 README
¶
README
¶
Machinery
Machinery is an asynchronous task queue/job queue based on distributed message passing.


![]()

![]()
![]()
![]()
- First Steps
- Configuration
- Custom Logger
- Server
- Workers
- Tasks
- Workflows
- Development
- Supporting the project
First Steps
Add the Machinery library to your $GOPATH/src:
go get github.com/RichardKnop/machinery/v1
First, you will need to define some tasks. Look at sample tasks in example/tasks/tasks.go to see a few examples.
Second, you will need to launch a worker process:
go run example/machinery.go worker
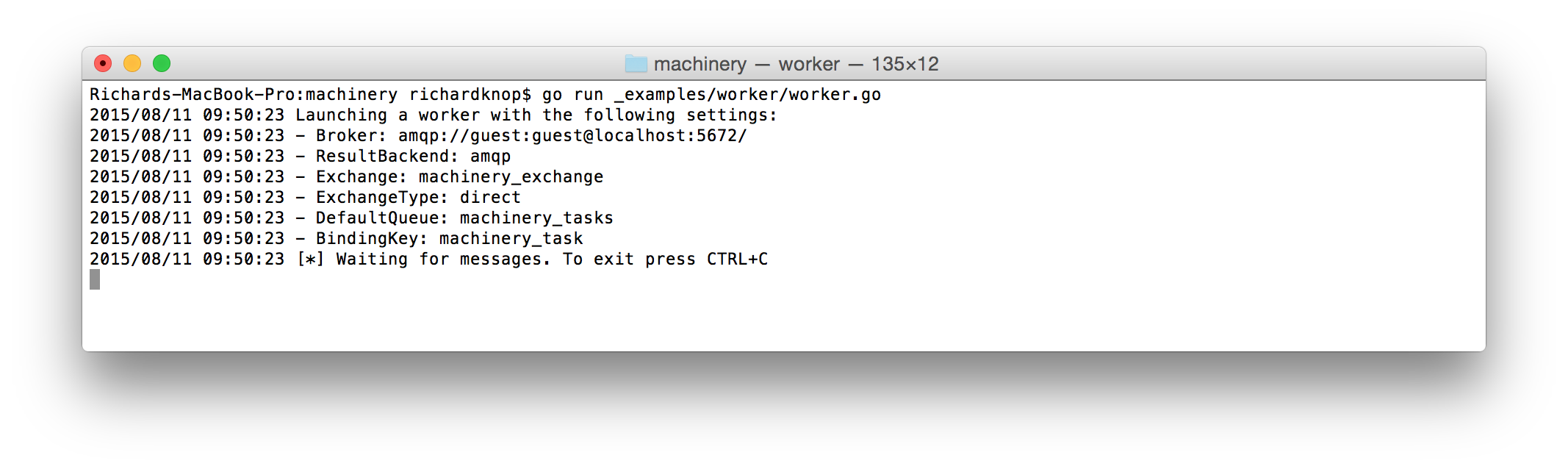
Finally, once you have a worker running and waiting for tasks to consume, send some tasks:
go run example/machinery.go send
You will be able to see the tasks being processed asynchronously by the worker:
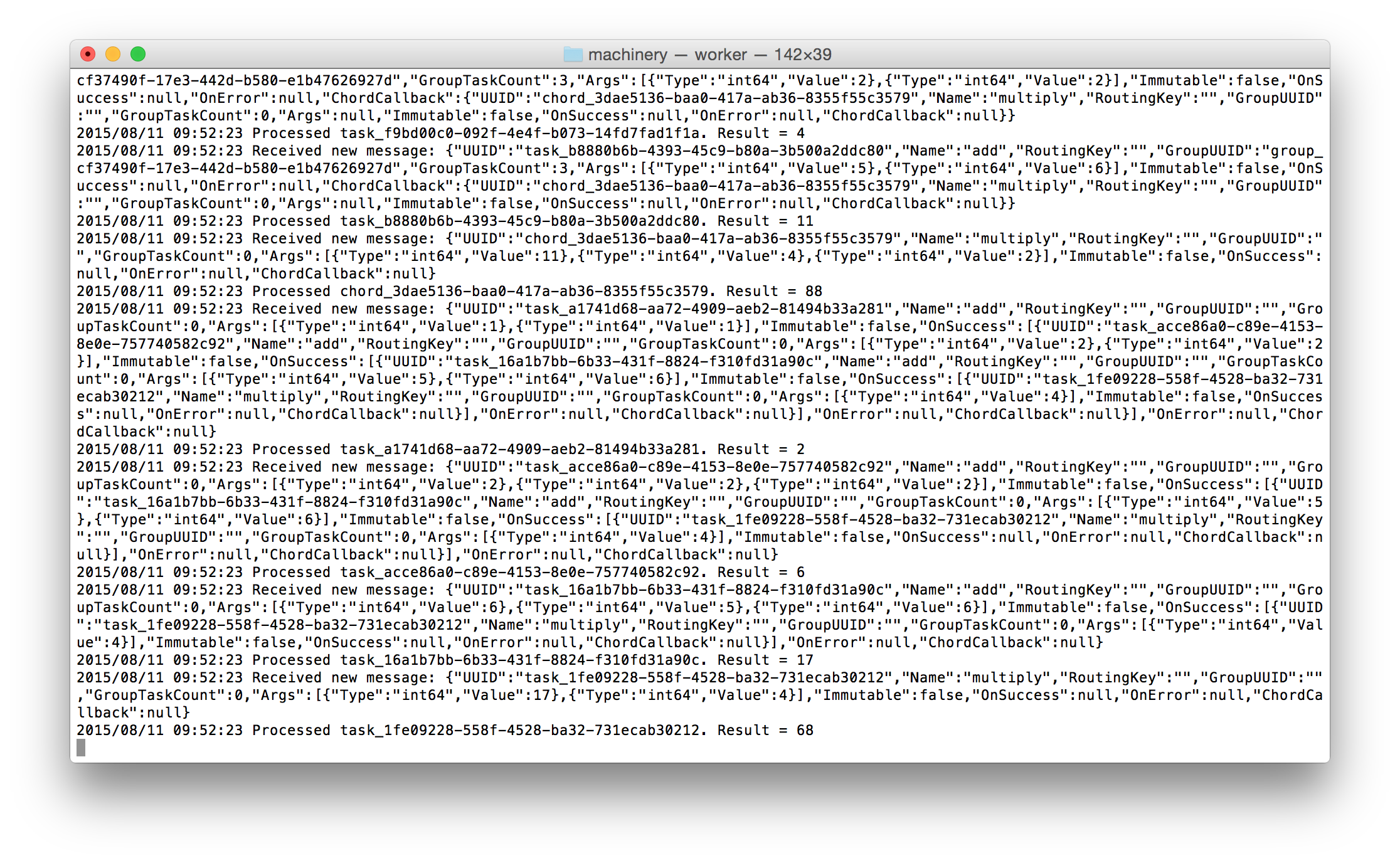
Configuration
The config package has convenience methods for loading configuration from environment variables or a YAML file. For example, load configuration from environment variables:
cnf, err := config.NewFromEnvironment(true)
Or load from YAML file:
cnf := config.NewFromFile("config.yml", true)
Second boolean flag enables live reloading of configuration every 10 seconds. Use false to disable live reloading.
Machinery configuration is encapsulated by a Config struct and injected as a dependency to objects that need it.
Broker
A message broker. Currently supported brokers are:
AMQP
Use AMQP URL in the format:
amqp://[username:password@]@host[:port]
For example:
amqp://guest:guest@localhost:5672
Redis
Use Redis URL in one of these formats:
redis://[password@]host[port][/db_num]
redis+socket://[password@]/path/to/file.sock[:/db_num]
For example:
redis://127.0.0.1:6379, or with passwordredis://password@127.0.0.1:6379redis+socket://password@/path/to/file.sock:/0
AWS SQS
Use AWS SQS URL in the format:
https://sqs.us-east-2.amazonaws.com/123456789012
See AWS SQS docs for more information.
