 README
¶
README
¶
![]()







![]()
All-in-one 的开源观测平台
开箱即用,集数据采集、可视化、监控告警于一体
推荐升级您的 Prometheus + AlertManager + Grafana + ELK + Jaeger 组合方案到夜莺!
功能和特点
- 开箱即用
- 支持 Docker、Helm Chart、云服务等多种部署方式,集数据采集、监控告警、可视化为一体,内置多种监控仪表盘、快捷视图、告警规则模板,导入即可快速使用,大幅降低云原生监控系统的建设成本、学习成本、使用成本;
- 专业告警
- 可视化的告警配置和管理,支持丰富的告警规则,提供屏蔽规则、订阅规则的配置能力,支持告警多种送达渠道,支持告警自愈、告警事件管理等;
- 推荐您使用夜莺的同时,无缝搭配FlashDuty,实现告警聚合收敛、认领、升级、排班、协同,让告警的触达既高效,又确保告警处理不遗漏、做到件件有回响。
- 云原生
- 以交钥匙的方式快速构建企业级的云原生监控体系,支持 Categraf、Telegraf、Grafana-agent 等多种采集器,支持 Prometheus、VictoriaMetrics、M3DB、ElasticSearch、Jaeger 等多种数据源,兼容支持导入 Grafana 仪表盘,与云原生生态无缝集成;
- 高性能 高可用
- 得益于夜莺的多数据源管理引擎,和夜莺引擎侧优秀的架构设计,借助于高性能时序库,可以满足数亿时间线的采集、存储、告警分析场景,节省大量成本;
- 夜莺监控组件均可水平扩展,无单点,已在上千家企业部署落地,经受了严苛的生产实践检验。众多互联网头部公司,夜莺集群机器达百台,处理数亿级时间线,重度使用夜莺监控;
- 灵活扩展 中心化管理
- 夜莺监控,可部署在 1 核 1G 的云主机,可在上百台机器集群化部署,可运行在 K8s 中;也可将时序库、告警引擎等组件下沉到各机房、各 Region,兼顾边缘部署和中心化统一管理,解决数据割裂,缺乏统一视图的难题;
- 开放社区
- 托管于中国计算机学会开源发展委员会,有快猫星云和众多公司的持续投入,和数千名社区用户的积极参与,以及夜莺监控项目清晰明确的定位,都保证了夜莺开源社区健康、长久的发展。活跃、专业的社区用户也在持续迭代和沉淀更多的最佳实践于产品中;
使用场景
- 如果您希望在一个平台中,统一管理和查看 Metrics、Logging、Tracing 数据,推荐你使用夜莺:
- 请参考阅读:不止于监控,夜莺 V6 全新升级为开源观测平台
