.3.0
func DecodeCSVUseQuoteDelim(value bool) DecodeCSVAttr
DecodeCSVUseQuoteDelim sets the optional use_quote_delim attribute to value.
value: If false, treats double quotation marks as regular characters inside of the string fields (ignoring RFC 4180, Section 2, Bullet 5). If not specified, defaults to true
type DecodeCompressedAttr ¶ added in v1.6.0
type DecodeCompressedAttr func(optionalAttr)
DecodeCompressedAttr is an optional argument to DecodeCompressed.
func DecodeCompressedCompressionType ¶ added in v1.6.0
func DecodeCompressedCompressionType(value string) DecodeCompressedAttr
DecodeCompressedCompressionType sets the optional compression_type attribute to value.
value: A scalar containing either (i) the empty string (no compression), (ii) "ZLIB", or (iii) "GZIP". If not specified, defaults to ""
type DecodeJpegAttr ¶ added in v1.1.0
type DecodeJpegAttr func(optionalAttr)
DecodeJpegAttr is an optional argument to DecodeJpeg.
func DecodeJpegAcceptableFraction ¶ added in v1.1.0
func DecodeJpegAcceptableFraction(value float32) DecodeJpegAttr
DecodeJpegAcceptableFraction sets the optional acceptable_fraction attribute to value.
value: The minimum required fraction of lines before a truncated input is accepted. If not specified, defaults to 1
func DecodeJpegChannels ¶ added in v1.1.0
func DecodeJpegChannels(value int64) DecodeJpegAttr
DecodeJpegChannels sets the optional channels attribute to value.
value: Number of color channels for the decoded image. If not specified, defaults to 0
func DecodeJpegDctMethod ¶ added in v1.1.0
func DecodeJpegDctMethod(value string) DecodeJpegAttr
DecodeJpegDctMethod sets the optional dct_method attribute to value.
value: string specifying a hint about the algorithm used for decompression. Defaults to "" which maps to a system-specific default. Currently valid values are ["INTEGER_FAST", "INTEGER_ACCURATE"]. The hint may be ignored (e.g., the internal jpeg library changes to a version that does not have that specific option.) If not specified, defaults to ""
func DecodeJpegFancyUpscaling ¶ added in v1.1.0
func DecodeJpegFancyUpscaling(value bool) DecodeJpegAttr
DecodeJpegFancyUpscaling sets the optional fancy_upscaling attribute to value.
value: If true use a slower but nicer upscaling of the chroma planes (yuv420/422 only). If not specified, defaults to true
func DecodeJpegRatio ¶ added in v1.1.0
func DecodeJpegRatio(value int64) DecodeJpegAttr
DecodeJpegRatio sets the optional ratio attribute to value.
value: Downscaling ratio. If not specified, defaults to 1
func DecodeJpegTryRecoverTruncated ¶ added in v1.1.0
func DecodeJpegTryRecoverTruncated(value bool) DecodeJpegAttr
DecodeJpegTryRecoverTruncated sets the optional try_recover_truncated attribute to value.
value: If true try to recover an image from truncated input. If not specified, defaults to false
type DecodePngAttr ¶ added in v1.1.0
type DecodePngAttr func(optionalAttr)
DecodePngAttr is an optional argument to DecodePng.
func DecodePngChannels ¶ added in v1.1.0
func DecodePngChannels(value int64) DecodePngAttr
DecodePngChannels sets the optional channels attribute to value.
value: Number of color channels for the decoded image. If not specified, defaults to 0
func DecodePngDtype ¶ added in v1.1.0
func DecodePngDtype(value tf.DataType) DecodePngAttr
DecodePngDtype sets the optional dtype attribute to value. If not specified, defaults to DT_UINT8
type DecodeRawAttr ¶ added in v1.1.0
type DecodeRawAttr func(optionalAttr)
DecodeRawAttr is an optional argument to DecodeRaw.
func DecodeRawLittleEndian ¶ added in v1.1.0
func DecodeRawLittleEndian(value bool) DecodeRawAttr
DecodeRawLittleEndian sets the optional little_endian attribute to value.
value: Whether the input `bytes` are in little-endian order. Ignored for `out_type` values that are stored in a single byte like `uint8`. If not specified, defaults to true
type DecodeWavAttr ¶ added in v1.2.0
type DecodeWavAttr func(optionalAttr)
DecodeWavAttr is an optional argument to DecodeWav.
func DecodeWavDesiredChannels ¶ added in v1.2.0
func DecodeWavDesiredChannels(value int64) DecodeWavAttr
DecodeWavDesiredChannels sets the optional desired_channels attribute to value.
value: Number of sample channels wanted. If not specified, defaults to -1
func DecodeWavDesiredSamples ¶ added in v1.2.0
func DecodeWavDesiredSamples(value int64) DecodeWavAttr
DecodeWavDesiredSamples sets the optional desired_samples attribute to value.
value: Length of audio requested. If not specified, defaults to -1
type DenseToDenseSetOperationAttr ¶ added in v1.1.0
type DenseToDenseSetOperationAttr func(optionalAttr)
DenseToDenseSetOperationAttr is an optional argument to DenseToDenseSetOperation.
func DenseToDenseSetOperationValidateIndices ¶ added in v1.1.0
func DenseToDenseSetOperationValidateIndices(value bool) DenseToDenseSetOperationAttr
DenseToDenseSetOperationValidateIndices sets the optional validate_indices attribute to value. If not specified, defaults to true
type DenseToSparseSetOperationAttr ¶ added in v1.1.0
type DenseToSparseSetOperationAttr func(optionalAttr)
DenseToSparseSetOperationAttr is an optional argument to DenseToSparseSetOperation.
func DenseToSparseSetOperationValidateIndices ¶ added in v1.1.0
func DenseToSparseSetOperationValidateIndices(value bool) DenseToSparseSetOperationAttr
DenseToSparseSetOperationValidateIndices sets the optional validate_indices attribute to value. If not specified, defaults to true
type DepthToSpaceAttr ¶ added in v1.4.0
type DepthToSpaceAttr func(optionalAttr)
DepthToSpaceAttr is an optional argument to DepthToSpace.
func DepthToSpaceDataFormat ¶ added in v1.4.0
func DepthToSpaceDataFormat(value string) DepthToSpaceAttr
DepthToSpaceDataFormat sets the optional data_format attribute to value. If not specified, defaults to "NHWC"
type DepthwiseConv2dNativeAttr ¶ added in v1.1.0
type DepthwiseConv2dNativeAttr func(optionalAttr)
DepthwiseConv2dNativeAttr is an optional argument to DepthwiseConv2dNative.
func DepthwiseConv2dNativeDataFormat ¶ added in v1.1.0
func DepthwiseConv2dNativeDataFormat(value string) DepthwiseConv2dNativeAttr
DepthwiseConv2dNativeDataFormat sets the optional data_format attribute to value.
value: Specify the data format of the input and output data. With the default format "NHWC", the data is stored in the order of:
[batch, height, width, channels].
Alternatively, the format could be "NCHW", the data storage order of:
[batch, channels, height, width].
If not specified, defaults to "NHWC"
func DepthwiseConv2dNativeDilations ¶ added in v1.6.0
func DepthwiseConv2dNativeDilations(value []int64) DepthwiseConv2dNativeAttr
DepthwiseConv2dNativeDilations sets the optional dilations attribute to value.
value: 1-D tensor of length 4. The dilation factor for each dimension of `input`. If set to k > 1, there will be k-1 skipped cells between each filter element on that dimension. The dimension order is determined by the value of `data_format`, see above for details. Dilations in the batch and depth dimensions must be 1. If not specified, defaults to <i:1 i:1 i:1 i:1 >
type DepthwiseConv2dNativeBackpropFilterAttr ¶ added in v1.1.0
type DepthwiseConv2dNativeBackpropFilterAttr func(optionalAttr)
DepthwiseConv2dNativeBackpropFilterAttr is an optional argument to DepthwiseConv2dNativeBackpropFilter.
func DepthwiseConv2dNativeBackpropFilterDataFormat ¶ added in v1.1.0
func DepthwiseConv2dNativeBackpropFilterDataFormat(value string) DepthwiseConv2dNativeBackpropFilterAttr
DepthwiseConv2dNativeBackpropFilterDataFormat sets the optional data_format attribute to value.
value: Specify the data format of the input and output data. With the default format "NHWC", the data is stored in the order of:
[batch, height, width, channels].
Alternatively, the format could be "NCHW", the data storage order of:
[batch, channels, height, width].
If not specified, defaults to "NHWC"
func DepthwiseConv2dNativeBackpropFilterDilations ¶ added in v1.6.0
func DepthwiseConv2dNativeBackpropFilterDilations(value []int64) DepthwiseConv2dNativeBackpropFilterAttr
DepthwiseConv2dNativeBackpropFilterDilations sets the optional dilations attribute to value.
value: 1-D tensor of length 4. The dilation factor for each dimension of `input`. If set to k > 1, there will be k-1 skipped cells between each filter element on that dimension. The dimension order is determined by the value of `data_format`, see above for details. Dilations in the batch and depth dimensions must be 1. If not specified, defaults to <i:1 i:1 i:1 i:1 >
type DepthwiseConv2dNativeBackpropInputAttr ¶ added in v1.1.0
type DepthwiseConv2dNativeBackpropInputAttr func(optionalAttr)
DepthwiseConv2dNativeBackpropInputAttr is an optional argument to DepthwiseConv2dNativeBackpropInput.
func DepthwiseConv2dNativeBackpropInputDataFormat ¶ added in v1.1.0
func DepthwiseConv2dNativeBackpropInputDataFormat(value string) DepthwiseConv2dNativeBackpropInputAttr
DepthwiseConv2dNativeBackpropInputDataFormat sets the optional data_format attribute to value.
value: Specify the data format of the input and output data. With the default format "NHWC", the data is stored in the order of:
[batch, height, width, channels].
Alternatively, the format could be "NCHW", the data storage order of:
[batch, channels, height, width].
If not specified, defaults to "NHWC"
func DepthwiseConv2dNativeBackpropInputDilations ¶ added in v1.6.0
func DepthwiseConv2dNativeBackpropInputDilations(value []int64) DepthwiseConv2dNativeBackpropInputAttr
DepthwiseConv2dNativeBackpropInputDilations sets the optional dilations attribute to value.
value: 1-D tensor of length 4. The dilation factor for each dimension of `input`. If set to k > 1, there will be k-1 skipped cells between each filter element on that dimension. The dimension order is determined by the value of `data_format`, see above for details. Dilations in the batch and depth dimensions must be 1. If not specified, defaults to <i:1 i:1 i:1 i:1 >
type DequantizeAttr ¶ added in v1.1.0
type DequantizeAttr func(optionalAttr)
DequantizeAttr is an optional argument to Dequantize.
func DequantizeMode ¶ added in v1.1.0
func DequantizeMode(value string) DequantizeAttr
DequantizeMode sets the optional mode attribute to value. If not specified, defaults to "MIN_COMBINED"
type DestroyResourceOpAttr ¶ added in v1.1.0
type DestroyResourceOpAttr func(optionalAttr)
DestroyResourceOpAttr is an optional argument to DestroyResourceOp.
func DestroyResourceOpIgnoreLookupError ¶ added in v1.1.0
func DestroyResourceOpIgnoreLookupError(value bool) DestroyResourceOpAttr
DestroyResourceOpIgnoreLookupError sets the optional ignore_lookup_error attribute to value.
value: whether to ignore the error when the resource doesn't exist. If not specified, defaults to true
type EditDistanceAttr ¶ added in v1.1.0
type EditDistanceAttr func(optionalAttr)
EditDistanceAttr is an optional argument to EditDistance.
func EditDistanceNormalize ¶ added in v1.1.0
func EditDistanceNormalize(value bool) EditDistanceAttr
EditDistanceNormalize sets the optional normalize attribute to value.
value: boolean (if true, edit distances are normalized by length of truth).
The output is: If not specified, defaults to true
type EncodeBase64Attr ¶ added in v1.1.0
type EncodeBase64Attr func(optionalAttr)
EncodeBase64Attr is an optional argument to EncodeBase64.
func EncodeBase64Pad ¶ added in v1.1.0
func EncodeBase64Pad(value bool) EncodeBase64Attr
EncodeBase64Pad sets the optional pad attribute to value.
value: Bool whether padding is applied at the ends. If not specified, defaults to false
type EncodeJpegAttr ¶ added in v1.1.0
type EncodeJpegAttr func(optionalAttr)
EncodeJpegAttr is an optional argument to EncodeJpeg.
func EncodeJpegChromaDownsampling ¶ added in v1.1.0
func EncodeJpegChromaDownsampling(value bool) EncodeJpegAttr
EncodeJpegChromaDownsampling sets the optional chroma_downsampling attribute to value.
value: See http://en.wikipedia.org/wiki/Chroma_subsampling. If not specified, defaults to true
func EncodeJpegDensityUnit ¶ added in v1.1.0
func EncodeJpegDensityUnit(value string) EncodeJpegAttr
EncodeJpegDensityUnit sets the optional density_unit attribute to value.
value: Unit used to specify `x_density` and `y_density`: pixels per inch (`'in'`) or centimeter (`'cm'`). If not specified, defaults to "in"
func EncodeJpegFormat ¶ added in v1.1.0
func EncodeJpegFormat(value string) EncodeJpegAttr
EncodeJpegFormat sets the optional format attribute to value.
value: Per pixel image format. If not specified, defaults to ""
func EncodeJpegOptimizeSize ¶ added in v1.1.0
func EncodeJpegOptimizeSize(value bool) EncodeJpegAttr
EncodeJpegOptimizeSize sets the optional optimize_size attribute to value.
value: If True, spend CPU/RAM to reduce size with no quality change. If not specified, defaults to false
func EncodeJpegProgressive ¶ added in v1.1.0
func EncodeJpegProgressive(value bool) EncodeJpegAttr
EncodeJpegProgressive sets the optional progressive attribute to value.
value: If True, create a JPEG that loads progressively (coarse to fine). If not specified, defaults to false
func EncodeJpegQuality ¶ added in v1.1.0
func EncodeJpegQuality(value int64) EncodeJpegAttr
EncodeJpegQuality sets the optional quality attribute to value.
value: Quality of the compression from 0 to 100 (higher is better and slower). If not specified, defaults to 95
func EncodeJpegXDensity ¶ added in v1.1.0
func EncodeJpegXDensity(value int64) EncodeJpegAttr
EncodeJpegXDensity sets the optional x_density attribute to value.
value: Horizontal pixels per density unit. If not specified, defaults to 300
func EncodeJpegXmpMetadata ¶ added in v1.1.0
func EncodeJpegXmpMetadata(value string) EncodeJpegAttr
EncodeJpegXmpMetadata sets the optional xmp_metadata attribute to value.
value: If not empty, embed this XMP metadata in the image header. If not specified, defaults to ""
func EncodeJpegYDensity ¶ added in v1.1.0
func EncodeJpegYDensity(value int64) EncodeJpegAttr
EncodeJpegYDensity sets the optional y_density attribute to value.
value: Vertical pixels per density unit. If not specified, defaults to 300
type EncodePngAttr ¶ added in v1.1.0
type EncodePngAttr func(optionalAttr)
EncodePngAttr is an optional argument to EncodePng.
func EncodePngCompression ¶ added in v1.1.0
func EncodePngCompression(value int64) EncodePngAttr
EncodePngCompression sets the optional compression attribute to value.
value: Compression level. If not specified, defaults to -1
type EnterAttr ¶ added in v1.1.0
type EnterAttr func(optionalAttr)
EnterAttr is an optional argument to Enter.
func EnterIsConstant ¶ added in v1.1.0
EnterIsConstant sets the optional is_constant attribute to value.
value: If true, the output is constant within the child frame. If not specified, defaults to false
func EnterParallelIterations ¶ added in v1.1.0
EnterParallelIterations sets the optional parallel_iterations attribute to value.
value: The number of iterations allowed to run in parallel. If not specified, defaults to 10
type ExtractGlimpseAttr ¶ added in v1.1.0
type ExtractGlimpseAttr func(optionalAttr)
ExtractGlimpseAttr is an optional argument to ExtractGlimpse.
func ExtractGlimpseCentered ¶ added in v1.1.0
func ExtractGlimpseCentered(value bool) ExtractGlimpseAttr
ExtractGlimpseCentered sets the optional centered attribute to value.
value: indicates if the offset coordinates are centered relative to the image, in which case the (0, 0) offset is relative to the center of the input images. If false, the (0,0) offset corresponds to the upper left corner of the input images. If not specified, defaults to true
func ExtractGlimpseNormalized ¶ added in v1.1.0
func ExtractGlimpseNormalized(value bool) ExtractGlimpseAttr
ExtractGlimpseNormalized sets the optional normalized attribute to value.
value: indicates if the offset coordinates are normalized. If not specified, defaults to true
func ExtractGlimpseUniformNoise ¶ added in v1.1.0
func ExtractGlimpseUniformNoise(value bool) ExtractGlimpseAttr
ExtractGlimpseUniformNoise sets the optional uniform_noise attribute to value.
value: indicates if the noise should be generated using a uniform distribution or a Gaussian distribution. If not specified, defaults to true
type ExtractJpegShapeAttr ¶ added in v1.4.0
type ExtractJpegShapeAttr func(optionalAttr)
ExtractJpegShapeAttr is an optional argument to ExtractJpegShape.
func ExtractJpegShapeOutputType ¶ added in v1.4.0
func ExtractJpegShapeOutputType(value tf.DataType) ExtractJpegShapeAttr
ExtractJpegShapeOutputType sets the optional output_type attribute to value.
value: (Optional) The output type of the operation (int32 or int64). Defaults to int32. If not specified, defaults to DT_INT32
type FIFOQueueV2Attr ¶ added in v1.1.0
type FIFOQueueV2Attr func(optionalAttr)
FIFOQueueV2Attr is an optional argument to FIFOQueueV2.
func FIFOQueueV2Capacity ¶ added in v1.1.0
func FIFOQueueV2Capacity(value int64) FIFOQueueV2Attr
FIFOQueueV2Capacity sets the optional capacity attribute to value.
value: The upper bound on the number of elements in this queue. Negative numbers mean no limit. If not specified, defaults to -1
func FIFOQueueV2Container ¶ added in v1.1.0
func FIFOQueueV2Container(value string) FIFOQueueV2Attr
FIFOQueueV2Container sets the optional container attribute to value.
value: If non-empty, this queue is placed in the given container. Otherwise, a default container is used. If not specified, defaults to ""
func FIFOQueueV2Shapes ¶ added in v1.1.0
func FIFOQueueV2Shapes(value []tf.Shape) FIFOQueueV2Attr
FIFOQueueV2Shapes sets the optional shapes attribute to value.
value: The shape of each component in a value. The length of this attr must be either 0 or the same as the length of component_types. If the length of this attr is 0, the shapes of queue elements are not constrained, and only one element may be dequeued at a time. If not specified, defaults to <>
REQUIRES: len(value) >= 0
func FIFOQueueV2SharedName ¶ added in v1.1.0
func FIFOQueueV2SharedName(value string) FIFOQueueV2Attr
FIFOQueueV2SharedName sets the optional shared_name attribute to value.
value: If non-empty, this queue will be shared under the given name across multiple sessions. If not specified, defaults to ""
type FakeQuantWithMinMaxArgsAttr ¶ added in v1.1.0
type FakeQuantWithMinMaxArgsAttr func(optionalAttr)
FakeQuantWithMinMaxArgsAttr is an optional argument to FakeQuantWithMinMaxArgs.
func FakeQuantWithMinMaxArgsMax ¶ added in v1.1.0
func FakeQuantWithMinMaxArgsMax(value float32) FakeQuantWithMinMaxArgsAttr
FakeQuantWithMinMaxArgsMax sets the optional max attribute to value. If not specified, defaults to 6
func FakeQuantWithMinMaxArgsMin ¶ added in v1.1.0
func FakeQuantWithMinMaxArgsMin(value float32) FakeQuantWithMinMaxArgsAttr
FakeQuantWithMinMaxArgsMin sets the optional min attribute to value. If not specified, defaults to -6
func FakeQuantWithMinMaxArgsNarrowRange ¶ added in v1.3.0
func FakeQuantWithMinMaxArgsNarrowRange(value bool) FakeQuantWithMinMaxArgsAttr
FakeQuantWithMinMaxArgsNarrowRange sets the optional narrow_range attribute to value. If not specified, defaults to false
func FakeQuantWithMinMaxArgsNumBits ¶ added in v1.2.0
func FakeQuantWithMinMaxArgsNumBits(value int64) FakeQuantWithMinMaxArgsAttr
FakeQuantWithMinMaxArgsNumBits sets the optional num_bits attribute to value. If not specified, defaults to 8
type FakeQuantWithMinMaxArgsGradientAttr ¶ added in v1.1.0
type FakeQuantWithMinMaxArgsGradientAttr func(optionalAttr)
FakeQuantWithMinMaxArgsGradientAttr is an optional argument to FakeQuantWithMinMaxArgsGradient.
func FakeQuantWithMinMaxArgsGradientMax ¶ added in v1.1.0
func FakeQuantWithMinMaxArgsGradientMax(value float32) FakeQuantWithMinMaxArgsGradientAttr
FakeQuantWithMinMaxArgsGradientMax sets the optional max attribute to value. If not specified, defaults to 6
func FakeQuantWithMinMaxArgsGradientMin ¶ added in v1.1.0
func FakeQuantWithMinMaxArgsGradientMin(value float32) FakeQuantWithMinMaxArgsGradientAttr
FakeQuantWithMinMaxArgsGradientMin sets the optional min attribute to value. If not specified, defaults to -6
func FakeQuantWithMinMaxArgsGradientNarrowRange ¶ added in v1.3.0
func FakeQuantWithMinMaxArgsGradientNarrowRange(value bool) FakeQuantWithMinMaxArgsGradientAttr
FakeQuantWithMinMaxArgsGradientNarrowRange sets the optional narrow_range attribute to value. If not specified, defaults to false
func FakeQuantWithMinMaxArgsGradientNumBits ¶ added in v1.2.0
func FakeQuantWithMinMaxArgsGradientNumBits(value int64) FakeQuantWithMinMaxArgsGradientAttr
FakeQuantWithMinMaxArgsGradientNumBits sets the optional num_bits attribute to value. If not specified, defaults to 8
type FakeQuantWithMinMaxVarsAttr ¶ added in v1.2.0
type FakeQuantWithMinMaxVarsAttr func(optionalAttr)
FakeQuantWithMinMaxVarsAttr is an optional argument to FakeQuantWithMinMaxVars.
func FakeQuantWithMinMaxVarsNarrowRange ¶ added in v1.3.0
func FakeQuantWithMinMaxVarsNarrowRange(value bool) FakeQuantWithMinMaxVarsAttr
FakeQuantWithMinMaxVarsNarrowRange sets the optional narrow_range attribute to value. If not specified, defaults to false
func FakeQuantWithMinMaxVarsNumBits ¶ added in v1.2.0
func FakeQuantWithMinMaxVarsNumBits(value int64) FakeQuantWithMinMaxVarsAttr
FakeQuantWithMinMaxVarsNumBits sets the optional num_bits attribute to value. If not specified, defaults to 8
type FakeQuantWithMinMaxVarsGradientAttr ¶ added in v1.2.0
type FakeQuantWithMinMaxVarsGradientAttr func(optionalAttr)
FakeQuantWithMinMaxVarsGradientAttr is an optional argument to FakeQuantWithMinMaxVarsGradient.
func FakeQuantWithMinMaxVarsGradientNarrowRange ¶ added in v1.3.0
func FakeQuantWithMinMaxVarsGradientNarrowRange(value bool) FakeQuantWithMinMaxVarsGradientAttr
FakeQuantWithMinMaxVarsGradientNarrowRange sets the optional narrow_range attribute to value.
value: Whether to quantize into 2^num_bits - 1 distinct values. If not specified, defaults to false
func FakeQuantWithMinMaxVarsGradientNumBits ¶ added in v1.2.0
func FakeQuantWithMinMaxVarsGradientNumBits(value int64) FakeQuantWithMinMaxVarsGradientAttr
FakeQuantWithMinMaxVarsGradientNumBits sets the optional num_bits attribute to value.
value: The bitwidth of the quantization; between 2 and 8, inclusive. If not specified, defaults to 8
type FakeQuantWithMinMaxVarsPerChannelAttr ¶ added in v1.2.0
type FakeQuantWithMinMaxVarsPerChannelAttr func(optionalAttr)
FakeQuantWithMinMaxVarsPerChannelAttr is an optional argument to FakeQuantWithMinMaxVarsPerChannel.
func FakeQuantWithMinMaxVarsPerChannelNarrowRange ¶ added in v1.3.0
func FakeQuantWithMinMaxVarsPerChannelNarrowRange(value bool) FakeQuantWithMinMaxVarsPerChannelAttr
FakeQuantWithMinMaxVarsPerChannelNarrowRange sets the optional narrow_range attribute to value. If not specified, defaults to false
func FakeQuantWithMinMaxVarsPerChannelNumBits ¶ added in v1.2.0
func FakeQuantWithMinMaxVarsPerChannelNumBits(value int64) FakeQuantWithMinMaxVarsPerChannelAttr
FakeQuantWithMinMaxVarsPerChannelNumBits sets the optional num_bits attribute to value. If not specified, defaults to 8
type FakeQuantWithMinMaxVarsPerChannelGradientAttr ¶ added in v1.2.0
type FakeQuantWithMinMaxVarsPerChannelGradientAttr func(optionalAttr)
FakeQuantWithMinMaxVarsPerChannelGradientAttr is an optional argument to FakeQuantWithMinMaxVarsPerChannelGradient.
func FakeQuantWithMinMaxVarsPerChannelGradientNarrowRange ¶ added in v1.3.0
func FakeQuantWithMinMaxVarsPerChannelGradientNarrowRange(value bool) FakeQuantWithMinMaxVarsPerChannelGradientAttr
FakeQuantWithMinMaxVarsPerChannelGradientNarrowRange sets the optional narrow_range attribute to value.