Also, configuring AWS_REGION is required, or an error would be thrown.
To use a manually configured SQS Client:
var sqsClient = sqs.New(session.Must(session.NewSession(&aws.Config{
Region: aws.String("YOUR_AWS_REGION"),
Credentials: credentials.NewStaticCredentials("YOUR_AWS_ACCESS_KEY", "YOUR_AWS_ACCESS_SECRET", ""),
HTTPClient: &http.Client{
Timeout: time.Second * 120,
},
})))
var cnf = &config.Config{
Broker: "YOUR_SQS_URL"
DefaultQueue: "machinery_tasks",
SQS: &config.SQSConfig{
Client: sqsClient,
},
}
DefaultQueue
Default queue name, e.g. machinery_tasks.
ResultBackend
Result backend to use for keeping task states and results.
Currently supported backends are:
Redis
Use Redis URL in one of these formats:
redis://[password@]host[port][/db_num]
redis+socket://[password@]/path/to/file.sock[:/db_num]
For example:
redis://127.0.0.1:6379, or with passwordredis://password@127.0.0.1:6379redis+socket://password@/path/to/file.sock:/0
Memcache
Use Memcache URL in the format:
memcache://host1[:port1][,host2[:port2],...[,hostN[:portN]]]
For example:
memcache://127.0.0.1:11211for a single instance, ormemcache://10.0.0.1:11211,10.0.0.2:11211for a cluster
AMQP
Use AMQP URL in the format:
amqp://[username:password@]@host[:port]
For example:
amqp://guest:guest@localhost:5672
Keep in mind AMQP is not recommended as a result backend. See Keeping Results
MongoDB
Use Mongodb URL in the format:
mongodb://[username:password@]host1[:port1][,host2[:port2],...[,hostN[:portN]]][/[database][?options]]
For example:
mongodb://127.0.0.1:27017/taskresults
See MongoDB docs for more information.
ResultsExpireIn
How long to store task results for in seconds. Defaults to 3600 (1 hour).
AMQP
RabbitMQ related configuration. Not neccessarry if you are using other broker/backend.
Exchange: exchange name, e.g.machinery_exchangeExchangeType: exchange type, e.g.directQueueBindingArguments: an optional map of additional arguments used when binding to an AMQP queueBindingKey: The queue is bind to the exchange with this key, e.g.machinery_taskPrefetchCount: How many tasks to prefetch (set to1if you have long running tasks)
Dynamodb
Dynamodb related configuration. Not neccessarry if you are using other backend.
task_states_table: Custom table name for saving task states. Default one istask_states, and make sure to create this table in your AWS admin first, usingTaskUUIDas table's primary key.group_metas_table: Custom table name for saving group metas. Default one isgroup_metas, and make sure to create this table in your AWS admin first, usingGroupUUIDas table's primary key. For example:
dynamodb:
task_states_table: 'task_states'
group_metas_table: 'group_metas'
If these tables are not found, an fatal error would be thrown.