- 如果您在使用 Prometheus 过程中,有以下的一个或者多个需求场景,推荐您无缝升级到夜莺:
- Prometheus、Alertmanager、Grafana 等多个系统较为割裂,缺乏统一视图,无法开箱即用;
- 通过修改配置文件来管理 Prometheus、Alertmanager 的方式,学习曲线大,协同有难度;
- 数据量过大而无法扩展您的 Prometheus 集群;
- 生产环境运行多套 Prometheus 集群,面临管理和使用成本高的问题;
- 如果您在使用 Zabbix,有以下的场景,推荐您升级到夜莺:
- 监控的数据量太大,希望有更好的扩展解决方案;
- 学习曲线高,多人多团队模式下,希望有更好的协同使用效率;
- 微服务和云原生架构下,监控数据的生命周期多变、监控数据维度基数高,Zabbix 数据模型不易适配;
- 了解更多Zabbix和夜莺监控的对比,推荐您进一步阅读Zabbix 和夜莺监控选型对比
- 如果您在使用 Open-Falcon,我们推荐您升级到夜莺:
- 关于 Open-Falcon 和夜莺的详细介绍,请参考阅读:云原生监控的十个特点和趋势
- 监控系统和可观测平台的区别,请参考阅读:从监控系统到可观测平台,Gap有多大
- 我们推荐您使用 Categraf 作为首选的监控数据采集器:
- Categraf 是夜莺监控的默认采集器,采用开放插件机制和 All-in-one 的设计理念,同时支持 metric、log、trace、event 的采集。Categraf 不仅可以采集 CPU、内存、网络等系统层面的指标,也集成了众多开源组件的采集能力,支持K8s生态。Categraf 内置了对应的仪表盘和告警规则,开箱即用。
文档
产品示意图
https://user-images.githubusercontent.com/792850/216888712-2565fcea-9df5-47bd-a49e-d60af9bd76e8.mp4
夜莺架构
夜莺监控可以接收各种采集器上报的监控数据(比如 Categraf、telegraf、grafana-agent、Prometheus),并写入多种流行的时序数据库中(可以支持Prometheus、M3DB、VictoriaMetrics、Thanos、TDEngine等),提供告警规则、屏蔽规则、订阅规则的配置能力,提供监控数据的查看能力,提供告警自愈机制(告警触发之后自动回调某个webhook地址或者执行某个脚本),提供历史告警事件的存储管理、分组查看的能力。