value: Whether to quantize into 2^num_bits - 1 distinct values. If not specified, defaults to false
func FakeQuantWithMinMaxVarsPerChannelGradientNumBits ¶ added in v1.2.0
func FakeQuantWithMinMaxVarsPerChannelGradientNumBits(value int64) FakeQuantWithMinMaxVarsPerChannelGradientAttr
FakeQuantWithMinMaxVarsPerChannelGradientNumBits sets the optional num_bits attribute to value.
value: The bitwidth of the quantization; between 2 and 8, inclusive. If not specified, defaults to 8
type FixedLengthRecordReaderV2Attr ¶ added in v1.1.0
type FixedLengthRecordReaderV2Attr func(optionalAttr)
FixedLengthRecordReaderV2Attr is an optional argument to FixedLengthRecordReaderV2.
func FixedLengthRecordReaderV2Container ¶ added in v1.1.0
func FixedLengthRecordReaderV2Container(value string) FixedLengthRecordReaderV2Attr
FixedLengthRecordReaderV2Container sets the optional container attribute to value.
value: If non-empty, this reader is placed in the given container. Otherwise, a default container is used. If not specified, defaults to ""
func FixedLengthRecordReaderV2Encoding ¶ added in v1.3.0
func FixedLengthRecordReaderV2Encoding(value string) FixedLengthRecordReaderV2Attr
FixedLengthRecordReaderV2Encoding sets the optional encoding attribute to value.
value: The type of encoding for the file. Currently ZLIB and GZIP are supported. Defaults to none. If not specified, defaults to ""
func FixedLengthRecordReaderV2FooterBytes ¶ added in v1.1.0
func FixedLengthRecordReaderV2FooterBytes(value int64) FixedLengthRecordReaderV2Attr
FixedLengthRecordReaderV2FooterBytes sets the optional footer_bytes attribute to value.
value: Number of bytes in the footer, defaults to 0. If not specified, defaults to 0
func FixedLengthRecordReaderV2HeaderBytes ¶ added in v1.1.0
func FixedLengthRecordReaderV2HeaderBytes(value int64) FixedLengthRecordReaderV2Attr
FixedLengthRecordReaderV2HeaderBytes sets the optional header_bytes attribute to value.
value: Number of bytes in the header, defaults to 0. If not specified, defaults to 0
func FixedLengthRecordReaderV2HopBytes ¶ added in v1.2.0
func FixedLengthRecordReaderV2HopBytes(value int64) FixedLengthRecordReaderV2Attr
FixedLengthRecordReaderV2HopBytes sets the optional hop_bytes attribute to value.
value: Number of bytes to hop before each read. Default of 0 means using record_bytes. If not specified, defaults to 0
func FixedLengthRecordReaderV2SharedName ¶ added in v1.1.0
func FixedLengthRecordReaderV2SharedName(value string) FixedLengthRecordReaderV2Attr
FixedLengthRecordReaderV2SharedName sets the optional shared_name attribute to value.
value: If non-empty, this reader is named in the given bucket with this shared_name. Otherwise, the node name is used instead. If not specified, defaults to ""
type FixedUnigramCandidateSamplerAttr ¶ added in v1.1.0
type FixedUnigramCandidateSamplerAttr func(optionalAttr)
FixedUnigramCandidateSamplerAttr is an optional argument to FixedUnigramCandidateSampler.
func FixedUnigramCandidateSamplerDistortion ¶ added in v1.1.0
func FixedUnigramCandidateSamplerDistortion(value float32) FixedUnigramCandidateSamplerAttr
FixedUnigramCandidateSamplerDistortion sets the optional distortion attribute to value.
value: The distortion is used to skew the unigram probability distribution. Each weight is first raised to the distortion's power before adding to the internal unigram distribution. As a result, distortion = 1.0 gives regular unigram sampling (as defined by the vocab file), and distortion = 0.0 gives a uniform distribution. If not specified, defaults to 1
func FixedUnigramCandidateSamplerNumReservedIds ¶ added in v1.1.0
func FixedUnigramCandidateSamplerNumReservedIds(value int64) FixedUnigramCandidateSamplerAttr
FixedUnigramCandidateSamplerNumReservedIds sets the optional num_reserved_ids attribute to value.
value: Optionally some reserved IDs can be added in the range [0, ..., num_reserved_ids) by the users. One use case is that a special unknown word token is used as ID 0. These IDs will have a sampling probability of 0. If not specified, defaults to 0
func FixedUnigramCandidateSamplerNumShards ¶ added in v1.1.0
func FixedUnigramCandidateSamplerNumShards(value int64) FixedUnigramCandidateSamplerAttr
FixedUnigramCandidateSamplerNumShards sets the optional num_shards attribute to value.
value: A sampler can be used to sample from a subset of the original range in order to speed up the whole computation through parallelism. This parameter (together with 'shard') indicates the number of partitions that are being used in the overall computation. If not specified, defaults to 1
REQUIRES: value >= 1
func FixedUnigramCandidateSamplerSeed ¶ added in v1.1.0
func FixedUnigramCandidateSamplerSeed(value int64) FixedUnigramCandidateSamplerAttr
FixedUnigramCandidateSamplerSeed sets the optional seed attribute to value.
value: If either seed or seed2 are set to be non-zero, the random number generator is seeded by the given seed. Otherwise, it is seeded by a random seed. If not specified, defaults to 0
func FixedUnigramCandidateSamplerSeed2 ¶ added in v1.1.0
func FixedUnigramCandidateSamplerSeed2(value int64) FixedUnigramCandidateSamplerAttr
FixedUnigramCandidateSamplerSeed2 sets the optional seed2 attribute to value.
value: An second seed to avoid seed collision. If not specified, defaults to 0
func FixedUnigramCandidateSamplerShard ¶ added in v1.1.0
func FixedUnigramCandidateSamplerShard(value int64) FixedUnigramCandidateSamplerAttr
FixedUnigramCandidateSamplerShard sets the optional shard attribute to value.
value: A sampler can be used to sample from a subset of the original range in order to speed up the whole computation through parallelism. This parameter (together with 'num_shards') indicates the particular partition number of a sampler op, when partitioning is being used. If not specified, defaults to 0
REQUIRES: value >= 0
func FixedUnigramCandidateSamplerUnigrams ¶ added in v1.1.0
func FixedUnigramCandidateSamplerUnigrams(value []float32) FixedUnigramCandidateSamplerAttr
FixedUnigramCandidateSamplerUnigrams sets the optional unigrams attribute to value.
value: A list of unigram counts or probabilities, one per ID in sequential order. Exactly one of vocab_file and unigrams should be passed to this op. If not specified, defaults to <>
func FixedUnigramCandidateSamplerVocabFile ¶ added in v1.1.0
func FixedUnigramCandidateSamplerVocabFile(value string) FixedUnigramCandidateSamplerAttr
FixedUnigramCandidateSamplerVocabFile sets the optional vocab_file attribute to value.
value: Each valid line in this file (which should have a CSV-like format) corresponds to a valid word ID. IDs are in sequential order, starting from num_reserved_ids. The last entry in each line is expected to be a value corresponding to the count or relative probability. Exactly one of vocab_file and unigrams needs to be passed to this op. If not specified, defaults to ""
type FractionalAvgPoolAttr ¶ added in v1.1.0
type FractionalAvgPoolAttr func(optionalAttr)
FractionalAvgPoolAttr is an optional argument to FractionalAvgPool.
func FractionalAvgPoolDeterministic ¶ added in v1.1.0
func FractionalAvgPoolDeterministic(value bool) FractionalAvgPoolAttr
FractionalAvgPoolDeterministic sets the optional deterministic attribute to value.
value: When set to True, a fixed pooling region will be used when iterating over a FractionalAvgPool node in the computation graph. Mainly used in unit test to make FractionalAvgPool deterministic. If not specified, defaults to false
func FractionalAvgPoolOverlapping ¶ added in v1.1.0
func FractionalAvgPoolOverlapping(value bool) FractionalAvgPoolAttr
FractionalAvgPoolOverlapping sets the optional overlapping attribute to value.
value: When set to True, it means when pooling, the values at the boundary of adjacent pooling cells are used by both cells. For example:
`index 0 1 2 3 4`
`value 20 5 16 3 7`
If the pooling sequence is [0, 2, 4], then 16, at index 2 will be used twice. The result would be [41/3, 26/3] for fractional avg pooling. If not specified, defaults to false
func FractionalAvgPoolPseudoRandom ¶ added in v1.1.0
func FractionalAvgPoolPseudoRandom(value bool) FractionalAvgPoolAttr
FractionalAvgPoolPseudoRandom sets the optional pseudo_random attribute to value.
value: When set to True, generates the pooling sequence in a pseudorandom fashion, otherwise, in a random fashion. Check paper [Benjamin Graham, Fractional Max-Pooling](http://arxiv.org/abs/1412.6071) for difference between pseudorandom and random. If not specified, defaults to false
func FractionalAvgPoolSeed ¶ added in v1.1.0
func FractionalAvgPoolSeed(value int64) FractionalAvgPoolAttr
FractionalAvgPoolSeed sets the optional seed attribute to value.
value: If either seed or seed2 are set to be non-zero, the random number generator is seeded by the given seed. Otherwise, it is seeded by a random seed. If not specified, defaults to 0
func FractionalAvgPoolSeed2 ¶ added in v1.1.0
func FractionalAvgPoolSeed2(value int64) FractionalAvgPoolAttr
FractionalAvgPoolSeed2 sets the optional seed2 attribute to value.
value: An second seed to avoid seed collision. If not specified, defaults to 0
type FractionalAvgPoolGradAttr ¶ added in v1.1.0
type FractionalAvgPoolGradAttr func(optionalAttr)
FractionalAvgPoolGradAttr is an optional argument to FractionalAvgPoolGrad.
func FractionalAvgPoolGradOverlapping ¶ added in v1.1.0
func FractionalAvgPoolGradOverlapping(value bool) FractionalAvgPoolGradAttr
FractionalAvgPoolGradOverlapping sets the optional overlapping attribute to value.
value: When set to True, it means when pooling, the values at the boundary of adjacent pooling cells are used by both cells. For example:
`index 0 1 2 3 4`
`value 20 5 16 3 7`
If the pooling sequence is [0, 2, 4], then 16, at index 2 will be used twice. The result would be [41/3, 26/3] for fractional avg pooling. If not specified, defaults to false
type FractionalMaxPoolAttr ¶ added in v1.1.0
type FractionalMaxPoolAttr func(optionalAttr)
FractionalMaxPoolAttr is an optional argument to FractionalMaxPool.
func FractionalMaxPoolDeterministic ¶ added in v1.1.0
func FractionalMaxPoolDeterministic(value bool) FractionalMaxPoolAttr
FractionalMaxPoolDeterministic sets the optional deterministic attribute to value.
value: When set to True, a fixed pooling region will be used when iterating over a FractionalMaxPool node in the computation graph. Mainly used in unit test to make FractionalMaxPool deterministic. If not specified, defaults to false
func FractionalMaxPoolOverlapping ¶ added in v1.1.0
func FractionalMaxPoolOverlapping(value bool) FractionalMaxPoolAttr
FractionalMaxPoolOverlapping sets the optional overlapping attribute to value.
value: When set to True, it means when pooling, the values at the boundary of adjacent pooling cells are used by both cells. For example:
`index 0 1 2 3 4`
`value 20 5 16 3 7`
If the pooling sequence is [0, 2, 4], then 16, at index 2 will be used twice. The result would be [20, 16] for fractional max pooling. If not specified, defaults to false
func FractionalMaxPoolPseudoRandom ¶ added in v1.1.0
func FractionalMaxPoolPseudoRandom(value bool) FractionalMaxPoolAttr
FractionalMaxPoolPseudoRandom sets the optional pseudo_random attribute to value.
value: When set to True, generates the pooling sequence in a pseudorandom fashion, otherwise, in a random fashion. Check paper [Benjamin Graham, Fractional Max-Pooling](http://arxiv.org/abs/1412.6071) for difference between pseudorandom and random. If not specified, defaults to false
func FractionalMaxPoolSeed ¶ added in v1.1.0
func FractionalMaxPoolSeed(value int64) FractionalMaxPoolAttr
FractionalMaxPoolSeed sets the optional seed attribute to value.
value: If either seed or seed2 are set to be non-zero, the random number generator is seeded by the given seed. Otherwise, it is seeded by a random seed. If not specified, defaults to 0
func FractionalMaxPoolSeed2 ¶ added in v1.1.0
func FractionalMaxPoolSeed2(value int64) FractionalMaxPoolAttr
FractionalMaxPoolSeed2 sets the optional seed2 attribute to value.
value: An second seed to avoid seed collision. If not specified, defaults to 0
type FractionalMaxPoolGradAttr ¶ added in v1.1.0
type FractionalMaxPoolGradAttr func(optionalAttr)
FractionalMaxPoolGradAttr is an optional argument to FractionalMaxPoolGrad.
func FractionalMaxPoolGradOverlapping ¶ added in v1.1.0
func FractionalMaxPoolGradOverlapping(value bool) FractionalMaxPoolGradAttr
FractionalMaxPoolGradOverlapping sets the optional overlapping attribute to value.
value: When set to True, it means when pooling, the values at the boundary of adjacent pooling cells are used by both cells. For example:
`index 0 1 2 3 4`
`value 20 5 16 3 7`
If the pooling sequence is [0, 2, 4], then 16, at index 2 will be used twice. The result would be [20, 16] for fractional max pooling. If not specified, defaults to false
type FusedBatchNormAttr ¶ added in v1.1.0
type FusedBatchNormAttr func(optionalAttr)
FusedBatchNormAttr is an optional argument to FusedBatchNorm.
func FusedBatchNormDataFormat ¶ added in v1.1.0
func FusedBatchNormDataFormat(value string) FusedBatchNormAttr
FusedBatchNormDataFormat sets the optional data_format attribute to value.
value: The data format for x and y. Either "NHWC" (default) or "NCHW". If not specified, defaults to "NHWC"
func FusedBatchNormEpsilon ¶ added in v1.1.0
func FusedBatchNormEpsilon(value float32) FusedBatchNormAttr
FusedBatchNormEpsilon sets the optional epsilon attribute to value.
value: A small float number added to the variance of x. If not specified, defaults to 0.0001
func FusedBatchNormIsTraining ¶ added in v1.1.0
func FusedBatchNormIsTraining(value bool) FusedBatchNormAttr
FusedBatchNormIsTraining sets the optional is_training attribute to value.
value: A bool value to indicate the operation is for training (default) or inference. If not specified, defaults to true
type FusedBatchNormGradAttr ¶ added in v1.1.0
type FusedBatchNormGradAttr func(optionalAttr)
FusedBatchNormGradAttr is an optional argument to FusedBatchNormGrad.
func FusedBatchNormGradDataFormat ¶ added in v1.1.0
func FusedBatchNormGradDataFormat(value string) FusedBatchNormGradAttr
FusedBatchNormGradDataFormat sets the optional data_format attribute to value.
value: The data format for y_backprop, x, x_backprop. Either "NHWC" (default) or "NCHW". If not specified, defaults to "NHWC"
func FusedBatchNormGradEpsilon ¶ added in v1.1.0
func FusedBatchNormGradEpsilon(value float32) FusedBatchNormGradAttr
FusedBatchNormGradEpsilon sets the optional epsilon attribute to value.
value: A small float number added to the variance of x. If not specified, defaults to 0.0001
func FusedBatchNormGradIsTraining ¶ added in v1.1.0
func FusedBatchNormGradIsTraining(value bool) FusedBatchNormGradAttr
FusedBatchNormGradIsTraining sets the optional is_training attribute to value.
value: A bool value to indicate the operation is for training (default) or inference. If not specified, defaults to true
type FusedBatchNormGradV2Attr ¶ added in v1.4.0
type FusedBatchNormGradV2Attr func(optionalAttr)
FusedBatchNormGradV2Attr is an optional argument to FusedBatchNormGradV2.
func FusedBatchNormGradV2DataFormat ¶ added in v1.4.0
func FusedBatchNormGradV2DataFormat(value string) FusedBatchNormGradV2Attr
FusedBatchNormGradV2DataFormat sets the optional data_format attribute to value.
value: The data format for y_backprop, x, x_backprop. Either "NHWC" (default) or "NCHW". If not specified, defaults to "NHWC"
func FusedBatchNormGradV2Epsilon ¶ added in v1.4.0
func FusedBatchNormGradV2Epsilon(value float32) FusedBatchNormGradV2Attr
FusedBatchNormGradV2Epsilon sets the optional epsilon attribute to value.
value: A small float number added to the variance of x. If not specified, defaults to 0.0001
func FusedBatchNormGradV2IsTraining ¶ added in v1.4.0
func FusedBatchNormGradV2IsTraining(value bool) FusedBatchNormGradV2Attr
FusedBatchNormGradV2IsTraining sets the optional is_training attribute to value.
value: A bool value to indicate the operation is for training (default) or inference. If not specified, defaults to true
type FusedBatchNormV2Attr ¶ added in v1.4.0
type FusedBatchNormV2Attr func(optionalAttr)
FusedBatchNormV2Attr is an optional argument to FusedBatchNormV2.
func FusedBatchNormV2DataFormat ¶ added in v1.4.0
func FusedBatchNormV2DataFormat(value string) FusedBatchNormV2Attr
FusedBatchNormV2DataFormat sets the optional data_format attribute to value.
value: The data format for x and y. Either "NHWC" (default) or "NCHW". If not specified, defaults to "NHWC"
func FusedBatchNormV2Epsilon ¶ added in v1.4.0
func FusedBatchNormV2Epsilon(value float32) FusedBatchNormV2Attr
FusedBatchNormV2Epsilon sets the optional epsilon attribute to value.
value: A small float number added to the variance of x. If not specified, defaults to 0.0001
func FusedBatchNormV2IsTraining ¶ added in v1.4.0
func FusedBatchNormV2IsTraining(value bool) FusedBatchNormV2Attr
FusedBatchNormV2IsTraining sets the optional is_training attribute to value.
value: A bool value to indicate the operation is for training (default) or inference. If not specified, defaults to true
type FusedResizeAndPadConv2DAttr ¶ added in v1.1.0
type FusedResizeAndPadConv2DAttr func(optionalAttr)
FusedResizeAndPadConv2DAttr is an optional argument to FusedResizeAndPadConv2D.
func FusedResizeAndPadConv2DResizeAlignCorners ¶ added in v1.1.0
func FusedResizeAndPadConv2DResizeAlignCorners(value bool) FusedResizeAndPadConv2DAttr
FusedResizeAndPadConv2DResizeAlignCorners sets the optional resize_align_corners attribute to value.
value: If true, rescale input by (new_height - 1) / (height - 1), which exactly aligns the 4 corners of images and resized images. If false, rescale by new_height / height. Treat similarly the width dimension. If not specified, defaults to false
type GatherAttr ¶ added in v1.1.0
type GatherAttr func(optionalAttr)
GatherAttr is an optional argument to Gather.
func GatherValidateIndices ¶ added in v1.1.0
func GatherValidateIndices(value bool) GatherAttr
GatherValidateIndices sets the optional validate_indices attribute to value. If not specified, defaults to true
type GenerateVocabRemappingAttr ¶ added in v1.5.0
type GenerateVocabRemappingAttr func(optionalAttr)
GenerateVocabRemappingAttr is an optional argument to GenerateVocabRemapping.
func GenerateVocabRemappingOldVocabSize ¶ added in v1.5.0
func GenerateVocabRemappingOldVocabSize(value int64) GenerateVocabRemappingAttr
GenerateVocabRemappingOldVocabSize sets the optional old_vocab_size attribute to value.
value: Number of entries in the old vocab file to consider. If -1, use the entire old vocabulary. If not specified, defaults to -1
REQUIRES: value >= -1
type HashTableV2Attr ¶ added in v1.2.0
type HashTableV2Attr func(optionalAttr)
HashTableV2Attr is an optional argument to HashTableV2.
func HashTableV2Container ¶ added in v1.2.0
func HashTableV2Container(value string) HashTableV2Attr
HashTableV2Container sets the optional container attribute to value.
value: If non-empty, this table is placed in the given container. Otherwise, a default container is used. If not specified, defaults to ""
func HashTableV2SharedName ¶ added in v1.2.0
func HashTableV2SharedName(value string) HashTableV2Attr
HashTableV2SharedName sets the optional shared_name attribute to value.
value: If non-empty, this table is shared under the given name across multiple sessions. If not specified, defaults to ""
func HashTableV2UseNodeNameSharing ¶ added in v1.2.0
func HashTableV2UseNodeNameSharing(value bool) HashTableV2Attr
HashTableV2UseNodeNameSharing sets the optional use_node_name_sharing attribute to value.
value: If true and shared_name is empty, the table is shared using the node name. If not specified, defaults to false
type HistogramFixedWidthAttr ¶ added in v1.5.0
type HistogramFixedWidthAttr func(optionalAttr)
HistogramFixedWidthAttr is an optional argument to HistogramFixedWidth.
func HistogramFixedWidthDtype ¶ added in v1.5.0
func HistogramFixedWidthDtype(value tf.DataType) HistogramFixedWidthAttr
HistogramFixedWidthDtype sets the optional dtype attribute to value. If not specified, defaults to DT_INT32
type IdentityReaderV2Attr ¶ added in v1.1.0
type IdentityReaderV2Attr func(optionalAttr)
IdentityReaderV2Attr is an optional argument to IdentityReaderV2.
func IdentityReaderV2Container ¶ added in v1.1.0
func IdentityReaderV2Container(value string) IdentityReaderV2Attr
IdentityReaderV2Container sets the optional container attribute to value.
value: If non-empty, this reader is placed in the given container. Otherwise, a default container is used. If not specified, defaults to ""
func IdentityReaderV2SharedName ¶ added in v1.1.0
func IdentityReaderV2SharedName(value string) IdentityReaderV2Attr
IdentityReaderV2SharedName sets the optional shared_name attribute to value.
value: If non-empty, this reader is named in the given bucket with this shared_name. Otherwise, the node name is used instead. If not specified, defaults to ""
type ImagAttr ¶ added in v1.1.0
type ImagAttr func(optionalAttr)
ImagAttr is an optional argument to Imag.
type ImageSummaryAttr ¶ added in v1.1.0
type ImageSummaryAttr func(optionalAttr)
ImageSummaryAttr is an optional argument to ImageSummary.
func ImageSummaryBadColor ¶ added in v1.1.0
func ImageSummaryBadColor(value tf.Tensor) ImageSummaryAttr
ImageSummaryBadColor sets the optional bad_color attribute to value.
value: Color to use for pixels with non-finite values. If not specified, defaults to <dtype:DT_UINT8 tensor_shape:<dim:<size:4 > > int_val:255 int_val:0 int_val:0 int_val:255 >
func ImageSummaryMaxImages ¶ added in v1.1.0
func ImageSummaryMaxImages(value int64) ImageSummaryAttr
ImageSummaryMaxImages sets the optional max_images attribute to value.
value: Max number of batch elements to generate images for. If not specified, defaults to 3
REQUIRES: value >= 1
type InitializeTableFromTextFileV2Attr ¶ added in v1.2.0
type InitializeTableFromTextFileV2Attr func(optionalAttr)
InitializeTableFromTextFileV2Attr is an optional argument to InitializeTableFromTextFileV2.
func InitializeTableFromTextFileV2Delimiter ¶ added in v1.2.0
func InitializeTableFromTextFileV2Delimiter(value string) InitializeTableFromTextFileV2Attr
InitializeTableFromTextFileV2Delimiter sets the optional delimiter attribute to value.
value: Delimiter to separate fields in a line. If not specified, defaults to "\t"
func InitializeTableFromTextFileV2VocabSize ¶ added in v1.2.0
func InitializeTableFromTextFileV2VocabSize(value int64) InitializeTableFromTextFileV2Attr
InitializeTableFromTextFileV2VocabSize sets the optional vocab_size attribute to value.
value: Number of elements of the file, use -1 if unknown. If not specified, defaults to -1
REQUIRES: value >= -1
type IteratorFromStringHandleAttr ¶ added in v1.4.0
type IteratorFromStringHandleAttr func(optionalAttr)
IteratorFromStringHandleAttr is an optional argument to IteratorFromStringHandle.
func IteratorFromStringHandleOutputShapes ¶ added in v1.4.0
func IteratorFromStringHandleOutputShapes(value []tf.Shape) IteratorFromStringHandleAttr
IteratorFromStringHandleOutputShapes sets the optional output_shapes attribute to value.
value: If specified, defines the shape of each tuple component in an element produced by the resulting iterator. If not specified, defaults to <>
REQUIRES: len(value) >= 0
func IteratorFromStringHandleOutputTypes ¶ added in v1.4.0
func IteratorFromStringHandleOutputTypes(value []tf.DataType) IteratorFromStringHandleAttr
IteratorFromStringHandleOutputTypes sets the optional output_types attribute to value.
value: If specified, defines the type of each tuple component in an element produced by the resulting iterator. If not specified, defaults to <>
REQUIRES: len(value) >= 0
type LRNAttr ¶ added in v1.1.0
type LRNAttr func(optionalAttr)
LRNAttr is an optional argument to LRN.
func LRNAlpha ¶ added in v1.1.0
LRNAlpha sets the optional alpha attribute to value.
value: A scale factor, usually positive. If not specified, defaults to 1
func LRNBeta ¶ added in v1.1.0
LRNBeta sets the optional beta attribute to value.
value: An exponent. If not specified, defaults to 0.5
func LRNBias ¶ added in v1.1.0
LRNBias sets the optional bias attribute to value.
value: An offset (usually positive to avoid dividing by 0). If not specified, defaults to 1
func LRNDepthRadius ¶ added in v1.1.0
LRNDepthRadius sets the optional depth_radius attribute to value.
value: 0-D. Half-width of the 1-D normalization window. If not specified, defaults to 5
type LRNGradAttr ¶ added in v1.1.0
type LRNGradAttr func(optionalAttr)
LRNGradAttr is an optional argument to LRNGrad.