Custom Logger
You can define a custom logger by implementing the following interface:
type Interface interface {
Print(...interface{})
Printf(string, ...interface{})
Println(...interface{})
Fatal(...interface{})
Fatalf(string, ...interface{})
Fatalln(...interface{})
Panic(...interface{})
Panicf(string, ...interface{})
Panicln(...interface{})
}
Then just set the logger in your setup code by calling Set function exported by github.com/RichardKnop/machinery/v1/log package:
log.Set(myCustomLogger)
Server
A Machinery library must be instantiated before use. The way this is done is by creating a Server instance. Server is a base object which stores Machinery configuration and registered tasks. E.g.:
import (
"github.com/RichardKnop/machinery/v1/config"
"github.com/RichardKnop/machinery/v1"
)
var cnf = &config.Config{
Broker: "amqp://guest:guest@localhost:5672/",
DefaultQueue: "machinery_tasks",
ResultBackend: "amqp://guest:guest@localhost:5672/",
AMQP: &config.AMQPConfig{
Exchange: "machinery_exchange",
ExchangeType: "direct",
BindingKey: "machinery_task",
},
}
server, err := machinery.NewServer(cnf)
if err != nil {
// do something with the error
}
Workers
In order to consume tasks, you need to have one or more workers running. All you need to run a worker is a Server instance with registered tasks. E.g.:
worker := server.NewWorker("worker_name", 10)
err := worker.Launch()
if err != nil {
// do something with the error
}
Each worker will only consume registered tasks. For each task on the queue the Worker.Process() method will will be run
in a goroutine. Use the second parameter of server.NewWorker to limit the number of concurrently running Worker.Process()
calls (per worker). Example: 1 will serialize task execution while 0 makes the number of concurrently executed tasks unlimited (default).
Tasks
Tasks are a building block of Machinery applications. A task is a function which defines what happens when a worker receives a message.
Each task needs to return an error as a last return value. In addition to error tasks can now return any number of arguments.
Examples of valid tasks:
func Add(args ...int64) (int64, error) {
sum := int64(0)
for _, arg := range args {
sum += arg
}
return sum, nil
}
func Multiply(args ...int64) (int64, error) {
sum := int64(1)
for _, arg := range args {
sum *= arg
}
return sum, nil
}
// You can use context.Context as first argument to tasks, useful for open tracing
func TaskWithContext(ctx context.Context, arg Arg) error {
// ... use ctx ...
return nil
}
// Tasks need to return at least error as a minimal requirement
func DummyTask(arg string) error {
return errors.New(arg)
}
// You can also return multiple results from the task
func DummyTask2(arg1, arg2 string) (string, string, error) {
return arg1, arg2, nil
}
Registering Tasks
Before your workers can consume a task, you need to register it with the server. This is done by assigning a task a unique name:
server.RegisterTasks(map[string]interface{}{
"add": Add,
"multiply": Multiply,
})
Tasks can also be registered one by one:
server.RegisterTask("add", Add)
server.RegisterTask("multiply", Multiply)
Simply put, when a worker receives a message like this:
{
"UUID": "48760a1a-8576-4536-973b-da09048c2ac5",
"Name": "add",
"RoutingKey": "",
"ETA": null,
"GroupUUID": "",
"GroupTaskCount": 0,
"Args": [
{
"Type": "int64",
"Value": 1,
},
{
"Type": "int64",
"Value": 1,
}
],
"Immutable": false,
"RetryCount": 0,
"RetryTimeout": 0,
"OnSuccess": null,
"OnError": null,
"ChordCallback": null
}
It will call Add(1, 1). Each task should return an error as well so we can handle failures.
Ideally, tasks should be idempotent which means there will be no unintended consequences when a task is called multiple times with the same arguments.
Signatures
A signature wraps calling arguments, execution options (such as immutability) and success/error callbacks of a task so it can be sent across the wire to workers. Task signatures implement a simple interface:
// Arg represents a single argument passed to invocation fo a task
type Arg struct {
Type string
Value interface{}
}
// Headers represents the headers which should be used to direct the task
type Headers map[string]interface{}
// Signature represents a single task invocation
type Signature struct {
UUID string
Name string
RoutingKey string
ETA *time.Time
GroupUUID string
GroupTaskCount int
Args []Arg
Headers Headers
Immutable bool
RetryCount int
RetryTimeout int
OnSuccess []*Signature
OnError []*Signature
ChordCallback *Signature
}
UUID is a unique ID of a task. You can either set it yourself or it will be automatically generated.
Name is the unique task name by which it is registered against a Server instance.
RoutingKey is used for routing a task to correct queue. If you leave it empty, the default behaviour will be to set it to the default queue's binding key for direct exchange type and to the default queue name for other exchange types.