中心汇聚式部署方案
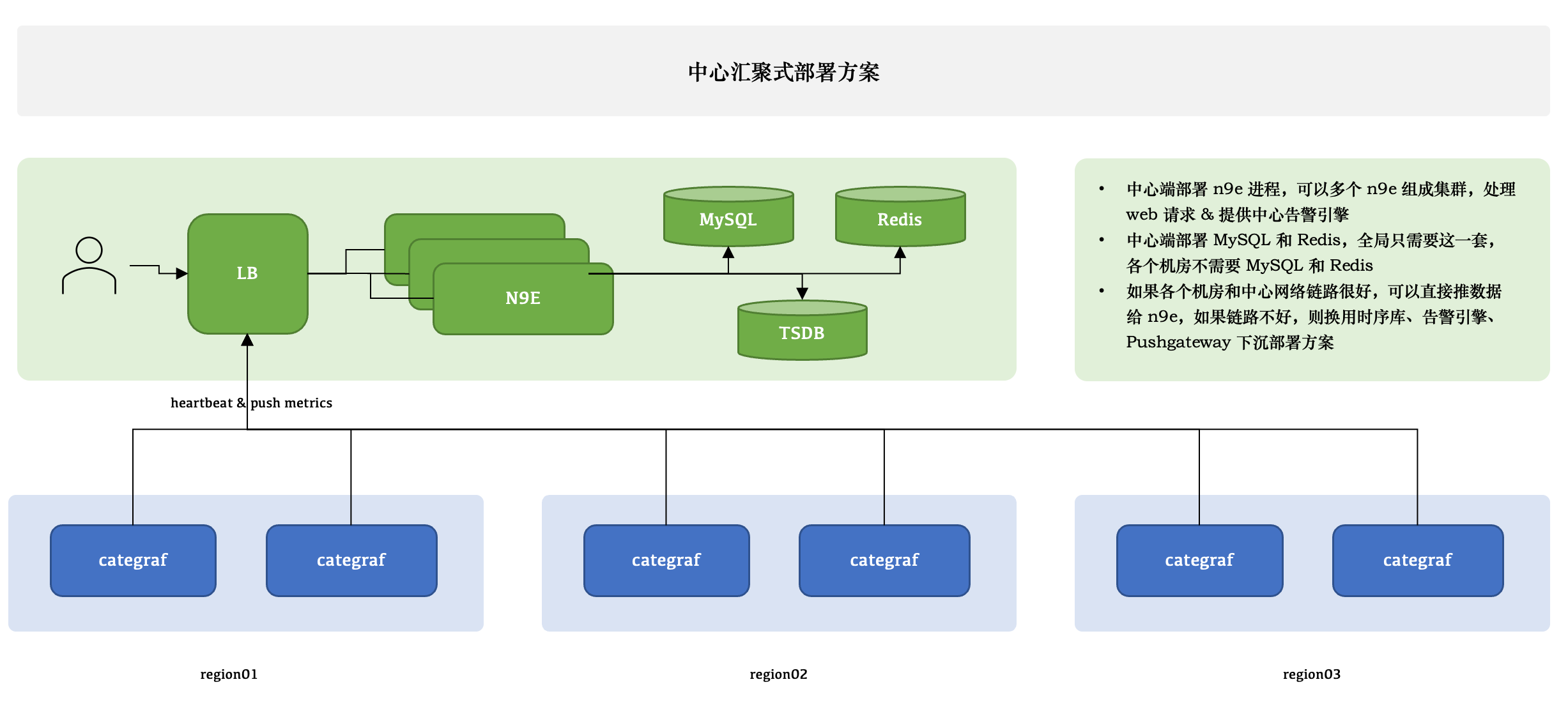
夜莺只有一个模块,就是 n9e,可以部署多个 n9e 实例组成集群,n9e 依赖 2 个存储,数据库、Redis,数据库可以使用 MySQL 或 Postgres,自己按需选用。
n9e 提供的是 HTTP 接口,前面负载均衡可以是 4 层的,也可以是 7 层的。一般就选用 Nginx 就可以了。
n9e 这个模块接收到数据之后,需要转发给后端的时序库,相关配置是:
[Pushgw]
LabelRewrite = true
[[Pushgw.Writers]]
Url = "http://127.0.0.1:9090/api/v1/write"
注意:虽然数据源可以在页面配置了,但是上报转发链路,还是需要在配置文件指定。
所有机房的 agent( 比如 Categraf、Telegraf、 Grafana-agent、Datadog-agent ),都直接推数据给 n9e,这个架构最为简单,维护成本最低。当然,前提是要求机房之间网络链路比较好,一般有专线。如果网络链路不好,则要使用下面的部署方式了。
边缘下沉式混杂部署方案
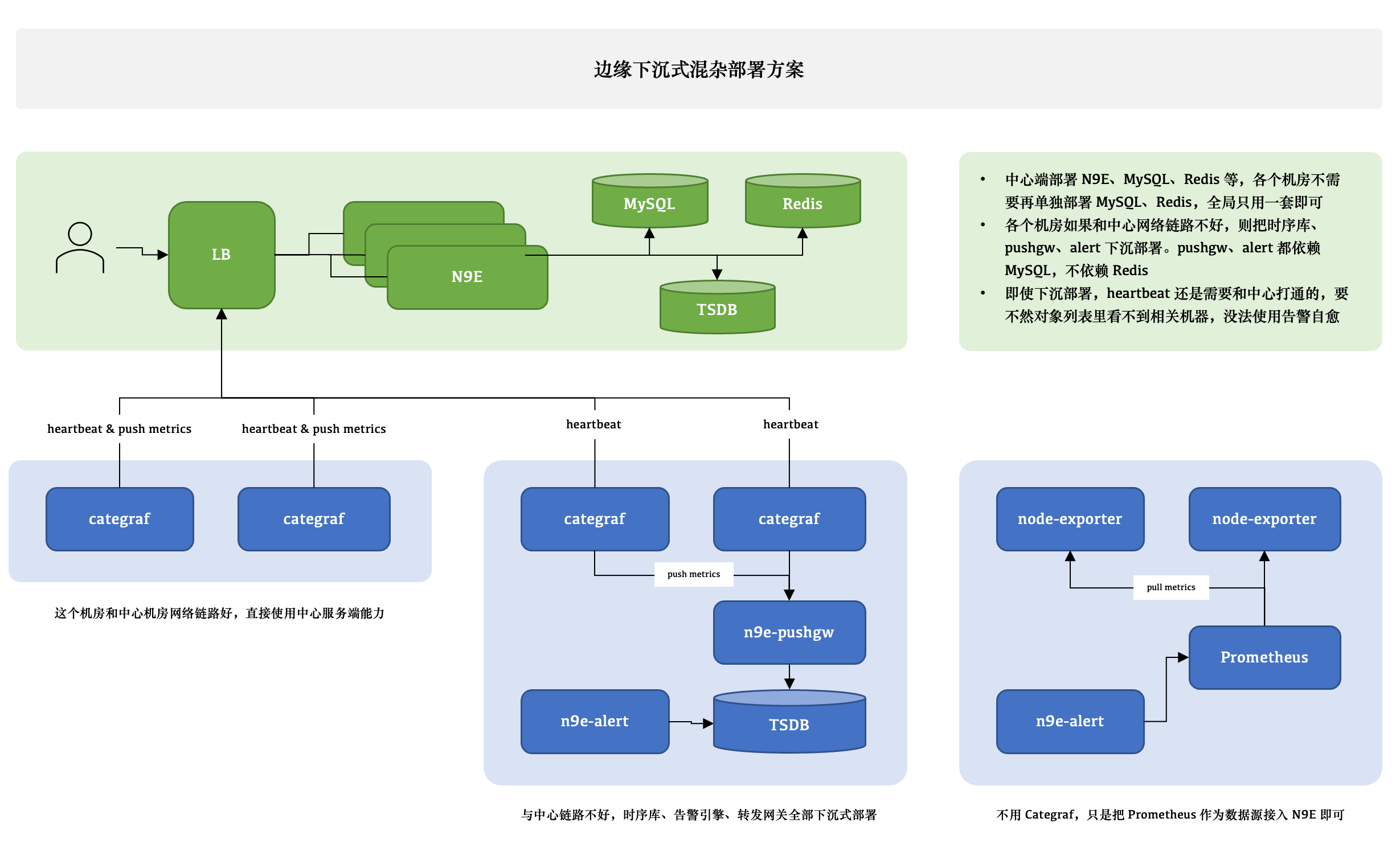
这个图尝试解释 3 种不同的情形,比如 A 机房和中心网络链路很好,Categraf 可以直接汇报数据给中心 n9e 模块,另一个机房网络链路不好,就需要把时序库下沉部署,时序库下沉了,对应的告警引擎和转发网关也都要跟随下沉,这样数据不会跨机房传输,比较稳定。但是心跳还是需要往中心心跳,要不然在对象列表里看不到机器的 CPU、内存使用率。还有的时候,可能是接入的一个已有的 Prometheus,数据采集没有走 Categraf,那此时只需要把 Prometheus 作为数据源接入夜莺即可,可以在夜莺里看图、配告警规则,但是就是在对象列表里看不到,也不能使用告警自愈的功能,问题也不大,核心功能都不受影响。
边缘机房,下沉部署时序库、告警引擎、转发网关的时候,要注意,告警引擎需要依赖数据库,因为要同步告警规则,转发网关也要依赖数据库,因为要注册对象到数据库里去,需要打通相关网络,告警引擎和转发网关都不用Redis,所以无需为 Redis 打通网络。
VictoriaMetrics 集群架构

如果单机版本的时序数据库(比如 Prometheus) 性能有瓶颈或容灾较差,我们推荐使用 VictoriaMetrics,VictoriaMetrics 架构较为简单,性能优异,易于部署和运维,架构图如上。VictoriaMetrics 更详尽的文档,还请参考其官网。