func LRNGradAlpha ¶ added in v1.1.0
func LRNGradAlpha(value float32) LRNGradAttr
LRNGradAlpha sets the optional alpha attribute to value.
value: A scale factor, usually positive. If not specified, defaults to 1
func LRNGradBeta ¶ added in v1.1.0
func LRNGradBeta(value float32) LRNGradAttr
LRNGradBeta sets the optional beta attribute to value.
value: An exponent. If not specified, defaults to 0.5
func LRNGradBias ¶ added in v1.1.0
func LRNGradBias(value float32) LRNGradAttr
LRNGradBias sets the optional bias attribute to value.
value: An offset (usually > 0 to avoid dividing by 0). If not specified, defaults to 1
func LRNGradDepthRadius ¶ added in v1.1.0
func LRNGradDepthRadius(value int64) LRNGradAttr
LRNGradDepthRadius sets the optional depth_radius attribute to value.
value: A depth radius. If not specified, defaults to 5
type LearnedUnigramCandidateSamplerAttr ¶ added in v1.1.0
type LearnedUnigramCandidateSamplerAttr func(optionalAttr)
LearnedUnigramCandidateSamplerAttr is an optional argument to LearnedUnigramCandidateSampler.
func LearnedUnigramCandidateSamplerSeed ¶ added in v1.1.0
func LearnedUnigramCandidateSamplerSeed(value int64) LearnedUnigramCandidateSamplerAttr
LearnedUnigramCandidateSamplerSeed sets the optional seed attribute to value.
value: If either seed or seed2 are set to be non-zero, the random number generator is seeded by the given seed. Otherwise, it is seeded by a random seed. If not specified, defaults to 0
func LearnedUnigramCandidateSamplerSeed2 ¶ added in v1.1.0
func LearnedUnigramCandidateSamplerSeed2(value int64) LearnedUnigramCandidateSamplerAttr
LearnedUnigramCandidateSamplerSeed2 sets the optional seed2 attribute to value.
value: An second seed to avoid seed collision. If not specified, defaults to 0
type ListDiffAttr ¶ added in v1.1.0
type ListDiffAttr func(optionalAttr)
ListDiffAttr is an optional argument to ListDiff.
func ListDiffOutIdx ¶ added in v1.1.0
func ListDiffOutIdx(value tf.DataType) ListDiffAttr
ListDiffOutIdx sets the optional out_idx attribute to value. If not specified, defaults to DT_INT32
type LoadAndRemapMatrixAttr ¶ added in v1.4.0
type LoadAndRemapMatrixAttr func(optionalAttr)
LoadAndRemapMatrixAttr is an optional argument to LoadAndRemapMatrix.
func LoadAndRemapMatrixMaxRowsInMemory ¶ added in v1.4.0
func LoadAndRemapMatrixMaxRowsInMemory(value int64) LoadAndRemapMatrixAttr
LoadAndRemapMatrixMaxRowsInMemory sets the optional max_rows_in_memory attribute to value.
value: The maximum number of rows to load from the checkpoint at once. If less than or equal to 0, the entire matrix will be loaded into memory. Setting this arg trades increased disk reads for lower memory usage. If not specified, defaults to -1
type LogUniformCandidateSamplerAttr ¶ added in v1.1.0
type LogUniformCandidateSamplerAttr func(optionalAttr)
LogUniformCandidateSamplerAttr is an optional argument to LogUniformCandidateSampler.
func LogUniformCandidateSamplerSeed ¶ added in v1.1.0
func LogUniformCandidateSamplerSeed(value int64) LogUniformCandidateSamplerAttr
LogUniformCandidateSamplerSeed sets the optional seed attribute to value.
value: If either seed or seed2 are set to be non-zero, the random number generator is seeded by the given seed. Otherwise, it is seeded by a random seed. If not specified, defaults to 0
func LogUniformCandidateSamplerSeed2 ¶ added in v1.1.0
func LogUniformCandidateSamplerSeed2(value int64) LogUniformCandidateSamplerAttr
LogUniformCandidateSamplerSeed2 sets the optional seed2 attribute to value.
value: An second seed to avoid seed collision. If not specified, defaults to 0
type MapClearAttr ¶ added in v1.3.0
type MapClearAttr func(optionalAttr)
MapClearAttr is an optional argument to MapClear.
func MapClearCapacity ¶ added in v1.3.0
func MapClearCapacity(value int64) MapClearAttr
MapClearCapacity sets the optional capacity attribute to value. If not specified, defaults to 0
REQUIRES: value >= 0
func MapClearContainer ¶ added in v1.3.0
func MapClearContainer(value string) MapClearAttr
MapClearContainer sets the optional container attribute to value. If not specified, defaults to ""
func MapClearMemoryLimit ¶ added in v1.3.0
func MapClearMemoryLimit(value int64) MapClearAttr
MapClearMemoryLimit sets the optional memory_limit attribute to value. If not specified, defaults to 0
REQUIRES: value >= 0
func MapClearSharedName ¶ added in v1.3.0
func MapClearSharedName(value string) MapClearAttr
MapClearSharedName sets the optional shared_name attribute to value. If not specified, defaults to ""
type MapIncompleteSizeAttr ¶ added in v1.3.0
type MapIncompleteSizeAttr func(optionalAttr)
MapIncompleteSizeAttr is an optional argument to MapIncompleteSize.
func MapIncompleteSizeCapacity ¶ added in v1.3.0
func MapIncompleteSizeCapacity(value int64) MapIncompleteSizeAttr
MapIncompleteSizeCapacity sets the optional capacity attribute to value. If not specified, defaults to 0
REQUIRES: value >= 0
func MapIncompleteSizeContainer ¶ added in v1.3.0
func MapIncompleteSizeContainer(value string) MapIncompleteSizeAttr
MapIncompleteSizeContainer sets the optional container attribute to value. If not specified, defaults to ""
func MapIncompleteSizeMemoryLimit ¶ added in v1.3.0
func MapIncompleteSizeMemoryLimit(value int64) MapIncompleteSizeAttr
MapIncompleteSizeMemoryLimit sets the optional memory_limit attribute to value. If not specified, defaults to 0
REQUIRES: value >= 0
func MapIncompleteSizeSharedName ¶ added in v1.3.0
func MapIncompleteSizeSharedName(value string) MapIncompleteSizeAttr
MapIncompleteSizeSharedName sets the optional shared_name attribute to value. If not specified, defaults to ""
type MapPeekAttr ¶ added in v1.3.0
type MapPeekAttr func(optionalAttr)
MapPeekAttr is an optional argument to MapPeek.
func MapPeekCapacity ¶ added in v1.3.0
func MapPeekCapacity(value int64) MapPeekAttr
MapPeekCapacity sets the optional capacity attribute to value. If not specified, defaults to 0
REQUIRES: value >= 0
func MapPeekContainer ¶ added in v1.3.0
func MapPeekContainer(value string) MapPeekAttr
MapPeekContainer sets the optional container attribute to value. If not specified, defaults to ""
func MapPeekMemoryLimit ¶ added in v1.3.0
func MapPeekMemoryLimit(value int64) MapPeekAttr
MapPeekMemoryLimit sets the optional memory_limit attribute to value. If not specified, defaults to 0
REQUIRES: value >= 0
func MapPeekSharedName ¶ added in v1.3.0
func MapPeekSharedName(value string) MapPeekAttr
MapPeekSharedName sets the optional shared_name attribute to value. If not specified, defaults to ""
type MapSizeAttr ¶ added in v1.3.0
type MapSizeAttr func(optionalAttr)
MapSizeAttr is an optional argument to MapSize.
func MapSizeCapacity ¶ added in v1.3.0
func MapSizeCapacity(value int64) MapSizeAttr
MapSizeCapacity sets the optional capacity attribute to value. If not specified, defaults to 0
REQUIRES: value >= 0
func MapSizeContainer ¶ added in v1.3.0
func MapSizeContainer(value string) MapSizeAttr
MapSizeContainer sets the optional container attribute to value. If not specified, defaults to ""
func MapSizeMemoryLimit ¶ added in v1.3.0
func MapSizeMemoryLimit(value int64) MapSizeAttr
MapSizeMemoryLimit sets the optional memory_limit attribute to value. If not specified, defaults to 0
REQUIRES: value >= 0
func MapSizeSharedName ¶ added in v1.3.0
func MapSizeSharedName(value string) MapSizeAttr
MapSizeSharedName sets the optional shared_name attribute to value. If not specified, defaults to ""
type MapStageAttr ¶ added in v1.3.0
type MapStageAttr func(optionalAttr)
MapStageAttr is an optional argument to MapStage.
func MapStageCapacity ¶ added in v1.3.0
func MapStageCapacity(value int64) MapStageAttr
MapStageCapacity sets the optional capacity attribute to value.
value: Maximum number of elements in the Staging Area. If > 0, inserts on the container will block when the capacity is reached. If not specified, defaults to 0
REQUIRES: value >= 0
func MapStageContainer ¶ added in v1.3.0
func MapStageContainer(value string) MapStageAttr
MapStageContainer sets the optional container attribute to value.
value: If non-empty, this queue is placed in the given container. Otherwise, a default container is used. If not specified, defaults to ""
func MapStageMemoryLimit ¶ added in v1.3.0
func MapStageMemoryLimit(value int64) MapStageAttr
MapStageMemoryLimit sets the optional memory_limit attribute to value. If not specified, defaults to 0
REQUIRES: value >= 0
func MapStageSharedName ¶ added in v1.3.0
func MapStageSharedName(value string) MapStageAttr
MapStageSharedName sets the optional shared_name attribute to value.
value: It is necessary to match this name to the matching Unstage Op. If not specified, defaults to ""
type MapUnstageAttr ¶ added in v1.3.0
type MapUnstageAttr func(optionalAttr)
MapUnstageAttr is an optional argument to MapUnstage.
func MapUnstageCapacity ¶ added in v1.3.0
func MapUnstageCapacity(value int64) MapUnstageAttr
MapUnstageCapacity sets the optional capacity attribute to value. If not specified, defaults to 0
REQUIRES: value >= 0
func MapUnstageContainer ¶ added in v1.3.0
func MapUnstageContainer(value string) MapUnstageAttr
MapUnstageContainer sets the optional container attribute to value. If not specified, defaults to ""
func MapUnstageMemoryLimit ¶ added in v1.3.0
func MapUnstageMemoryLimit(value int64) MapUnstageAttr
MapUnstageMemoryLimit sets the optional memory_limit attribute to value. If not specified, defaults to 0
REQUIRES: value >= 0
func MapUnstageSharedName ¶ added in v1.3.0
func MapUnstageSharedName(value string) MapUnstageAttr
MapUnstageSharedName sets the optional shared_name attribute to value. If not specified, defaults to ""
type MapUnstageNoKeyAttr ¶ added in v1.3.0
type MapUnstageNoKeyAttr func(optionalAttr)
MapUnstageNoKeyAttr is an optional argument to MapUnstageNoKey.
func MapUnstageNoKeyCapacity ¶ added in v1.3.0
func MapUnstageNoKeyCapacity(value int64) MapUnstageNoKeyAttr
MapUnstageNoKeyCapacity sets the optional capacity attribute to value. If not specified, defaults to 0
REQUIRES: value >= 0
func MapUnstageNoKeyContainer ¶ added in v1.3.0
func MapUnstageNoKeyContainer(value string) MapUnstageNoKeyAttr
MapUnstageNoKeyContainer sets the optional container attribute to value. If not specified, defaults to ""
func MapUnstageNoKeyMemoryLimit ¶ added in v1.3.0
func MapUnstageNoKeyMemoryLimit(value int64) MapUnstageNoKeyAttr
MapUnstageNoKeyMemoryLimit sets the optional memory_limit attribute to value. If not specified, defaults to 0
REQUIRES: value >= 0
func MapUnstageNoKeySharedName ¶ added in v1.3.0
func MapUnstageNoKeySharedName(value string) MapUnstageNoKeyAttr
MapUnstageNoKeySharedName sets the optional shared_name attribute to value. If not specified, defaults to ""
type MatMulAttr ¶ added in v1.1.0
type MatMulAttr func(optionalAttr)
MatMulAttr is an optional argument to MatMul.
func MatMulTransposeA ¶ added in v1.1.0
func MatMulTransposeA(value bool) MatMulAttr
MatMulTransposeA sets the optional transpose_a attribute to value.
value: If true, "a" is transposed before multiplication. If not specified, defaults to false
func MatMulTransposeB ¶ added in v1.1.0
func MatMulTransposeB(value bool) MatMulAttr
MatMulTransposeB sets the optional transpose_b attribute to value.
value: If true, "b" is transposed before multiplication. If not specified, defaults to false
type MatrixInverseAttr ¶ added in v1.1.0
type MatrixInverseAttr func(optionalAttr)
MatrixInverseAttr is an optional argument to MatrixInverse.
func MatrixInverseAdjoint ¶ added in v1.1.0
func MatrixInverseAdjoint(value bool) MatrixInverseAttr
MatrixInverseAdjoint sets the optional adjoint attribute to value. If not specified, defaults to false
type MatrixSolveAttr ¶ added in v1.1.0
type MatrixSolveAttr func(optionalAttr)
MatrixSolveAttr is an optional argument to MatrixSolve.
func MatrixSolveAdjoint ¶ added in v1.1.0
func MatrixSolveAdjoint(value bool) MatrixSolveAttr
MatrixSolveAdjoint sets the optional adjoint attribute to value.
value: Boolean indicating whether to solve with `matrix` or its (block-wise) adjoint. If not specified, defaults to false
type MatrixSolveLsAttr ¶ added in v1.1.0
type MatrixSolveLsAttr func(optionalAttr)
MatrixSolveLsAttr is an optional argument to MatrixSolveLs.
func MatrixSolveLsFast ¶ added in v1.1.0
func MatrixSolveLsFast(value bool) MatrixSolveLsAttr
MatrixSolveLsFast sets the optional fast attribute to value. If not specified, defaults to true
type MatrixTriangularSolveAttr ¶ added in v1.1.0
type MatrixTriangularSolveAttr func(optionalAttr)
MatrixTriangularSolveAttr is an optional argument to MatrixTriangularSolve.
func MatrixTriangularSolveAdjoint ¶ added in v1.1.0
func MatrixTriangularSolveAdjoint(value bool) MatrixTriangularSolveAttr
MatrixTriangularSolveAdjoint sets the optional adjoint attribute to value.
value: Boolean indicating whether to solve with `matrix` or its (block-wise)
adjoint.
@compatibility(numpy) Equivalent to np.linalg.triangular_solve @end_compatibility If not specified, defaults to false
func MatrixTriangularSolveLower ¶ added in v1.1.0
func MatrixTriangularSolveLower(value bool) MatrixTriangularSolveAttr
MatrixTriangularSolveLower sets the optional lower attribute to value.
value: Boolean indicating whether the innermost matrices in `matrix` are lower or upper triangular. If not specified, defaults to true
type MaxAttr ¶ added in v1.1.0
type MaxAttr func(optionalAttr)
MaxAttr is an optional argument to Max.
func MaxKeepDims ¶ added in v1.1.0
MaxKeepDims sets the optional keep_dims attribute to value.
value: If true, retain reduced dimensions with length 1. If not specified, defaults to false
type MaxPool3DAttr ¶ added in v1.2.0
type MaxPool3DAttr func(optionalAttr)
MaxPool3DAttr is an optional argument to MaxPool3D.
func MaxPool3DDataFormat ¶ added in v1.2.0
func MaxPool3DDataFormat(value string) MaxPool3DAttr
MaxPool3DDataFormat sets the optional data_format attribute to value.
value: The data format of the input and output data. With the default format "NDHWC", the data is stored in the order of:
[batch, in_depth, in_height, in_width, in_channels].
Alternatively, the format could be "NCDHW", the data storage order is:
[batch, in_channels, in_depth, in_height, in_width].
If not specified, defaults to "NDHWC"
type MaxPool3DGradAttr ¶ added in v1.2.0
type MaxPool3DGradAttr func(optionalAttr)
MaxPool3DGradAttr is an optional argument to MaxPool3DGrad.
func MaxPool3DGradDataFormat ¶ added in v1.2.0
func MaxPool3DGradDataFormat(value string) MaxPool3DGradAttr
MaxPool3DGradDataFormat sets the optional data_format attribute to value.
value: The data format of the input and output data. With the default format "NDHWC", the data is stored in the order of:
[batch, in_depth, in_height, in_width, in_channels].
Alternatively, the format could be "NCDHW", the data storage order is:
[batch, in_channels, in_depth, in_height, in_width].
If not specified, defaults to "NDHWC"
type MaxPool3DGradGradAttr ¶ added in v1.2.0
type MaxPool3DGradGradAttr func(optionalAttr)
MaxPool3DGradGradAttr is an optional argument to MaxPool3DGradGrad.
func MaxPool3DGradGradDataFormat ¶ added in v1.2.0
func MaxPool3DGradGradDataFormat(value string) MaxPool3DGradGradAttr
MaxPool3DGradGradDataFormat sets the optional data_format attribute to value.
value: The data format of the input and output data. With the default format "NDHWC", the data is stored in the order of:
[batch, in_depth, in_height, in_width, in_channels].
Alternatively, the format could be "NCDHW", the data storage order is:
[batch, in_channels, in_depth, in_height, in_width].
If not specified, defaults to "NDHWC"
type MaxPoolAttr ¶ added in v1.1.0
type MaxPoolAttr func(optionalAttr)
MaxPoolAttr is an optional argument to MaxPool.
func MaxPoolDataFormat ¶ added in v1.1.0
func MaxPoolDataFormat(value string) MaxPoolAttr
MaxPoolDataFormat sets the optional data_format attribute to value.
value: Specify the data format of the input and output data. With the default format "NHWC", the data is stored in the order of:
[batch, in_height, in_width, in_channels].
Alternatively, the format could be "NCHW", the data storage order of:
[batch, in_channels, in_height, in_width].
If not specified, defaults to "NHWC"
type MaxPoolGradAttr ¶ added in v1.1.0
type MaxPoolGradAttr func(optionalAttr)
MaxPoolGradAttr is an optional argument to MaxPoolGrad.
func MaxPoolGradDataFormat ¶ added in v1.1.0
func MaxPoolGradDataFormat(value string) MaxPoolGradAttr
MaxPoolGradDataFormat sets the optional data_format attribute to value.
value: Specify the data format of the input and output data. With the default format "NHWC", the data is stored in the order of:
[batch, in_height, in_width, in_channels].
Alternatively, the format could be "NCHW", the data storage order of:
[batch, in_channels, in_height, in_width].
If not specified, defaults to "NHWC"
type MaxPoolGradGradAttr ¶ added in v1.2.0
type MaxPoolGradGradAttr func(optionalAttr)
MaxPoolGradGradAttr is an optional argument to MaxPoolGradGrad.
func MaxPoolGradGradDataFormat ¶ added in v1.2.0
func MaxPoolGradGradDataFormat(value string) MaxPoolGradGradAttr
MaxPoolGradGradDataFormat sets the optional data_format attribute to value.
value: Specify the data format of the input and output data. With the default format "NHWC", the data is stored in the order of:
[batch, in_height, in_width, in_channels].
Alternatively, the format could be "NCHW", the data storage order of:
[batch, in_channels, in_height, in_width].
If not specified, defaults to "NHWC"
type MaxPoolGradGradV2Attr ¶ added in v1.4.0
type MaxPoolGradGradV2Attr func(optionalAttr)
MaxPoolGradGradV2Attr is an optional argument to MaxPoolGradGradV2.
func MaxPoolGradGradV2DataFormat ¶ added in v1.4.0
func MaxPoolGradGradV2DataFormat(value string) MaxPoolGradGradV2Attr
MaxPoolGradGradV2DataFormat sets the optional data_format attribute to value.
value: Specify the data format of the input and output data. With the default format "NHWC", the data is stored in the order of:
[batch, in_height, in_width, in_channels].
Alternatively, the format could be "NCHW", the data storage order of:
[batch, in_channels, in_height, in_width].
If not specified, defaults to "NHWC"
type MaxPoolGradV2Attr ¶ added in v1.4.0
type MaxPoolGradV2Attr func(optionalAttr)
MaxPoolGradV2Attr is an optional argument to MaxPoolGradV2.
func MaxPoolGradV2DataFormat ¶ added in v1.4.0
func MaxPoolGradV2DataFormat(value string) MaxPoolGradV2Attr
MaxPoolGradV2DataFormat sets the optional data_format attribute to value.
value: Specify the data format of the input and output data. With the default format "NHWC", the data is stored in the order of:
[batch, in_height, in_width, in_channels].
Alternatively, the format could be "NCHW", the data storage order of:
[batch, in_channels, in_height, in_width].
If not specified, defaults to "NHWC"
type MaxPoolV2Attr ¶ added in v1.4.0
type MaxPoolV2Attr func(optionalAttr)
MaxPoolV2Attr is an optional argument to MaxPoolV2.
func MaxPoolV2DataFormat ¶ added in v1.4.0
func MaxPoolV2DataFormat(value string) MaxPoolV2Attr
MaxPoolV2DataFormat sets the optional data_format attribute to value.
value: Specify the data format of the input and output data. With the default format "NHWC", the data is stored in the order of:
[batch, in_height, in_width, in_channels].
Alternatively, the format could be "NCHW", the data storage order of:
[batch, in_channels, in_height, in_width].
If not specified, defaults to "NHWC"
type MaxPoolWithArgmaxAttr ¶ added in v1.1.0
type MaxPoolWithArgmaxAttr func(optionalAttr)
MaxPoolWithArgmaxAttr is an optional argument to MaxPoolWithArgmax.
func MaxPoolWithArgmaxTargmax ¶ added in v1.1.0
func MaxPoolWithArgmaxTargmax(value tf.DataType) MaxPoolWithArgmaxAttr
MaxPoolWithArgmaxTargmax sets the optional Targmax attribute to value. If not specified, defaults to DT_INT64
type MeanAttr ¶ added in v1.1.0
type MeanAttr func(optionalAttr)
MeanAttr is an optional argument to Mean.
func MeanKeepDims ¶ added in v1.1.0
MeanKeepDims sets the optional keep_dims attribute to value.
value: If true, retain reduced dimensions with length 1. If not specified, defaults to false
type MergeV2CheckpointsAttr ¶ added in v1.1.0
type MergeV2CheckpointsAttr func(optionalAttr)
MergeV2CheckpointsAttr is an optional argument to MergeV2Checkpoints.
func MergeV2CheckpointsDeleteOldDirs ¶ added in v1.1.0
func MergeV2CheckpointsDeleteOldDirs(value bool) MergeV2CheckpointsAttr
MergeV2CheckpointsDeleteOldDirs sets the optional delete_old_dirs attribute to value.
value: see above. If not specified, defaults to true
type MfccAttr ¶ added in v1.2.0
type MfccAttr func(optionalAttr)
MfccAttr is an optional argument to Mfcc.
func MfccDctCoefficientCount ¶ added in v1.2.0
MfccDctCoefficientCount sets the optional dct_coefficient_count attribute to value.
value: How many output channels to produce per time slice. If not specified, defaults to 13
func MfccFilterbankChannelCount ¶ added in v1.2.0
MfccFilterbankChannelCount sets the optional filterbank_channel_count attribute to value.
value: Resolution of the Mel bank used internally. If not specified, defaults to 40
func MfccLowerFrequencyLimit ¶ added in v1.2.0
MfccLowerFrequencyLimit sets the optional lower_frequency_limit attribute to value.
value: The lowest frequency to use when calculating the ceptstrum. If not specified, defaults to 20
func MfccUpperFrequencyLimit ¶ added in v1.2.0
MfccUpperFrequencyLimit sets the optional upper_frequency_limit attribute to value.
value: The highest frequency to use when calculating the ceptstrum. If not specified, defaults to 4000
type MinAttr ¶ added in v1.1.0
type MinAttr func(optionalAttr)
MinAttr is an optional argument to Min.
func MinKeepDims ¶ added in v1.1.0
MinKeepDims sets the optional keep_dims attribute to value.
value: If true, retain reduced dimensions with length 1. If not specified, defaults to false
type MultinomialAttr ¶ added in v1.1.0
type MultinomialAttr func(optionalAttr)
MultinomialAttr is an optional argument to Multinomial.
func MultinomialOutputDtype ¶ added in v1.6.0
func MultinomialOutputDtype(value tf.DataType) MultinomialAttr
MultinomialOutputDtype sets the optional output_dtype attribute to value. If not specified, defaults to DT_INT64
func MultinomialSeed ¶ added in v1.1.0
func MultinomialSeed(value int64) MultinomialAttr
MultinomialSeed sets the optional seed attribute to value.
value: If either seed or seed2 is set to be non-zero, the internal random number generator is seeded by the given seed. Otherwise, a random seed is used. If not specified, defaults to 0
func MultinomialSeed2 ¶ added in v1.1.0
func MultinomialSeed2(value int64) MultinomialAttr
MultinomialSeed2 sets the optional seed2 attribute to value.
value: A second seed to avoid seed collision. If not specified, defaults to 0
type MutableDenseHashTableV2Attr ¶ added in v1.2.0
type MutableDenseHashTableV2Attr func(optionalAttr)
MutableDenseHashTableV2Attr is an optional argument to MutableDenseHashTableV2.
func MutableDenseHashTableV2Container ¶ added in v1.2.0
func MutableDenseHashTableV2Container(value string) MutableDenseHashTableV2Attr
MutableDenseHashTableV2Container sets the optional container attribute to value.
value: If non-empty, this table is placed in the given container. Otherwise, a default container is used. If not specified, defaults to ""
func MutableDenseHashTableV2InitialNumBuckets ¶ added in v1.2.0
func MutableDenseHashTableV2InitialNumBuckets(value int64) MutableDenseHashTableV2Attr
MutableDenseHashTableV2InitialNumBuckets sets the optional initial_num_buckets attribute to value.