ETA is a timestamp used for delaying a task. if it's nil, the task will be published for workers to consume immediately. If it is set, the task will be delayed until the ETA timestamp.
GroupUUID, GroupTaskCount are useful for creating groups of tasks.
Args is a list of arguments that will be passed to the task when it is executed by a worker.
Headers is a list of headers that will be used when publishing the task to AMQP queue.
Immutable is a flag which defines whether a result of the executed task can be modified or not. This is important with OnSuccess callbacks. Immutable task will not pass its result to its success callbacks while a mutable task will prepend its result to args sent to callback tasks. Long story short, set Immutable to false if you want to pass result of the first task in a chain to the second task.
RetryCount specifies how many times a failed task should be retried (defaults to 0). Retry attempts will be spaced out in time, after each failure another attempt will be scheduled further to the future.
RetryTimeout specifies how long to wait before resending task to the queue for retry attempt. Default behaviour is to use fibonacci sequence to increase the timeout after each failed retry attempt.
OnSuccess defines tasks which will be called after the task has executed successfully. It is a slice of task signature structs.
OnError defines tasks which will be called after the task execution fails. The first argument passed to error callbacks will be the error string returned from the failed task.
ChordCallback is used to create a callback to a group of tasks.
Supported Types
Machinery encodes tasks to JSON before sending them to the broker. Task results are also stored in the backend as JSON encoded strings. Therefor only types with native JSON representation can be supported. Currently supported types are:
boolintint8int16int32int64uintuint8uint16uint32uint64float32float64string[]bool[]int[]int8[]int16[]int32[]int64[]uint[]uint8[]uint16[]uint32[]uint64[]float32[]float64[]string
Sending Tasks
Tasks can be called by passing an instance of Signature to an Server instance. E.g:
import (
"github.com/RichardKnop/machinery/v1/tasks"
)
signature := &tasks.Signature{
Name: "add",
Args: []tasks.Arg{
{
Type: "int64",
Value: 1,
},
{
Type: "int64",
Value: 1,
},
},
}
asyncResult, err := server.SendTask(signature)
if err != nil {
// failed to send the task
// do something with the error
}
Delayed Tasks
You can delay a task by setting the ETA timestamp field on the task signature.
// Delay the task by 5 seconds
eta := time.Now().UTC().Add(time.Second * 5)
signature.ETA = &eta
Retry Tasks
You can set a number of retry attempts before declaring task as failed. Fibonacci sequence will be used to space out retry requests over time.
// If the task fails, retry it up to 3 times
signature.RetryCount = 3
Alternatively, you can return tasks.ErrRetryTaskLater from your task and specify duration after which the task should be retried, e.g.:
return tasks.NewErrRetryTaskLater("some error", 4 * time.Hour)
Get Pending Tasks
Tasks currently waiting in the queue to be consumed by workers can be inspected, e.g.:
server.GetBroker().GetPendingTasks("some_queue")
Currently only supported by Redis broker.
Keeping Results
If you configure a result backend, the task states and results will be persisted. Possible states:
const (
// StatePending - initial state of a task
StatePending = "PENDING"
// StateReceived - when task is received by a worker
StateReceived = "RECEIVED"
// StateStarted - when the worker starts processing the task
StateStarted = "STARTED"
// StateRetry - when failed task has been scheduled for retry
StateRetry = "RETRY"
// StateSuccess - when the task is processed successfully
StateSuccess = "SUCCESS"
// StateFailure - when processing of the task fails
StateFailure = "FAILURE"
)
When using AMQP as a result backend, task states will be persisted in separate queues for each task. Although RabbitMQ can scale up to thousands of queues, it is strongly advised to use a better suited result backend (e.g. Memcache) when you are expecting to run a large number of parallel tasks.