夜莺社区
开源项目要更有生命力,离不开开放的治理架构和源源不断的开发者和用户共同参与,我们致力于建立开放、中立的开源治理架构,吸纳更多来自企业、高校等各方面对云原生监控感兴趣、有热情的开发者,一起打造有活力的夜莺开源社区。关于《夜莺开源项目和社区治理架构(草案)》,请查阅 COMMUNITY GOVERNANCE.
我们欢迎您以各种方式参与到夜莺开源项目和开源社区中来,工作包括不限于:
- 补充和完善文档 => n9e.github.io
- 分享您在使用夜莺监控过程中的最佳实践和经验心得 => 文章分享
- 提交产品建议 =》 github issue
- 提交代码,让夜莺监控更快、更稳、更好用 => github pull request
尊重、认可和记录每一位贡献者的工作是夜莺开源社区的第一指导原则,我们提倡高效的提问,这既是对开发者时间的尊重,也是对整个社区知识沉淀的贡献:
Who is using Nightingale
您可以通过在 Who is Using Nightingale 登记您的使用情况,分享您的使用经验。
Stargazers over time

Contributors
License
加入交流群

 Directories
¶
Directories
¶
| Path | Synopsis |
|---|---|
|
cmd
|
|
|
pkg
|
|
|
choice
Package choice provides basic functions for working with plugin options that must be one of several values.
|
Package choice provides basic functions for working with plugin options that must be one of several values. |
|
prom
Package v1 provides bindings to the Prometheus HTTP API v1: http://prometheus.io/docs/querying/api/
|
Package v1 provides bindings to the Prometheus HTTP API v1: http://prometheus.io/docs/querying/api/ |