value: The initial number of hash table buckets. Must be a power to 2. If not specified, defaults to 131072
func MutableDenseHashTableV2MaxLoadFactor ¶ added in v1.2.0
func MutableDenseHashTableV2MaxLoadFactor(value float32) MutableDenseHashTableV2Attr
MutableDenseHashTableV2MaxLoadFactor sets the optional max_load_factor attribute to value.
value: The maximum ratio between number of entries and number of buckets before growing the table. Must be between 0 and 1. If not specified, defaults to 0.8
func MutableDenseHashTableV2SharedName ¶ added in v1.2.0
func MutableDenseHashTableV2SharedName(value string) MutableDenseHashTableV2Attr
MutableDenseHashTableV2SharedName sets the optional shared_name attribute to value.
value: If non-empty, this table is shared under the given name across multiple sessions. If not specified, defaults to ""
func MutableDenseHashTableV2UseNodeNameSharing ¶ added in v1.2.0
func MutableDenseHashTableV2UseNodeNameSharing(value bool) MutableDenseHashTableV2Attr
MutableDenseHashTableV2UseNodeNameSharing sets the optional use_node_name_sharing attribute to value. If not specified, defaults to false
func MutableDenseHashTableV2ValueShape ¶ added in v1.2.0
func MutableDenseHashTableV2ValueShape(value tf.Shape) MutableDenseHashTableV2Attr
MutableDenseHashTableV2ValueShape sets the optional value_shape attribute to value.
value: The shape of each value. If not specified, defaults to <>
type MutableHashTableOfTensorsV2Attr ¶ added in v1.2.0
type MutableHashTableOfTensorsV2Attr func(optionalAttr)
MutableHashTableOfTensorsV2Attr is an optional argument to MutableHashTableOfTensorsV2.
func MutableHashTableOfTensorsV2Container ¶ added in v1.2.0
func MutableHashTableOfTensorsV2Container(value string) MutableHashTableOfTensorsV2Attr
MutableHashTableOfTensorsV2Container sets the optional container attribute to value.
value: If non-empty, this table is placed in the given container. Otherwise, a default container is used. If not specified, defaults to ""
func MutableHashTableOfTensorsV2SharedName ¶ added in v1.2.0
func MutableHashTableOfTensorsV2SharedName(value string) MutableHashTableOfTensorsV2Attr
MutableHashTableOfTensorsV2SharedName sets the optional shared_name attribute to value.
value: If non-empty, this table is shared under the given name across multiple sessions. If not specified, defaults to ""
func MutableHashTableOfTensorsV2UseNodeNameSharing ¶ added in v1.2.0
func MutableHashTableOfTensorsV2UseNodeNameSharing(value bool) MutableHashTableOfTensorsV2Attr
MutableHashTableOfTensorsV2UseNodeNameSharing sets the optional use_node_name_sharing attribute to value. If not specified, defaults to false
func MutableHashTableOfTensorsV2ValueShape ¶ added in v1.2.0
func MutableHashTableOfTensorsV2ValueShape(value tf.Shape) MutableHashTableOfTensorsV2Attr
MutableHashTableOfTensorsV2ValueShape sets the optional value_shape attribute to value. If not specified, defaults to <>
type MutableHashTableV2Attr ¶ added in v1.2.0
type MutableHashTableV2Attr func(optionalAttr)
MutableHashTableV2Attr is an optional argument to MutableHashTableV2.
func MutableHashTableV2Container ¶ added in v1.2.0
func MutableHashTableV2Container(value string) MutableHashTableV2Attr
MutableHashTableV2Container sets the optional container attribute to value.
value: If non-empty, this table is placed in the given container. Otherwise, a default container is used. If not specified, defaults to ""
func MutableHashTableV2SharedName ¶ added in v1.2.0
func MutableHashTableV2SharedName(value string) MutableHashTableV2Attr
MutableHashTableV2SharedName sets the optional shared_name attribute to value.
value: If non-empty, this table is shared under the given name across multiple sessions. If not specified, defaults to ""
func MutableHashTableV2UseNodeNameSharing ¶ added in v1.2.0
func MutableHashTableV2UseNodeNameSharing(value bool) MutableHashTableV2Attr
MutableHashTableV2UseNodeNameSharing sets the optional use_node_name_sharing attribute to value.
value: If true and shared_name is empty, the table is shared using the node name. If not specified, defaults to false
type NonMaxSuppressionAttr ¶ added in v1.1.0
type NonMaxSuppressionAttr func(optionalAttr)
NonMaxSuppressionAttr is an optional argument to NonMaxSuppression.
func NonMaxSuppressionIouThreshold ¶ added in v1.1.0
func NonMaxSuppressionIouThreshold(value float32) NonMaxSuppressionAttr
NonMaxSuppressionIouThreshold sets the optional iou_threshold attribute to value.
value: A float representing the threshold for deciding whether boxes overlap too much with respect to IOU. If not specified, defaults to 0.5
type NthElementAttr ¶ added in v1.5.0
type NthElementAttr func(optionalAttr)
NthElementAttr is an optional argument to NthElement.
func NthElementReverse ¶ added in v1.5.0
func NthElementReverse(value bool) NthElementAttr
NthElementReverse sets the optional reverse attribute to value.
value: When set to True, find the nth-largest value in the vector and vice versa. If not specified, defaults to false
type OneHotAttr ¶ added in v1.1.0
type OneHotAttr func(optionalAttr)
OneHotAttr is an optional argument to OneHot.
func OneHotAxis ¶ added in v1.1.0
func OneHotAxis(value int64) OneHotAttr
OneHotAxis sets the optional axis attribute to value.
value: The axis to fill (default: -1, a new inner-most axis). If not specified, defaults to -1
type OrderedMapClearAttr ¶ added in v1.3.0
type OrderedMapClearAttr func(optionalAttr)
OrderedMapClearAttr is an optional argument to OrderedMapClear.
func OrderedMapClearCapacity ¶ added in v1.3.0
func OrderedMapClearCapacity(value int64) OrderedMapClearAttr
OrderedMapClearCapacity sets the optional capacity attribute to value. If not specified, defaults to 0
REQUIRES: value >= 0
func OrderedMapClearContainer ¶ added in v1.3.0
func OrderedMapClearContainer(value string) OrderedMapClearAttr
OrderedMapClearContainer sets the optional container attribute to value. If not specified, defaults to ""
func OrderedMapClearMemoryLimit ¶ added in v1.3.0
func OrderedMapClearMemoryLimit(value int64) OrderedMapClearAttr
OrderedMapClearMemoryLimit sets the optional memory_limit attribute to value. If not specified, defaults to 0
REQUIRES: value >= 0
func OrderedMapClearSharedName ¶ added in v1.3.0
func OrderedMapClearSharedName(value string) OrderedMapClearAttr
OrderedMapClearSharedName sets the optional shared_name attribute to value. If not specified, defaults to ""
type OrderedMapIncompleteSizeAttr ¶ added in v1.3.0
type OrderedMapIncompleteSizeAttr func(optionalAttr)
OrderedMapIncompleteSizeAttr is an optional argument to OrderedMapIncompleteSize.
func OrderedMapIncompleteSizeCapacity ¶ added in v1.3.0
func OrderedMapIncompleteSizeCapacity(value int64) OrderedMapIncompleteSizeAttr
OrderedMapIncompleteSizeCapacity sets the optional capacity attribute to value. If not specified, defaults to 0
REQUIRES: value >= 0
func OrderedMapIncompleteSizeContainer ¶ added in v1.3.0
func OrderedMapIncompleteSizeContainer(value string) OrderedMapIncompleteSizeAttr
OrderedMapIncompleteSizeContainer sets the optional container attribute to value. If not specified, defaults to ""
func OrderedMapIncompleteSizeMemoryLimit ¶ added in v1.3.0
func OrderedMapIncompleteSizeMemoryLimit(value int64) OrderedMapIncompleteSizeAttr
OrderedMapIncompleteSizeMemoryLimit sets the optional memory_limit attribute to value. If not specified, defaults to 0
REQUIRES: value >= 0
func OrderedMapIncompleteSizeSharedName ¶ added in v1.3.0
func OrderedMapIncompleteSizeSharedName(value string) OrderedMapIncompleteSizeAttr
OrderedMapIncompleteSizeSharedName sets the optional shared_name attribute to value. If not specified, defaults to ""
type OrderedMapPeekAttr ¶ added in v1.3.0
type OrderedMapPeekAttr func(optionalAttr)
OrderedMapPeekAttr is an optional argument to OrderedMapPeek.
func OrderedMapPeekCapacity ¶ added in v1.3.0
func OrderedMapPeekCapacity(value int64) OrderedMapPeekAttr
OrderedMapPeekCapacity sets the optional capacity attribute to value. If not specified, defaults to 0
REQUIRES: value >= 0
func OrderedMapPeekContainer ¶ added in v1.3.0
func OrderedMapPeekContainer(value string) OrderedMapPeekAttr
OrderedMapPeekContainer sets the optional container attribute to value. If not specified, defaults to ""
func OrderedMapPeekMemoryLimit ¶ added in v1.3.0
func OrderedMapPeekMemoryLimit(value int64) OrderedMapPeekAttr
OrderedMapPeekMemoryLimit sets the optional memory_limit attribute to value. If not specified, defaults to 0
REQUIRES: value >= 0
func OrderedMapPeekSharedName ¶ added in v1.3.0
func OrderedMapPeekSharedName(value string) OrderedMapPeekAttr
OrderedMapPeekSharedName sets the optional shared_name attribute to value. If not specified, defaults to ""
type OrderedMapSizeAttr ¶ added in v1.3.0
type OrderedMapSizeAttr func(optionalAttr)
OrderedMapSizeAttr is an optional argument to OrderedMapSize.
func OrderedMapSizeCapacity ¶ added in v1.3.0
func OrderedMapSizeCapacity(value int64) OrderedMapSizeAttr
OrderedMapSizeCapacity sets the optional capacity attribute to value. If not specified, defaults to 0
REQUIRES: value >= 0
func OrderedMapSizeContainer ¶ added in v1.3.0
func OrderedMapSizeContainer(value string) OrderedMapSizeAttr
OrderedMapSizeContainer sets the optional container attribute to value. If not specified, defaults to ""
func OrderedMapSizeMemoryLimit ¶ added in v1.3.0
func OrderedMapSizeMemoryLimit(value int64) OrderedMapSizeAttr
OrderedMapSizeMemoryLimit sets the optional memory_limit attribute to value. If not specified, defaults to 0
REQUIRES: value >= 0
func OrderedMapSizeSharedName ¶ added in v1.3.0
func OrderedMapSizeSharedName(value string) OrderedMapSizeAttr
OrderedMapSizeSharedName sets the optional shared_name attribute to value. If not specified, defaults to ""
type OrderedMapStageAttr ¶ added in v1.3.0
type OrderedMapStageAttr func(optionalAttr)
OrderedMapStageAttr is an optional argument to OrderedMapStage.
func OrderedMapStageCapacity ¶ added in v1.3.0
func OrderedMapStageCapacity(value int64) OrderedMapStageAttr
OrderedMapStageCapacity sets the optional capacity attribute to value.
value: Maximum number of elements in the Staging Area. If > 0, inserts on the container will block when the capacity is reached. If not specified, defaults to 0
REQUIRES: value >= 0
func OrderedMapStageContainer ¶ added in v1.3.0
func OrderedMapStageContainer(value string) OrderedMapStageAttr
OrderedMapStageContainer sets the optional container attribute to value.
value: If non-empty, this queue is placed in the given container. Otherwise, a default container is used. If not specified, defaults to ""
func OrderedMapStageMemoryLimit ¶ added in v1.3.0
func OrderedMapStageMemoryLimit(value int64) OrderedMapStageAttr
OrderedMapStageMemoryLimit sets the optional memory_limit attribute to value. If not specified, defaults to 0
REQUIRES: value >= 0
func OrderedMapStageSharedName ¶ added in v1.3.0
func OrderedMapStageSharedName(value string) OrderedMapStageAttr
OrderedMapStageSharedName sets the optional shared_name attribute to value.
value: It is necessary to match this name to the matching Unstage Op. If not specified, defaults to ""
type OrderedMapUnstageAttr ¶ added in v1.3.0
type OrderedMapUnstageAttr func(optionalAttr)
OrderedMapUnstageAttr is an optional argument to OrderedMapUnstage.
func OrderedMapUnstageCapacity ¶ added in v1.3.0
func OrderedMapUnstageCapacity(value int64) OrderedMapUnstageAttr
OrderedMapUnstageCapacity sets the optional capacity attribute to value. If not specified, defaults to 0
REQUIRES: value >= 0
func OrderedMapUnstageContainer ¶ added in v1.3.0
func OrderedMapUnstageContainer(value string) OrderedMapUnstageAttr
OrderedMapUnstageContainer sets the optional container attribute to value. If not specified, defaults to ""
func OrderedMapUnstageMemoryLimit ¶ added in v1.3.0
func OrderedMapUnstageMemoryLimit(value int64) OrderedMapUnstageAttr
OrderedMapUnstageMemoryLimit sets the optional memory_limit attribute to value. If not specified, defaults to 0
REQUIRES: value >= 0
func OrderedMapUnstageSharedName ¶ added in v1.3.0
func OrderedMapUnstageSharedName(value string) OrderedMapUnstageAttr
OrderedMapUnstageSharedName sets the optional shared_name attribute to value. If not specified, defaults to ""
type OrderedMapUnstageNoKeyAttr ¶ added in v1.3.0
type OrderedMapUnstageNoKeyAttr func(optionalAttr)
OrderedMapUnstageNoKeyAttr is an optional argument to OrderedMapUnstageNoKey.
func OrderedMapUnstageNoKeyCapacity ¶ added in v1.3.0
func OrderedMapUnstageNoKeyCapacity(value int64) OrderedMapUnstageNoKeyAttr
OrderedMapUnstageNoKeyCapacity sets the optional capacity attribute to value. If not specified, defaults to 0
REQUIRES: value >= 0
func OrderedMapUnstageNoKeyContainer ¶ added in v1.3.0
func OrderedMapUnstageNoKeyContainer(value string) OrderedMapUnstageNoKeyAttr
OrderedMapUnstageNoKeyContainer sets the optional container attribute to value. If not specified, defaults to ""
func OrderedMapUnstageNoKeyMemoryLimit ¶ added in v1.3.0
func OrderedMapUnstageNoKeyMemoryLimit(value int64) OrderedMapUnstageNoKeyAttr
OrderedMapUnstageNoKeyMemoryLimit sets the optional memory_limit attribute to value. If not specified, defaults to 0
REQUIRES: value >= 0
func OrderedMapUnstageNoKeySharedName ¶ added in v1.3.0
func OrderedMapUnstageNoKeySharedName(value string) OrderedMapUnstageNoKeyAttr
OrderedMapUnstageNoKeySharedName sets the optional shared_name attribute to value. If not specified, defaults to ""
type PackAttr ¶ added in v1.1.0
type PackAttr func(optionalAttr)
PackAttr is an optional argument to Pack.
type PaddingFIFOQueueV2Attr ¶ added in v1.1.0
type PaddingFIFOQueueV2Attr func(optionalAttr)
PaddingFIFOQueueV2Attr is an optional argument to PaddingFIFOQueueV2.
func PaddingFIFOQueueV2Capacity ¶ added in v1.1.0
func PaddingFIFOQueueV2Capacity(value int64) PaddingFIFOQueueV2Attr
PaddingFIFOQueueV2Capacity sets the optional capacity attribute to value.
value: The upper bound on the number of elements in this queue. Negative numbers mean no limit. If not specified, defaults to -1
func PaddingFIFOQueueV2Container ¶ added in v1.1.0
func PaddingFIFOQueueV2Container(value string) PaddingFIFOQueueV2Attr
PaddingFIFOQueueV2Container sets the optional container attribute to value.
value: If non-empty, this queue is placed in the given container. Otherwise, a default container is used. If not specified, defaults to ""
func PaddingFIFOQueueV2Shapes ¶ added in v1.1.0
func PaddingFIFOQueueV2Shapes(value []tf.Shape) PaddingFIFOQueueV2Attr
PaddingFIFOQueueV2Shapes sets the optional shapes attribute to value.
value: The shape of each component in a value. The length of this attr must be either 0 or the same as the length of component_types. Shapes of fixed rank but variable size are allowed by setting any shape dimension to -1. In this case, the inputs' shape may vary along the given dimension, and DequeueMany will pad the given dimension with zeros up to the maximum shape of all elements in the given batch. If the length of this attr is 0, different queue elements may have different ranks and shapes, but only one element may be dequeued at a time. If not specified, defaults to <>
REQUIRES: len(value) >= 0
func PaddingFIFOQueueV2SharedName ¶ added in v1.1.0
func PaddingFIFOQueueV2SharedName(value string) PaddingFIFOQueueV2Attr
PaddingFIFOQueueV2SharedName sets the optional shared_name attribute to value.
value: If non-empty, this queue will be shared under the given name across multiple sessions. If not specified, defaults to ""
type ParameterizedTruncatedNormalAttr ¶ added in v1.1.0
type ParameterizedTruncatedNormalAttr func(optionalAttr)
ParameterizedTruncatedNormalAttr is an optional argument to ParameterizedTruncatedNormal.
func ParameterizedTruncatedNormalSeed ¶ added in v1.1.0
func ParameterizedTruncatedNormalSeed(value int64) ParameterizedTruncatedNormalAttr
ParameterizedTruncatedNormalSeed sets the optional seed attribute to value.
value: If either `seed` or `seed2` are set to be non-zero, the random number generator is seeded by the given seed. Otherwise, it is seeded by a random seed. If not specified, defaults to 0
func ParameterizedTruncatedNormalSeed2 ¶ added in v1.1.0
func ParameterizedTruncatedNormalSeed2(value int64) ParameterizedTruncatedNormalAttr
ParameterizedTruncatedNormalSeed2 sets the optional seed2 attribute to value.
value: A second seed to avoid seed collision. If not specified, defaults to 0
type ParseSingleSequenceExampleAttr ¶ added in v1.1.0
type ParseSingleSequenceExampleAttr func(optionalAttr)
ParseSingleSequenceExampleAttr is an optional argument to ParseSingleSequenceExample.
func ParseSingleSequenceExampleContextDenseShapes ¶ added in v1.1.0
func ParseSingleSequenceExampleContextDenseShapes(value []tf.Shape) ParseSingleSequenceExampleAttr
ParseSingleSequenceExampleContextDenseShapes sets the optional context_dense_shapes attribute to value.
value: A list of Ncontext_dense shapes; the shapes of data in each context Feature given in context_dense_keys. The number of elements in the Feature corresponding to context_dense_key[j] must always equal context_dense_shapes[j].NumEntries(). The shape of context_dense_values[j] will match context_dense_shapes[j]. If not specified, defaults to <>
REQUIRES: len(value) >= 0
func ParseSingleSequenceExampleContextSparseTypes ¶ added in v1.1.0
func ParseSingleSequenceExampleContextSparseTypes(value []tf.DataType) ParseSingleSequenceExampleAttr
ParseSingleSequenceExampleContextSparseTypes sets the optional context_sparse_types attribute to value.
value: A list of Ncontext_sparse types; the data types of data in each context Feature given in context_sparse_keys. Currently the ParseSingleSequenceExample supports DT_FLOAT (FloatList), DT_INT64 (Int64List), and DT_STRING (BytesList). If not specified, defaults to <>
REQUIRES: len(value) >= 0
func ParseSingleSequenceExampleFeatureListDenseShapes ¶ added in v1.1.0
func ParseSingleSequenceExampleFeatureListDenseShapes(value []tf.Shape) ParseSingleSequenceExampleAttr
ParseSingleSequenceExampleFeatureListDenseShapes sets the optional feature_list_dense_shapes attribute to value.
value: A list of Nfeature_list_dense shapes; the shapes of data in each FeatureList given in feature_list_dense_keys. The shape of each Feature in the FeatureList corresponding to feature_list_dense_key[j] must always equal feature_list_dense_shapes[j].NumEntries(). If not specified, defaults to <>
REQUIRES: len(value) >= 0
func ParseSingleSequenceExampleFeatureListDenseTypes ¶ added in v1.1.0
func ParseSingleSequenceExampleFeatureListDenseTypes(value []tf.DataType) ParseSingleSequenceExampleAttr
ParseSingleSequenceExampleFeatureListDenseTypes sets the optional feature_list_dense_types attribute to value. If not specified, defaults to <>
REQUIRES: len(value) >= 0
func ParseSingleSequenceExampleFeatureListSparseTypes ¶ added in v1.1.0
func ParseSingleSequenceExampleFeatureListSparseTypes(value []tf.DataType) ParseSingleSequenceExampleAttr
ParseSingleSequenceExampleFeatureListSparseTypes sets the optional feature_list_sparse_types attribute to value.
value: A list of Nfeature_list_sparse types; the data types of data in each FeatureList given in feature_list_sparse_keys. Currently the ParseSingleSequenceExample supports DT_FLOAT (FloatList), DT_INT64 (Int64List), and DT_STRING (BytesList). If not specified, defaults to <>
REQUIRES: len(value) >= 0
type PlaceholderAttr ¶ added in v1.1.0
type PlaceholderAttr func(optionalAttr)
PlaceholderAttr is an optional argument to Placeholder.
func PlaceholderShape ¶ added in v1.1.0
func PlaceholderShape(value tf.Shape) PlaceholderAttr
PlaceholderShape sets the optional shape attribute to value.
value: (Optional) The shape of the tensor. If the shape has 0 dimensions, the shape is unconstrained. If not specified, defaults to <unknown_rank:true >
type PreventGradientAttr ¶ added in v1.1.0
type PreventGradientAttr func(optionalAttr)
PreventGradientAttr is an optional argument to PreventGradient.
func PreventGradientMessage ¶ added in v1.1.0
func PreventGradientMessage(value string) PreventGradientAttr
PreventGradientMessage sets the optional message attribute to value.
value: Will be printed in the error when anyone tries to differentiate this operation. If not specified, defaults to ""
type PrintAttr ¶ added in v1.1.0
type PrintAttr func(optionalAttr)
PrintAttr is an optional argument to Print.
func PrintFirstN ¶ added in v1.1.0
PrintFirstN sets the optional first_n attribute to value.
value: Only log `first_n` number of times. -1 disables logging. If not specified, defaults to -1
func PrintMessage ¶ added in v1.1.0
PrintMessage sets the optional message attribute to value.
value: A string, prefix of the error message. If not specified, defaults to ""
func PrintSummarize ¶ added in v1.1.0
PrintSummarize sets the optional summarize attribute to value.
value: Only print this many entries of each tensor. If not specified, defaults to 3
type PriorityQueueV2Attr ¶ added in v1.1.0
type PriorityQueueV2Attr func(optionalAttr)
PriorityQueueV2Attr is an optional argument to PriorityQueueV2.
func PriorityQueueV2Capacity ¶ added in v1.1.0
func PriorityQueueV2Capacity(value int64) PriorityQueueV2Attr
PriorityQueueV2Capacity sets the optional capacity attribute to value.
value: The upper bound on the number of elements in this queue. Negative numbers mean no limit. If not specified, defaults to -1
func PriorityQueueV2ComponentTypes ¶ added in v1.1.0
func PriorityQueueV2ComponentTypes(value []tf.DataType) PriorityQueueV2Attr
PriorityQueueV2ComponentTypes sets the optional component_types attribute to value.
value: The type of each component in a value. If not specified, defaults to <>
REQUIRES: len(value) >= 0
func PriorityQueueV2Container ¶ added in v1.1.0
func PriorityQueueV2Container(value string) PriorityQueueV2Attr
PriorityQueueV2Container sets the optional container attribute to value.
value: If non-empty, this queue is placed in the given container. Otherwise, a default container is used. If not specified, defaults to ""
func PriorityQueueV2SharedName ¶ added in v1.1.0
func PriorityQueueV2SharedName(value string) PriorityQueueV2Attr
PriorityQueueV2SharedName sets the optional shared_name attribute to value.
value: If non-empty, this queue will be shared under the given name across multiple sessions. If not specified, defaults to ""
type ProdAttr ¶ added in v1.1.0
type ProdAttr func(optionalAttr)
ProdAttr is an optional argument to Prod.
func ProdKeepDims ¶ added in v1.1.0
ProdKeepDims sets the optional keep_dims attribute to value.
value: If true, retain reduced dimensions with length 1. If not specified, defaults to false
type QrAttr ¶ added in v1.1.0
type QrAttr func(optionalAttr)
QrAttr is an optional argument to Qr.
func QrFullMatrices ¶ added in v1.1.0
QrFullMatrices sets the optional full_matrices attribute to value.
value: If true, compute full-sized `q` and `r`. If false (the default), compute only the leading `P` columns of `q`. If not specified, defaults to false
type QuantizeAndDequantizeAttr ¶ added in v1.1.0
type QuantizeAndDequantizeAttr func(optionalAttr)
QuantizeAndDequantizeAttr is an optional argument to QuantizeAndDequantize.
func QuantizeAndDequantizeInputMax ¶ added in v1.1.0
func QuantizeAndDequantizeInputMax(value float32) QuantizeAndDequantizeAttr
QuantizeAndDequantizeInputMax sets the optional input_max attribute to value. If not specified, defaults to 0
func QuantizeAndDequantizeInputMin ¶ added in v1.1.0
func QuantizeAndDequantizeInputMin(value float32) QuantizeAndDequantizeAttr
QuantizeAndDequantizeInputMin sets the optional input_min attribute to value. If not specified, defaults to 0
func QuantizeAndDequantizeNumBits ¶ added in v1.1.0
func QuantizeAndDequantizeNumBits(value int64) QuantizeAndDequantizeAttr
QuantizeAndDequantizeNumBits sets the optional num_bits attribute to value. If not specified, defaults to 8
func QuantizeAndDequantizeRangeGiven ¶ added in v1.1.0
func QuantizeAndDequantizeRangeGiven(value bool) QuantizeAndDequantizeAttr
QuantizeAndDequantizeRangeGiven sets the optional range_given attribute to value. If not specified, defaults to false
func QuantizeAndDequantizeSignedInput ¶ added in v1.1.0
func QuantizeAndDequantizeSignedInput(value bool) QuantizeAndDequantizeAttr
QuantizeAndDequantizeSignedInput sets the optional signed_input attribute to value. If not specified, defaults to true
type QuantizeAndDequantizeV2Attr ¶ added in v1.1.0
type QuantizeAndDequantizeV2Attr func(optionalAttr)
QuantizeAndDequantizeV2Attr is an optional argument to QuantizeAndDequantizeV2.