// TaskResult represents an actual return value of a processed task
type TaskResult struct {
Type string `bson:"type"`
Value interface{} `bson:"value"`
}
// TaskState represents a state of a task
type TaskState struct {
TaskUUID string `bson:"_id"`
State string `bson:"state"`
Results []*TaskResult `bson:"results"`
Error string `bson:"error"`
}
// GroupMeta stores useful metadata about tasks within the same group
// E.g. UUIDs of all tasks which are used in order to check if all tasks
// completed successfully or not and thus whether to trigger chord callback
type GroupMeta struct {
GroupUUID string `bson:"_id"`
TaskUUIDs []string `bson:"task_uuids"`
ChordTriggered bool `bson:"chord_triggered"`
Lock bool `bson:"lock"`
}
TaskResult represents a slice of return values of a processed task.
TaskState struct will be serialized and stored every time a task state changes.
GroupMeta stores useful metadata about tasks within the same group. E.g. UUIDs of all tasks which are used in order to check if all tasks completed successfully or not and thus whether to trigger chord callback.
AsyncResult object allows you to check for the state of a task:
taskState := asyncResult.GetState()
fmt.Printf("Current state of %v task is:\n", taskState.TaskUUID)
fmt.Println(taskState.State)
There are couple of convenient me methods to inspect the task status:
asyncResult.GetState().IsCompleted()
asyncResult.GetState().IsSuccess()
asyncResult.GetState().IsFailure()
You can also do a synchronous blocking call to wait for a task result:
results, err := asyncResult.Get(time.Duration(time.Millisecond * 5))
if err != nil {
// getting result of a task failed
// do something with the error
}
for _, result := range results {
fmt.Println(result.Interface())
}
Workflows
Running a single asynchronous task is fine but often you will want to design a workflow of tasks to be executed in an orchestrated way. There are couple of useful functions to help you design workflows.
Groups
Group is a set of tasks which will be executed in parallel, independent of each other. E.g.:
import (
"github.com/RichardKnop/machinery/v1/tasks"
"github.com/RichardKnop/machinery/v1"
)
signature1 := tasks.Signature{
Name: "add",
Args: []tasks.Arg{
{
Type: "int64",
Value: 1,
},
{
Type: "int64",
Value: 1,
},
},
}
signature2 := tasks.Signature{
Name: "add",
Args: []tasks.Arg{
{
Type: "int64",
Value: 5,
},
{
Type: "int64",
Value: 5,
},
},
}
group, _ := tasks.NewGroup(&signature1, &signature2)
asyncResults, err := server.SendGroup(group)
if err != nil {
// failed to send the group
// do something with the error
}
SendGroup returns a slice of AsyncResult objects. So you can do a blocking call and wait for the result of groups tasks:
for _, asyncResult := range asyncResults {
results, err := asyncResult.Get(time.Duration(time.Millisecond * 5))
if err != nil {
// getting result of a task failed
// do something with the error
}
for _, result := range results {
fmt.Println(result.Interface())
}
}
Chords
Chord allows you to define a callback to be executed after all tasks in a group finished processing, e.g.:
import (
"github.com/RichardKnop/machinery/v1/tasks"
"github.com/RichardKnop/machinery/v1"
)
signature1 := tasks.Signature{
Name: "add",
Args: []tasks.Arg{
{
Type: "int64",
Value: 1,
},
{
Type: "int64",
Value: 1,
},
},
}
signature2 := tasks.Signature{
Name: "add",
Args: []tasks.Arg{
{
Type: "int64",
Value: 5,
},
{
Type: "int64",
Value: 5,
},
},
}
signature3 := tasks.Signature{
Name: "multiply",
}
group := tasks.NewGroup(&signature1, &signature2)
chord, _ := tasks.NewChord(group, &signature3)
chordAsyncResult, err := server.SendChord(chord)
if err != nil {
// failed to send the chord
// do something with the error
}