func QuantizeAndDequantizeV2NumBits ¶ added in v1.1.0
func QuantizeAndDequantizeV2NumBits(value int64) QuantizeAndDequantizeV2Attr
QuantizeAndDequantizeV2NumBits sets the optional num_bits attribute to value.
value: The bitwidth of the quantization. If not specified, defaults to 8
func QuantizeAndDequantizeV2RangeGiven ¶ added in v1.1.0
func QuantizeAndDequantizeV2RangeGiven(value bool) QuantizeAndDequantizeV2Attr
QuantizeAndDequantizeV2RangeGiven sets the optional range_given attribute to value.
value: If the range is given or should be computed from the tensor. If not specified, defaults to false
func QuantizeAndDequantizeV2SignedInput ¶ added in v1.1.0
func QuantizeAndDequantizeV2SignedInput(value bool) QuantizeAndDequantizeV2Attr
QuantizeAndDequantizeV2SignedInput sets the optional signed_input attribute to value.
value: If the quantization is signed or unsigned. If not specified, defaults to true
type QuantizeAndDequantizeV3Attr ¶ added in v1.3.0
type QuantizeAndDequantizeV3Attr func(optionalAttr)
QuantizeAndDequantizeV3Attr is an optional argument to QuantizeAndDequantizeV3.
func QuantizeAndDequantizeV3RangeGiven ¶ added in v1.3.0
func QuantizeAndDequantizeV3RangeGiven(value bool) QuantizeAndDequantizeV3Attr
QuantizeAndDequantizeV3RangeGiven sets the optional range_given attribute to value. If not specified, defaults to true
func QuantizeAndDequantizeV3SignedInput ¶ added in v1.3.0
func QuantizeAndDequantizeV3SignedInput(value bool) QuantizeAndDequantizeV3Attr
QuantizeAndDequantizeV3SignedInput sets the optional signed_input attribute to value. If not specified, defaults to true
type QuantizeV2Attr ¶ added in v1.1.0
type QuantizeV2Attr func(optionalAttr)
QuantizeV2Attr is an optional argument to QuantizeV2.
func QuantizeV2Mode ¶ added in v1.1.0
func QuantizeV2Mode(value string) QuantizeV2Attr
QuantizeV2Mode sets the optional mode attribute to value. If not specified, defaults to "MIN_COMBINED"
func QuantizeV2RoundMode ¶ added in v1.5.0
func QuantizeV2RoundMode(value string) QuantizeV2Attr
QuantizeV2RoundMode sets the optional round_mode attribute to value. If not specified, defaults to "HALF_AWAY_FROM_ZERO"
type QuantizedAddAttr ¶ added in v1.3.0
type QuantizedAddAttr func(optionalAttr)
QuantizedAddAttr is an optional argument to QuantizedAdd.
func QuantizedAddToutput ¶ added in v1.3.0
func QuantizedAddToutput(value tf.DataType) QuantizedAddAttr
QuantizedAddToutput sets the optional Toutput attribute to value. If not specified, defaults to DT_QINT32
type QuantizedConv2DAttr ¶ added in v1.1.0
type QuantizedConv2DAttr func(optionalAttr)
QuantizedConv2DAttr is an optional argument to QuantizedConv2D.
func QuantizedConv2DDilations ¶ added in v1.6.0
func QuantizedConv2DDilations(value []int64) QuantizedConv2DAttr
QuantizedConv2DDilations sets the optional dilations attribute to value.
value: 1-D tensor of length 4. The dilation factor for each dimension of `input`. If set to k > 1, there will be k-1 skipped cells between each filter element on that dimension. The dimension order is determined by the value of `data_format`, see above for details. Dilations in the batch and depth dimensions must be 1. If not specified, defaults to <i:1 i:1 i:1 i:1 >
func QuantizedConv2DOutType ¶ added in v1.1.0
func QuantizedConv2DOutType(value tf.DataType) QuantizedConv2DAttr
QuantizedConv2DOutType sets the optional out_type attribute to value. If not specified, defaults to DT_QINT32
type QuantizedInstanceNormAttr ¶ added in v1.1.0
type QuantizedInstanceNormAttr func(optionalAttr)
QuantizedInstanceNormAttr is an optional argument to QuantizedInstanceNorm.
func QuantizedInstanceNormGivenYMax ¶ added in v1.1.0
func QuantizedInstanceNormGivenYMax(value float32) QuantizedInstanceNormAttr
QuantizedInstanceNormGivenYMax sets the optional given_y_max attribute to value.
value: Output in `y_max` if `output_range_given` is True. If not specified, defaults to 0
func QuantizedInstanceNormGivenYMin ¶ added in v1.1.0
func QuantizedInstanceNormGivenYMin(value float32) QuantizedInstanceNormAttr
QuantizedInstanceNormGivenYMin sets the optional given_y_min attribute to value.
value: Output in `y_min` if `output_range_given` is True. If not specified, defaults to 0
func QuantizedInstanceNormMinSeparation ¶ added in v1.1.0
func QuantizedInstanceNormMinSeparation(value float32) QuantizedInstanceNormAttr
QuantizedInstanceNormMinSeparation sets the optional min_separation attribute to value.
value: Minimum value of `y_max - y_min` If not specified, defaults to 0.001
func QuantizedInstanceNormOutputRangeGiven ¶ added in v1.1.0
func QuantizedInstanceNormOutputRangeGiven(value bool) QuantizedInstanceNormAttr
QuantizedInstanceNormOutputRangeGiven sets the optional output_range_given attribute to value.
value: If True, `given_y_min` and `given_y_min` and `given_y_max` are used as the output range. Otherwise, the implementation computes the output range. If not specified, defaults to false
func QuantizedInstanceNormVarianceEpsilon ¶ added in v1.1.0
func QuantizedInstanceNormVarianceEpsilon(value float32) QuantizedInstanceNormAttr
QuantizedInstanceNormVarianceEpsilon sets the optional variance_epsilon attribute to value.
value: A small float number to avoid dividing by 0. If not specified, defaults to 1e-05
type QuantizedMatMulAttr ¶ added in v1.1.0
type QuantizedMatMulAttr func(optionalAttr)
QuantizedMatMulAttr is an optional argument to QuantizedMatMul.
func QuantizedMatMulTactivation ¶ added in v1.1.0
func QuantizedMatMulTactivation(value tf.DataType) QuantizedMatMulAttr
QuantizedMatMulTactivation sets the optional Tactivation attribute to value.
value: The type of output produced by activation function following this operation. If not specified, defaults to DT_QUINT8
func QuantizedMatMulToutput ¶ added in v1.1.0
func QuantizedMatMulToutput(value tf.DataType) QuantizedMatMulAttr
QuantizedMatMulToutput sets the optional Toutput attribute to value. If not specified, defaults to DT_QINT32
func QuantizedMatMulTransposeA ¶ added in v1.1.0
func QuantizedMatMulTransposeA(value bool) QuantizedMatMulAttr
QuantizedMatMulTransposeA sets the optional transpose_a attribute to value.
value: If true, `a` is transposed before multiplication. If not specified, defaults to false
func QuantizedMatMulTransposeB ¶ added in v1.1.0
func QuantizedMatMulTransposeB(value bool) QuantizedMatMulAttr
QuantizedMatMulTransposeB sets the optional transpose_b attribute to value.
value: If true, `b` is transposed before multiplication. If not specified, defaults to false
type QuantizedMulAttr ¶ added in v1.1.0
type QuantizedMulAttr func(optionalAttr)
QuantizedMulAttr is an optional argument to QuantizedMul.
func QuantizedMulToutput ¶ added in v1.1.0
func QuantizedMulToutput(value tf.DataType) QuantizedMulAttr
QuantizedMulToutput sets the optional Toutput attribute to value. If not specified, defaults to DT_QINT32
type QuantizedRelu6Attr ¶ added in v1.1.0
type QuantizedRelu6Attr func(optionalAttr)
QuantizedRelu6Attr is an optional argument to QuantizedRelu6.
func QuantizedRelu6OutType ¶ added in v1.1.0
func QuantizedRelu6OutType(value tf.DataType) QuantizedRelu6Attr
QuantizedRelu6OutType sets the optional out_type attribute to value. If not specified, defaults to DT_QUINT8
type QuantizedReluAttr ¶ added in v1.1.0
type QuantizedReluAttr func(optionalAttr)
QuantizedReluAttr is an optional argument to QuantizedRelu.
func QuantizedReluOutType ¶ added in v1.1.0
func QuantizedReluOutType(value tf.DataType) QuantizedReluAttr
QuantizedReluOutType sets the optional out_type attribute to value. If not specified, defaults to DT_QUINT8
type QuantizedReluXAttr ¶ added in v1.1.0
type QuantizedReluXAttr func(optionalAttr)
QuantizedReluXAttr is an optional argument to QuantizedReluX.
func QuantizedReluXOutType ¶ added in v1.1.0
func QuantizedReluXOutType(value tf.DataType) QuantizedReluXAttr
QuantizedReluXOutType sets the optional out_type attribute to value. If not specified, defaults to DT_QUINT8
type QuantizedResizeBilinearAttr ¶ added in v1.3.0
type QuantizedResizeBilinearAttr func(optionalAttr)
QuantizedResizeBilinearAttr is an optional argument to QuantizedResizeBilinear.
func QuantizedResizeBilinearAlignCorners ¶ added in v1.3.0
func QuantizedResizeBilinearAlignCorners(value bool) QuantizedResizeBilinearAttr
QuantizedResizeBilinearAlignCorners sets the optional align_corners attribute to value.
value: If true, rescale input by (new_height - 1) / (height - 1), which exactly aligns the 4 corners of images and resized images. If false, rescale by new_height / height. Treat similarly the width dimension. If not specified, defaults to false
type QueueCloseV2Attr ¶ added in v1.1.0
type QueueCloseV2Attr func(optionalAttr)
QueueCloseV2Attr is an optional argument to QueueCloseV2.
func QueueCloseV2CancelPendingEnqueues ¶ added in v1.1.0
func QueueCloseV2CancelPendingEnqueues(value bool) QueueCloseV2Attr
QueueCloseV2CancelPendingEnqueues sets the optional cancel_pending_enqueues attribute to value.
value: If true, all pending enqueue requests that are blocked on the given queue will be canceled. If not specified, defaults to false
type QueueDequeueManyV2Attr ¶ added in v1.1.0
type QueueDequeueManyV2Attr func(optionalAttr)
QueueDequeueManyV2Attr is an optional argument to QueueDequeueManyV2.
func QueueDequeueManyV2TimeoutMs ¶ added in v1.1.0
func QueueDequeueManyV2TimeoutMs(value int64) QueueDequeueManyV2Attr
QueueDequeueManyV2TimeoutMs sets the optional timeout_ms attribute to value.
value: If the queue has fewer than n elements, this operation will block for up to timeout_ms milliseconds. Note: This option is not supported yet. If not specified, defaults to -1
type QueueDequeueUpToV2Attr ¶ added in v1.1.0
type QueueDequeueUpToV2Attr func(optionalAttr)
QueueDequeueUpToV2Attr is an optional argument to QueueDequeueUpToV2.
func QueueDequeueUpToV2TimeoutMs ¶ added in v1.1.0
func QueueDequeueUpToV2TimeoutMs(value int64) QueueDequeueUpToV2Attr
QueueDequeueUpToV2TimeoutMs sets the optional timeout_ms attribute to value.
value: If the queue has fewer than n elements, this operation will block for up to timeout_ms milliseconds. Note: This option is not supported yet. If not specified, defaults to -1
type QueueDequeueV2Attr ¶ added in v1.1.0
type QueueDequeueV2Attr func(optionalAttr)
QueueDequeueV2Attr is an optional argument to QueueDequeueV2.
func QueueDequeueV2TimeoutMs ¶ added in v1.1.0
func QueueDequeueV2TimeoutMs(value int64) QueueDequeueV2Attr
QueueDequeueV2TimeoutMs sets the optional timeout_ms attribute to value.
value: If the queue is empty, this operation will block for up to timeout_ms milliseconds. Note: This option is not supported yet. If not specified, defaults to -1
type QueueEnqueueManyV2Attr ¶ added in v1.1.0
type QueueEnqueueManyV2Attr func(optionalAttr)
QueueEnqueueManyV2Attr is an optional argument to QueueEnqueueManyV2.
func QueueEnqueueManyV2TimeoutMs ¶ added in v1.1.0
func QueueEnqueueManyV2TimeoutMs(value int64) QueueEnqueueManyV2Attr
QueueEnqueueManyV2TimeoutMs sets the optional timeout_ms attribute to value.
value: If the queue is too full, this operation will block for up to timeout_ms milliseconds. Note: This option is not supported yet. If not specified, defaults to -1
type QueueEnqueueV2Attr ¶ added in v1.1.0
type QueueEnqueueV2Attr func(optionalAttr)
QueueEnqueueV2Attr is an optional argument to QueueEnqueueV2.
func QueueEnqueueV2TimeoutMs ¶ added in v1.1.0
func QueueEnqueueV2TimeoutMs(value int64) QueueEnqueueV2Attr
QueueEnqueueV2TimeoutMs sets the optional timeout_ms attribute to value.
value: If the queue is full, this operation will block for up to timeout_ms milliseconds. Note: This option is not supported yet. If not specified, defaults to -1
type RandomCropAttr ¶ added in v1.1.0
type RandomCropAttr func(optionalAttr)
RandomCropAttr is an optional argument to RandomCrop.
func RandomCropSeed ¶ added in v1.1.0
func RandomCropSeed(value int64) RandomCropAttr
RandomCropSeed sets the optional seed attribute to value.
value: If either seed or seed2 are set to be non-zero, the random number generator is seeded by the given seed. Otherwise, it is seeded by a random seed. If not specified, defaults to 0
func RandomCropSeed2 ¶ added in v1.1.0
func RandomCropSeed2(value int64) RandomCropAttr
RandomCropSeed2 sets the optional seed2 attribute to value.
value: An second seed to avoid seed collision. If not specified, defaults to 0
type RandomGammaAttr ¶ added in v1.1.0
type RandomGammaAttr func(optionalAttr)
RandomGammaAttr is an optional argument to RandomGamma.
func RandomGammaSeed ¶ added in v1.1.0
func RandomGammaSeed(value int64) RandomGammaAttr
RandomGammaSeed sets the optional seed attribute to value.
value: If either `seed` or `seed2` are set to be non-zero, the random number generator is seeded by the given seed. Otherwise, it is seeded by a random seed. If not specified, defaults to 0
func RandomGammaSeed2 ¶ added in v1.1.0
func RandomGammaSeed2(value int64) RandomGammaAttr
RandomGammaSeed2 sets the optional seed2 attribute to value.
value: A second seed to avoid seed collision. If not specified, defaults to 0
type RandomPoissonAttr ¶ added in v1.1.0
type RandomPoissonAttr func(optionalAttr)
RandomPoissonAttr is an optional argument to RandomPoisson.
func RandomPoissonSeed ¶ added in v1.1.0
func RandomPoissonSeed(value int64) RandomPoissonAttr
RandomPoissonSeed sets the optional seed attribute to value. If not specified, defaults to 0
func RandomPoissonSeed2 ¶ added in v1.1.0
func RandomPoissonSeed2(value int64) RandomPoissonAttr
RandomPoissonSeed2 sets the optional seed2 attribute to value. If not specified, defaults to 0
type RandomPoissonV2Attr ¶ added in v1.4.0
type RandomPoissonV2Attr func(optionalAttr)
RandomPoissonV2Attr is an optional argument to RandomPoissonV2.
func RandomPoissonV2Dtype ¶ added in v1.4.0
func RandomPoissonV2Dtype(value tf.DataType) RandomPoissonV2Attr
RandomPoissonV2Dtype sets the optional dtype attribute to value. If not specified, defaults to DT_INT64
func RandomPoissonV2Seed ¶ added in v1.4.0
func RandomPoissonV2Seed(value int64) RandomPoissonV2Attr
RandomPoissonV2Seed sets the optional seed attribute to value.
value: If either `seed` or `seed2` are set to be non-zero, the random number generator is seeded by the given seed. Otherwise, it is seeded by a random seed. If not specified, defaults to 0
func RandomPoissonV2Seed2 ¶ added in v1.4.0
func RandomPoissonV2Seed2(value int64) RandomPoissonV2Attr
RandomPoissonV2Seed2 sets the optional seed2 attribute to value.
value: A second seed to avoid seed collision. If not specified, defaults to 0
type RandomShuffleAttr ¶ added in v1.1.0
type RandomShuffleAttr func(optionalAttr)
RandomShuffleAttr is an optional argument to RandomShuffle.
func RandomShuffleSeed ¶ added in v1.1.0
func RandomShuffleSeed(value int64) RandomShuffleAttr
RandomShuffleSeed sets the optional seed attribute to value.
value: If either `seed` or `seed2` are set to be non-zero, the random number generator is seeded by the given seed. Otherwise, it is seeded by a random seed. If not specified, defaults to 0
func RandomShuffleSeed2 ¶ added in v1.1.0
func RandomShuffleSeed2(value int64) RandomShuffleAttr
RandomShuffleSeed2 sets the optional seed2 attribute to value.
value: A second seed to avoid seed collision. If not specified, defaults to 0
type RandomShuffleQueueV2Attr ¶ added in v1.1.0
type RandomShuffleQueueV2Attr func(optionalAttr)
RandomShuffleQueueV2Attr is an optional argument to RandomShuffleQueueV2.
func RandomShuffleQueueV2Capacity ¶ added in v1.1.0
func RandomShuffleQueueV2Capacity(value int64) RandomShuffleQueueV2Attr
RandomShuffleQueueV2Capacity sets the optional capacity attribute to value.
value: The upper bound on the number of elements in this queue. Negative numbers mean no limit. If not specified, defaults to -1
func RandomShuffleQueueV2Container ¶ added in v1.1.0
func RandomShuffleQueueV2Container(value string) RandomShuffleQueueV2Attr
RandomShuffleQueueV2Container sets the optional container attribute to value.
value: If non-empty, this queue is placed in the given container. Otherwise, a default container is used. If not specified, defaults to ""
func RandomShuffleQueueV2MinAfterDequeue ¶ added in v1.1.0
func RandomShuffleQueueV2MinAfterDequeue(value int64) RandomShuffleQueueV2Attr
RandomShuffleQueueV2MinAfterDequeue sets the optional min_after_dequeue attribute to value.
value: Dequeue will block unless there would be this many elements after the dequeue or the queue is closed. This ensures a minimum level of mixing of elements. If not specified, defaults to 0
func RandomShuffleQueueV2Seed ¶ added in v1.1.0
func RandomShuffleQueueV2Seed(value int64) RandomShuffleQueueV2Attr
RandomShuffleQueueV2Seed sets the optional seed attribute to value.
value: If either seed or seed2 is set to be non-zero, the random number generator is seeded by the given seed. Otherwise, a random seed is used. If not specified, defaults to 0
func RandomShuffleQueueV2Seed2 ¶ added in v1.1.0
func RandomShuffleQueueV2Seed2(value int64) RandomShuffleQueueV2Attr
RandomShuffleQueueV2Seed2 sets the optional seed2 attribute to value.
value: A second seed to avoid seed collision. If not specified, defaults to 0
func RandomShuffleQueueV2Shapes ¶ added in v1.1.0
func RandomShuffleQueueV2Shapes(value []tf.Shape) RandomShuffleQueueV2Attr
RandomShuffleQueueV2Shapes sets the optional shapes attribute to value.
value: The shape of each component in a value. The length of this attr must be either 0 or the same as the length of component_types. If the length of this attr is 0, the shapes of queue elements are not constrained, and only one element may be dequeued at a time. If not specified, defaults to <>
REQUIRES: len(value) >= 0
func RandomShuffleQueueV2SharedName ¶ added in v1.1.0
func RandomShuffleQueueV2SharedName(value string) RandomShuffleQueueV2Attr
RandomShuffleQueueV2SharedName sets the optional shared_name attribute to value.
value: If non-empty, this queue will be shared under the given name across multiple sessions. If not specified, defaults to ""
type RandomStandardNormalAttr ¶ added in v1.1.0
type RandomStandardNormalAttr func(optionalAttr)
RandomStandardNormalAttr is an optional argument to RandomStandardNormal.
func RandomStandardNormalSeed ¶ added in v1.1.0
func RandomStandardNormalSeed(value int64) RandomStandardNormalAttr
RandomStandardNormalSeed sets the optional seed attribute to value.
value: If either `seed` or `seed2` are set to be non-zero, the random number generator is seeded by the given seed. Otherwise, it is seeded by a random seed. If not specified, defaults to 0
func RandomStandardNormalSeed2 ¶ added in v1.1.0
func RandomStandardNormalSeed2(value int64) RandomStandardNormalAttr
RandomStandardNormalSeed2 sets the optional seed2 attribute to value.
value: A second seed to avoid seed collision. If not specified, defaults to 0
type RandomUniformAttr ¶ added in v1.1.0
type RandomUniformAttr func(optionalAttr)
RandomUniformAttr is an optional argument to RandomUniform.
func RandomUniformSeed ¶ added in v1.1.0
func RandomUniformSeed(value int64) RandomUniformAttr
RandomUniformSeed sets the optional seed attribute to value.
value: If either `seed` or `seed2` are set to be non-zero, the random number generator is seeded by the given seed. Otherwise, it is seeded by a random seed. If not specified, defaults to 0
func RandomUniformSeed2 ¶ added in v1.1.0
func RandomUniformSeed2(value int64) RandomUniformAttr
RandomUniformSeed2 sets the optional seed2 attribute to value.
value: A second seed to avoid seed collision. If not specified, defaults to 0
type RandomUniformIntAttr ¶ added in v1.1.0
type RandomUniformIntAttr func(optionalAttr)
RandomUniformIntAttr is an optional argument to RandomUniformInt.
func RandomUniformIntSeed ¶ added in v1.1.0
func RandomUniformIntSeed(value int64) RandomUniformIntAttr
RandomUniformIntSeed sets the optional seed attribute to value.
value: If either `seed` or `seed2` are set to be non-zero, the random number generator is seeded by the given seed. Otherwise, it is seeded by a random seed. If not specified, defaults to 0
func RandomUniformIntSeed2 ¶ added in v1.1.0
func RandomUniformIntSeed2(value int64) RandomUniformIntAttr
RandomUniformIntSeed2 sets the optional seed2 attribute to value.
value: A second seed to avoid seed collision. If not specified, defaults to 0
type RealAttr ¶ added in v1.1.0
type RealAttr func(optionalAttr)
RealAttr is an optional argument to Real.
type RecordInputAttr ¶ added in v1.1.0
type RecordInputAttr func(optionalAttr)
RecordInputAttr is an optional argument to RecordInput.
func RecordInputBatchSize ¶ added in v1.1.0
func RecordInputBatchSize(value int64) RecordInputAttr
RecordInputBatchSize sets the optional batch_size attribute to value.
value: The batch size. If not specified, defaults to 32
func RecordInputCompressionType ¶ added in v1.6.0
func RecordInputCompressionType(value string) RecordInputAttr
RecordInputCompressionType sets the optional compression_type attribute to value.
value: The type of compression for the file. Currently ZLIB and GZIP are supported. Defaults to none. If not specified, defaults to ""
func RecordInputFileBufferSize ¶ added in v1.1.0
func RecordInputFileBufferSize(value int64) RecordInputAttr
RecordInputFileBufferSize sets the optional file_buffer_size attribute to value.
value: The randomization shuffling buffer. If not specified, defaults to 10000
func RecordInputFileParallelism ¶ added in v1.1.0
func RecordInputFileParallelism(value int64) RecordInputAttr
RecordInputFileParallelism sets the optional file_parallelism attribute to value.
value: How many sstables are opened and concurrently iterated over. If not specified, defaults to 16
func RecordInputFileRandomSeed ¶ added in v1.1.0
func RecordInputFileRandomSeed(value int64) RecordInputAttr
RecordInputFileRandomSeed sets the optional file_random_seed attribute to value.
value: Random seeds used to produce randomized records. If not specified, defaults to 301
func RecordInputFileShuffleShiftRatio ¶ added in v1.1.0
func RecordInputFileShuffleShiftRatio(value float32) RecordInputAttr
RecordInputFileShuffleShiftRatio sets the optional file_shuffle_shift_ratio attribute to value.
value: Shifts the list of files after the list is randomly shuffled. If not specified, defaults to 0
type ReduceJoinAttr ¶ added in v1.1.0
type ReduceJoinAttr func(optionalAttr)
ReduceJoinAttr is an optional argument to ReduceJoin.
func ReduceJoinKeepDims ¶ added in v1.1.0
func ReduceJoinKeepDims(value bool) ReduceJoinAttr
ReduceJoinKeepDims sets the optional keep_dims attribute to value.
value: If `True`, retain reduced dimensions with length `1`. If not specified, defaults to false
func ReduceJoinSeparator ¶ added in v1.1.0
func ReduceJoinSeparator(value string) ReduceJoinAttr
ReduceJoinSeparator sets the optional separator attribute to value.
value: The separator to use when joining. If not specified, defaults to ""
type ResizeAreaAttr ¶ added in v1.1.0
type ResizeAreaAttr func(optionalAttr)
ResizeAreaAttr is an optional argument to ResizeArea.
func ResizeAreaAlignCorners ¶ added in v1.1.0
func ResizeAreaAlignCorners(value bool) ResizeAreaAttr
ResizeAreaAlignCorners sets the optional align_corners attribute to value.
value: If true, rescale input by (new_height - 1) / (height - 1), which exactly aligns the 4 corners of images and resized images. If false, rescale by new_height / height. Treat similarly the width dimension. If not specified, defaults to false
type ResizeBicubicAttr ¶ added in v1.1.0
type ResizeBicubicAttr func(optionalAttr)
ResizeBicubicAttr is an optional argument to ResizeBicubic.
func ResizeBicubicAlignCorners ¶ added in v1.1.0
func ResizeBicubicAlignCorners(value bool) ResizeBicubicAttr
ResizeBicubicAlignCorners sets the optional align_corners attribute to value.
value: If true, rescale input by (new_height - 1) / (height - 1), which exactly aligns the 4 corners of images and resized images. If false, rescale by new_height / height. Treat similarly the width dimension. If not specified, defaults to false
type ResizeBicubicGradAttr ¶ added in v1.4.0
type ResizeBicubicGradAttr func(optionalAttr)
ResizeBicubicGradAttr is an optional argument to ResizeBicubicGrad.
func ResizeBicubicGradAlignCorners ¶ added in v1.4.0
func ResizeBicubicGradAlignCorners(value bool) ResizeBicubicGradAttr
ResizeBicubicGradAlignCorners sets the optional align_corners attribute to value.
value: If true, rescale grads by (orig_height - 1) / (height - 1), which exactly aligns the 4 corners of grads and original_image. If false, rescale by orig_height / height. Treat similarly the width dimension. If not specified, defaults to false
type ResizeBilinearAttr ¶ added in v1.1.0
type ResizeBilinearAttr func(optionalAttr)
ResizeBilinearAttr is an optional argument to ResizeBilinear.
func ResizeBilinearAlignCorners ¶ added in v1.1.0
func ResizeBilinearAlignCorners(value bool) ResizeBilinearAttr
ResizeBilinearAlignCorners sets the optional align_corners attribute to value.
value: If true, rescale input by (new_height - 1) / (height - 1), which exactly aligns the 4 corners of images and resized images. If false, rescale by new_height / height. Treat similarly the width dimension. If not specified, defaults to false
type ResizeBilinearGradAttr ¶ added in v1.1.0
type ResizeBilinearGradAttr func(optionalAttr)
ResizeBilinearGradAttr is an optional argument to ResizeBilinearGrad.
func ResizeBilinearGradAlignCorners ¶ added in v1.1.0
func ResizeBilinearGradAlignCorners(value bool) ResizeBilinearGradAttr
ResizeBilinearGradAlignCorners sets the optional align_corners attribute to value.
value: If true, rescale grads by (orig_height - 1) / (height - 1), which exactly aligns the 4 corners of grads and original_image. If false, rescale by orig_height / height. Treat similarly the width dimension. If not specified, defaults to false
type ResizeNearestNeighborAttr ¶ added in v1.1.0
type ResizeNearestNeighborAttr func(optionalAttr)
ResizeNearestNeighborAttr is an optional argument to ResizeNearestNeighbor.
func ResizeNearestNeighborAlignCorners ¶ added in v1.1.0
func ResizeNearestNeighborAlignCorners(value bool) ResizeNearestNeighborAttr
ResizeNearestNeighborAlignCorners sets the optional align_corners attribute to value.
value: If true, rescale input by (new_height - 1) / (height - 1), which exactly aligns the 4 corners of images and resized images. If false, rescale by new_height / height. Treat similarly the width dimension. If not specified, defaults to false
type ResizeNearestNeighborGradAttr ¶ added in v1.1.0
type ResizeNearestNeighborGradAttr func(optionalAttr)
ResizeNearestNeighborGradAttr is an optional argument to ResizeNearestNeighborGrad.
func ResizeNearestNeighborGradAlignCorners ¶ added in v1.1.0
func ResizeNearestNeighborGradAlignCorners(value bool) ResizeNearestNeighborGradAttr
ResizeNearestNeighborGradAlignCorners sets the optional align_corners attribute to value.
value: If true, rescale grads by (orig_height - 1) / (height - 1), which exactly aligns the 4 corners of grads and original_image. If false, rescale by orig_height / height. Treat similarly the width dimension. If not specified, defaults to false
type ResourceApplyAdadeltaAttr ¶ added in v1.1.0
type ResourceApplyAdadeltaAttr func(optionalAttr)
ResourceApplyAdadeltaAttr is an optional argument to ResourceApplyAdadelta.
func ResourceApplyAdadeltaUseLocking ¶ added in v1.1.0
func ResourceApplyAdadeltaUseLocking(value bool) ResourceApplyAdadeltaAttr
ResourceApplyAdadeltaUseLocking sets the optional use_locking attribute to value.
value: If True, updating of the var, accum and update_accum tensors will be protected by a lock; otherwise the behavior is undefined, but may exhibit less contention. If not specified, defaults to false
type ResourceApplyAdagradAttr ¶ added in v1.1.0
type ResourceApplyAdagradAttr func(optionalAttr)
ResourceApplyAdagradAttr is an optional argument to ResourceApplyAdagrad.
func ResourceApplyAdagradUseLocking ¶ added in v1.1.0
func ResourceApplyAdagradUseLocking(value bool) ResourceApplyAdagradAttr
ResourceApplyAdagradUseLocking sets the optional use_locking attribute to value.
value: If `True`, updating of the var and accum tensors will be protected by a lock; otherwise the behavior is undefined, but may exhibit less contention. If not specified, defaults to false
type ResourceApplyAdagradDAAttr ¶ added in v1.1.0
type ResourceApplyAdagradDAAttr func(optionalAttr)
ResourceApplyAdagradDAAttr is an optional argument to ResourceApplyAdagradDA.
func ResourceApplyAdagradDAUseLocking ¶ added in v1.1.0
func ResourceApplyAdagradDAUseLocking(value bool) ResourceApplyAdagradDAAttr
ResourceApplyAdagradDAUseLocking sets the optional use_locking attribute to value.
value: If True, updating of the var and accum tensors will be protected by a lock; otherwise the behavior is undefined, but may exhibit less contention. If not specified, defaults to false
type ResourceApplyAdamAttr ¶ added in v1.1.0
type ResourceApplyAdamAttr func(optionalAttr)
ResourceApplyAdamAttr is an optional argument to ResourceApplyAdam.
func ResourceApplyAdamUseLocking ¶ added in v1.1.0
func ResourceApplyAdamUseLocking(value bool) ResourceApplyAdamAttr
ResourceApplyAdamUseLocking sets the optional use_locking attribute to value.
value: If `True`, updating of the var, m, and v tensors will be protected by a lock; otherwise the behavior is undefined, but may exhibit less contention. If not specified, defaults to false
func ResourceApplyAdamUseNesterov ¶ added in v1.3.0
func ResourceApplyAdamUseNesterov(value bool) ResourceApplyAdamAttr
ResourceApplyAdamUseNesterov sets the optional use_nesterov attribute to value.
value: If `True`, uses the nesterov update. If not specified, defaults to false
type ResourceApplyAddSignAttr ¶ added in v1.5.0
type ResourceApplyAddSignAttr func(optionalAttr)
ResourceApplyAddSignAttr is an optional argument to ResourceApplyAddSign.
func ResourceApplyAddSignUseLocking ¶ added in v1.5.0
func ResourceApplyAddSignUseLocking(value bool) ResourceApplyAddSignAttr
ResourceApplyAddSignUseLocking sets the optional use_locking attribute to value.
value: If `True`, updating of the var and m tensors is protected by a lock; otherwise the behavior is undefined, but may exhibit less contention. If not specified, defaults to false
type ResourceApplyCenteredRMSPropAttr ¶ added in v1.1.0
type ResourceApplyCenteredRMSPropAttr func(optionalAttr)
ResourceApplyCenteredRMSPropAttr is an optional argument to ResourceApplyCenteredRMSProp.
func ResourceApplyCenteredRMSPropUseLocking ¶ added in v1.1.0
func ResourceApplyCenteredRMSPropUseLocking(value bool) ResourceApplyCenteredRMSPropAttr
ResourceApplyCenteredRMSPropUseLocking sets the optional use_locking attribute to value.
value: If `True`, updating of the var, mg, ms, and mom tensors is protected by a lock; otherwise the behavior is undefined, but may exhibit less contention. If not specified, defaults to false
type ResourceApplyFtrlAttr ¶ added in v1.1.0
type ResourceApplyFtrlAttr func(optionalAttr)
ResourceApplyFtrlAttr is an optional argument to ResourceApplyFtrl.
func ResourceApplyFtrlUseLocking ¶ added in v1.1.0
func ResourceApplyFtrlUseLocking(value bool) ResourceApplyFtrlAttr
ResourceApplyFtrlUseLocking sets the optional use_locking attribute to value.
value: If `True`, updating of the var and accum tensors will be protected by a lock; otherwise the behavior is undefined, but may exhibit less contention. If not specified, defaults to false
type ResourceApplyFtrlV2Attr ¶ added in v1.3.0
type ResourceApplyFtrlV2Attr func(optionalAttr)
ResourceApplyFtrlV2Attr is an optional argument to ResourceApplyFtrlV2.
func ResourceApplyFtrlV2UseLocking ¶ added in v1.3.0
func ResourceApplyFtrlV2UseLocking(value bool) ResourceApplyFtrlV2Attr
ResourceApplyFtrlV2UseLocking sets the optional use_locking attribute to value.
value: If `True`, updating of the var and accum tensors will be protected by a lock; otherwise the behavior is undefined, but may exhibit less contention. If not specified, defaults to false
type ResourceApplyGradientDescentAttr ¶ added in v1.1.0
type ResourceApplyGradientDescentAttr func(optionalAttr)
ResourceApplyGradientDescentAttr is an optional argument to ResourceApplyGradientDescent.
func ResourceApplyGradientDescentUseLocking ¶ added in v1.1.0
func ResourceApplyGradientDescentUseLocking(value bool) ResourceApplyGradientDescentAttr
ResourceApplyGradientDescentUseLocking sets the optional use_locking attribute to value.
value: If `True`, the subtraction will be protected by a lock; otherwise the behavior is undefined, but may exhibit less contention. If not specified, defaults to false
type ResourceApplyMomentumAttr ¶ added in v1.1.0
type ResourceApplyMomentumAttr func(optionalAttr)
ResourceApplyMomentumAttr is an optional argument to ResourceApplyMomentum.
func ResourceApplyMomentumUseLocking ¶ added in v1.1.0
func ResourceApplyMomentumUseLocking(value bool) ResourceApplyMomentumAttr
ResourceApplyMomentumUseLocking sets the optional use_locking attribute to value.
value: If `True`, updating of the var and accum tensors will be protected by a lock; otherwise the behavior is undefined, but may exhibit less contention. If not specified, defaults to false
func ResourceApplyMomentumUseNesterov ¶ added in v1.1.0
func ResourceApplyMomentumUseNesterov(value bool) ResourceApplyMomentumAttr
ResourceApplyMomentumUseNesterov sets the optional use_nesterov attribute to value.
value: If `True`, the tensor passed to compute grad will be var - lr * momentum * accum, so in the end, the var you get is actually var - lr * momentum * accum. If not specified, defaults to false
type ResourceApplyPowerSignAttr ¶ added in v1.5.0
type ResourceApplyPowerSignAttr func(optionalAttr)
ResourceApplyPowerSignAttr is an optional argument to ResourceApplyPowerSign.
func ResourceApplyPowerSignUseLocking ¶ added in v1.5.0
func ResourceApplyPowerSignUseLocking(value bool) ResourceApplyPowerSignAttr
ResourceApplyPowerSignUseLocking sets the optional use_locking attribute to value.
value: If `True`, updating of the var and m tensors is protected by a lock; otherwise the behavior is undefined, but may exhibit less contention. If not specified, defaults to false
type ResourceApplyProximalAdagradAttr ¶ added in v1.1.0
type ResourceApplyProximalAdagradAttr func(optionalAttr)
ResourceApplyProximalAdagradAttr is an optional argument to ResourceApplyProximalAdagrad.
func ResourceApplyProximalAdagradUseLocking ¶ added in v1.1.0
func ResourceApplyProximalAdagradUseLocking(value bool) ResourceApplyProximalAdagradAttr
ResourceApplyProximalAdagradUseLocking sets the optional use_locking attribute to value.
value: If True, updating of the var and accum tensors will be protected by a lock; otherwise the behavior is undefined, but may exhibit less contention. If not specified, defaults to false
type ResourceApplyProximalGradientDescentAttr ¶ added in v1.1.0
type ResourceApplyProximalGradientDescentAttr func(optionalAttr)
ResourceApplyProximalGradientDescentAttr is an optional argument to ResourceApplyProximalGradientDescent.
func ResourceApplyProximalGradientDescentUseLocking ¶ added in v1.1.0
func ResourceApplyProximalGradientDescentUseLocking(value bool) ResourceApplyProximalGradientDescentAttr
ResourceApplyProximalGradientDescentUseLocking sets the optional use_locking attribute to value.
value: If True, the subtraction will be protected by a lock; otherwise the behavior is undefined, but may exhibit less contention. If not specified, defaults to false
type ResourceApplyRMSPropAttr ¶ added in v1.1.0
type ResourceApplyRMSPropAttr func(optionalAttr)
ResourceApplyRMSPropAttr is an optional argument to ResourceApplyRMSProp.
func ResourceApplyRMSPropUseLocking ¶ added in v1.1.0
func ResourceApplyRMSPropUseLocking(value bool) ResourceApplyRMSPropAttr
ResourceApplyRMSPropUseLocking sets the optional use_locking attribute to value.
value: If `True`, updating of the var, ms, and mom tensors is protected by a lock; otherwise the behavior is undefined, but may exhibit less contention. If not specified, defaults to false
type ResourceGatherAttr ¶ added in v1.1.0
type ResourceGatherAttr func(optionalAttr)
ResourceGatherAttr is an optional argument to ResourceGather.
func ResourceGatherValidateIndices ¶ added in v1.1.0
func ResourceGatherValidateIndices(value bool) ResourceGatherAttr
ResourceGatherValidateIndices sets the optional validate_indices attribute to value. If not specified, defaults to true
type ResourceScatterNdUpdateAttr ¶ added in v1.6.0
type ResourceScatterNdUpdateAttr func(optionalAttr)
ResourceScatterNdUpdateAttr is an optional argument to ResourceScatterNdUpdate.
func ResourceScatterNdUpdateUseLocking ¶ added in v1.6.0
func ResourceScatterNdUpdateUseLocking(value bool) ResourceScatterNdUpdateAttr
ResourceScatterNdUpdateUseLocking sets the optional use_locking attribute to value.
value: An optional bool. Defaults to True. If True, the assignment will be protected by a lock; otherwise the behavior is undefined, but may exhibit less contention. If not specified, defaults to true
type ResourceSparseApplyAdadeltaAttr ¶ added in v1.1.0
type ResourceSparseApplyAdadeltaAttr func(optionalAttr)
ResourceSparseApplyAdadeltaAttr is an optional argument to ResourceSparseApplyAdadelta.
func ResourceSparseApplyAdadeltaUseLocking ¶ added in v1.1.0
func ResourceSparseApplyAdadeltaUseLocking(value bool) ResourceSparseApplyAdadeltaAttr
ResourceSparseApplyAdadeltaUseLocking sets the optional use_locking attribute to value.
value: If True, updating of the var and accum tensors will be protected by a lock; otherwise the behavior is undefined, but may exhibit less contention. If not specified, defaults to false
type ResourceSparseApplyAdagradAttr ¶ added in v1.1.0
type ResourceSparseApplyAdagradAttr func(optionalAttr)
ResourceSparseApplyAdagradAttr is an optional argument to ResourceSparseApplyAdagrad.
func ResourceSparseApplyAdagradUseLocking ¶ added in v1.1.0
func ResourceSparseApplyAdagradUseLocking(value bool) ResourceSparseApplyAdagradAttr
ResourceSparseApplyAdagradUseLocking sets the optional use_locking attribute to value.
value: If `True`, updating of the var and accum tensors will be protected by a lock; otherwise the behavior is undefined, but may exhibit less contention. If not specified, defaults to false
type ResourceSparseApplyAdagradDAAttr ¶ added in v1.1.0
type ResourceSparseApplyAdagradDAAttr func(optionalAttr)
ResourceSparseApplyAdagradDAAttr is an optional argument to ResourceSparseApplyAdagradDA.
func ResourceSparseApplyAdagradDAUseLocking ¶ added in v1.1.0
func ResourceSparseApplyAdagradDAUseLocking(value bool) ResourceSparseApplyAdagradDAAttr
ResourceSparseApplyAdagradDAUseLocking sets the optional use_locking attribute to value.
value: If True, updating of the var and accum tensors will be protected by a lock; otherwise the behavior is undefined, but may exhibit less contention. If not specified, defaults to false
type ResourceSparseApplyCenteredRMSPropAttr ¶ added in v1.1.0
type ResourceSparseApplyCenteredRMSPropAttr func(optionalAttr)
ResourceSparseApplyCenteredRMSPropAttr is an optional argument to ResourceSparseApplyCenteredRMSProp.
func ResourceSparseApplyCenteredRMSPropUseLocking ¶ added in v1.1.0
func ResourceSparseApplyCenteredRMSPropUseLocking(value bool) ResourceSparseApplyCenteredRMSPropAttr
ResourceSparseApplyCenteredRMSPropUseLocking sets the optional use_locking attribute to value.
value: If `True`, updating of the var, mg, ms, and mom tensors is protected by a lock; otherwise the behavior is undefined, but may exhibit less contention. If not specified, defaults to false
type ResourceSparseApplyFtrlAttr ¶ added in v1.1.0
type ResourceSparseApplyFtrlAttr func(optionalAttr)
ResourceSparseApplyFtrlAttr is an optional argument to ResourceSparseApplyFtrl.
func ResourceSparseApplyFtrlUseLocking ¶ added in v1.1.0
func ResourceSparseApplyFtrlUseLocking(value bool) ResourceSparseApplyFtrlAttr
ResourceSparseApplyFtrlUseLocking sets the optional use_locking attribute to value.
value: If `True`, updating of the var and accum tensors will be protected by a lock; otherwise the behavior is undefined, but may exhibit less contention. If not specified, defaults to false
type ResourceSparseApplyFtrlV2Attr ¶ added in v1.3.0
type ResourceSparseApplyFtrlV2Attr func(optionalAttr)
ResourceSparseApplyFtrlV2Attr is an optional argument to ResourceSparseApplyFtrlV2.
func ResourceSparseApplyFtrlV2UseLocking ¶ added in v1.3.0
func ResourceSparseApplyFtrlV2UseLocking(value bool) ResourceSparseApplyFtrlV2Attr
ResourceSparseApplyFtrlV2UseLocking sets the optional use_locking attribute to value.
value: If `True`, updating of the var and accum tensors will be protected by a lock; otherwise the behavior is undefined, but may exhibit less contention. If not specified, defaults to false
type ResourceSparseApplyMomentumAttr ¶ added in v1.1.0
type ResourceSparseApplyMomentumAttr func(optionalAttr)
ResourceSparseApplyMomentumAttr is an optional argument to ResourceSparseApplyMomentum.
func ResourceSparseApplyMomentumUseLocking ¶ added in v1.1.0
func ResourceSparseApplyMomentumUseLocking(value bool) ResourceSparseApplyMomentumAttr
ResourceSparseApplyMomentumUseLocking sets the optional use_locking attribute to value.
value: If `True`, updating of the var and accum tensors will be protected by a lock; otherwise the behavior is undefined, but may exhibit less contention. If not specified, defaults to false
func ResourceSparseApplyMomentumUseNesterov ¶ added in v1.1.0
func ResourceSparseApplyMomentumUseNesterov(value bool) ResourceSparseApplyMomentumAttr
ResourceSparseApplyMomentumUseNesterov sets the optional use_nesterov attribute to value.
value: If `True`, the tensor passed to compute grad will be var - lr * momentum * accum, so in the end, the var you get is actually var - lr * momentum * accum. If not specified, defaults to false
type ResourceSparseApplyProximalAdagradAttr ¶ added in v1.1.0
type ResourceSparseApplyProximalAdagradAttr func(optionalAttr)
ResourceSparseApplyProximalAdagradAttr is an optional argument to ResourceSparseApplyProximalAdagrad.
func ResourceSparseApplyProximalAdagradUseLocking ¶ added in v1.1.0
func ResourceSparseApplyProximalAdagradUseLocking(value bool) ResourceSparseApplyProximalAdagradAttr
ResourceSparseApplyProximalAdagradUseLocking sets the optional use_locking attribute to value.
value: If True, updating of the var and accum tensors will be protected by a lock; otherwise the behavior is undefined, but may exhibit less contention. If not specified, defaults to false
type ResourceSparseApplyProximalGradientDescentAttr ¶ added in v1.1.0
type ResourceSparseApplyProximalGradientDescentAttr func(optionalAttr)
ResourceSparseApplyProximalGradientDescentAttr is an optional argument to ResourceSparseApplyProximalGradientDescent.
func ResourceSparseApplyProximalGradientDescentUseLocking ¶ added in v1.1.0
func ResourceSparseApplyProximalGradientDescentUseLocking(value bool) ResourceSparseApplyProximalGradientDescentAttr
ResourceSparseApplyProximalGradientDescentUseLocking sets the optional use_locking attribute to value.
value: If True, the subtraction will be protected by a lock; otherwise the behavior is undefined, but may exhibit less contention. If not specified, defaults to false
type ResourceSparseApplyRMSPropAttr ¶ added in v1.1.0
type ResourceSparseApplyRMSPropAttr func(optionalAttr)
ResourceSparseApplyRMSPropAttr is an optional argument to ResourceSparseApplyRMSProp.
func ResourceSparseApplyRMSPropUseLocking ¶ added in v1.1.0
func ResourceSparseApplyRMSPropUseLocking(value bool) ResourceSparseApplyRMSPropAttr
ResourceSparseApplyRMSPropUseLocking sets the optional use_locking attribute to value.
value: If `True`, updating of the var, ms, and mom tensors is protected by a lock; otherwise the behavior is undefined, but may exhibit less contention. If not specified, defaults to false
type ResourceStridedSliceAssignAttr ¶ added in v1.2.0
type ResourceStridedSliceAssignAttr func(optionalAttr)
ResourceStridedSliceAssignAttr is an optional argument to ResourceStridedSliceAssign.
func ResourceStridedSliceAssignBeginMask ¶ added in v1.2.0
func ResourceStridedSliceAssignBeginMask(value int64) ResourceStridedSliceAssignAttr
ResourceStridedSliceAssignBeginMask sets the optional begin_mask attribute to value. If not specified, defaults to 0
func ResourceStridedSliceAssignEllipsisMask ¶ added in v1.2.0
func ResourceStridedSliceAssignEllipsisMask(value int64) ResourceStridedSliceAssignAttr
ResourceStridedSliceAssignEllipsisMask sets the optional ellipsis_mask attribute to value. If not specified, defaults to 0
func ResourceStridedSliceAssignEndMask ¶ added in v1.2.0
func ResourceStridedSliceAssignEndMask(value int64) ResourceStridedSliceAssignAttr
ResourceStridedSliceAssignEndMask sets the optional end_mask attribute to value. If not specified, defaults to 0
func ResourceStridedSliceAssignNewAxisMask ¶ added in v1.2.0
func ResourceStridedSliceAssignNewAxisMask(value int64) ResourceStridedSliceAssignAttr
ResourceStridedSliceAssignNewAxisMask sets the optional new_axis_mask attribute to value. If not specified, defaults to 0
func ResourceStridedSliceAssignShrinkAxisMask ¶ added in v1.2.0
func ResourceStridedSliceAssignShrinkAxisMask(value int64) ResourceStridedSliceAssignAttr
ResourceStridedSliceAssignShrinkAxisMask sets the optional shrink_axis_mask attribute to value. If not specified, defaults to 0
type RestoreAttr ¶ added in v1.1.0
type RestoreAttr func(optionalAttr)
RestoreAttr is an optional argument to Restore.
func RestorePreferredShard ¶ added in v1.1.0
func RestorePreferredShard(value int64) RestoreAttr
RestorePreferredShard sets the optional preferred_shard attribute to value.
value: Index of file to open first if multiple files match `file_pattern`. If not specified, defaults to -1
type RestoreSliceAttr ¶ added in v1.1.0
type RestoreSliceAttr func(optionalAttr)
RestoreSliceAttr is an optional argument to RestoreSlice.
func RestoreSlicePreferredShard ¶ added in v1.1.0
func RestoreSlicePreferredShard(value int64) RestoreSliceAttr
RestoreSlicePreferredShard sets the optional preferred_shard attribute to value.
value: Index of file to open first if multiple files match `file_pattern`. See the documentation for `Restore`. If not specified, defaults to -1
type ReverseSequenceAttr ¶ added in v1.1.0
type ReverseSequenceAttr func(optionalAttr)
ReverseSequenceAttr is an optional argument to ReverseSequence.
func ReverseSequenceBatchDim ¶ added in v1.1.0
func ReverseSequenceBatchDim(value int64) ReverseSequenceAttr
ReverseSequenceBatchDim sets the optional batch_dim attribute to value.
value: The dimension along which reversal is performed. If not specified, defaults to 0
type SampleDistortedBoundingBoxAttr ¶ added in v1.1.0
type SampleDistortedBoundingBoxAttr func(optionalAttr)
SampleDistortedBoundingBoxAttr is an optional argument to SampleDistortedBoundingBox.
func SampleDistortedBoundingBoxAreaRange ¶ added in v1.1.0
func SampleDistortedBoundingBoxAreaRange(value []float32) SampleDistortedBoundingBoxAttr
SampleDistortedBoundingBoxAreaRange sets the optional area_range attribute to value.
value: The cropped area of the image must contain a fraction of the supplied image within in this range. If not specified, defaults to <f:0.05 f:1 >
func SampleDistortedBoundingBoxAspectRatioRange ¶ added in v1.1.0
func SampleDistortedBoundingBoxAspectRatioRange(value []float32) SampleDistortedBoundingBoxAttr
SampleDistortedBoundingBoxAspectRatioRange sets the optional aspect_ratio_range attribute to value.