The above example executes task1 and task2 in parallel, aggregates their results and passes them to task3. Therefore what would end up happening is:
multiply(add(1, 1), add(5, 5))
More explicitly:
(1 + 1) * (5 + 5) = 2 * 10 = 20
SendChord returns ChordAsyncResult which follows AsyncResult's interface. So you can do a blocking call and wait for the result of the callback:
results, err := chordAsyncResult.Get(time.Duration(time.Millisecond * 5))
if err != nil {
// getting result of a chord failed
// do something with the error
}
for _, result := range results {
fmt.Println(result.Interface())
}
Chains
Chain is simply a set of tasks which will be executed one by one, each successful task triggering the next task in the chain. E.g.:
import (
"github.com/RichardKnop/machinery/v1/tasks"
"github.com/RichardKnop/machinery/v1"
)
signature1 := tasks.Signature{
Name: "add",
Args: []tasks.Arg{
{
Type: "int64",
Value: 1,
},
{
Type: "int64",
Value: 1,
},
},
}
signature2 := tasks.Signature{
Name: "add",
Args: []tasks.Arg{
{
Type: "int64",
Value: 5,
},
{
Type: "int64",
Value: 5,
},
},
}
signature3 := tasks.Signature{
Name: "multiply",
Args: []tasks.Arg{
{
Type: "int64",
Value: 4,
},
},
}
chain, _ := tasks.NewChain(&signature1, &signature2, &signature3)
chainAsyncResult, err := server.SendChain(chain)
if err != nil {
// failed to send the chain
// do something with the error
}
The above example executes task1, then task2 and then task3, passing the result of each task to the next task in the chain. Therefore what would end up happening is:
multiply(add(add(1, 1), 5, 5), 4)
More explicitly:
((1 + 1) + (5 + 5)) * 4 = 12 * 4 = 48
SendChain returns ChainAsyncResult which follows AsyncResult's interface. So you can do a blocking call and wait for the result of the whole chain:
results, err := chainAsyncResult.Get(time.Duration(time.Millisecond * 5))
if err != nil {
// getting result of a chain failed
// do something with the error
}
for _, result := range results {
fmt.Println(result.Interface())
}
Development
Requirements
- Go
- RabbitMQ
- Redis (optional)
- Memcached (optional)
- MongoDB (optional)
On OS X systems, you can install requirements using Homebrew:
brew install go
brew install rabbitmq
brew install redis
brew install memcached
brew install mongodb
Dependencies
According to Go 1.5 Vendor experiment, all dependencies are stored in the vendor directory. This approach is called vendoring and is the best practice for Go projects to lock versions of dependencies in order to achieve reproducible builds.
This project uses dep for dependency management. To update dependencies during development:
dep ensure
Testing
Easiest (and platform agnostic) way to run tests is via docker-compose:
make ci
This will basically run docker-compose command:
(docker-compose -f docker-compose.test.yml -p machinery_ci up --build -d) && (docker logs -f machinery_sut &) && (docker wait machinery_sut)
Alternative approach is to setup a development environment on your machine.
In order to enable integration tests, you will need to install all required services (RabbitMQ, Redis, Memcache, MongoDB) and export these environment variables:
export AMQP_URL=amqp://guest:guest@localhost:5672/
export REDIS_URL=127.0.0.1:6379
export MEMCACHE_URL=127.0.0.1:11211
export MONGODB_URL=127.0.0.1:27017
To run integration tests against an SQS instance, you will need to create a "test_queue" in SQS and export these environment variables:
export SQS_URL=https://YOUR_SQS_URL
export AWS_ACCESS_KEY_ID=YOUR_AWS_ACCESS_KEY_ID
export AWS_SECRET_ACCESS_KEY=YOUR_AWS_SECRET_ACCESS_KEY
export AWS_DEFAULT_REGION=YOUR_AWS_DEFAULT_REGION
Then just run:
make test
If the environment variables are not exported, make test will only run unit tests.
Supporting the project
Donate BTC to my wallet if you find this project useful: 12iFVjQ5n3Qdmiai4Mp9EG93NSvDipyRKV