value: The cropped area of the image must have an aspect ratio = width / height within this range. If not specified, defaults to <f:0.75 f:1.33 >
func SampleDistortedBoundingBoxMaxAttempts ¶ added in v1.1.0
func SampleDistortedBoundingBoxMaxAttempts(value int64) SampleDistortedBoundingBoxAttr
SampleDistortedBoundingBoxMaxAttempts sets the optional max_attempts attribute to value.
value: Number of attempts at generating a cropped region of the image of the specified constraints. After `max_attempts` failures, return the entire image. If not specified, defaults to 100
func SampleDistortedBoundingBoxMinObjectCovered ¶ added in v1.1.0
func SampleDistortedBoundingBoxMinObjectCovered(value float32) SampleDistortedBoundingBoxAttr
SampleDistortedBoundingBoxMinObjectCovered sets the optional min_object_covered attribute to value.
value: The cropped area of the image must contain at least this fraction of any bounding box supplied. The value of this parameter should be non-negative. In the case of 0, the cropped area does not need to overlap any of the bounding boxes supplied. If not specified, defaults to 0.1
func SampleDistortedBoundingBoxSeed ¶ added in v1.1.0
func SampleDistortedBoundingBoxSeed(value int64) SampleDistortedBoundingBoxAttr
SampleDistortedBoundingBoxSeed sets the optional seed attribute to value.
value: If either `seed` or `seed2` are set to non-zero, the random number generator is seeded by the given `seed`. Otherwise, it is seeded by a random seed. If not specified, defaults to 0
func SampleDistortedBoundingBoxSeed2 ¶ added in v1.1.0
func SampleDistortedBoundingBoxSeed2(value int64) SampleDistortedBoundingBoxAttr
SampleDistortedBoundingBoxSeed2 sets the optional seed2 attribute to value.
value: A second seed to avoid seed collision. If not specified, defaults to 0
func SampleDistortedBoundingBoxUseImageIfNoBoundingBoxes ¶ added in v1.1.0
func SampleDistortedBoundingBoxUseImageIfNoBoundingBoxes(value bool) SampleDistortedBoundingBoxAttr
SampleDistortedBoundingBoxUseImageIfNoBoundingBoxes sets the optional use_image_if_no_bounding_boxes attribute to value.
value: Controls behavior if no bounding boxes supplied. If true, assume an implicit bounding box covering the whole input. If false, raise an error. If not specified, defaults to false
type SampleDistortedBoundingBoxV2Attr ¶ added in v1.3.0
type SampleDistortedBoundingBoxV2Attr func(optionalAttr)
SampleDistortedBoundingBoxV2Attr is an optional argument to SampleDistortedBoundingBoxV2.
func SampleDistortedBoundingBoxV2AreaRange ¶ added in v1.3.0
func SampleDistortedBoundingBoxV2AreaRange(value []float32) SampleDistortedBoundingBoxV2Attr
SampleDistortedBoundingBoxV2AreaRange sets the optional area_range attribute to value.
value: The cropped area of the image must contain a fraction of the supplied image within in this range. If not specified, defaults to <f:0.05 f:1 >
func SampleDistortedBoundingBoxV2AspectRatioRange ¶ added in v1.3.0
func SampleDistortedBoundingBoxV2AspectRatioRange(value []float32) SampleDistortedBoundingBoxV2Attr
SampleDistortedBoundingBoxV2AspectRatioRange sets the optional aspect_ratio_range attribute to value.
value: The cropped area of the image must have an aspect ratio = width / height within this range. If not specified, defaults to <f:0.75 f:1.33 >
func SampleDistortedBoundingBoxV2MaxAttempts ¶ added in v1.3.0
func SampleDistortedBoundingBoxV2MaxAttempts(value int64) SampleDistortedBoundingBoxV2Attr
SampleDistortedBoundingBoxV2MaxAttempts sets the optional max_attempts attribute to value.
value: Number of attempts at generating a cropped region of the image of the specified constraints. After `max_attempts` failures, return the entire image. If not specified, defaults to 100
func SampleDistortedBoundingBoxV2Seed ¶ added in v1.3.0
func SampleDistortedBoundingBoxV2Seed(value int64) SampleDistortedBoundingBoxV2Attr
SampleDistortedBoundingBoxV2Seed sets the optional seed attribute to value.
value: If either `seed` or `seed2` are set to non-zero, the random number generator is seeded by the given `seed`. Otherwise, it is seeded by a random seed. If not specified, defaults to 0
func SampleDistortedBoundingBoxV2Seed2 ¶ added in v1.3.0
func SampleDistortedBoundingBoxV2Seed2(value int64) SampleDistortedBoundingBoxV2Attr
SampleDistortedBoundingBoxV2Seed2 sets the optional seed2 attribute to value.
value: A second seed to avoid seed collision. If not specified, defaults to 0
func SampleDistortedBoundingBoxV2UseImageIfNoBoundingBoxes ¶ added in v1.3.0
func SampleDistortedBoundingBoxV2UseImageIfNoBoundingBoxes(value bool) SampleDistortedBoundingBoxV2Attr
SampleDistortedBoundingBoxV2UseImageIfNoBoundingBoxes sets the optional use_image_if_no_bounding_boxes attribute to value.
value: Controls behavior if no bounding boxes supplied. If true, assume an implicit bounding box covering the whole input. If false, raise an error. If not specified, defaults to false
type Scope ¶
type Scope struct {
// contains filtered or unexported fields
}
Scope encapsulates common operation properties when building a Graph.
A Scope object (and its derivates, e.g., obtained from Scope.SubScope) act as a builder for graphs. They allow common properties (such as a name prefix) to be specified for multiple operations being added to the graph.
A Scope object and all its derivates (e.g., obtained from Scope.SubScope) are not safe for concurrent use by multiple goroutines.
func NewScopeWithGraph ¶ added in v1.3.0
NewScopeWithGraph creates a Scope initialized with the Graph thats passed in
func (*Scope) AddOperation ¶
AddOperation adds the operation to the Graph managed by s.
If there is a name prefix associated with s (such as if s was created by a call to SubScope), then this prefix will be applied to the name of the operation being added. See also Graph.AddOperation.
func (*Scope) Err ¶
Err returns the error, if any, encountered during the construction of the Graph managed by s.
Once Err returns a non-nil error, all future calls will do the same, indicating that the scope should be discarded as the graph could not be constructed.
func (*Scope) Finalize ¶
Finalize returns the Graph on which this scope operates on and renders s unusable. If there was an error during graph construction, that error is returned instead.
func (*Scope) SubScope ¶
SubScope returns a new Scope which will cause all operations added to the graph to be namespaced with 'namespace'. If namespace collides with an existing namespace within the scope, then a suffix will be added.
Example ¶
var (
s = NewScope()
c1 = Const(s.SubScope("x"), int64(1))
c2 = Const(s.SubScope("x"), int64(1))
)
if s.Err() != nil {
panic(s.Err())
}
fmt.Println(c1.Op.Name(), c2.Op.Name())
Output: x/Const x_1/Const
func (*Scope) UpdateErr ¶
UpdateErr is used to notify Scope of any graph construction errors while creating the operation op.
func (*Scope) WithControlDependencies ¶ added in v1.6.0
WithControlDependencies returns a new Scope which will cause all operations added to the graph to execute only after all the provided operations have executed first (in addition to any other control dependencies in s).
type SdcaOptimizerAttr ¶ added in v1.1.0
type SdcaOptimizerAttr func(optionalAttr)
SdcaOptimizerAttr is an optional argument to SdcaOptimizer.
func SdcaOptimizerAdaptative ¶ added in v1.1.0
func SdcaOptimizerAdaptative(value bool) SdcaOptimizerAttr
SdcaOptimizerAdaptative sets the optional adaptative attribute to value.
value: Whether to use Adapative SDCA for the inner loop. If not specified, defaults to false
type SelfAdjointEigV2Attr ¶ added in v1.1.0
type SelfAdjointEigV2Attr func(optionalAttr)
SelfAdjointEigV2Attr is an optional argument to SelfAdjointEigV2.
func SelfAdjointEigV2ComputeV ¶ added in v1.1.0
func SelfAdjointEigV2ComputeV(value bool) SelfAdjointEigV2Attr
SelfAdjointEigV2ComputeV sets the optional compute_v attribute to value.
value: If `True` then eigenvectors will be computed and returned in `v`. Otherwise, only the eigenvalues will be computed. If not specified, defaults to true
type SerializeManySparseAttr ¶ added in v1.6.0
type SerializeManySparseAttr func(optionalAttr)
SerializeManySparseAttr is an optional argument to SerializeManySparse.
func SerializeManySparseOutType ¶ added in v1.6.0
func SerializeManySparseOutType(value tf.DataType) SerializeManySparseAttr
SerializeManySparseOutType sets the optional out_type attribute to value.
value: The `dtype` to use for serialization; the supported types are `string` (default) and `variant`. If not specified, defaults to DT_STRING
type SerializeSparseAttr ¶ added in v1.6.0
type SerializeSparseAttr func(optionalAttr)
SerializeSparseAttr is an optional argument to SerializeSparse.
func SerializeSparseOutType ¶ added in v1.6.0
func SerializeSparseOutType(value tf.DataType) SerializeSparseAttr
SerializeSparseOutType sets the optional out_type attribute to value.
value: The `dtype` to use for serialization; the supported types are `string` (default) and `variant`. If not specified, defaults to DT_STRING
type SetSizeAttr ¶ added in v1.1.0
type SetSizeAttr func(optionalAttr)
SetSizeAttr is an optional argument to SetSize.
func SetSizeValidateIndices ¶ added in v1.1.0
func SetSizeValidateIndices(value bool) SetSizeAttr
SetSizeValidateIndices sets the optional validate_indices attribute to value. If not specified, defaults to true
type ShapeAttr ¶ added in v1.1.0
type ShapeAttr func(optionalAttr)
ShapeAttr is an optional argument to Shape.
func ShapeOutType ¶ added in v1.1.0
ShapeOutType sets the optional out_type attribute to value. If not specified, defaults to DT_INT32
type ShapeNAttr ¶ added in v1.1.0
type ShapeNAttr func(optionalAttr)
ShapeNAttr is an optional argument to ShapeN.
func ShapeNOutType ¶ added in v1.1.0
func ShapeNOutType(value tf.DataType) ShapeNAttr
ShapeNOutType sets the optional out_type attribute to value. If not specified, defaults to DT_INT32
type ShuffleDatasetAttr ¶ added in v1.4.0
type ShuffleDatasetAttr func(optionalAttr)
ShuffleDatasetAttr is an optional argument to ShuffleDataset.
func ShuffleDatasetReshuffleEachIteration ¶ added in v1.4.0
func ShuffleDatasetReshuffleEachIteration(value bool) ShuffleDatasetAttr
ShuffleDatasetReshuffleEachIteration sets the optional reshuffle_each_iteration attribute to value.
value: If true, each iterator over this dataset will be given a different pseudorandomly generated seed, based on a sequence seeded by the `seed` and `seed2` inputs. If false, each iterator will be given the same seed, and repeated iteration over this dataset will yield the exact same sequence of results. If not specified, defaults to true
type SizeAttr ¶ added in v1.1.0
type SizeAttr func(optionalAttr)
SizeAttr is an optional argument to Size.
func SizeOutType ¶ added in v1.1.0
SizeOutType sets the optional out_type attribute to value. If not specified, defaults to DT_INT32
type SkipgramAttr ¶ added in v1.1.0
type SkipgramAttr func(optionalAttr)
SkipgramAttr is an optional argument to Skipgram.
func SkipgramMinCount ¶ added in v1.1.0
func SkipgramMinCount(value int64) SkipgramAttr
SkipgramMinCount sets the optional min_count attribute to value.
value: The minimum number of word occurrences for it to be included in the vocabulary. If not specified, defaults to 5
func SkipgramSubsample ¶ added in v1.1.0
func SkipgramSubsample(value float32) SkipgramAttr
SkipgramSubsample sets the optional subsample attribute to value.
value: Threshold for word occurrence. Words that appear with higher frequency will be randomly down-sampled. Set to 0 to disable. If not specified, defaults to 0.001
func SkipgramWindowSize ¶ added in v1.1.0
func SkipgramWindowSize(value int64) SkipgramAttr
SkipgramWindowSize sets the optional window_size attribute to value.
value: The number of words to predict to the left and right of the target. If not specified, defaults to 5
type SpaceToDepthAttr ¶ added in v1.4.0
type SpaceToDepthAttr func(optionalAttr)
SpaceToDepthAttr is an optional argument to SpaceToDepth.
func SpaceToDepthDataFormat ¶ added in v1.4.0
func SpaceToDepthDataFormat(value string) SpaceToDepthAttr
SpaceToDepthDataFormat sets the optional data_format attribute to value. If not specified, defaults to "NHWC"
type SparseMatMulAttr ¶ added in v1.1.0
type SparseMatMulAttr func(optionalAttr)
SparseMatMulAttr is an optional argument to SparseMatMul.
func SparseMatMulAIsSparse ¶ added in v1.1.0
func SparseMatMulAIsSparse(value bool) SparseMatMulAttr
SparseMatMulAIsSparse sets the optional a_is_sparse attribute to value. If not specified, defaults to false
func SparseMatMulBIsSparse ¶ added in v1.1.0
func SparseMatMulBIsSparse(value bool) SparseMatMulAttr
SparseMatMulBIsSparse sets the optional b_is_sparse attribute to value. If not specified, defaults to false
func SparseMatMulTransposeA ¶ added in v1.1.0
func SparseMatMulTransposeA(value bool) SparseMatMulAttr
SparseMatMulTransposeA sets the optional transpose_a attribute to value. If not specified, defaults to false
func SparseMatMulTransposeB ¶ added in v1.1.0
func SparseMatMulTransposeB(value bool) SparseMatMulAttr
SparseMatMulTransposeB sets the optional transpose_b attribute to value. If not specified, defaults to false
type SparseReduceMaxAttr ¶ added in v1.3.0
type SparseReduceMaxAttr func(optionalAttr)
SparseReduceMaxAttr is an optional argument to SparseReduceMax.
func SparseReduceMaxKeepDims ¶ added in v1.3.0
func SparseReduceMaxKeepDims(value bool) SparseReduceMaxAttr
SparseReduceMaxKeepDims sets the optional keep_dims attribute to value.
value: If true, retain reduced dimensions with length 1. If not specified, defaults to false
type SparseReduceMaxSparseAttr ¶ added in v1.3.0
type SparseReduceMaxSparseAttr func(optionalAttr)
SparseReduceMaxSparseAttr is an optional argument to SparseReduceMaxSparse.
func SparseReduceMaxSparseKeepDims ¶ added in v1.3.0
func SparseReduceMaxSparseKeepDims(value bool) SparseReduceMaxSparseAttr
SparseReduceMaxSparseKeepDims sets the optional keep_dims attribute to value.
value: If true, retain reduced dimensions with length 1. If not specified, defaults to false
type SparseReduceSumAttr ¶ added in v1.1.0
type SparseReduceSumAttr func(optionalAttr)
SparseReduceSumAttr is an optional argument to SparseReduceSum.
func SparseReduceSumKeepDims ¶ added in v1.1.0
func SparseReduceSumKeepDims(value bool) SparseReduceSumAttr
SparseReduceSumKeepDims sets the optional keep_dims attribute to value.
value: If true, retain reduced dimensions with length 1. If not specified, defaults to false
type SparseReduceSumSparseAttr ¶ added in v1.1.0
type SparseReduceSumSparseAttr func(optionalAttr)
SparseReduceSumSparseAttr is an optional argument to SparseReduceSumSparse.
func SparseReduceSumSparseKeepDims ¶ added in v1.1.0
func SparseReduceSumSparseKeepDims(value bool) SparseReduceSumSparseAttr
SparseReduceSumSparseKeepDims sets the optional keep_dims attribute to value.
value: If true, retain reduced dimensions with length 1. If not specified, defaults to false
type SparseTensorDenseMatMulAttr ¶ added in v1.1.0
type SparseTensorDenseMatMulAttr func(optionalAttr)
SparseTensorDenseMatMulAttr is an optional argument to SparseTensorDenseMatMul.
func SparseTensorDenseMatMulAdjointA ¶ added in v1.1.0
func SparseTensorDenseMatMulAdjointA(value bool) SparseTensorDenseMatMulAttr
SparseTensorDenseMatMulAdjointA sets the optional adjoint_a attribute to value.
value: Use the adjoint of A in the matrix multiply. If A is complex, this is transpose(conj(A)). Otherwise it's transpose(A). If not specified, defaults to false
func SparseTensorDenseMatMulAdjointB ¶ added in v1.1.0
func SparseTensorDenseMatMulAdjointB(value bool) SparseTensorDenseMatMulAttr
SparseTensorDenseMatMulAdjointB sets the optional adjoint_b attribute to value.
value: Use the adjoint of B in the matrix multiply. If B is complex, this is transpose(conj(B)). Otherwise it's transpose(B). If not specified, defaults to false
type SparseToDenseAttr ¶ added in v1.1.0
type SparseToDenseAttr func(optionalAttr)
SparseToDenseAttr is an optional argument to SparseToDense.
func SparseToDenseValidateIndices ¶ added in v1.1.0
func SparseToDenseValidateIndices(value bool) SparseToDenseAttr
SparseToDenseValidateIndices sets the optional validate_indices attribute to value.
value: If true, indices are checked to make sure they are sorted in lexicographic order and that there are no repeats. If not specified, defaults to true
type SparseToSparseSetOperationAttr ¶ added in v1.1.0
type SparseToSparseSetOperationAttr func(optionalAttr)
SparseToSparseSetOperationAttr is an optional argument to SparseToSparseSetOperation.
func SparseToSparseSetOperationValidateIndices ¶ added in v1.1.0
func SparseToSparseSetOperationValidateIndices(value bool) SparseToSparseSetOperationAttr
SparseToSparseSetOperationValidateIndices sets the optional validate_indices attribute to value. If not specified, defaults to true
type SqueezeAttr ¶ added in v1.1.0
type SqueezeAttr func(optionalAttr)
SqueezeAttr is an optional argument to Squeeze.
func SqueezeAxis ¶ added in v1.6.0
func SqueezeAxis(value []int64) SqueezeAttr
SqueezeAxis sets the optional axis attribute to value.
value: If specified, only squeezes the dimensions listed. The dimension index starts at 0. It is an error to squeeze a dimension that is not 1. Must be in the range `[-rank(input), rank(input))`. If not specified, defaults to <>
REQUIRES: len(value) >= 0
type StackPushV2Attr ¶ added in v1.3.0
type StackPushV2Attr func(optionalAttr)
StackPushV2Attr is an optional argument to StackPushV2.
func StackPushV2SwapMemory ¶ added in v1.3.0
func StackPushV2SwapMemory(value bool) StackPushV2Attr
StackPushV2SwapMemory sets the optional swap_memory attribute to value.
value: Swap `elem` to CPU. Default to false. If not specified, defaults to false
type StackV2Attr ¶ added in v1.3.0
type StackV2Attr func(optionalAttr)
StackV2Attr is an optional argument to StackV2.
func StackV2StackName ¶ added in v1.3.0
func StackV2StackName(value string) StackV2Attr
StackV2StackName sets the optional stack_name attribute to value.
value: Overrides the name used for the temporary stack resource. Default value is the name of the 'Stack' op (which is guaranteed unique). If not specified, defaults to ""
type StageAttr ¶ added in v1.1.0
type StageAttr func(optionalAttr)
StageAttr is an optional argument to Stage.
func StageCapacity ¶ added in v1.3.0
StageCapacity sets the optional capacity attribute to value.
value: Maximum number of elements in the Staging Area. If > 0, inserts on the container will block when the capacity is reached. If not specified, defaults to 0
REQUIRES: value >= 0
func StageContainer ¶ added in v1.1.0
StageContainer sets the optional container attribute to value.
value: If non-empty, this queue is placed in the given container. Otherwise, a default container is used. If not specified, defaults to ""
func StageMemoryLimit ¶ added in v1.3.0
StageMemoryLimit sets the optional memory_limit attribute to value.
value: The maximum number of bytes allowed for Tensors in the Staging Area. If > 0, inserts will block until sufficient space is available. If not specified, defaults to 0
REQUIRES: value >= 0
func StageSharedName ¶ added in v1.1.0
StageSharedName sets the optional shared_name attribute to value.
value: It is necessary to match this name to the matching Unstage Op. If not specified, defaults to ""
type StageClearAttr ¶ added in v1.3.0
type StageClearAttr func(optionalAttr)
StageClearAttr is an optional argument to StageClear.
func StageClearCapacity ¶ added in v1.3.0
func StageClearCapacity(value int64) StageClearAttr
StageClearCapacity sets the optional capacity attribute to value. If not specified, defaults to 0
REQUIRES: value >= 0
func StageClearContainer ¶ added in v1.3.0
func StageClearContainer(value string) StageClearAttr
StageClearContainer sets the optional container attribute to value. If not specified, defaults to ""
func StageClearMemoryLimit ¶ added in v1.3.0
func StageClearMemoryLimit(value int64) StageClearAttr
StageClearMemoryLimit sets the optional memory_limit attribute to value. If not specified, defaults to 0
REQUIRES: value >= 0
func StageClearSharedName ¶ added in v1.3.0
func StageClearSharedName(value string) StageClearAttr
StageClearSharedName sets the optional shared_name attribute to value. If not specified, defaults to ""
type StagePeekAttr ¶ added in v1.3.0
type StagePeekAttr func(optionalAttr)
StagePeekAttr is an optional argument to StagePeek.
func StagePeekCapacity ¶ added in v1.3.0
func StagePeekCapacity(value int64) StagePeekAttr
StagePeekCapacity sets the optional capacity attribute to value. If not specified, defaults to 0
REQUIRES: value >= 0
func StagePeekContainer ¶ added in v1.3.0
func StagePeekContainer(value string) StagePeekAttr
StagePeekContainer sets the optional container attribute to value. If not specified, defaults to ""
func StagePeekMemoryLimit ¶ added in v1.3.0
func StagePeekMemoryLimit(value int64) StagePeekAttr
StagePeekMemoryLimit sets the optional memory_limit attribute to value. If not specified, defaults to 0
REQUIRES: value >= 0
func StagePeekSharedName ¶ added in v1.3.0
func StagePeekSharedName(value string) StagePeekAttr
StagePeekSharedName sets the optional shared_name attribute to value. If not specified, defaults to ""
type StageSizeAttr ¶ added in v1.3.0
type StageSizeAttr func(optionalAttr)
StageSizeAttr is an optional argument to StageSize.
func StageSizeCapacity ¶ added in v1.3.0
func StageSizeCapacity(value int64) StageSizeAttr
StageSizeCapacity sets the optional capacity attribute to value. If not specified, defaults to 0
REQUIRES: value >= 0
func StageSizeContainer ¶ added in v1.3.0
func StageSizeContainer(value string) StageSizeAttr
StageSizeContainer sets the optional container attribute to value. If not specified, defaults to ""
func StageSizeMemoryLimit ¶ added in v1.3.0
func StageSizeMemoryLimit(value int64) StageSizeAttr
StageSizeMemoryLimit sets the optional memory_limit attribute to value. If not specified, defaults to 0
REQUIRES: value >= 0
func StageSizeSharedName ¶ added in v1.3.0
func StageSizeSharedName(value string) StageSizeAttr
StageSizeSharedName sets the optional shared_name attribute to value. If not specified, defaults to ""
type StatelessRandomNormalAttr ¶ added in v1.2.0
type StatelessRandomNormalAttr func(optionalAttr)
StatelessRandomNormalAttr is an optional argument to StatelessRandomNormal.
func StatelessRandomNormalDtype ¶ added in v1.2.0
func StatelessRandomNormalDtype(value tf.DataType) StatelessRandomNormalAttr
StatelessRandomNormalDtype sets the optional dtype attribute to value.
value: The type of the output. If not specified, defaults to DT_FLOAT
type StatelessRandomUniformAttr ¶ added in v1.2.0
type StatelessRandomUniformAttr func(optionalAttr)
StatelessRandomUniformAttr is an optional argument to StatelessRandomUniform.
func StatelessRandomUniformDtype ¶ added in v1.2.0
func StatelessRandomUniformDtype(value tf.DataType) StatelessRandomUniformAttr
StatelessRandomUniformDtype sets the optional dtype attribute to value.
value: The type of the output. If not specified, defaults to DT_FLOAT
type StatelessTruncatedNormalAttr ¶ added in v1.2.0
type StatelessTruncatedNormalAttr func(optionalAttr)
StatelessTruncatedNormalAttr is an optional argument to StatelessTruncatedNormal.
func StatelessTruncatedNormalDtype ¶ added in v1.2.0
func StatelessTruncatedNormalDtype(value tf.DataType) StatelessTruncatedNormalAttr
StatelessTruncatedNormalDtype sets the optional dtype attribute to value.
value: The type of the output. If not specified, defaults to DT_FLOAT
type StatsAggregatorHandleAttr ¶ added in v1.5.0
type StatsAggregatorHandleAttr func(optionalAttr)
StatsAggregatorHandleAttr is an optional argument to StatsAggregatorHandle.
func StatsAggregatorHandleContainer ¶ added in v1.5.0
func StatsAggregatorHandleContainer(value string) StatsAggregatorHandleAttr
StatsAggregatorHandleContainer sets the optional container attribute to value. If not specified, defaults to ""
func StatsAggregatorHandleSharedName ¶ added in v1.5.0
func StatsAggregatorHandleSharedName(value string) StatsAggregatorHandleAttr
StatsAggregatorHandleSharedName sets the optional shared_name attribute to value. If not specified, defaults to ""
type StridedSliceAttr ¶ added in v1.1.0
type StridedSliceAttr func(optionalAttr)
StridedSliceAttr is an optional argument to StridedSlice.
func StridedSliceBeginMask ¶ added in v1.1.0
func StridedSliceBeginMask(value int64) StridedSliceAttr
StridedSliceBeginMask sets the optional begin_mask attribute to value.
value: a bitmask where a bit i being 1 means to ignore the begin value and instead use the largest interval possible. At runtime begin[i] will be replaced with `[0, n-1) if `stride[i] > 0` or `[-1, n-1]` if `stride[i] < 0` If not specified, defaults to 0
func StridedSliceEllipsisMask ¶ added in v1.1.0
func StridedSliceEllipsisMask(value int64) StridedSliceAttr
StridedSliceEllipsisMask sets the optional ellipsis_mask attribute to value.
value: a bitmask where bit `i` being 1 means the `i`th position is actually an ellipsis. One bit at most can be 1. If `ellipsis_mask == 0`, then an implicit ellipsis mask of `1 << (m+1)` is provided. This means that `foo[3:5] == foo[3:5, ...]`. An ellipsis implicitly creates as many range specifications as necessary to fully specify the sliced range for every dimension. For example for a 4-dimensional tensor `foo` the slice `foo[2, ..., 5:8]` implies `foo[2, :, :, 5:8]`. If not specified, defaults to 0
func StridedSliceEndMask ¶ added in v1.1.0
func StridedSliceEndMask(value int64) StridedSliceAttr
StridedSliceEndMask sets the optional end_mask attribute to value.
value: analogous to `begin_mask` If not specified, defaults to 0
func StridedSliceNewAxisMask ¶ added in v1.1.0
func StridedSliceNewAxisMask(value int64) StridedSliceAttr
StridedSliceNewAxisMask sets the optional new_axis_mask attribute to value.
value: a bitmask where bit `i` being 1 means the `i`th specification creates a new shape 1 dimension. For example `foo[:4, tf.newaxis, :2]` would produce a shape `(4, 1, 2)` tensor. If not specified, defaults to 0
func StridedSliceShrinkAxisMask ¶ added in v1.1.0
func StridedSliceShrinkAxisMask(value int64) StridedSliceAttr
StridedSliceShrinkAxisMask sets the optional shrink_axis_mask attribute to value.
value: a bitmask where bit `i` implies that the `i`th specification should shrink the dimensionality. begin and end must imply a slice of size 1 in the dimension. For example in python one might do `foo[:, 3, :]` which would result in `shrink_axis_mask` being 2. If not specified, defaults to 0
type StridedSliceGradAttr ¶ added in v1.1.0
type StridedSliceGradAttr func(optionalAttr)
StridedSliceGradAttr is an optional argument to StridedSliceGrad.
func StridedSliceGradBeginMask ¶ added in v1.1.0
func StridedSliceGradBeginMask(value int64) StridedSliceGradAttr
StridedSliceGradBeginMask sets the optional begin_mask attribute to value. If not specified, defaults to 0
func StridedSliceGradEllipsisMask ¶ added in v1.1.0
func StridedSliceGradEllipsisMask(value int64) StridedSliceGradAttr
StridedSliceGradEllipsisMask sets the optional ellipsis_mask attribute to value. If not specified, defaults to 0
func StridedSliceGradEndMask ¶ added in v1.1.0
func StridedSliceGradEndMask(value int64) StridedSliceGradAttr
StridedSliceGradEndMask sets the optional end_mask attribute to value. If not specified, defaults to 0
func StridedSliceGradNewAxisMask ¶ added in v1.1.0
func StridedSliceGradNewAxisMask(value int64) StridedSliceGradAttr
StridedSliceGradNewAxisMask sets the optional new_axis_mask attribute to value. If not specified, defaults to 0
func StridedSliceGradShrinkAxisMask ¶ added in v1.1.0
func StridedSliceGradShrinkAxisMask(value int64) StridedSliceGradAttr
StridedSliceGradShrinkAxisMask sets the optional shrink_axis_mask attribute to value. If not specified, defaults to 0
type StringJoinAttr ¶ added in v1.1.0
type StringJoinAttr func(optionalAttr)
StringJoinAttr is an optional argument to StringJoin.
func StringJoinSeparator ¶ added in v1.1.0
func StringJoinSeparator(value string) StringJoinAttr
StringJoinSeparator sets the optional separator attribute to value.
value: string, an optional join separator. If not specified, defaults to ""
type StringSplitAttr ¶ added in v1.4.0
type StringSplitAttr func(optionalAttr)
StringSplitAttr is an optional argument to StringSplit.
func StringSplitSkipEmpty ¶ added in v1.4.0
func StringSplitSkipEmpty(value bool) StringSplitAttr
StringSplitSkipEmpty sets the optional skip_empty attribute to value.
value: A `bool`. If `True`, skip the empty strings from the result. If not specified, defaults to true
type StringToNumberAttr ¶ added in v1.1.0
type StringToNumberAttr func(optionalAttr)
StringToNumberAttr is an optional argument to StringToNumber.
func StringToNumberOutType ¶ added in v1.1.0
func StringToNumberOutType(value tf.DataType) StringToNumberAttr
StringToNumberOutType sets the optional out_type attribute to value.
value: The numeric type to interpret each string in `string_tensor` as. If not specified, defaults to DT_FLOAT
type SumAttr ¶ added in v1.1.0
type SumAttr func(optionalAttr)
SumAttr is an optional argument to Sum.
func SumKeepDims ¶ added in v1.1.0
SumKeepDims sets the optional keep_dims attribute to value.
value: If true, retain reduced dimensions with length 1. If not specified, defaults to false
type SummaryWriterAttr ¶ added in v1.4.0
type SummaryWriterAttr func(optionalAttr)
SummaryWriterAttr is an optional argument to SummaryWriter.
func SummaryWriterContainer ¶ added in v1.4.0
func SummaryWriterContainer(value string) SummaryWriterAttr
SummaryWriterContainer sets the optional container attribute to value. If not specified, defaults to ""
func SummaryWriterSharedName ¶ added in v1.4.0
func SummaryWriterSharedName(value string) SummaryWriterAttr
SummaryWriterSharedName sets the optional shared_name attribute to value. If not specified, defaults to ""
type SvdAttr ¶ added in v1.1.0
type SvdAttr func(optionalAttr)
SvdAttr is an optional argument to Svd.
func SvdComputeUv ¶ added in v1.1.0
SvdComputeUv sets the optional compute_uv attribute to value.
value: If true, left and right singular vectors will be computed and returned in `u` and `v`, respectively. If false, `u` and `v` are not set and should never referenced. If not specified, defaults to true
func SvdFullMatrices ¶ added in v1.1.0
SvdFullMatrices sets the optional full_matrices attribute to value.
value: If true, compute full-sized `u` and `v`. If false (the default), compute only the leading `P` singular vectors. Ignored if `compute_uv` is `False`. If not specified, defaults to false
type TFRecordReaderV2Attr ¶ added in v1.1.0
type TFRecordReaderV2Attr func(optionalAttr)
TFRecordReaderV2Attr is an optional argument to TFRecordReaderV2.
func TFRecordReaderV2CompressionType ¶ added in v1.1.0
func TFRecordReaderV2CompressionType(value string) TFRecordReaderV2Attr
TFRecordReaderV2CompressionType sets the optional compression_type attribute to value. If not specified, defaults to ""
func TFRecordReaderV2Container ¶ added in v1.1.0
func TFRecordReaderV2Container(value string) TFRecordReaderV2Attr
TFRecordReaderV2Container sets the optional container attribute to value.
value: If non-empty, this reader is placed in the given container. Otherwise, a default container is used. If not specified, defaults to ""
func TFRecordReaderV2SharedName ¶ added in v1.1.0
func TFRecordReaderV2SharedName(value string) TFRecordReaderV2Attr
TFRecordReaderV2SharedName sets the optional shared_name attribute to value.
value: If non-empty, this reader is named in the given bucket with this shared_name. Otherwise, the node name is used instead. If not specified, defaults to ""
type TakeManySparseFromTensorsMapAttr ¶ added in v1.1.0
type TakeManySparseFromTensorsMapAttr func(optionalAttr)
TakeManySparseFromTensorsMapAttr is an optional argument to TakeManySparseFromTensorsMap.
func TakeManySparseFromTensorsMapContainer ¶ added in v1.1.0
func TakeManySparseFromTensorsMapContainer(value string) TakeManySparseFromTensorsMapAttr
TakeManySparseFromTensorsMapContainer sets the optional container attribute to value.
value: The container name for the `SparseTensorsMap` read by this op. If not specified, defaults to ""
func TakeManySparseFromTensorsMapSharedName ¶ added in v1.1.0
func TakeManySparseFromTensorsMapSharedName(value string) TakeManySparseFromTensorsMapAttr
TakeManySparseFromTensorsMapSharedName sets the optional shared_name attribute to value.
value: The shared name for the `SparseTensorsMap` read by this op. It should not be blank; rather the `shared_name` or unique Operation name of the Op that created the original `SparseTensorsMap` should be used. If not specified, defaults to ""
type TensorArrayConcatV2Attr ¶ added in v1.1.0
type TensorArrayConcatV2Attr func(optionalAttr)
TensorArrayConcatV2Attr is an optional argument to TensorArrayConcatV2.
func TensorArrayConcatV2ElementShapeExcept0 ¶ added in v1.1.0
func TensorArrayConcatV2ElementShapeExcept0(value tf.Shape) TensorArrayConcatV2Attr
TensorArrayConcatV2ElementShapeExcept0 sets the optional element_shape_except0 attribute to value. If not specified, defaults to <unknown_rank:true >
type TensorArrayConcatV3Attr ¶ added in v1.1.0
type TensorArrayConcatV3Attr func(optionalAttr)
TensorArrayConcatV3Attr is an optional argument to TensorArrayConcatV3.
func TensorArrayConcatV3ElementShapeExcept0 ¶ added in v1.1.0
func TensorArrayConcatV3ElementShapeExcept0(value tf.Shape) TensorArrayConcatV3Attr
TensorArrayConcatV3ElementShapeExcept0 sets the optional element_shape_except0 attribute to value.
value: The expected shape of an element, if known, excluding the first dimension. Used to validate the shapes of TensorArray elements. If this shape is not fully specified, concatenating zero-size TensorArrays is an error. If not specified, defaults to <unknown_rank:true >
type TensorArrayGatherV2Attr ¶ added in v1.1.0
type TensorArrayGatherV2Attr func(optionalAttr)
TensorArrayGatherV2Attr is an optional argument to TensorArrayGatherV2.
func TensorArrayGatherV2ElementShape ¶ added in v1.1.0
func TensorArrayGatherV2ElementShape(value tf.Shape) TensorArrayGatherV2Attr
TensorArrayGatherV2ElementShape sets the optional element_shape attribute to value. If not specified, defaults to <unknown_rank:true >
type TensorArrayGatherV3Attr ¶ added in v1.1.0
type TensorArrayGatherV3Attr func(optionalAttr)
TensorArrayGatherV3Attr is an optional argument to TensorArrayGatherV3.
func TensorArrayGatherV3ElementShape ¶ added in v1.1.0
func TensorArrayGatherV3ElementShape(value tf.Shape) TensorArrayGatherV3Attr
TensorArrayGatherV3ElementShape sets the optional element_shape attribute to value.
value: The expected shape of an element, if known. Used to validate the shapes of TensorArray elements. If this shape is not fully specified, gathering zero-size TensorArrays is an error. If not specified, defaults to <unknown_rank:true >
type TensorArrayV2Attr ¶ added in v1.1.0
type TensorArrayV2Attr func(optionalAttr)
TensorArrayV2Attr is an optional argument to TensorArrayV2.
func TensorArrayV2ClearAfterRead ¶ added in v1.1.0
func TensorArrayV2ClearAfterRead(value bool) TensorArrayV2Attr
TensorArrayV2ClearAfterRead sets the optional clear_after_read attribute to value. If not specified, defaults to true
func TensorArrayV2DynamicSize ¶ added in v1.1.0
func TensorArrayV2DynamicSize(value bool) TensorArrayV2Attr
TensorArrayV2DynamicSize sets the optional dynamic_size attribute to value. If not specified, defaults to false
func TensorArrayV2ElementShape ¶ added in v1.1.0
func TensorArrayV2ElementShape(value tf.Shape) TensorArrayV2Attr
TensorArrayV2ElementShape sets the optional element_shape attribute to value. If not specified, defaults to <unknown_rank:true >
func TensorArrayV2TensorArrayName ¶ added in v1.1.0
func TensorArrayV2TensorArrayName(value string) TensorArrayV2Attr
TensorArrayV2TensorArrayName sets the optional tensor_array_name attribute to value. If not specified, defaults to ""
type TensorArrayV3Attr ¶ added in v1.1.0
type TensorArrayV3Attr func(optionalAttr)
TensorArrayV3Attr is an optional argument to TensorArrayV3.
func TensorArrayV3ClearAfterRead ¶ added in v1.1.0
func TensorArrayV3ClearAfterRead(value bool) TensorArrayV3Attr
TensorArrayV3ClearAfterRead sets the optional clear_after_read attribute to value.
value: If true (default), Tensors in the TensorArray are cleared after being read. This disables multiple read semantics but allows early release of memory. If not specified, defaults to true
func TensorArrayV3DynamicSize ¶ added in v1.1.0
func TensorArrayV3DynamicSize(value bool) TensorArrayV3Attr
TensorArrayV3DynamicSize sets the optional dynamic_size attribute to value.
value: A boolean that determines whether writes to the TensorArray are allowed to grow the size. By default, this is not allowed. If not specified, defaults to false
func TensorArrayV3ElementShape ¶ added in v1.1.0
func TensorArrayV3ElementShape(value tf.Shape) TensorArrayV3Attr
TensorArrayV3ElementShape sets the optional element_shape attribute to value.
value: The expected shape of an element, if known. Used to validate the shapes of TensorArray elements. If this shape is not fully specified, gathering zero-size TensorArrays is an error. If not specified, defaults to <unknown_rank:true >
func TensorArrayV3IdenticalElementShapes ¶ added in v1.5.0
func TensorArrayV3IdenticalElementShapes(value bool) TensorArrayV3Attr
TensorArrayV3IdenticalElementShapes sets the optional identical_element_shapes attribute to value.
value: If true (default is false), then all elements in the TensorArray will be expected to have have identical shapes. This allows certain behaviors, like dynamically checking for consistent shapes on write, and being able to fill in properly shaped zero tensors on stack -- even if the element_shape attribute is not fully defined. If not specified, defaults to false
func TensorArrayV3TensorArrayName ¶ added in v1.1.0
func TensorArrayV3TensorArrayName(value string) TensorArrayV3Attr
TensorArrayV3TensorArrayName sets the optional tensor_array_name attribute to value.
value: Overrides the name used for the temporary tensor_array resource. Default value is the name of the 'TensorArray' op (which is guaranteed unique). If not specified, defaults to ""
type TensorSummaryAttr ¶ added in v1.1.0
type TensorSummaryAttr func(optionalAttr)
TensorSummaryAttr is an optional argument to TensorSummary.
func TensorSummaryDescription ¶ added in v1.1.0
func TensorSummaryDescription(value string) TensorSummaryAttr
TensorSummaryDescription sets the optional description attribute to value.
value: A json-encoded SummaryDescription proto. If not specified, defaults to ""
func TensorSummaryDisplayName ¶ added in v1.1.0
func TensorSummaryDisplayName(value string) TensorSummaryAttr
TensorSummaryDisplayName sets the optional display_name attribute to value.
value: An unused string. If not specified, defaults to ""
func TensorSummaryLabels ¶ added in v1.1.0
func TensorSummaryLabels(value []string) TensorSummaryAttr
TensorSummaryLabels sets the optional labels attribute to value.
value: An unused list of strings. If not specified, defaults to <>
type TextLineReaderV2Attr ¶ added in v1.1.0
type TextLineReaderV2Attr func(optionalAttr)
TextLineReaderV2Attr is an optional argument to TextLineReaderV2.
func TextLineReaderV2Container ¶ added in v1.1.0
func TextLineReaderV2Container(value string) TextLineReaderV2Attr
TextLineReaderV2Container sets the optional container attribute to value.
value: If non-empty, this reader is placed in the given container. Otherwise, a default container is used. If not specified, defaults to ""
func TextLineReaderV2SharedName ¶ added in v1.1.0
func TextLineReaderV2SharedName(value string) TextLineReaderV2Attr
TextLineReaderV2SharedName sets the optional shared_name attribute to value.
value: If non-empty, this reader is named in the given bucket with this shared_name. Otherwise, the node name is used instead. If not specified, defaults to ""
func TextLineReaderV2SkipHeaderLines ¶ added in v1.1.0
func TextLineReaderV2SkipHeaderLines(value int64) TextLineReaderV2Attr
TextLineReaderV2SkipHeaderLines sets the optional skip_header_lines attribute to value.
value: Number of lines to skip from the beginning of every file. If not specified, defaults to 0
type ThreadUnsafeUnigramCandidateSamplerAttr ¶ added in v1.1.0
type ThreadUnsafeUnigramCandidateSamplerAttr func(optionalAttr)
ThreadUnsafeUnigramCandidateSamplerAttr is an optional argument to ThreadUnsafeUnigramCandidateSampler.
func ThreadUnsafeUnigramCandidateSamplerSeed ¶ added in v1.1.0
func ThreadUnsafeUnigramCandidateSamplerSeed(value int64) ThreadUnsafeUnigramCandidateSamplerAttr
ThreadUnsafeUnigramCandidateSamplerSeed sets the optional seed attribute to value.
value: If either seed or seed2 are set to be non-zero, the random number generator is seeded by the given seed. Otherwise, it is seeded by a random seed. If not specified, defaults to 0
func ThreadUnsafeUnigramCandidateSamplerSeed2 ¶ added in v1.1.0
func ThreadUnsafeUnigramCandidateSamplerSeed2(value int64) ThreadUnsafeUnigramCandidateSamplerAttr
ThreadUnsafeUnigramCandidateSamplerSeed2 sets the optional seed2 attribute to value.
value: An second seed to avoid seed collision. If not specified, defaults to 0
type TopKAttr ¶ added in v1.1.0
type TopKAttr func(optionalAttr)
TopKAttr is an optional argument to TopK.
func TopKSorted ¶ added in v1.1.0
TopKSorted sets the optional sorted attribute to value.
value: If true the resulting `k` elements will be sorted by the values in descending order. If not specified, defaults to true
type TopKV2Attr ¶ added in v1.1.0
type TopKV2Attr func(optionalAttr)
TopKV2Attr is an optional argument to TopKV2.
func TopKV2Sorted ¶ added in v1.1.0
func TopKV2Sorted(value bool) TopKV2Attr
TopKV2Sorted sets the optional sorted attribute to value.
value: If true the resulting `k` elements will be sorted by the values in descending order. If not specified, defaults to true
type TruncatedNormalAttr ¶ added in v1.1.0
type TruncatedNormalAttr func(optionalAttr)
TruncatedNormalAttr is an optional argument to TruncatedNormal.
func TruncatedNormalSeed ¶ added in v1.1.0
func TruncatedNormalSeed(value int64) TruncatedNormalAttr
TruncatedNormalSeed sets the optional seed attribute to value.
value: If either `seed` or `seed2` are set to be non-zero, the random number generator is seeded by the given seed. Otherwise, it is seeded by a random seed. If not specified, defaults to 0
func TruncatedNormalSeed2 ¶ added in v1.1.0
func TruncatedNormalSeed2(value int64) TruncatedNormalAttr
TruncatedNormalSeed2 sets the optional seed2 attribute to value.
value: A second seed to avoid seed collision. If not specified, defaults to 0
type UniformCandidateSamplerAttr ¶ added in v1.1.0
type UniformCandidateSamplerAttr func(optionalAttr)
UniformCandidateSamplerAttr is an optional argument to UniformCandidateSampler.
func UniformCandidateSamplerSeed ¶ added in v1.1.0
func UniformCandidateSamplerSeed(value int64) UniformCandidateSamplerAttr
UniformCandidateSamplerSeed sets the optional seed attribute to value.
value: If either seed or seed2 are set to be non-zero, the random number generator is seeded by the given seed. Otherwise, it is seeded by a random seed. If not specified, defaults to 0
func UniformCandidateSamplerSeed2 ¶ added in v1.1.0
func UniformCandidateSamplerSeed2(value int64) UniformCandidateSamplerAttr
UniformCandidateSamplerSeed2 sets the optional seed2 attribute to value.
value: An second seed to avoid seed collision. If not specified, defaults to 0
type UniqueAttr ¶ added in v1.1.0
type UniqueAttr func(optionalAttr)
UniqueAttr is an optional argument to Unique.
func UniqueOutIdx ¶ added in v1.1.0
func UniqueOutIdx(value tf.DataType) UniqueAttr
UniqueOutIdx sets the optional out_idx attribute to value. If not specified, defaults to DT_INT32
type UniqueV2Attr ¶ added in v1.6.0
type UniqueV2Attr func(optionalAttr)
UniqueV2Attr is an optional argument to UniqueV2.
func UniqueV2OutIdx ¶ added in v1.6.0
func UniqueV2OutIdx(value tf.DataType) UniqueV2Attr
UniqueV2OutIdx sets the optional out_idx attribute to value. If not specified, defaults to DT_INT32
type UniqueWithCountsAttr ¶ added in v1.1.0
type UniqueWithCountsAttr func(optionalAttr)
UniqueWithCountsAttr is an optional argument to UniqueWithCounts.
func UniqueWithCountsOutIdx ¶ added in v1.1.0
func UniqueWithCountsOutIdx(value tf.DataType) UniqueWithCountsAttr
UniqueWithCountsOutIdx sets the optional out_idx attribute to value. If not specified, defaults to DT_INT32
type UnpackAttr ¶ added in v1.1.0
type UnpackAttr func(optionalAttr)
UnpackAttr is an optional argument to Unpack.
func UnpackAxis ¶ added in v1.1.0
func UnpackAxis(value int64) UnpackAttr
UnpackAxis sets the optional axis attribute to value.
value: Dimension along which to unpack. Negative values wrap around, so the valid range is `[-R, R)`. If not specified, defaults to 0
type UnstageAttr ¶ added in v1.1.0
type UnstageAttr func(optionalAttr)
UnstageAttr is an optional argument to Unstage.
func UnstageCapacity ¶ added in v1.3.0
func UnstageCapacity(value int64) UnstageAttr
UnstageCapacity sets the optional capacity attribute to value. If not specified, defaults to 0
REQUIRES: value >= 0
func UnstageContainer ¶ added in v1.1.0
func UnstageContainer(value string) UnstageAttr
UnstageContainer sets the optional container attribute to value. If not specified, defaults to ""
func UnstageMemoryLimit ¶ added in v1.3.0
func UnstageMemoryLimit(value int64) UnstageAttr
UnstageMemoryLimit sets the optional memory_limit attribute to value. If not specified, defaults to 0
REQUIRES: value >= 0
func UnstageSharedName ¶ added in v1.1.0
func UnstageSharedName(value string) UnstageAttr
UnstageSharedName sets the optional shared_name attribute to value. If not specified, defaults to ""
type VarHandleOpAttr ¶ added in v1.1.0
type VarHandleOpAttr func(optionalAttr)
VarHandleOpAttr is an optional argument to VarHandleOp.
func VarHandleOpContainer ¶ added in v1.1.0
func VarHandleOpContainer(value string) VarHandleOpAttr
VarHandleOpContainer sets the optional container attribute to value.
value: the container this variable is placed in. If not specified, defaults to ""
func VarHandleOpSharedName ¶ added in v1.1.0
func VarHandleOpSharedName(value string) VarHandleOpAttr
VarHandleOpSharedName sets the optional shared_name attribute to value.
value: the name by which this variable is referred to. If not specified, defaults to ""
type VariableShapeAttr ¶ added in v1.4.0
type VariableShapeAttr func(optionalAttr)
VariableShapeAttr is an optional argument to VariableShape.
func VariableShapeOutType ¶ added in v1.4.0
func VariableShapeOutType(value tf.DataType) VariableShapeAttr
VariableShapeOutType sets the optional out_type attribute to value. If not specified, defaults to DT_INT32
type WholeFileReaderV2Attr ¶ added in v1.1.0
type WholeFileReaderV2Attr func(optionalAttr)
WholeFileReaderV2Attr is an optional argument to WholeFileReaderV2.
func WholeFileReaderV2Container ¶ added in v1.1.0
func WholeFileReaderV2Container(value string) WholeFileReaderV2Attr
WholeFileReaderV2Container sets the optional container attribute to value.
value: If non-empty, this reader is placed in the given container. Otherwise, a default container is used. If not specified, defaults to ""
func WholeFileReaderV2SharedName ¶ added in v1.1.0
func WholeFileReaderV2SharedName(value string) WholeFileReaderV2Attr
WholeFileReaderV2SharedName sets the optional shared_name attribute to value.
value: If non-empty, this reader is named in the given bucket with this shared_name. Otherwise, the node name is used instead. If not specified, defaults to ""
type WriteAudioSummaryAttr ¶ added in v1.4.0
type WriteAudioSummaryAttr func(optionalAttr)
WriteAudioSummaryAttr is an optional argument to WriteAudioSummary.
func WriteAudioSummaryMaxOutputs ¶ added in v1.4.0
func WriteAudioSummaryMaxOutputs(value int64) WriteAudioSummaryAttr
WriteAudioSummaryMaxOutputs sets the optional max_outputs attribute to value.
value: Max number of batch elements to generate audio for. If not specified, defaults to 3
REQUIRES: value >= 1
type WriteImageSummaryAttr ¶ added in v1.4.0
type WriteImageSummaryAttr func(optionalAttr)
WriteImageSummaryAttr is an optional argument to WriteImageSummary.
func WriteImageSummaryMaxImages ¶ added in v1.4.0
func WriteImageSummaryMaxImages(value int64) WriteImageSummaryAttr
WriteImageSummaryMaxImages sets the optional max_images attribute to value.
value: Max number of batch elements to generate images for. If not specified, defaults to 3
REQUIRES: value >= 1